 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Architecture Search as Program Transformation Exploration
Feb 12, 2021
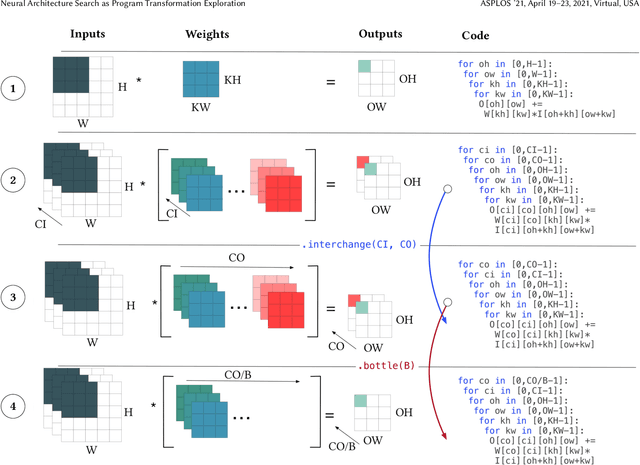
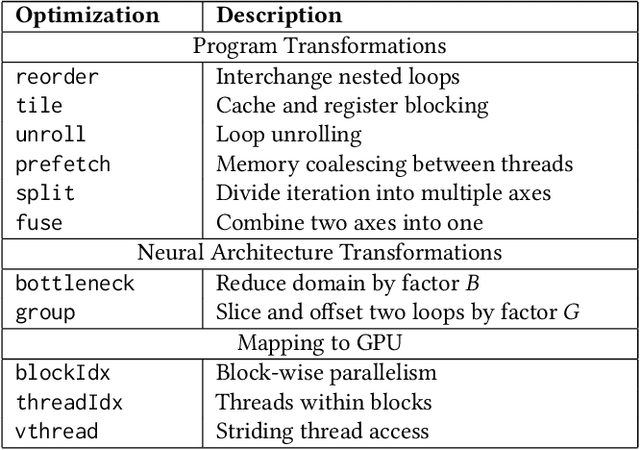
Improving the performance of deep neural networks (DNNs) is important to both the compiler and neural architecture search (NAS) communities. Compilers apply program transformations in order to exploit hardware parallelism and memory hierarchy. However, legality concerns mean they fail to exploit the natural robustness of neural networks. In contrast, NAS techniques mutate networks by operations such as the grouping or bottlenecking of convolutions, exploiting the resilience of DNNs. In this work, we express such neural architecture operations as program transformations whose legality depends on a notion of representational capacity. This allows them to be combined with existing transformations into a unified optimization framework. This unification allows us to express existing NAS operations as combinations of simpler transformations. Crucially, it allows us to generate and explore new tensor convolutions. We prototyped the combined framework in TVM and were able to find optimizations across different DNNs, that significantly reduce inference time - over 3$\times$ in the majority of cases. Furthermore, our scheme dramatically reduces NAS search time. Code is available at~\href{https://github.com/jack-willturner/nas-as-program-transformation-exploration}{this https url}.
Interpretable Vector AutoRegressions with Exogenous Time Series
Nov 09, 2017
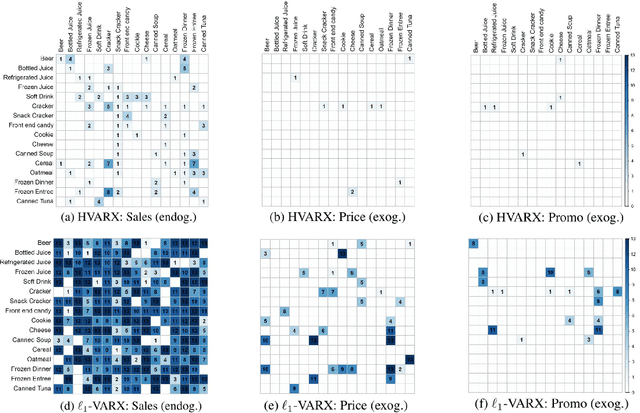
The Vector AutoRegressive (VAR) model is fundamental to the study of multivariate time series. Although VAR models are intensively investigated by many researchers, practitioners often show more interest in analyzing VARX models that incorporate the impact of unmodeled exogenous variables (X) into the VAR. However, since the parameter space grows quadratically with the number of time series, estimation quickly becomes challenging. While several proposals have been made to sparsely estimate large VAR models, the estimation of large VARX models is under-explored. Moreover, typically these sparse proposals involve a lasso-type penalty and do not incorporate lag selection into the estimation procedure. As a consequence, the resulting models may be difficult to interpret. In this paper, we propose a lag-based hierarchically sparse estimator, called "HVARX", for large VARX models. We illustrate the usefulness of HVARX on a cross-category management marketing application. Our results show how it provides a highly interpretable model, and improves out-of-sample forecast accuracy compared to a lasso-type approach.
