 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph Deep Factors for Forecasting
Oct 14, 2020
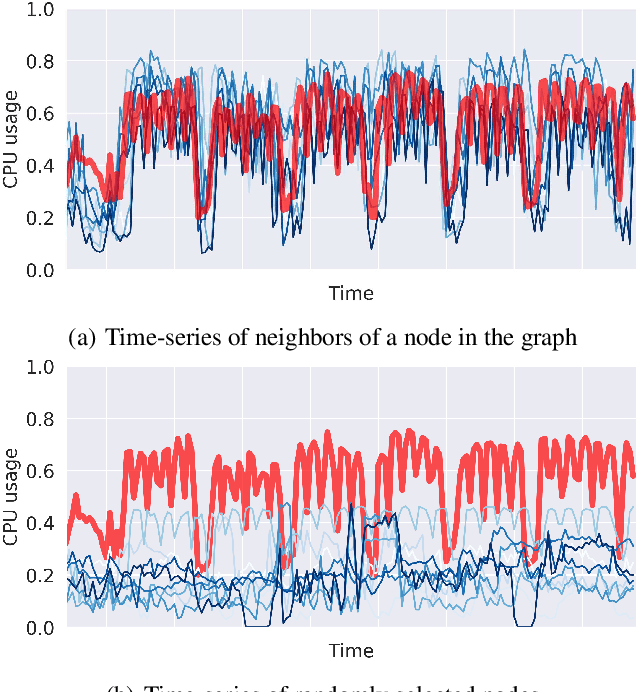
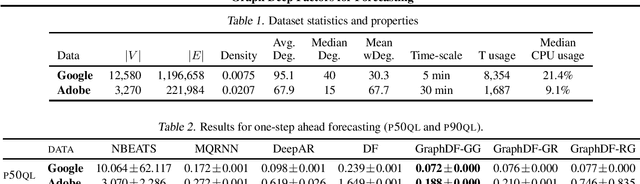

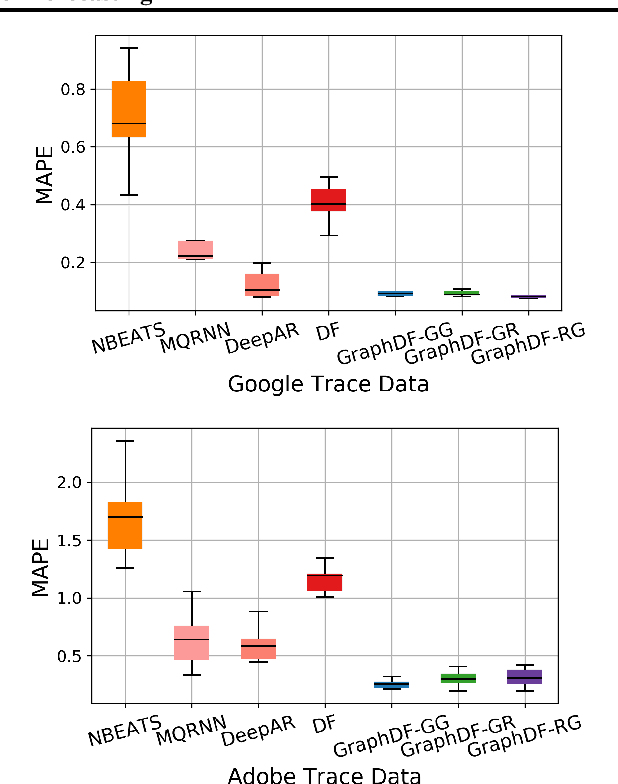
Deep probabilistic forecasting techniques have recently been proposed for modeling large collections of time-series. However, these techniques explicitly assume either complete independence (local model) or complete dependence (global model) between time-series in the collection. This corresponds to the two extreme cases where every time-series is disconnected from every other time-series in the collection or likewise, that every time-series is related to every other time-series resulting in a completely connected graph. In this work, we propose a deep hybrid probabilistic graph-based forecasting framework called Graph Deep Factors (GraphDF) that goes beyond these two extremes by allowing nodes and their time-series to be connected to others in an arbitrary fashion. GraphDF is a hybrid forecasting framework that consists of a relational global and relational local model. In particular, we propose a relational global model that learns complex non-linear time-series patterns globally using the structure of the graph to improve both forecasting accuracy and computational efficiency. Similarly, instead of modeling every time-series independently, we learn a relational local model that not only considers its individual time-series but also the time-series of nodes that are connected in the graph. The experiments demonstrate the effectiveness of the proposed deep hybrid graph-based forecasting model compared to the state-of-the-art methods in terms of its forecasting accuracy, runtime, and scalability. Our case study reveals that GraphDF can successfully generate cloud usage forecasts and opportunistically schedule workloads to increase cloud cluster utilization by 47.5% on average.
