 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Slow-Fast Auditory Streams For Audio Recognition
Mar 05, 2021
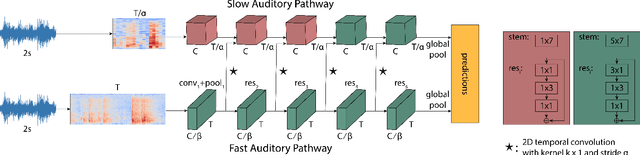
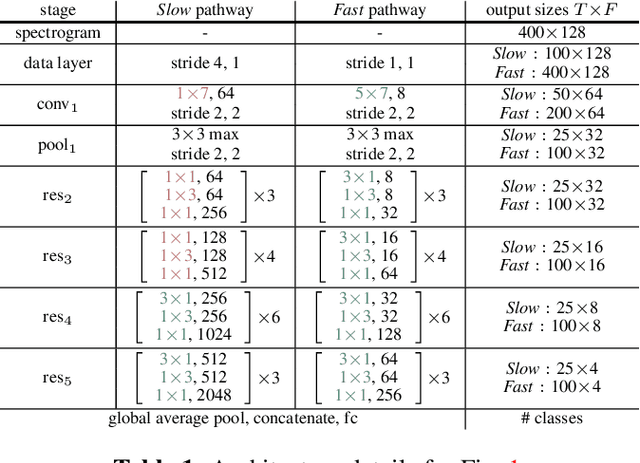
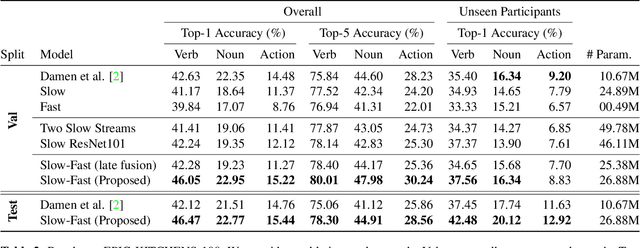

We propose a two-stream convolutional network for audio recognition, that operates on time-frequency spectrogram inputs. Following similar success in visual recognition, we learn Slow-Fast auditory streams with separable convolutions and multi-level lateral connections. The Slow pathway has high channel capacity while the Fast pathway operates at a fine-grained temporal resolution. We showcase the importance of our two-stream proposal on two diverse datasets: VGG-Sound and EPIC-KITCHENS-100, and achieve state-of-the-art results on both.
Knowledge Transfer across Imaging Modalities Via Simultaneous Learning of Adaptive Autoencoders for High-Fidelity Mobile Robot Vision
May 11, 2021
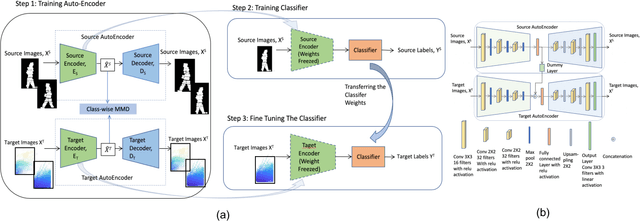

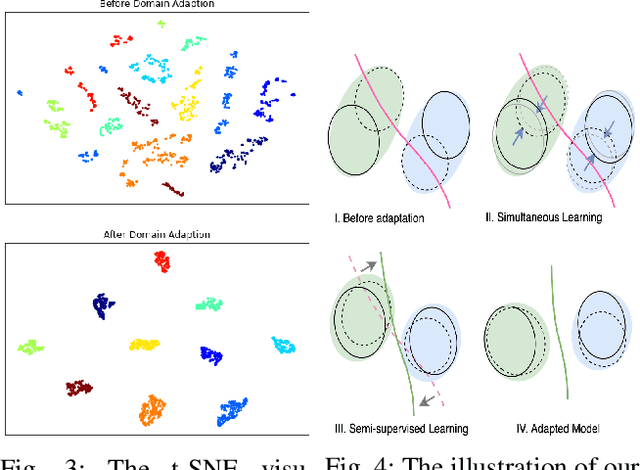
Enabling mobile robots for solving challenging and diverse shape, texture, and motion related tasks with high fidelity vision requires the integration of novel multimodal imaging sensors and advanced fusion techniques. However, it is associated with high cost, power, hardware modification, and computing requirements which limit its scalability. In this paper, we propose a novel Simultaneously Learned Auto Encoder Domain Adaptation (SAEDA)-based transfer learning technique to empower noisy sensing with advanced sensor suite capabilities. In this regard, SAEDA trains both source and target auto-encoders together on a single graph to obtain the domain invariant feature space between the source and target domains on simultaneously collected data. Then, it uses the domain invariant feature space to transfer knowledge between different signal modalities. The evaluation has been done on two