The Evolution of Rumors on a Closed Platform during COVID-19
Apr 28, 2021
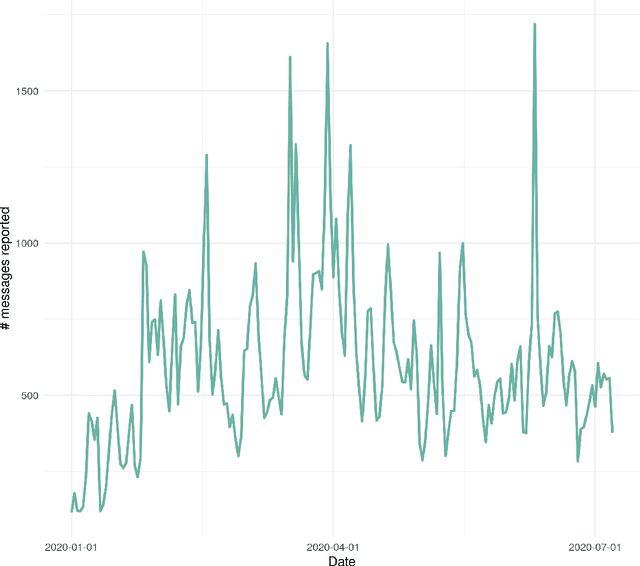
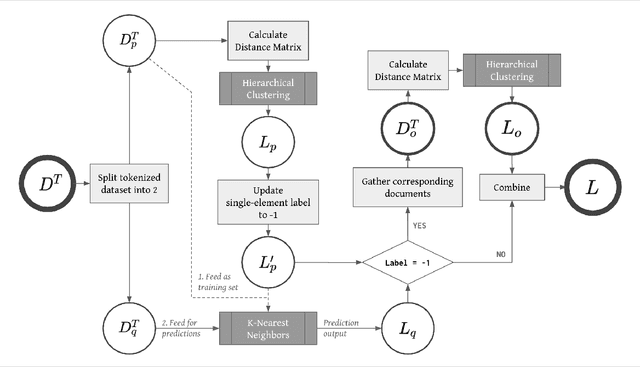
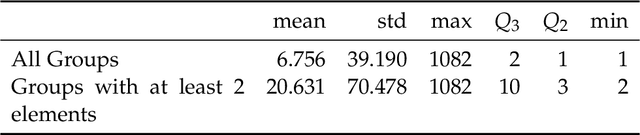
In this work we looked into a dataset of 114 thousands of suspicious messages collected from the most popular closed messaging platform in Taiwan between January and July, 2020. We proposed an hybrid algorithm that could efficiently cluster a large number of text messages according their topics and narratives. That is, we obtained groups of messages that are within a limited content alterations within each other. By employing the algorithm to the dataset, we were able to look at the content alterations and the temporal dynamics of each particular rumor over time. With qualitative case studies of three COVID-19 related rumors, we have found that key authoritative figures were often misquoted in false information. It was an effective measure to increase the popularity of one false information. In addition, fact-check was not effective in stopping misinformation from getting attention. In fact, the popularity of one false information was often more influenced by major societal events and effective content alterations.
