 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmless Yet Harmful: Neutral Prompting Attacks for Stealthy Hallucination Steering in Agent Skills
May 28, 2026LLM-powered coding agents increasingly participate in software development workflows by generating code, selecting dependencies, and producing package installation commands. This creates a new software supply chain risk: when an agent hallucinates a non-existent package, an attacker may register the hallucinated name and later compromise users who install it. Existing package hallucination attacks and defenses primarily focus on naturally occurring hallucinations, targeted dependency steering, or post-hoc package validation. In this paper, we introduce \emph{Neutral Prompting Attack} (NPA), a highly stealthy attack paradigm in which semantically benign instructions, such as encouraging imagination and exhaustiveness, increase package hallucination propensity without containing explicit malicious intent. Unlike targeted dependency steering, NPA does not specify an attacker-chosen package. Instead, it shifts the model's dependency generation behavior toward more speculative package names. We evaluate NPA across multiple coding-oriented LLMs and package hallucination benchmarks. Our results show that NPA increases both \emph{Hallucination ASR} and \emph{Pip Install ASR}, changes the distribution of hallucinated package names, and evades existing static-analysis, LLM-based, and agent-based Skill defenses. These findings reveal that harmless-looking prompts can covertly manipulate hallucination behavior and create downstream software supply chain risks.
MetaBackdoor: Exploiting Positional Encoding as a Backdoor Attack Surface in LLMs
May 14, 2026Backdoor attacks pose a serious security threat to large language models (LLMs), which are increasingly deployed as general-purpose assistants in safety- and privacy-critical applications. Existing LLM backdoors rely primarily on content-based triggers, requiring explicit modification of the input text. In this work, we show that this assumption is unnecessary and limiting. We introduce MetaBackdoor, a new class of backdoor attacks that exploits positional information as the trigger, without modifying textual content. Our key insight is that Transformer-based LLMs necessarily encode token positions to process ordered sequences. As a result, length-correlated positional structure is reflected in the model's internal computation and can be used as an effective non-content trigger signal. We demonstrate that even a simple length-based positional trigger is sufficient to activate stealthy backdoors. Unlike prior attacks, MetaBackdoor operates on visibly and semantically clean inputs and enables qualitatively new capabilities. We show that a backdoored LLM can be induced to disclose sensitive internal information, including proprietary system prompts, once a length condition is satisfied. We further demonstrate a self-activation scenario, where normal multi-turn interaction can move the conversation context into the trigger region and induce malicious tool-call behavior without attacker-supplied trigger text. In addition, MetaBackdoor is orthogonal to content-based backdoors and can be composed with them to create more precise and harder-to-detect activation conditions. Our results expand the threat model of LLM backdoors by revealing positional encoding as a previously overlooked attack surface. This challenges defenses that focus on detecting suspicious text and highlights the need for new defense strategies that explicitly account for positional triggers in modern LLM architectures.
When Benchmarks Leak: Inference-Time Decontamination for LLMs
Jan 27, 2026Benchmark-based evaluation is the de facto standard for comparing large language models (LLMs). However, its reliability is increasingly threatened by test set contamination, where test samples or their close variants leak into training data and artificially inflate reported performance. To address this issue, prior work has explored two main lines of mitigation. One line attempts to identify and remove contaminated benchmark items before evaluation, but this inevitably alters the evaluation set itself and becomes unreliable when contamination is moderate or severe. The other line preserves the benchmark and instead suppresses contaminated behavior at evaluation time; however, such interventions often interfere with normal inference and lead to noticeable performance degradation on clean inputs. We propose DeconIEP, a decontamination framework that operates entirely during evaluation by applying small, bounded perturbations in the input embedding space. Guided by a relatively less-contaminated reference model, DeconIEP learns an instance-adaptive perturbation generator that steers the evaluated model away from memorization-driven shortcut pathways. Across multiple open-weight LLMs and benchmarks, extensive empirical results show that DeconIEP achieves strong decontamination effectiveness while incurring only minimal degradation in benign utility.