D2S: Document-to-Slide Generation Via Query-Based Text Summarization
May 08, 2021
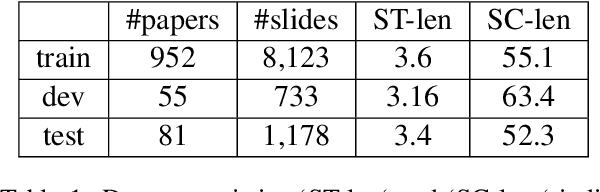

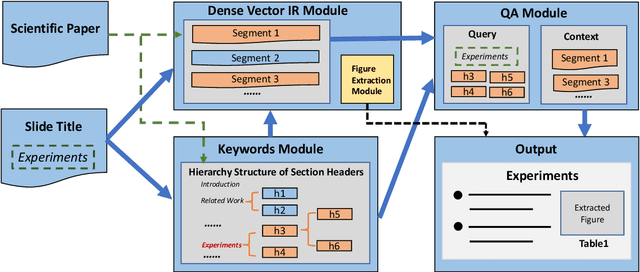
Presentations are critical for communication in all areas of our lives, yet the creation of slide decks is often tedious and time-consuming. There has been limited research aiming to automate the document-to-slides generation process and all face a critical challenge: no publicly available dataset for training and benchmarking. In this work, we first contribute a new dataset, SciDuet, consisting of pairs of papers and their corresponding slides decks from recent years' NLP and ML conferences (e.g., ACL). Secondly, we present D2S, a novel system that tackles the document-to-slides task with a two-step approach: 1) Use slide titles to retrieve relevant and engaging text, figures, and tables; 2) Summarize the retrieved context into bullet points with long-form question answering. Our evaluation suggests that long-form QA outperforms state-of-the-art summarization baselines on both automated ROUGE metrics and qualitative human evaluation.
Learning a Compact State Representation for Navigation Tasks by Autoencoding 2D-Lidar Scans
Feb 03, 2021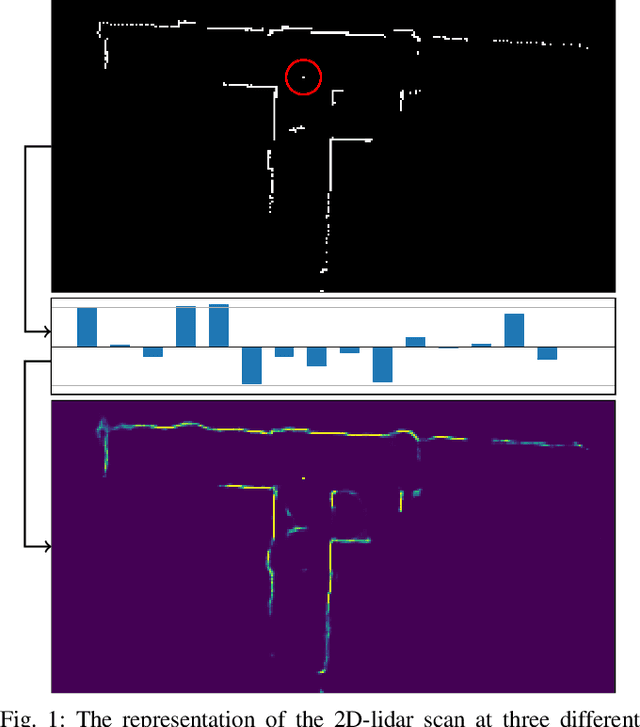
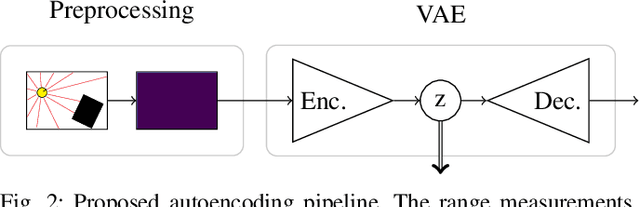
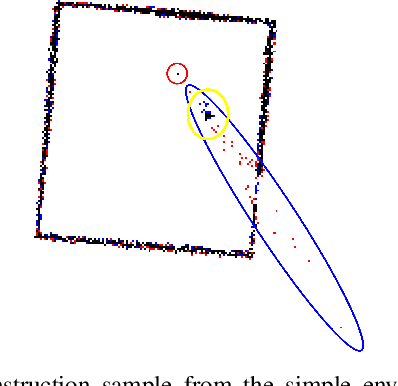
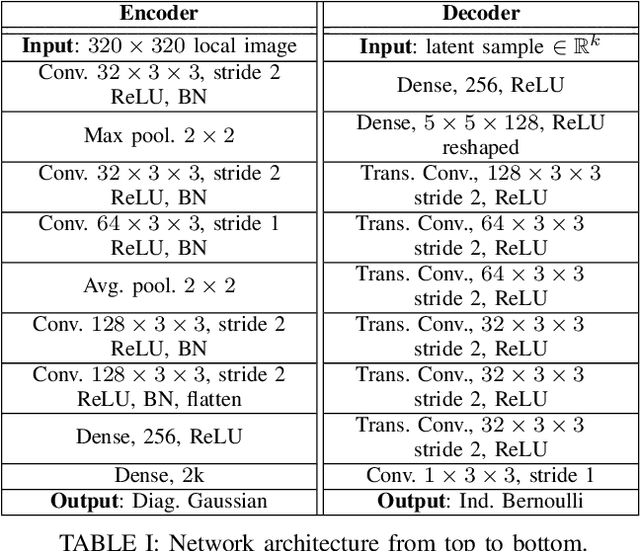
In this paper, we address the problem of generating a compact representation of 2D-lidar scans for reinforcement learning in navigation tasks. By now only little work focuses on the compactness of the provided state, which is a necessary condition to successfully