 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Agent, Complex Environment: Efficient Reinforcement Learning with Agent State
Paper and Code
Mar 08, 2021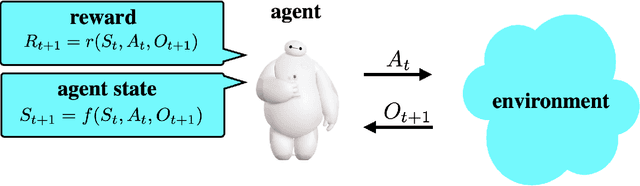
We design a simple reinforcement learning agent that, with a specification only of agent state dynamics and a reward function, can operate with some degree of competence in any environment. The agent maintains only visitation counts and value estimates for each agent-state-action pair. The value function is updated incrementally in response to temporal differences and optimistic boosts that encourage exploration. The agent executes actions that are greedy with respect to this value function. We establish a regret bound demonstrating convergence to near-optimal per-period performance, where the time taken to achieve near-optimality is polynomial in the number of agent states and actions, as well as the reward mixing time of the best policy within the reference policy class, which is comprised of those that depend on history only through agent state. Notably, there is no further dependence on the number of environment states or mixing times associated with other policies or statistics of history. Our result sheds light on the potential benefits of (deep) representation learning, which has demonstrated the capability to extract compact and relevant features from high-dimensional interaction histories.