 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Canonical Correlation Alignment for Sensor Signals
Jun 07, 2021
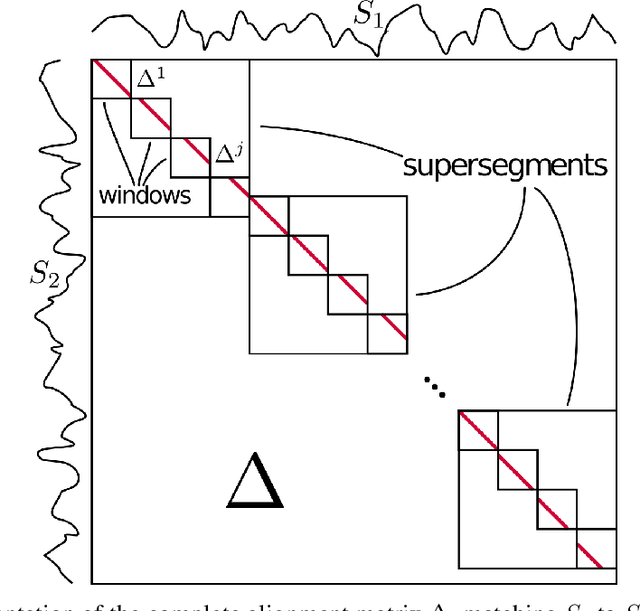
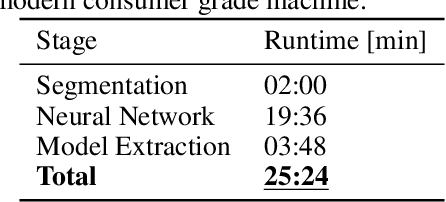
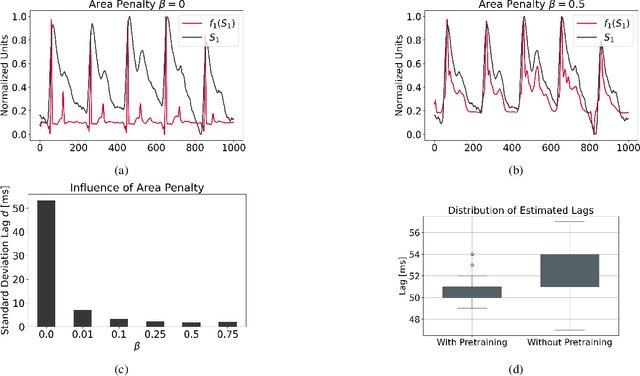

Sensor technology is becoming increasingly prevalent across a multitude of fields and industries. As a result, simultaneous recordings of multiple inter-correlated signals is becoming increasingly common. With this, more problems of a practical nature emerge due to sensor clock-drift, offsets, and other complications. Processing of multiple sensor data is often dependent on the data being properly aligned in the temporal dimension. The alignment process is a necessary step before the data can be evaluated properly but it is a time consuming process, often involving significant manual labor and expertise. Regularly used methods to align sensor signals have trouble addressing real-world issues such as morphological dissimilarities, excessive noise, or very long, raw sensor signals. In this work, we present Deep Canonical Correlation Sensor Alignment (DCCA), a method that is specifically tailored to address these problems. It exploits common properties specific to misalignments produced by sensor circuitry, such as clock-drift and offsets. On a selection of artificial and real datasets we demonstrate the performance of DCCA under a variety of conditions.