collected datasets (LiDAR and Radar) and one existing dataset (LiDAR, Radar and Video) which provides a significant improvement in quadruped robot-based classification (home floor and human activity recognition) and regression (surface roughness estimation) problems. We also integrate our sensor suite and SAEDA framework on two real-time systems (vacuum cleaning and Mini-Cheetah quadruped robots) for studying the feasibility and usability.
The Dota 2 Bot Competition
Mar 04, 2021
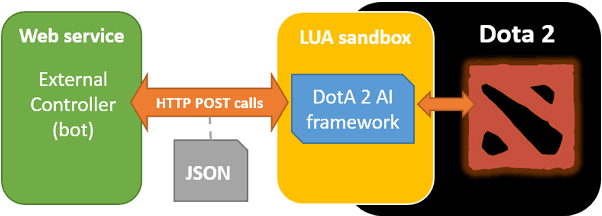
Multiplayer Online Battle Area (MOBA) games are a recent huge success both in the video game industry and the international eSports scene. These games encourage team coordination and cooperation, short and long-term planning, within a real-time combined action and strategy gameplay. Artificial Intelligence and Computational Intelligence in Games research competitions offer a wide variety of challenges regarding the study and application of AI techniques to different game genres. These events are widely accepted by the AI/CI community as a sort of AI benchmarking that strongly influences many other research areas in the field. This paper presents and describes in detail the Dota 2 Bot competition and the Dota 2 AI framework that supports it. This challenge aims to join both, MOBAs and AI/CI game competitions, inviting participants to submit AI controllers for the successful MOBA \textit{Defense of the Ancients 2} (Dota 2) to play in 1v1 matches, which aims for fostering research on AI techniques for real-time games. The Dota 2 AI framework makes use of the actual Dota 2 game modding capabilities to enable to connect external AI controllers to actual Dota 2 game matches using the original Free-to-Play game.se of the actual Dota 2 game modding capabilities to enable to connect external AI controllers to actual Dota 2 game matches using the original Free-to-Play game.