EEG-Inception: An Accurate and Robust End-to-End Neural Network for EEG-based Motor Imagery Classification
Jan 24, 2021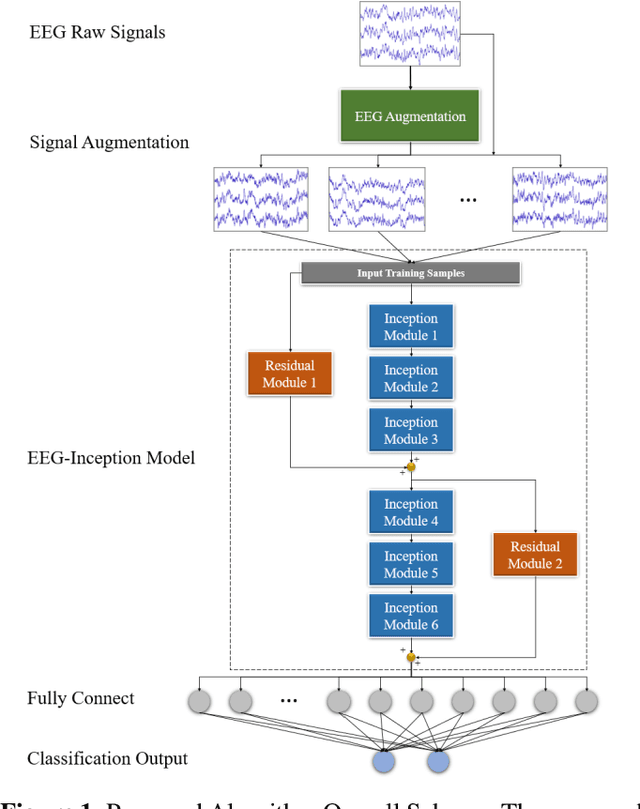

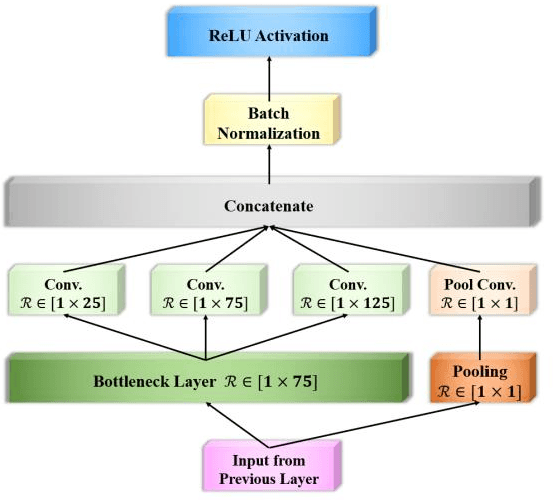
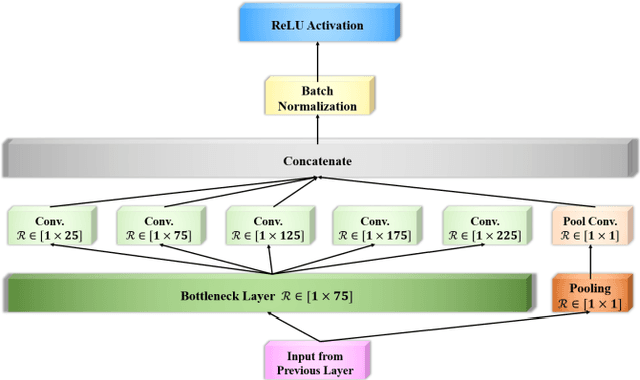
Classification of EEG-based motor imagery (MI) is a crucial non-invasive application in the brain-computer interface (BCI) research. This paper proposes a convolutional neural network (CNN) architecture for accurate and robust EEG-based MI classification that outperforms the state-of-the-art methods. The proposed CNN model, namely EEG-Inception, is built on the backbone of the Inception-Time network, which showed to be highly efficient and accurate for time-series classification. Also, the proposed network is an end-to-end classification, for it takes the raw EEG signals as the input and does not require complex EEG signal-preprocessing. Furthermore, this paper proposes a novel data augmentation method for EEG signals to enhance the accuracy, at least by 3%, and reduce overfitting with limited BCI datasets. The proposed model outperformed all the state-of-the-art methods by achieving the average accuracy of 88.4% and 88.6% on the 2008 BCI Competition IV 2a (four-classes) and 2b datasets (binary-classes), respectively. Furthermore, it takes less than 0.025 seconds to test a sample, which is suitable for real-time processing. Moreover, the classification standard deviation for nine different subjects achieved the lowest value of 5.5 for the 2b dataset and 7.1 for the 2a dataset, validating that the proposed method is highly robust. From the experiment results, it can be inferred that the EEG-Inception network exhibits a strong potential as a subject-independent classifier for EEG-based MI tasks.