Denoising Single Voxel Magnetic Resonance Spectroscopy with Deep Learning on Repeatedly Sampled In Vivo Data
Jan 26, 2021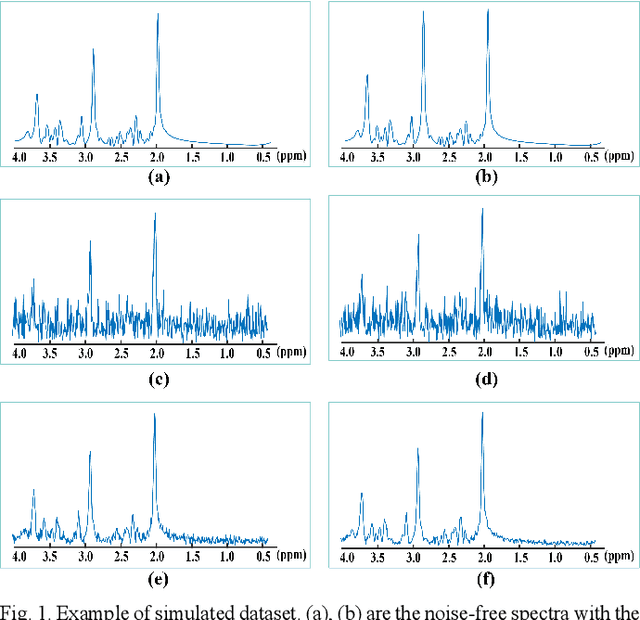
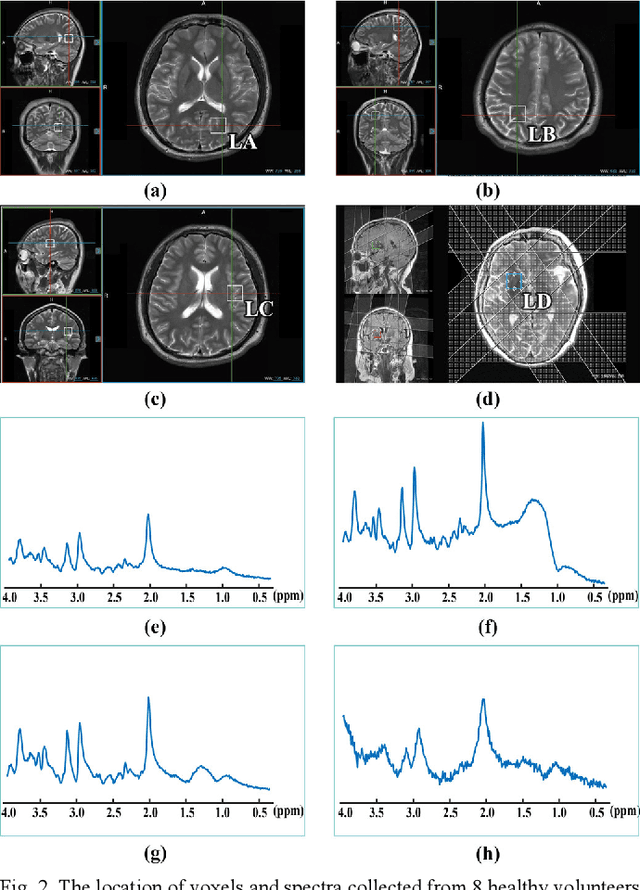
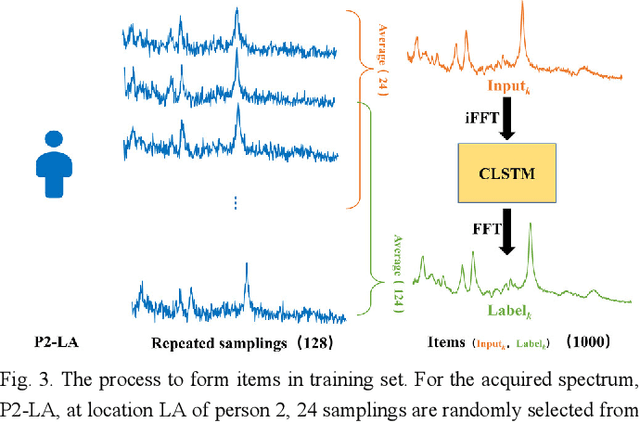
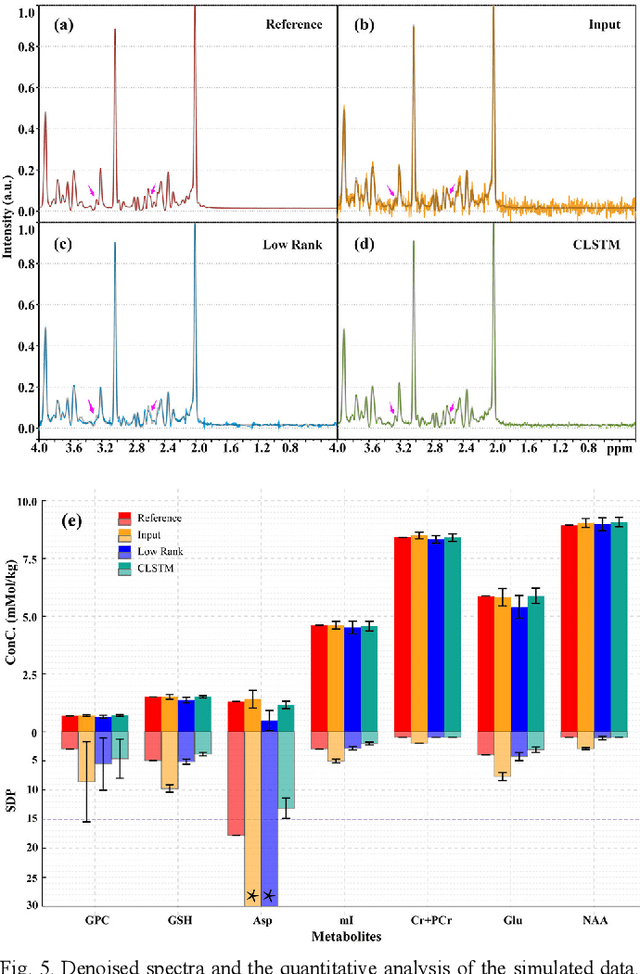
Objective: Magnetic Resonance Spectroscopy (MRS) is a noninvasive tool to reveal metabolic information. One challenge of MRS is the relatively low Signal-Noise Ratio (SNR) due to low concentrations of metabolites. To improve the SNR, the most common approach is to average signals that are acquired in multiple times. The data acquisition time, however, is increased by multiple times accordingly, resulting in the scanned objects uncomfortable or even unbearable. Methods: By exploring the multiple sampled data, a deep learning denoising approach is proposed to learn a mapping from the low SNR signal to the high SNR one. Results: Results on simulated and in vivo data show that the proposed method significantly reduces the data acquisition time with slightly compromised metabolic accuracy. Conclusion: A deep learning denoising method was proposed to significantly shorten the time of data acquisition, while maintaining signal accuracy and reliability. Significance: Provide a solution of the fundamental low SNR problem in MRS with artificial intelligence.