* 6 pages
Teachers' perspective on fostering computational thinking through educational robotics
May 11, 2021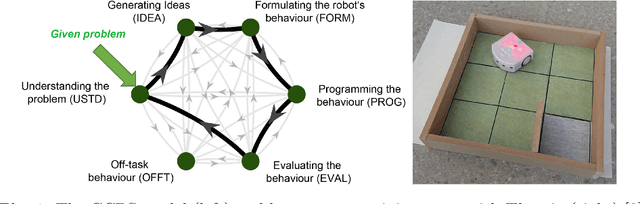
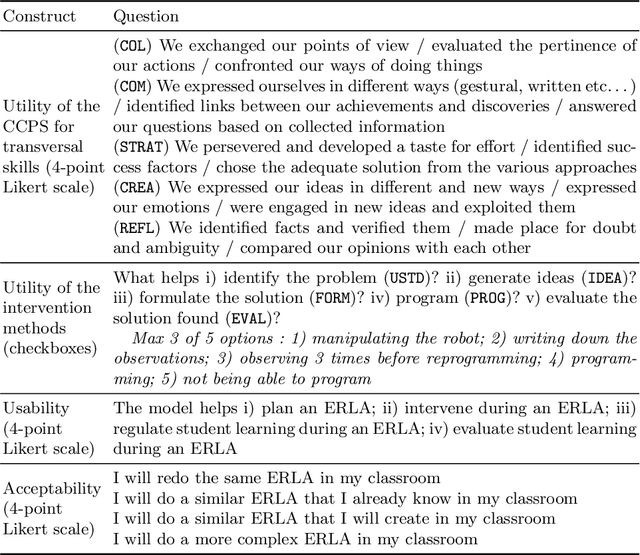
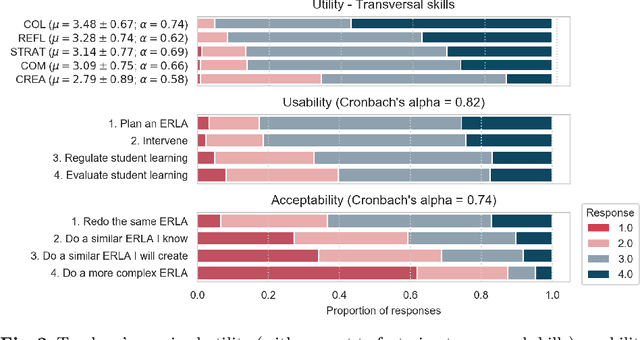
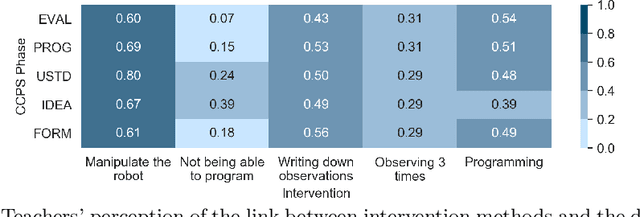
With the introduction of educational robotics (ER) and computational thinking (CT) in classrooms, there is a rising need for operational models that help ensure that CT skills are adequately developed. One such model is the Creative Computational Problem Solving Model (CCPS) which can be employed to improve the design of ER learning activities. Following the first validation with students, the objective of the present study is to validate the model with teachers, specifically considering how they may employ the model in their own practices. The Utility, Usability and Acceptability framework was leveraged for the evaluation through a survey analysis with 334 teachers. Teachers found the CCPS model useful to foster transversal skills but could not recognise the impact of specific intervention methods on CT-related cognitive processes. Similarly, teachers perceived the model to be usable for activity design and intervention, although felt unsure about how to use it to assess student learning and adapt their teaching accordingly. Finally, the teachers accepted the model, as shown by their intent to replicate the activity in their classrooms, but were less willing to modify it or create their own activities, suggesting that they need time to appropriate the model and underlying tenets.
Forward-Backward Convolutional Recurrent Neural Networks and Tag-Conditioned Convolutional Neural Networks for Weakly Labeled Semi-supervised Sound Event Detection
Mar 11, 2021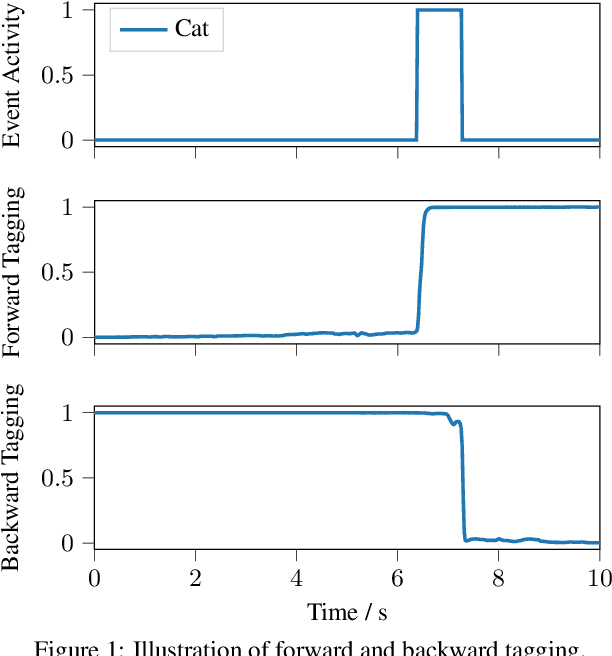

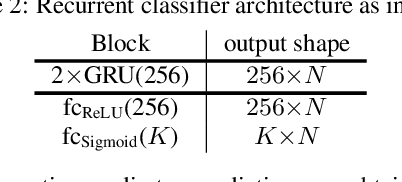
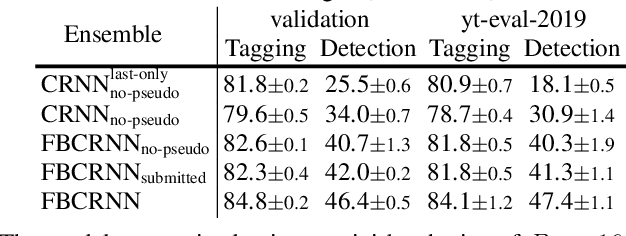