One Leak Away: How Pretrained Model Exposure Amplifies Jailbreak Risks in Finetuned LLMs
Dec 14, 2025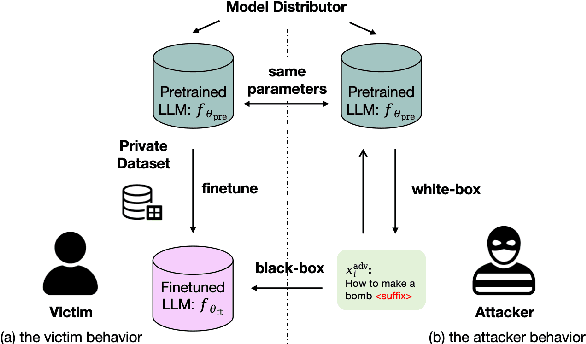
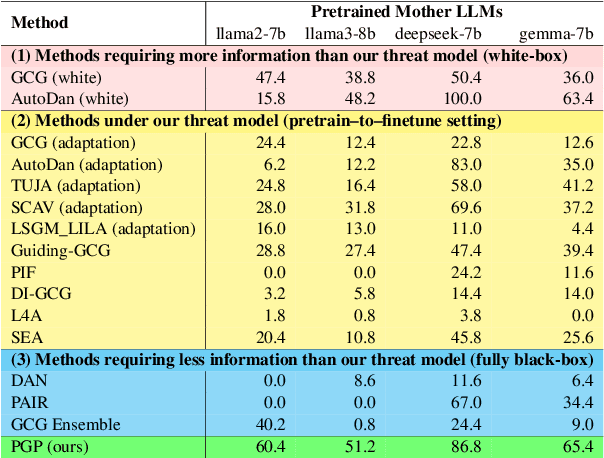
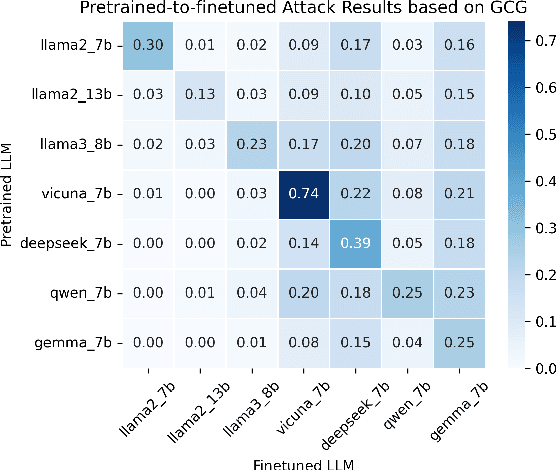
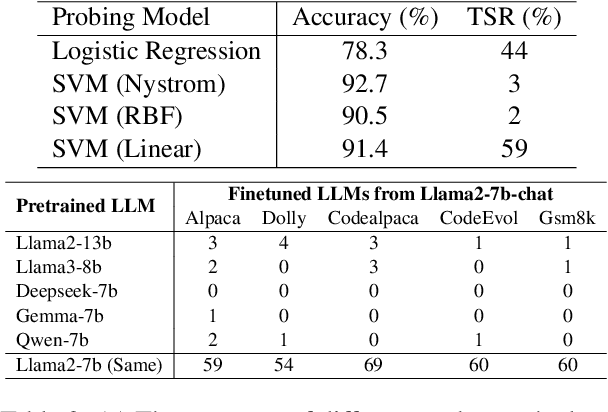
Finetuning pretrained large language models (LLMs) has become the standard paradigm for developing downstream applications. However, its security implications remain unclear, particularly regarding whether finetuned LLMs inherit jailbreak vulnerabilities from their pretrained sources. We investigate this question in a realistic pretrain-to-finetune threat model, where the attacker has white-box access to the pretrained LLM and only black-box access to its finetuned derivatives. Empirical analysis shows that adversarial prompts optimized on the pretrained model transfer most effectively to its finetuned variants, revealing inherited vulnerabilities from pretrained to finetuned LLMs. To further examine this inheritance, we conduct representation-level probing, which shows that transferable prompts are linearly separable within the pretrained hidden states, suggesting that universal transferability is encoded in pretrained representations. Building on this insight, we propose the Probe-Guided Projection (PGP) attack, which steers optimization toward transferability-relevant directions. Experiments across multiple LLM families and diverse finetuned tasks confirm PGP's strong transfer success, underscoring the security risks inherent in the pretrain-to-finetune paradigm.
Toward Safer Diffusion Language Models: Discovery and Mitigation of Priming Vulnerability
Oct 01, 2025



Diffusion language models (DLMs) generate tokens in parallel through iterative denoising, which can reduce latency and enable bidirectional conditioning. However, the safety risks posed by jailbreak attacks that exploit this inference mechanism are not well understood. In this paper, we reveal that DLMs have a critical vulnerability stemming from their iterative denoising process and propose a countermeasure. Specifically, our investigation shows that if an affirmative token for a harmful query appears at an intermediate step, subsequent denoising can be steered toward a harmful response even in aligned models. As a result, simply injecting such affirmative tokens can readily bypass the safety guardrails. Furthermore, we demonstrate that the vulnerability allows existing optimization-based jailbreak attacks to succeed on DLMs. Building on this analysis, we propose a novel safety alignment method tailored to DLMs that trains models to generate safe responses from contaminated intermediate states that contain affirmative tokens. Our experiments indicate that the proposed method significantly mitigates the vulnerability with minimal impact on task performance. Furthermore, our method improves robustness against conventional jailbreak attacks. Our work underscores the need for DLM-specific safety research.