Perceived Safety in Physical Human Robot Interaction -- A Survey
May 30, 2021
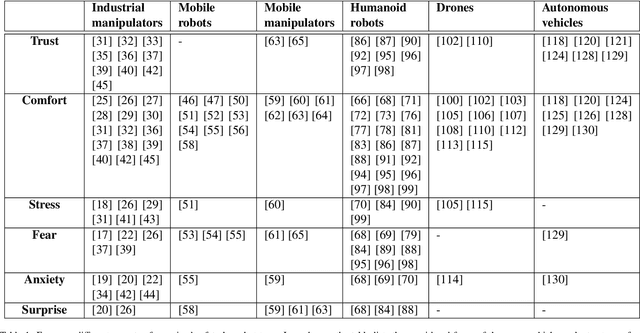
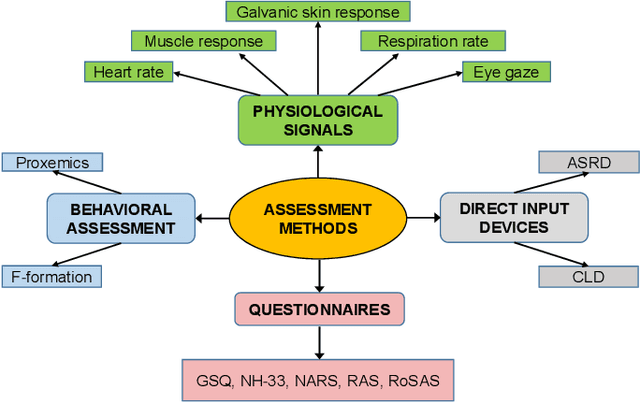
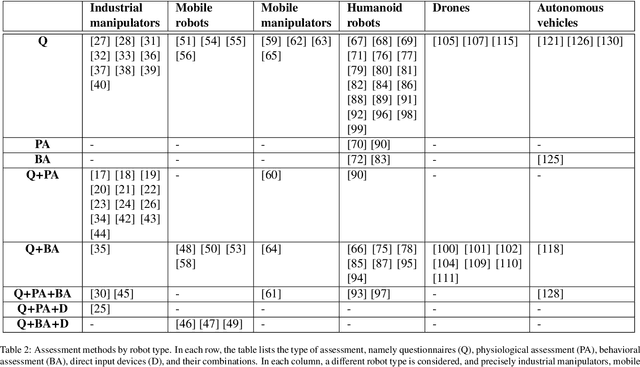
This review paper focuses on different aspects of perceived safety for a number of autonomous physical systems. This is a major aspect of robotics research, as more and more applications allow human and autonomous systems to share their space, with crucial implications both on safety and on its perception. The alternative terms used to express related concepts (e.g., psychological safety, trust, comfort, stress, fear, and anxiety) are listed and explained. Then, the available methods to assess perceived safety (i.e., questionnaires, physiological measurements, behavioral assessment, and direct input devices) are described. Six categories of autonomous systems are considered (industrial manipulators, mobile robots, mobile manipulators, humanoid robots, drones, and autonomous vehicles), providing an overview of the main themes related to perceived safety in the specific domain, a description of selected works, and an analysis of how motion and characteristics of the system influence the perception of safety. The survey also discusses experimental duration and location of the reviewed papers as well as identified trends over time.