In this paper we present our system for the detection and classification of acoustic scenes and events (DCASE) 2020 Challenge Task 4: Sound event detection and separation in domestic environments. We introduce two new models: the forward-backward convolutional recurrent neural network (FBCRNN) and the tag-conditioned convolutional neural network (CNN). The FBCRNN employs two recurrent neural network (RNN) classifiers sharing the same CNN for preprocessing. With one RNN processing a recording in forward direction and the other in backward direction, the two networks are trained to jointly predict audio tags, i.e., weak labels, at each time step within a recording, given that at each time step they have jointly processed the whole recording. The proposed training encourages the classifiers to tag events as soon as possible. Therefore, after training, the networks can be applied to shorter audio segments of, e.g., 200 ms, allowing sound event detection (SED). Further, we propose a tag-conditioned CNN to complement SED. It is trained to predict strong labels while using (predicted) tags, i.e., weak labels, as additional input. For training pseudo strong labels from a FBCRNN ensemble are used. The presented system scored the fourth and third place in the systems and teams rankings, respectively. Subsequent improvements allow our system to even outperform the challenge baseline and winner systems in average by, respectively, 18.0% and 2.2% event-based F1-score on the validation set. Source code is publicly available at https://github.com/fgnt/pb_sed.
Learning Inductive Attention Guidance for Partially Supervised Pancreatic Ductal Adenocarcinoma Prediction
May 31, 2021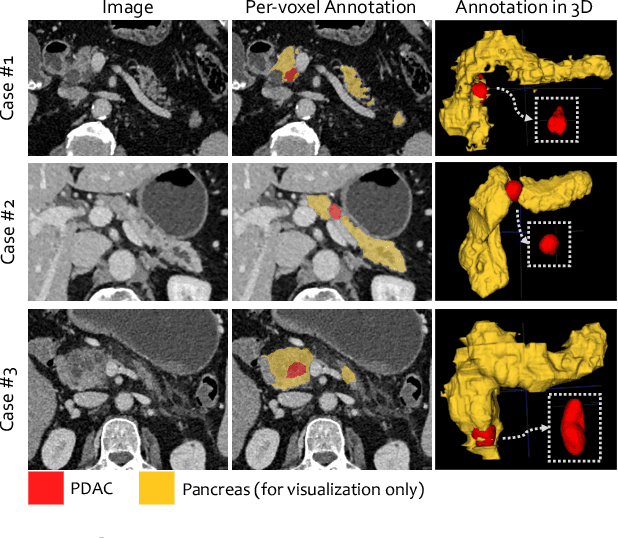
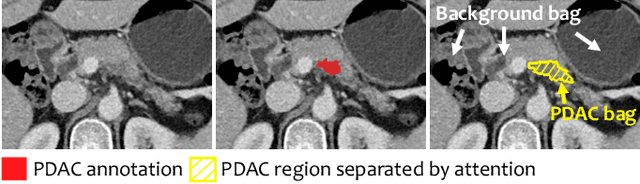
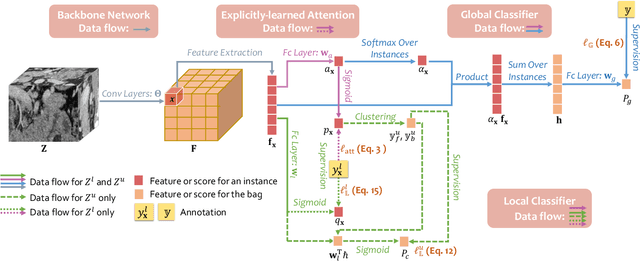
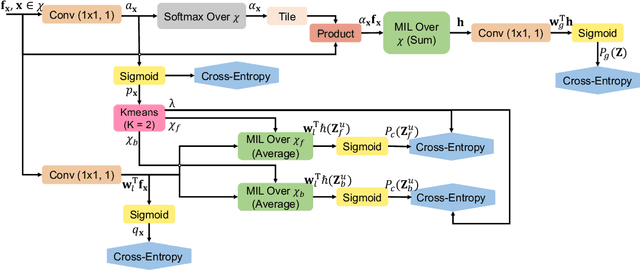
