 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning for Sensor-Based Navigation
Aug 30, 2021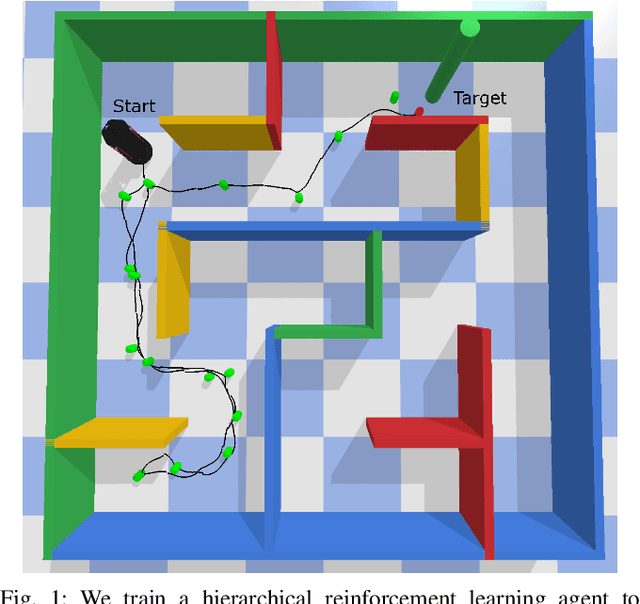
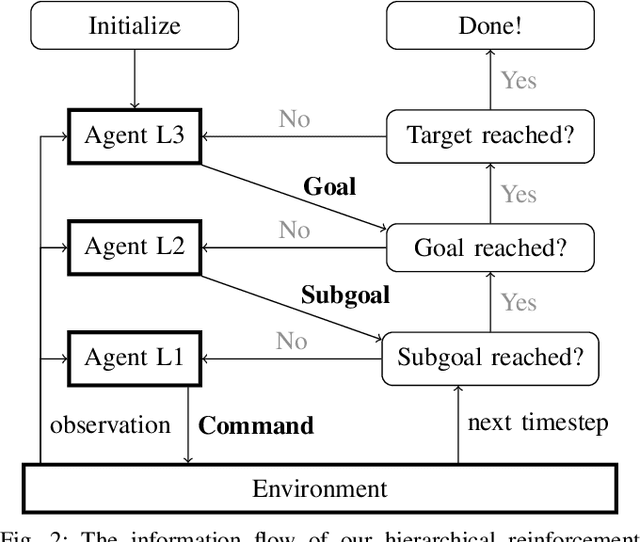
Robotic systems are nowadays capable of solving complex navigation tasks under real-world conditions. However, their capabilities are intrinsically limited to the imagination of the designer and consequently lack generalizability to initially unconsidered situations. This makes deep reinforcement learning especially interesting, as these algorithms promise a self-learning system only relying on feedback from the environment. Having the system itself search for an optimal solution brings the benefit of great generalization or even constant improvement when life-long learning is addressed. In this paper, we address robot navigation in continuous action space using deep hierarchical reinforcement learning without including the target location in the state representation. Our agent self-assigns internal goals and learns to extract reasonable waypoints to reach the desired target position only based on local sensor data. In our experiments we demonstrate that our hierarchical structure improves the performance of the navigation agent in terms of collected reward and success rate in comparison to a flat structure, while not requiring any global or target information.
The Pitfall of More Powerful Autoencoders in Lidar-Based Navigation
Mar 08, 2021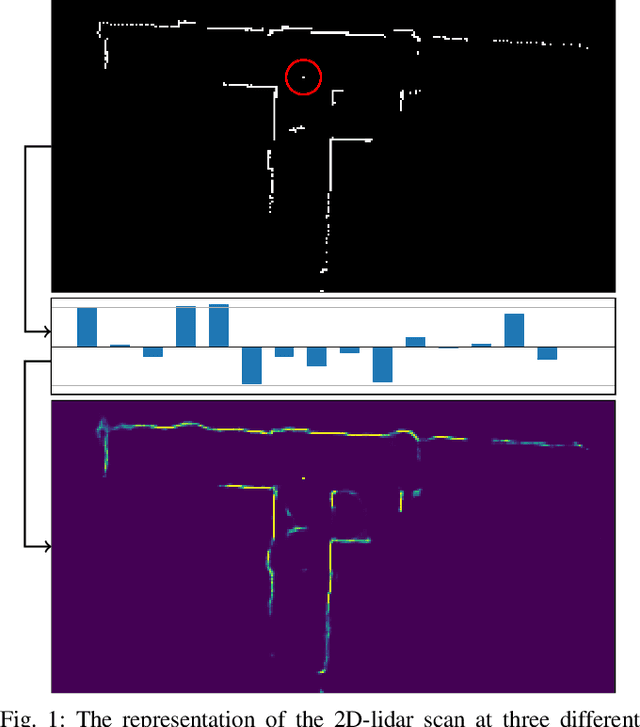
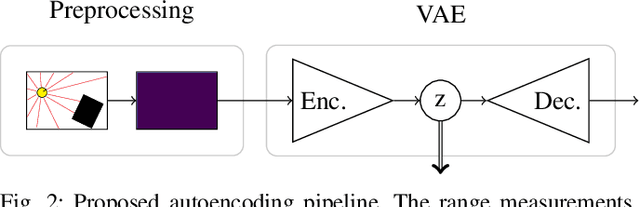
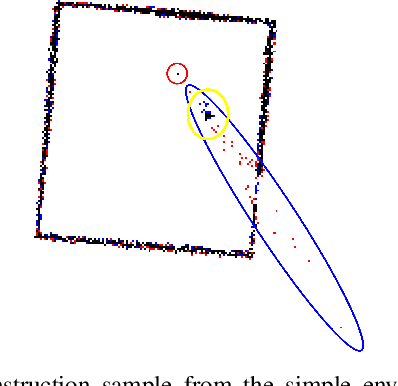
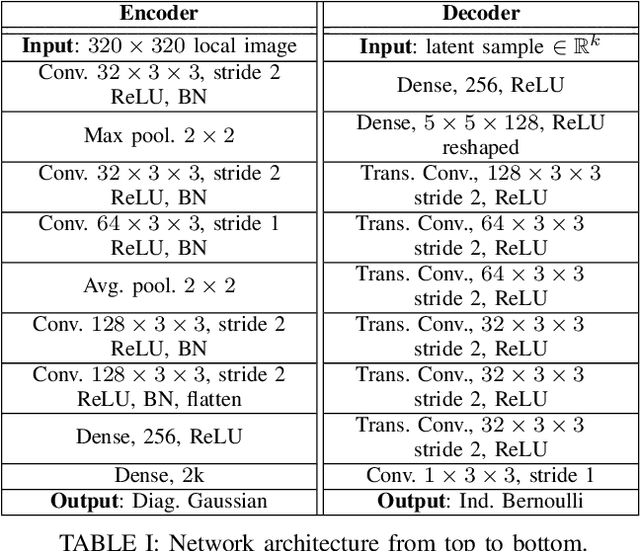
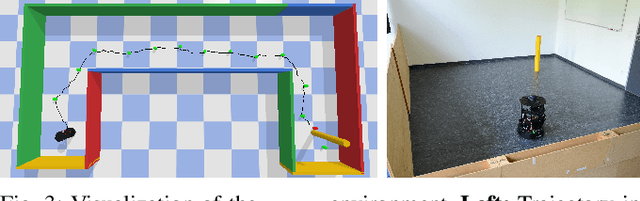