Isconna: Streaming Anomaly Detection with Frequency and Patterns
Apr 04, 2021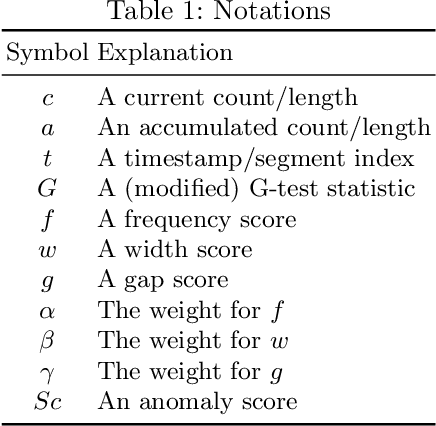
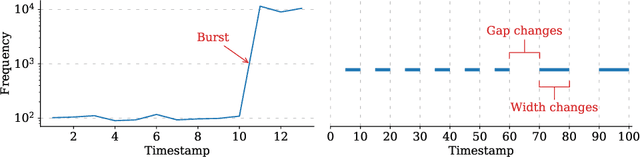
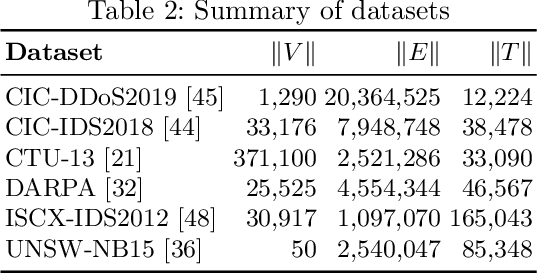
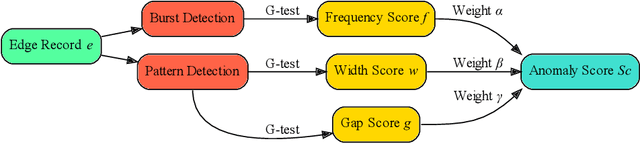
An edge stream is a common form of presentation of dynamic networks. It can evolve with time, with new types of nodes or edges being continuously added. Existing methods for anomaly detection rely on edge occurrence counts or compare pattern snippets found in historical records. In this work, we propose Isconna, which focuses on both the frequency and the pattern of edge records. The burst detection component targets anomalies between individual timestamps, while the pattern detection component highlights anomalies across segments of timestamps. These two components together produce three intermediate scores, which are aggregated into the final anomaly score. Isconna does not actively explore or maintain pattern snippets; it instead measures the consecutive presence and absence of edge records. Isconna is an online algorithm, it does not keep the original information of edge records; only statistical values are maintained in a few count-min sketches (CMS). Isconna's space complexity $O(rc)$ is determined by two user-specific parameters, the size of CMSs. In worst case, Isconna's time complexity can be up to $O(rc)$, but it can be amortized in practice. Experiments show that Isconna outperforms five state-of-the-art frequency- and/or pattern-based baselines on six real-world datasets with up to 20 million edge records.