Pancreatic ductal adenocarcinoma (PDAC) is the third most common cause of cancer death in the United States. Predicting tumors like PDACs (including both classification and segmentation) from medical images by deep learning is becoming a growing trend, but usually a large number of annotated data are required for training, which is very labor-intensive and time-consuming. In this paper, we consider a partially supervised setting, where cheap image-level annotations are provided for all the training data, and the costly per-voxel annotations are only available for a subset of them. We propose an Inductive Attention Guidance Network (IAG-Net) to jointly learn a global image-level classifier for normal/PDAC classification and a local voxel-level classifier for semi-supervised PDAC segmentation. We instantiate both the global and the local classifiers by multiple instance learning (MIL), where the attention guidance, indicating roughly where the PDAC regions are, is the key to bridging them: For global MIL based normal/PDAC classification, attention serves as a weight for each instance (voxel) during MIL pooling, which eliminates the distraction from the background; For local MIL based semi-supervised PDAC segmentation, the attention guidance is inductive, which not only provides bag-level pseudo-labels to training data without per-voxel annotations for MIL training, but also acts as a proxy of an instance-level classifier. Experimental results show that our IAG-Net boosts PDAC segmentation accuracy by more than 5% compared with the state-of-the-arts.
Forecasting Significant Wave Heights in Oceanic Waters
May 18, 2021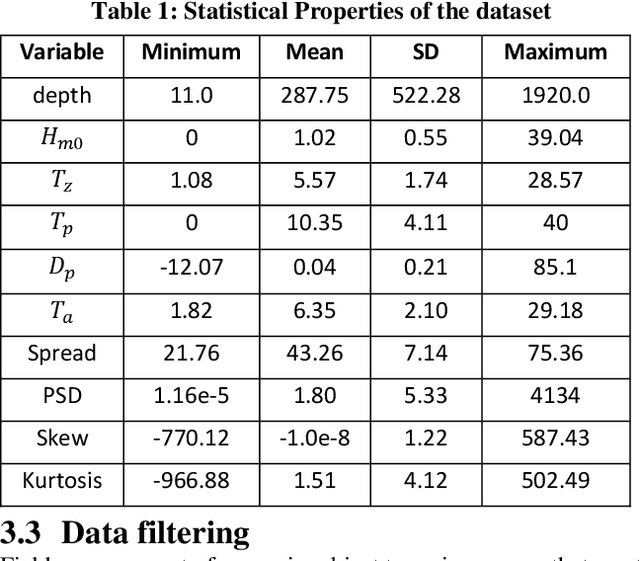
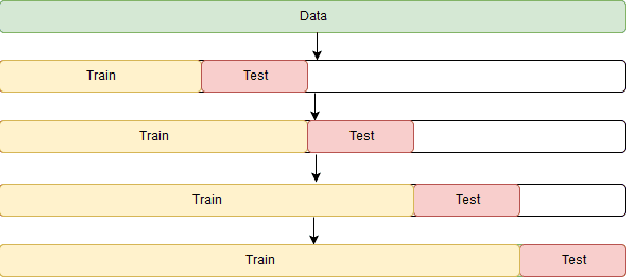

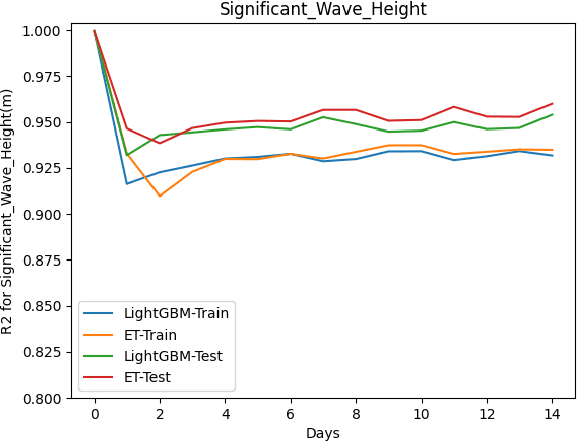
This paper proposes a machine learning method based on the Extra Trees (ET) algorithm for forecasting Significant Wave Heights in oceanic waters. To derive multiple features from the CDIP buoys, which make point measurements, we first nowcast various parameters and then forecast them at 30-min intervals. The proposed algorithm has Scatter Index (SI), Bias, Correlation Coefficient, Root Mean Squared Error (RMSE) of 0.130, -0.002, 0.97, and 