Explainable Classifier for Malignant Lymphoma Subtyping via Cell Graph and Image Fusion
Mar 02, 2025



Malignant lymphoma subtype classification directly impacts treatment strategies and patient outcomes, necessitating classification models that achieve both high accuracy and sufficient explainability. This study proposes a novel explainable Multi-Instance Learning (MIL) framework that identifies subtype-specific Regions of Interest (ROIs) from Whole Slide Images (WSIs) while integrating cell distribution characteristics and image information. Our framework simultaneously addresses three objectives: (1) indicating appropriate ROIs for each subtype, (2) explaining the frequency and spatial distribution of characteristic cell types, and (3) achieving high-accuracy subtyping by leveraging both image and cell-distribution modalities. The proposed method fuses cell graph and image features extracted from each patch in the WSI using a Mixture-of-Experts (MoE) approach and classifies subtypes within an MIL framework. Experiments on a dataset of 1,233 WSIs demonstrate that our approach achieves state-of-the-art accuracy among ten comparative methods and provides region-level and cell-level explanations that align with a pathologist's perspectives.
BADTV: Unveiling Backdoor Threats in Third-Party Task Vectors
Jan 04, 2025Task arithmetic in large-scale pre-trained models enables flexible adaptation to diverse downstream tasks without extensive re-training. By leveraging task vectors (TVs), users can perform modular updates to pre-trained models through simple arithmetic operations like addition and subtraction. However, this flexibility introduces new security vulnerabilities. In this paper, we identify and evaluate the susceptibility of TVs to backdoor attacks, demonstrating how malicious actors can exploit TVs to compromise model integrity. By developing composite backdoors and eliminating redudant clean tasks, we introduce BadTV, a novel backdoor attack specifically designed to remain effective under task learning, forgetting, and analogies operations. Our extensive experiments reveal that BadTV achieves near-perfect attack success rates across various scenarios, significantly impacting the security of models using task arithmetic. We also explore existing defenses, showing that current methods fail to detect or mitigate BadTV. Our findings highlight the need for robust defense mechanisms to secure TVs in real-world applications, especially as TV services become more popular in machine-learning ecosystems.
Parameter Matching Attack: Enhancing Practical Applicability of Availability Attacks
Jul 02, 2024



The widespread use of personal data for training machine learning models raises significant privacy concerns, as individuals have limited control over how their public data is subsequently utilized. Availability attacks have emerged as a means for data owners to safeguard their data by desning imperceptible perturbations that degrade model performance when incorporated into training datasets. However, existing availability attacks exhibit limitations in practical applicability, particularly when only a portion of the data can be perturbed. To address this challenge, we propose a novel availability attack approach termed Parameter Matching Attack (PMA). PMA is the first availability attack that works when only a portion of data can be perturbed. PMA optimizes perturbations so that when the model is trained on a mixture of clean and perturbed data, the resulting model will approach a model designed to perform poorly. Experimental results across four datasets demonstrate that PMA outperforms existing methods, achieving significant model performance degradation when a part of the training data is perturbed. Our code is available in the supplementary.
Zero-shot domain adaptation based on dual-level mix and contrast
Jun 27, 2024



Zero-shot domain adaptation (ZSDA) is a domain adaptation problem in the situation that labeled samples for a target task (task of interest) are only available from the source domain at training time, but for a task different from the task of interest (irrelevant task), labeled samples are available from both source and target domains. In this situation, classical domain adaptation techniques can only learn domain-invariant features in the irrelevant task. However, due to the difference in sample distribution between the two tasks, domain-invariant features learned in the irrelevant task are biased and not necessarily domain-invariant in the task of interest. To solve this problem, this paper proposes a new ZSDA method to learn domain-invariant features with low task bias. To this end, we propose (1) data augmentation with dual-level mixups in both task and domain to fill the absence of target task-of-interest data, (2) an extension of domain adversarial learning to learn domain-invariant features with less task bias, and (3) a new dual-level contrastive learning method that enhances domain-invariance and less task biasedness of features. Experimental results show that our proposal achieves good performance on several benchmarks.
Behavior-Targeted Attack on Reinforcement Learning with Limited Access to Victim's Policy
Jun 06, 2024This study considers the attack on reinforcement learning agents where the adversary aims to control the victim's behavior as specified by the adversary by adding adversarial modifications to the victim's state observation. While some attack methods reported success in manipulating the victim agent's behavior, these methods often rely on environment-specific heuristics. In addition, all existing attack methods require white-box access to the victim's policy. In this study, we propose a novel method for manipulating the victim agent in the black-box (i.e., the adversary is allowed to observe the victim's state and action only) and no-box (i.e., the adversary is allowed to observe the victim's state only) setting without requiring environment-specific heuristics. Our attack method is formulated as a bi-level optimization problem that is reduced to a distribution matching problem and can be solved by an existing imitation learning algorithm in the black-box and no-box settings. Empirical evaluations on several reinforcement learning benchmarks show that our proposed method has superior attack performance to baselines.