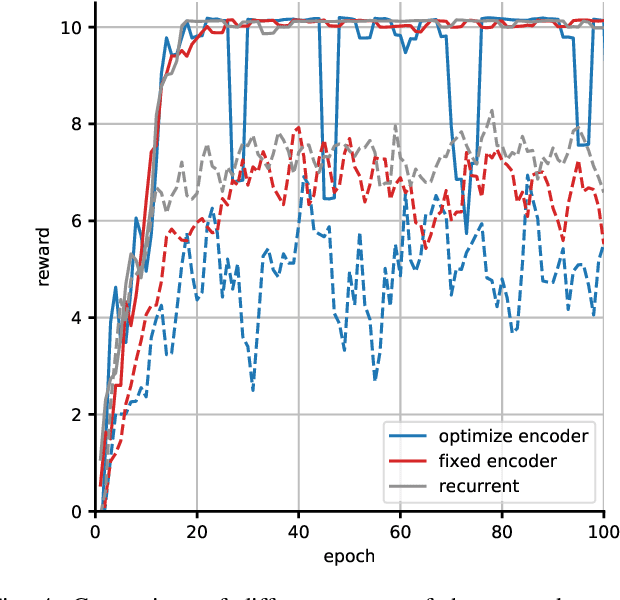
The benefit of pretrained autoencoders for reinforcement learning in comparison to training on raw observations is already known [1]. In this paper, we address the generation of a compact and information-rich state representation. In particular, we train a variational autoencoder for 2D-lidar scans to use its latent state for reinforcement learning of navigation tasks. To achieve high reconstruction power of our autoencoding pipeline, we propose an - in the context of autoencoding 2D-lidar scans - novel preprocessing into a local binary occupancy image. This has no additional requirements, neither self-localization nor robust mapping, and therefore can be applied in any setting and easily transferred from simulation in real-world. In a second stage, we show the usage of the compact state representation generated by our autoencoding pipeline in a simplistic navigation task and expose the pitfall that increased reconstruction power will always lead to an improved performance. We implemented our approach in python using tensorflow. Our datasets are simulated with pybullet as well as recorded using a slamtec rplidar A3. The experiments show the significantly improved reconstruction capabilities of our approach for 2D-lidar scans w.r.t. the state of the art. However, as we demonstrate in the experiments the impact on reinforcement learning in lidar-based navigation tasks is non-predictable when improving the latent state representation generated by an autoencoding pipeline. This is surprising and needs to be taken into account during the process of optimizing a pretrained autoencoder for reinforcement learning tasks.