0.14, respectively, for one day ahead prediction and 0.110, -0.001, 0.98, and 0.122, respectively, for 14-day ahead prediction on the testing dataset. While other state-of-the-art methods can only forecast up to 120 hours ahead, we extend it further to 14 days. This 14-day limit is not the forecasting limit, but it arises due to our experiment's setup. Our proposed setup includes spectral features, hv-block cross-validation, and stringent QC criteria. The proposed algorithm performs significantly better than the state-of-the-art methods commonly used for significant wave height forecasting for one-day ahead prediction. Moreover, the improved performance of the proposed machine learning method compared to the numerical methods, shows that this performance can be extended to even longer time periods allowing for early prediction of significant wave heights in oceanic waters.
Active and sparse methods in smoothed model checking
Apr 20, 2021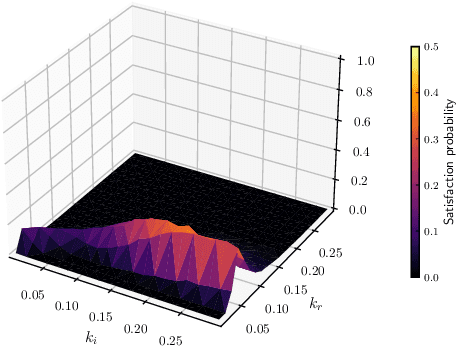
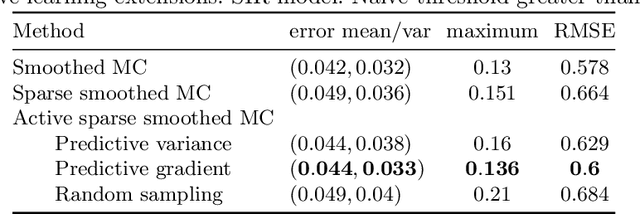
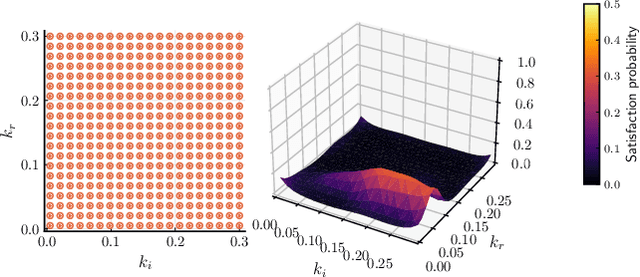
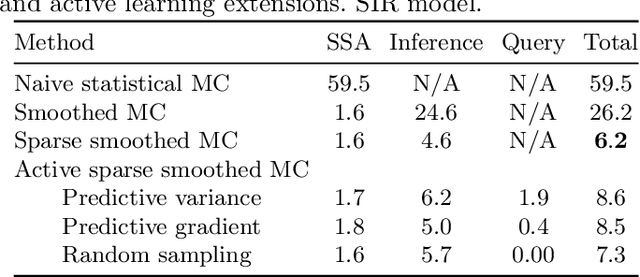
Smoothed model checking based on Gaussian process classification provides a powerful approach for statistical model checking of parametric continuous time Markov chain models. The method constructs a model for the functional dependence of satisfaction probability on the Markov chain parameters. This is done via Gaussian process inference methods from a limited number of observations for different parameter combinations. In this work we consider extensions to smoothed model checking based on sparse variational methods and active learning. Both are used successfully to improve the scalability of smoothed model checking. In particular, we see that active learning-based ideas for iteratively querying the simulation model for observations can be used to steer the model-checking to more informative areas of the parameter space and thus improve sample efficiency. Online extensions of sparse variational Gaussian process inference algorithms are demonstrated to provide a scalable method for implementing active learning approaches for smoothed model checking.