and efficiently train a navigation agent. Our approach works in three stages. First, we propose a novel preprocessing of the distance measurements and compute a local, egocentric, binary grid map based on the current range measurements. We then autoencode the local map using a variational autoencoder, where the latent space serves as state representation. An important key for a compact and, at the same time, meaningful representation is the degree of disentanglement, which describes the correlation between each latent dimension. Therefore, we finally apply state-of-the-art disentangling methods to improve the representation power. Furthermore, we investige the possibilities of incorporating time-dependent information into the latent space. In particular, we incorporate the relation of consecutive scans, especially ego-motion, by applying a memory model. We implemented our approach in python using tensorflow. Our datasets are simulated with pybullet as well as recorded using a slamtec rplidar A3. The experiments show the capability of our approach to highly compress lidar data, maintain a meaningful distribution of the latent space, and even incorporate time-depended information.
Massive Self-Assembly in Grid Environments
Feb 05, 2021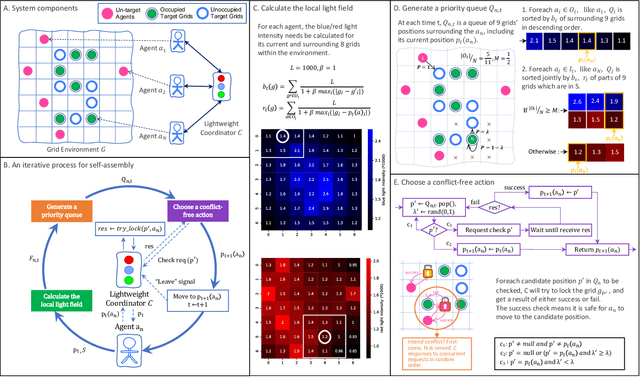
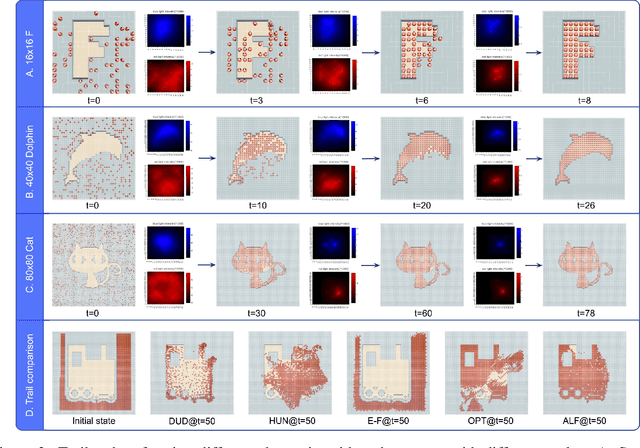
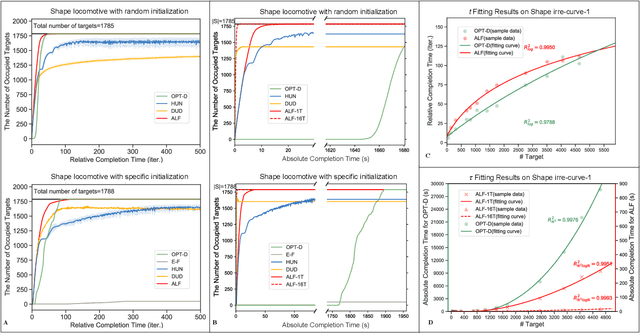
Self-assembly plays an essential role in many natural processes, involving the formation and evolution of living or non-living structures, and shows potential applications in many emerging domains. In existing research and practice, there still lacks an ideal