Linnaeus: A highly reusable and adaptable ML based log classification pipeline
Mar 11, 2021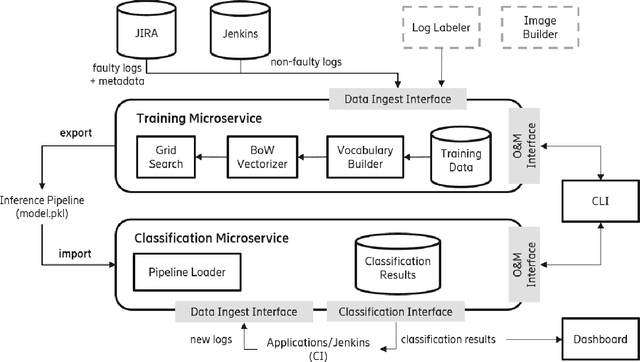
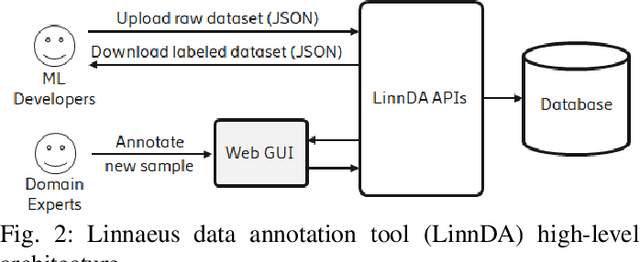
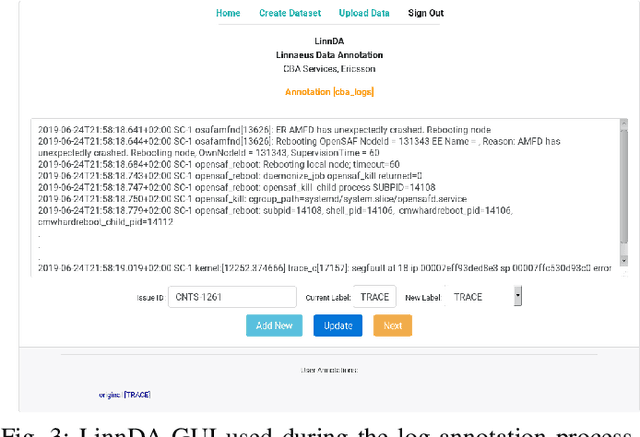
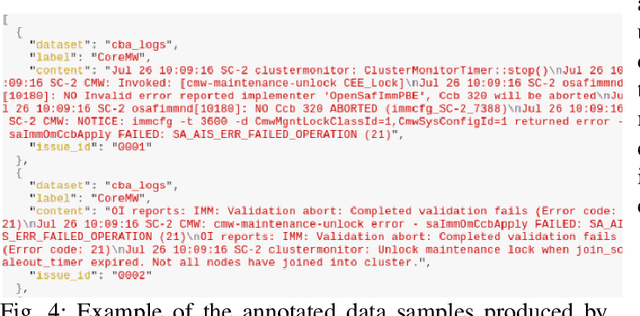
Logs are a common way to record detailed run-time information in software. As modern software systems evolve in scale and complexity, logs have become indispensable to understanding the internal states of the system. At the same time however, manually inspecting logs has become impractical. In recent times, there has been more emphasis on statistical and machine learning (ML) based methods for analyzing logs. While the results have shown promise, most of the literature focuses on algorithms and state-of-the-art (SOTA), while largely ignoring the practical aspects. In this paper we demonstrate our end-to-end log classification pipeline, Linnaeus. Besides showing the more traditional ML flow, we also demonstrate our solutions for adaptability and re-use, integration towards large scale software development processes, and how we cope with lack of labelled data. We hope Linnaeus can serve as a blueprint for, and inspire the integration of, various ML based solutions in other large scale industrial settings.
Temporal Knowledge Graph Forecasting with Neural ODE
Jan 13, 2021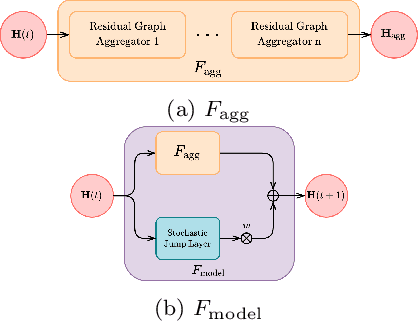

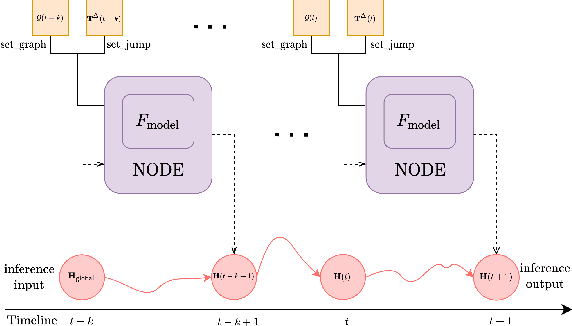

Learning node representation on dynamically-evolving, multi-relational graph data has gained great research interest. However, most of the existing models for temporal knowledge graph forecasting use Recurrent Neural Network (RNN) with discrete depth to capture temporal information, while time is a continuous variable. Inspired by Neural Ordinary Differential Equation (NODE), we extend the idea of continuum-depth models to time-evolving multi-relational graph data, and propose a novel Temporal Knowledge Graph Forecasting model with NODE. Our model captures temporal information through NODE and structural information through a Graph Neural Network (GNN). Thus, our graph ODE model achieves a continuous model in time and efficiently learns node representation for future prediction. We evaluate our model on six temporal knowledge graph datasets by performing link forecasting. Experiment results show the superiority of our model.