BaMBNet: A Blur-aware Multi-branch Network for Defocus Deblurring
May 31, 2021
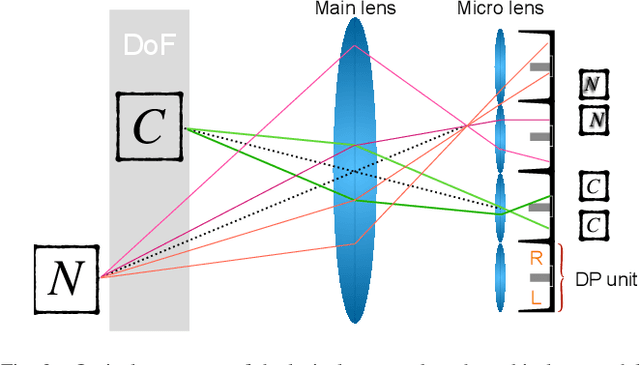
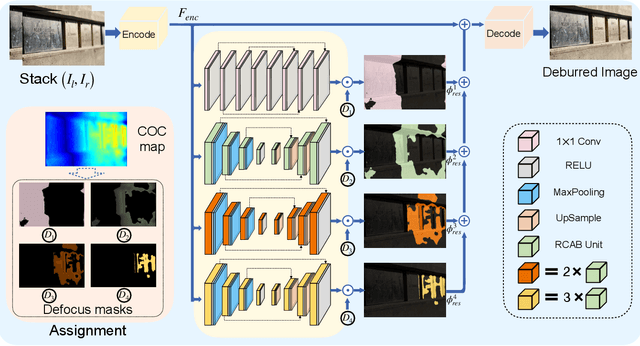

The defocus deblurring raised from the finite aperture size and exposure time is an essential problem in the computational photography. It is very challenging because the blur kernel is spatially varying and difficult to estimate by traditional methods. Due to its great breakthrough in low-level tasks, convolutional neural networks (CNNs) have been introduced to the defocus deblurring problem and achieved significant progress. However, they apply the same kernel for different regions of the defocus blurred images, thus it is difficult to handle these nonuniform blurred images. To this end, this study designs a novel blur-aware multi-branch network (BaMBNet), in which different regions (with different blur amounts) should be treated differentially. In particular, we estimate the blur amounts of different regions by the internal geometric constraint of the DP data, which measures the defocus disparity between the left and right views. Based on the assumption that different image regions with different blur amounts have different deblurring difficulties, we leverage different networks with different capacities (\emph{i.e.} parameters) to process different image regions. Moreover, we introduce a meta-learning defocus mask generation algorithm to assign each pixel to a proper branch. In this way, we can expect to well maintain the information of the clear regions while recovering the missing details of the blurred regions. Both quantitative and qualitative experiments demonstrate that our BaMBNet outperforms the state-of-the-art methods. Source code will be available at https://github.com/junjun-jiang/BaMBNet.