Self-Weighted Ensemble Method to Adjust the Influence of Individual Models based on Reliability
Apr 09, 2021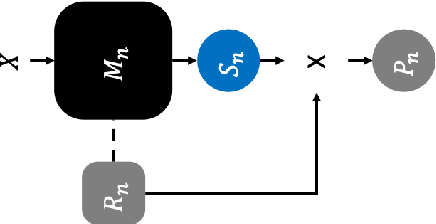

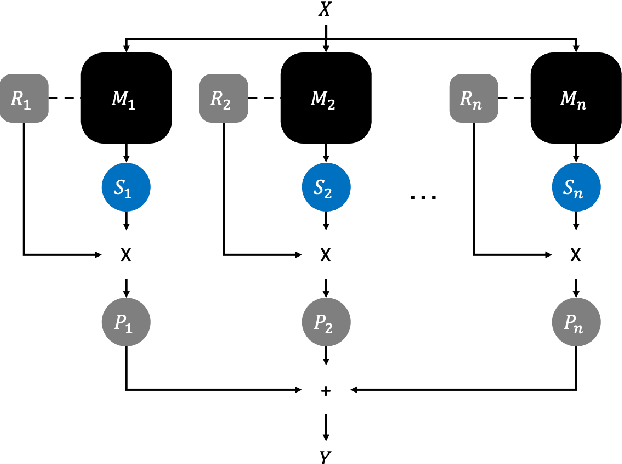
Image classification technology and performance based on Deep Learning have already achieved high standards. Nevertheless, many efforts have conducted to improve the stability of classification via ensembling. However, the existing ensemble method has a limitation in that it requires extra effort including time consumption to find the weight for each model output. In this paper, we propose a simple but improved ensemble method, naming with Self-Weighted Ensemble (SWE), that places the weight of each model via its verification reliability. The proposed ensemble method, SWE, reduces overall efforts for constructing a classification system with varied classifiers. The performance using SWE is 0.033% higher than the conventional ensemble method. Also, the percent of performance superiority to the previous model is up to 73.333% (ratio of 8:22).
Intelligence and Learning in O-RAN for Data-driven NextG Cellular Networks
Dec 02, 2020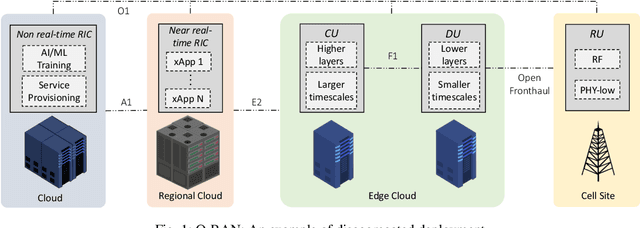
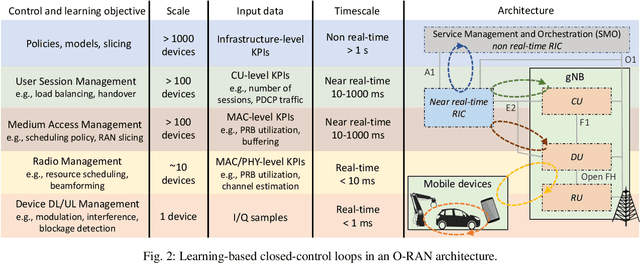
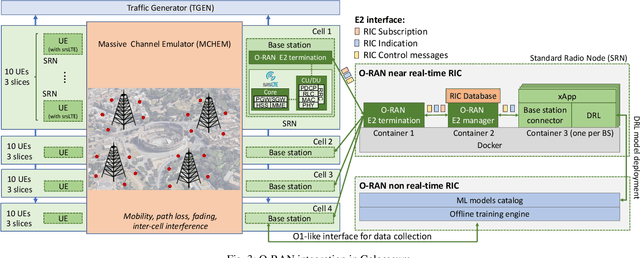
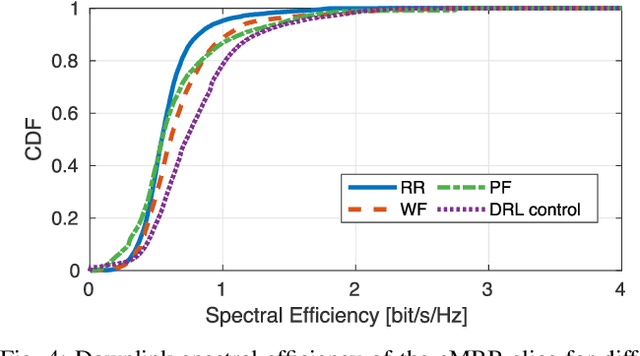