self-assembly mechanism that manifests efficiency, scalability, and stability at the same time. Inspired by phototaxis observed in nature, we propose a computational approach for massive self-assembly of connected shapes in grid environments. The key component of this approach is an artificial light field superimposed on a grid environment, which is determined by the positions of all agents and at the same time drives all agents to further change their positions, forming a dynamic mutual feedback process. This work advances the understanding and potential applications of self-assembly.
Videos as Space-Time Region Graphs
Jun 05, 2018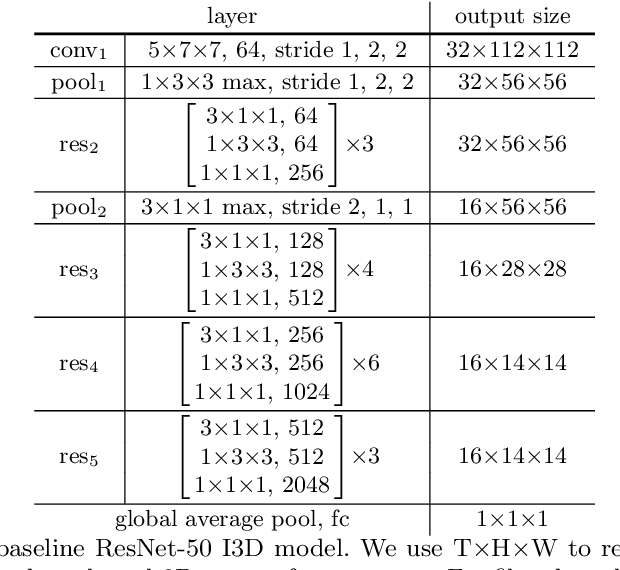
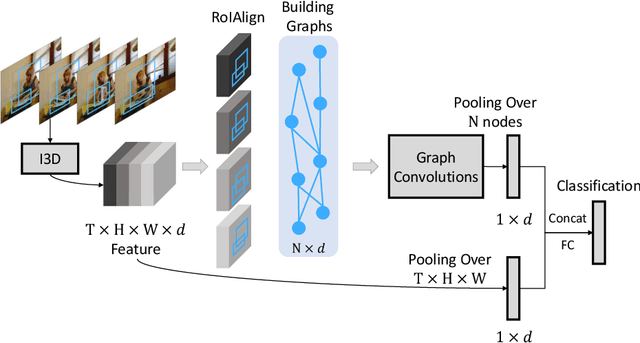


How do humans recognize the action "opening a book" ? We argue that there are two important cues: modeling temporal shape dynamics and modeling functional relationships between humans and objects. In this paper, we propose to represent videos as space-time region graphs which capture these two important cues. Our graph nodes are defined by the object region proposals from different frames in a long range video. These nodes are connected by two types of relations: (i) similarity relations capturing the long range dependencies between correlated objects and (ii) spatial-temporal relations capturing the interactions between nearby objects. We perform reasoning on this graph representation via Graph Convolutional Networks. We achieve state-of-the-art results on both Charades and Something-Something datasets. Especially for Charades, we obtain a huge 4.4% gain when our model is applied in complex environments.