Inductive Predictions of Extreme Hydrologic Events in The Wabash River Watershed
Apr 25, 2021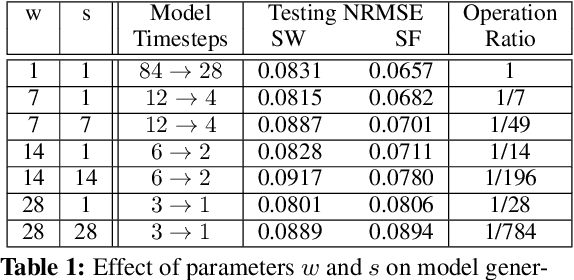
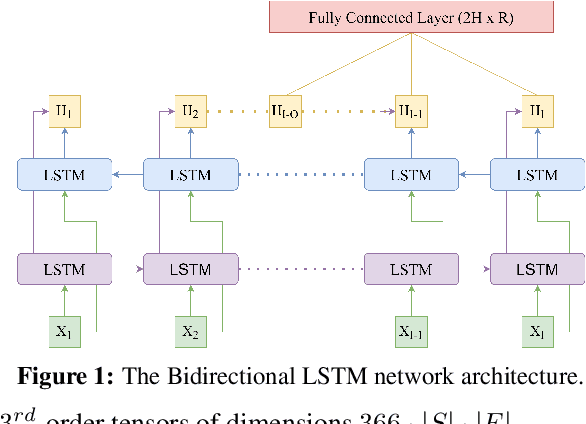
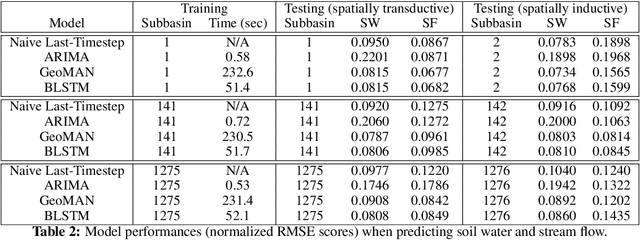
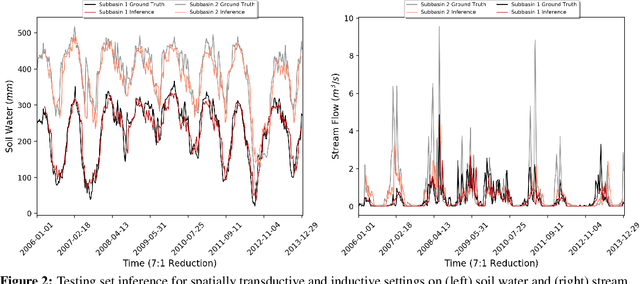
We present a machine learning method to predict extreme hydrologic events from spatially and temporally varying hydrological and meteorological data. We used a timestep reduction technique to reduce the computational and memory requirements and trained a bidirection LSTM network to predict soil water and stream flow from time series data observed and simulated over eighty years in the Wabash River Watershed. We show that our simple model can be trained much faster than complex attention networks such as GeoMAN without sacrificing accuracy. Based on the predicted values of soil water and stream flow, we predict the occurrence and severity of extreme hydrologic events such as droughts. We also demonstrate that extreme events can be predicted in geographical locations separate from locations observed during the training process. This spatially-inductive setting enables us to predict extreme events in other areas in the US and other parts of the world using our model trained with the Wabash Basin data.