Future, "NextG" cellular networks will be natively cloud-based and built upon programmable, virtualized, and disaggregated architectures. The separation of control functions from the hardware fabric and the introduction of standardized control interfaces will enable the definition of custom closed-control loops, which will ultimately enable embedded intelligence and real-time analytics, thus effectively realizing the vision of autonomous and self-optimizing networks. This article explores the NextG disaggregated architecture proposed by the O-RAN Alliance. Within this architectural context, it discusses potential, challenges, and limitations of data-driven optimization approaches to network control over different timescales. It also provides the first large-scale demonstration of the integration of O-RAN-compliant software components with an open-source full-stack softwarized cellular network. Experiments conducted on Colosseum, the world's largest wireless network emulator, demonstrate closed-loop integration of real-time analytics and control through deep reinforcement learning agents. We also demonstrate for the first time Radio Access Network (RAN) control through xApps running on the near real-time RAN Intelligent Controller (RIC), to optimize the scheduling policies of co-existing network slices, leveraging O-RAN open interfaces to collect data at the edge of the network.
Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
Jun 27, 2020
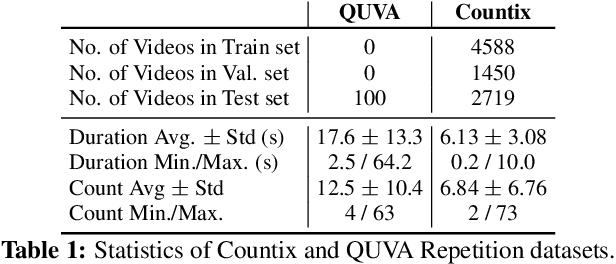


We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google.com/view/repnet .