Simple Agent, Complex Environment: Efficient Reinforcement Learning with Agent State
Mar 08, 2021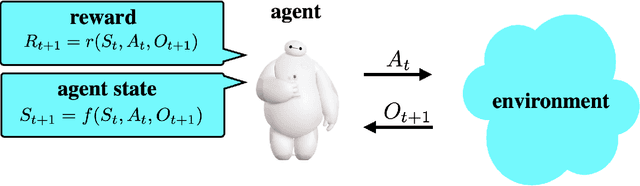
We design a simple reinforcement learning agent that, with a specification only of agent state dynamics and a reward function, can operate with some degree of competence in any environment. The agent maintains only visitation counts and value estimates for each agent-state-action pair. The value function is updated incrementally in response to temporal differences and optimistic boosts that encourage exploration. The agent executes actions that are greedy with respect to this value function. We establish a regret bound demonstrating convergence to near-optimal per-period performance, where the time taken to achieve near-optimality is polynomial in the number of agent states and actions, as well as the reward mixing time of the best policy within the reference policy class, which is comprised of those that depend on history only through agent state. Notably, there is no further dependence on the number of environment states or mixing times associated with other policies or statistics of history. Our result sheds light on the potential benefits of (deep) representation learning, which has demonstrated the capability to extract compact and relevant features from high-dimensional interaction histories.
Neural Network Surrogate Models for Absorptivity and Emissivity Spectra of Multiple Elements
Jun 04, 2021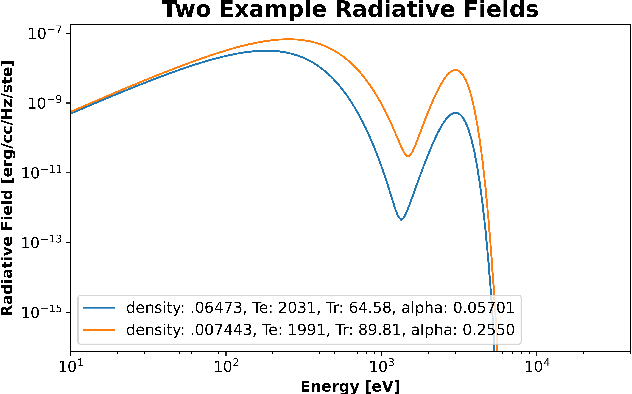

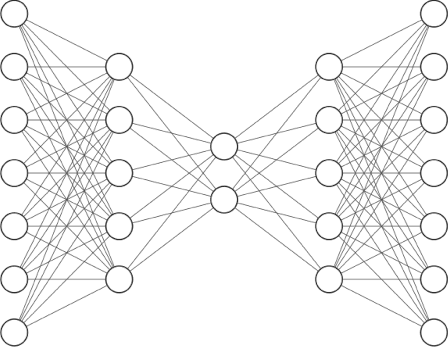

Simulations of high energy density physics are expensive in terms of computational resources. In particular, the computation of opacities of plasmas, which are needed to accurately compute radiation transport in the non-local thermal equilibrium (NLTE) regime, are expensive to the point of easily requiring multiple times the sum-total compute time of all other components of the simulation. As such, there is great interest in finding ways to accelerate NLTE computations. Previous work has demonstrated that a combination of fully-connected autoencoders and a deep jointly-informed neural network (DJINN) can successfully replace the standard NLTE calculations for the opacity of krypton. This work expands this idea to multiple elements in demonstrating that individual surrogate models can be also be generated for other elements with the focus being on creating autoencoders that can accurately encode and decode the absorptivity and emissivity spectra. Furthermore, this work shows that multiple elements across a large range of atomic numbers can be combined into a single autoencoder when using a convolutional autoencoder while maintaining accuracy that is comparable to individual fully-connected autoencoders. Lastly, it is demonstrated that DJINN can effectively learn the latent space of a convolutional autoencoder that can encode multiple elements allowing the combination to effectively function as a surrogate model.