A Monotone Approximate Dynamic Programming Approach for the Stochastic Scheduling, Allocation, and Inventory Replenishment Problem: Applications to Drone and Electric Vehicle Battery Swap Stations
May 14, 2021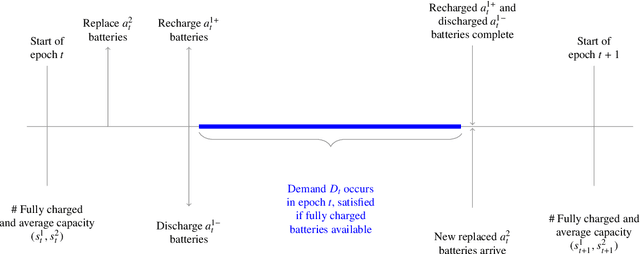

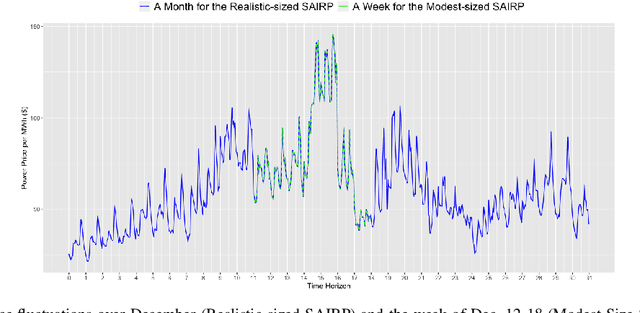
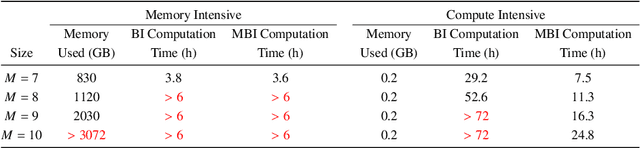
There is a growing interest in using electric vehicles (EVs) and drones for many applications. However, battery-oriented issues, including range anxiety and battery degradation, impede adoption. Battery swap stations are one alternative to reduce these concerns that allow the swap of depleted for full batteries in minutes. We consider the problem of deriving actions at a battery swap station when explicitly considering the uncertain arrival of swap demand, battery degradation, and replacement. We model the operations at a battery swap station using a finite horizon Markov Decision Process model for the stochastic scheduling, allocation, and inventory replenishment problem (SAIRP), which determines when and how many batteries are charged, discharged, and replaced over time. We present theoretical proofs for the monotonicity of the value function and monotone structure of an optimal policy for special SAIRP cases. Due to the curses of dimensionality, we develop a new monotone approximate dynamic programming (ADP) method, which intelligently initializes a value function approximation using regression. In computational tests, we demonstrate the superior performance of the new regression-based monotone ADP method as compared to exact methods and other monotone ADP methods. Further, with the tests, we deduce policy insights for drone swap stations.
Distilling Knowledge via Knowledge Review
Apr 19, 2021
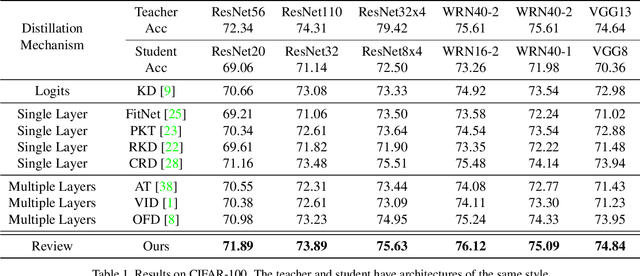
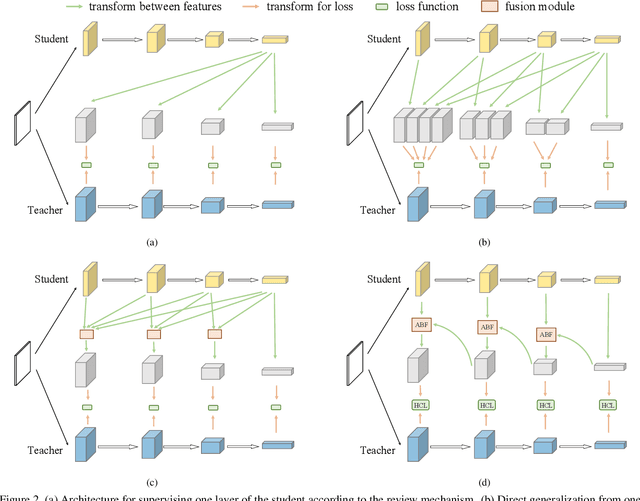
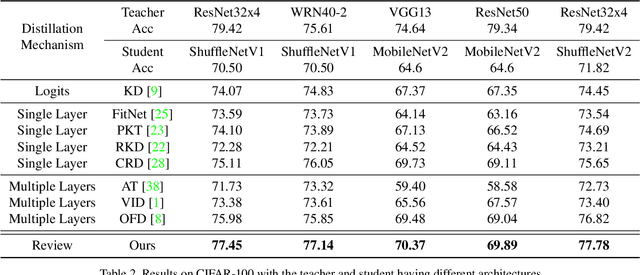
Knowledge distillation transfers knowledge from the teacher network to the student one, with the goal of greatly improving the performance of the student network. Previous methods mostly focus on proposing feature transformation and loss functions between the same level's features to improve the effectiveness. We differently study the factor of connection path cross levels between teacher