Efficient Online Trajectory Planning for Integrator Chain Dynamics using Polynomial Elimination
Dec 13, 2020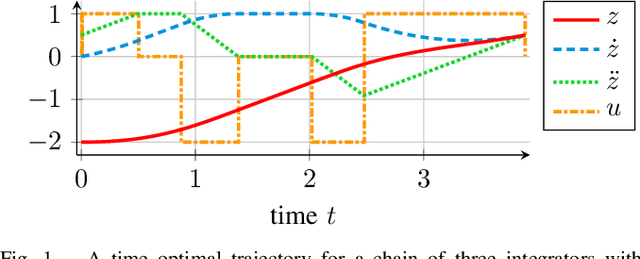
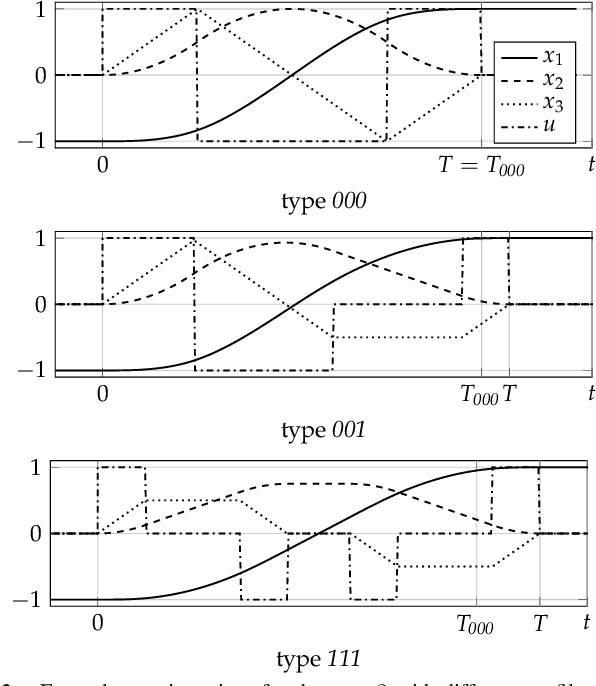
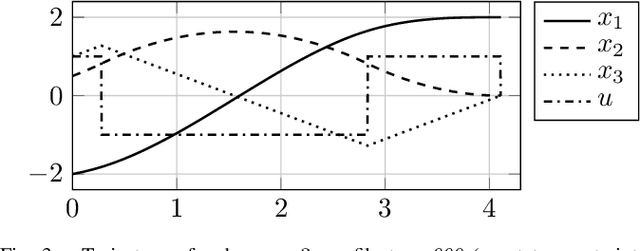
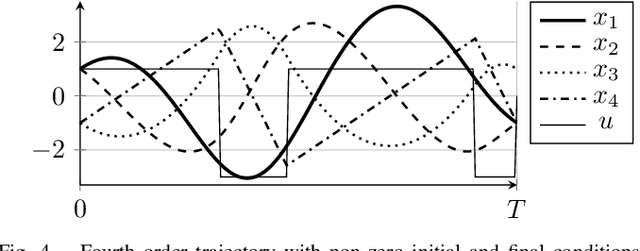
Providing smooth reference trajectories can effectively increase performance and accuracy of tracking control applications while overshoot and unwanted vibrations are reduced. Trajectory planning computations can often be simplified significantly by transforming the system dynamics into decoupled integrator chains using methods such as feedback linearization, differential flatness or the controller canonical form. We present an efficient method to plan time optimal trajectories for integrator chains subject to derivative bound constraints. Therefore, an algebraic precomputation algorithm formulates the necessary conditions for time optimality in form of a set of polynomial systems, followed by a symbolic polynomial elimination using Gr\"obner bases. A fast online algorithm then plans the trajectories by calculating the roots of the decomposed polynomial systems. These roots describe the switching time instants of the input signal and the full trajectory simply follows by multiple integration. This method presents a systematic way to compute time optimal trajectories exactly via algebraic calculations without numerical approximation iterations. It is applied to various trajectory types with different continuity order, asymmetric derivative bounds and non-rest initial and final states.