and student networks, and reveal its great importance. For the first time in knowledge distillation, cross-stage connection paths are proposed. Our new review mechanism is effective and structurally simple. Our finally designed nested and compact framework requires negligible computation overhead, and outperforms other methods on a variety of tasks. We apply our method to classification, object detection, and instance segmentation tasks. All of them witness significant student network performance improvement. Code is available at https://github.com/Jia-Research-Lab/ReviewKD
Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
May 28, 2021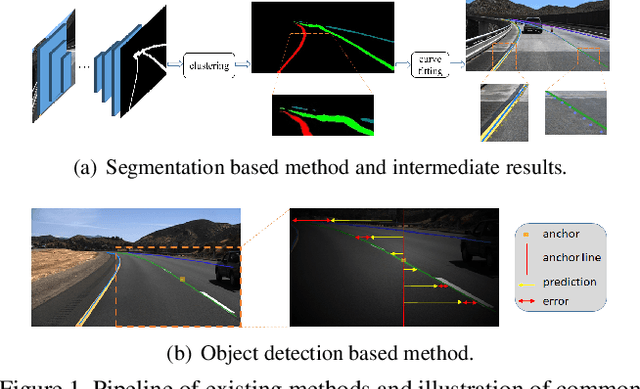
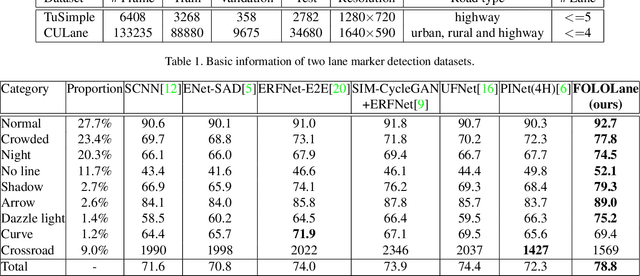
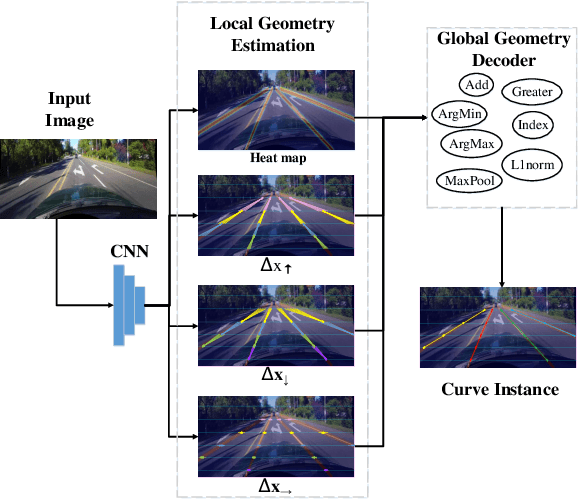

Mainstream lane marker detection methods are implemented by predicting the overall structure and deriving parametric curves through post-processing. Complex lane line shapes require high-dimensional output of CNNs to model global structures, which further increases the demand for model capacity and training data. In contrast, the locality of a lane marker has finite geometric variations and spatial coverage. We propose a novel lane marker detection solution, FOLOLane, that focuses on modeling local patterns and achieving prediction of global structures in a bottom-up manner. Specifically, the CNN models lowcomplexity local patterns with two separate heads, the first one predicts the existence of key points, and the second refines the location of key points in the local range and correlates key points of the same lane line. The locality of the task is consistent with the limited FOV of the feature in CNN, which in turn leads to more stable training and better generalization. In addition, an efficiency-oriented decoding algorithm was proposed as well as a greedy one, which achieving 36% runtime gains at the cost of negligible performance degradation. Both of the two decoders integrated local information into the global geometry of lane markers. In the absence of a complex network architecture design, the proposed method greatly outperforms all existing methods on public datasets while achieving the best state-of-the-art results and real-time processing simultaneously.