Selective Survey: Most Efficient Models and Solvers for Integrative Multimodal Transport
Mar 16, 2021In the family of Intelligent Transportation Systems (ITS), Multimodal Transport Systems (MMTS) have placed themselves as a mainstream transportation mean of our time as a feasible integrative transportation process. The Global Economy progressed with the help of transportation. The volume of goods and distances covered have doubled in the last ten years, so there is a high demand of an optimized transportation, fast but with low costs, saving resources but also safe, with low or zero emissions. Thus, it is important to have an overview of existing research in this field, to know what was already done and what is to be studied next. The main objective is to explore a beneficent selection of the existing research, methods and information in the field of multimodal transportation research, to identify industry needs and gaps in research and provide context for future research. The selective survey covers multimodal transport design and optimization in terms of: cost, time, and network topology. The multimodal transport theoretical aspects, context and resources are also covering various aspects. The survey's selection includes nowadays best methods and solvers for Intelligent Transportation Systems (ITS). The gap between theory and real-world applications should be further solved in order to optimize the global multimodal transportation system.
Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking
May 21, 2021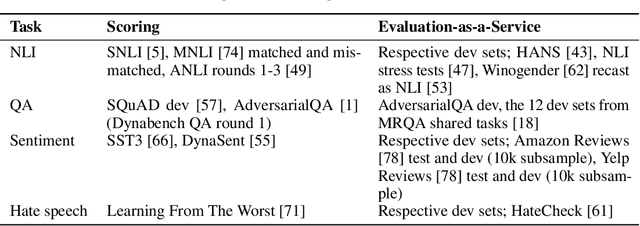
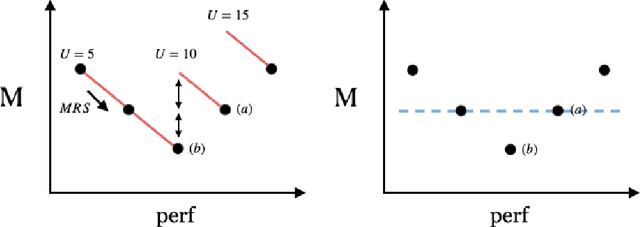
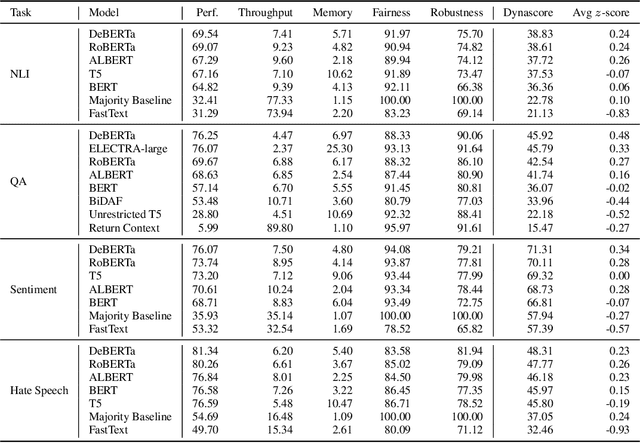
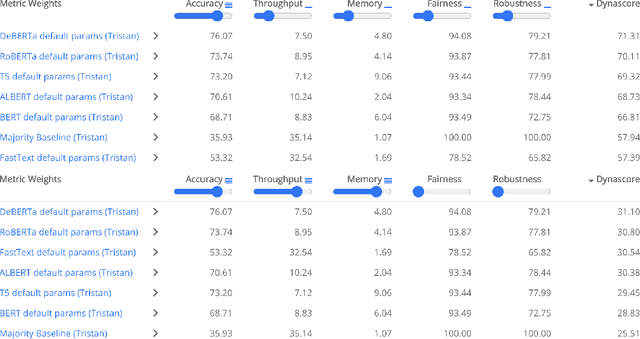
We introduce Dynaboard, an evaluation-as-a-service framework for hosting benchmarks and conducting holistic model comparison, integrated with the Dynabench platform. Our platform evaluates NLP models directly instead of relying on self-reported metrics or predictions on a single dataset. Under this paradigm, models are submitted to be evaluated in the cloud, circumventing the issues of reproducibility, accessibility, and backwards compatibility that often hinder benchmarking in NLP. This allows users to interact with uploaded models in real time to assess their quality, and permits the collection of additional metrics such as memory use, throughput, and robustness, which -- despite their importance to practitioners -- have traditionally been absent from leaderboards. On each task, models are ranked according to the Dynascore, a novel utility-based aggregation of these statistics, which users can customize to better reflect their preferences, placing more/less weight on a particular axis of evaluation or dataset. As state-of-the-art NLP models push the limits of traditional benchmarks, Dynaboard offers a standardized solution for a more diverse and comprehensive evaluation of model quality.