Deep Latent Emotion Network for Multi-Task Learning
Apr 18, 2021
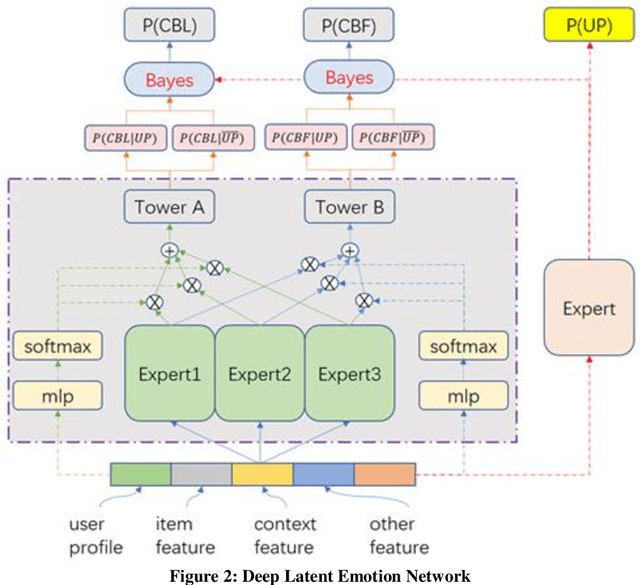

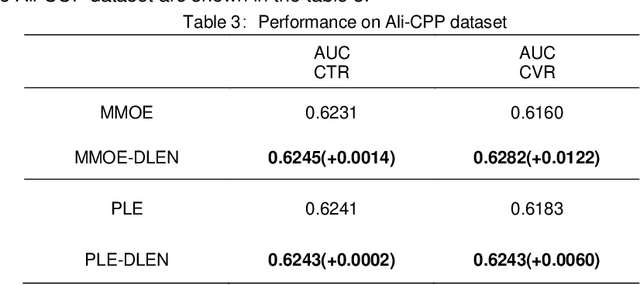
Feed recommendation models are widely adopted by numerous feed platforms to encourage users to explore the contents they are interested in. However, most of the current research simply focus on targeting user's preference and lack in-depth study of avoiding objectionable contents to be frequently recommended, which is a common reason that let user detest. To address this issue, we propose a Deep Latent Emotion Network (DLEN) model to extract latent probability of a user preferring a feed by modeling multiple targets with semi-supervised learning. With this method, the conflicts of different targets are successfully reduced in the training phase, which improves the training accuracy of each target effectively. Besides, by adding this latent state of user emotion to multi-target fusion, the model is capable of decreasing the probability to recommend objectionable contents to improve user retention and stay time during online testing phase. DLEN is deployed on a real-world multi-task feed recommendation scenario of Tencent QQ-Small-World with a dataset containing over a billion samples, and it exhibits a significant performance advantage over the SOTA MTL model in offline evaluation, together with a considerable increase by 3.02% in view-count and 2.63% in user stay-time in production. Complementary offline experiments of DLEN model on a public dataset also repeat improvements in various scenarios. At present, DLEN model has been successfully deployed in Tencent's feed recommendation system.
Optimizing piano practice with a utility-based scaffold
Jun 21, 2021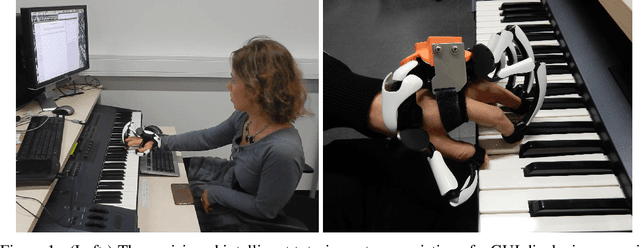
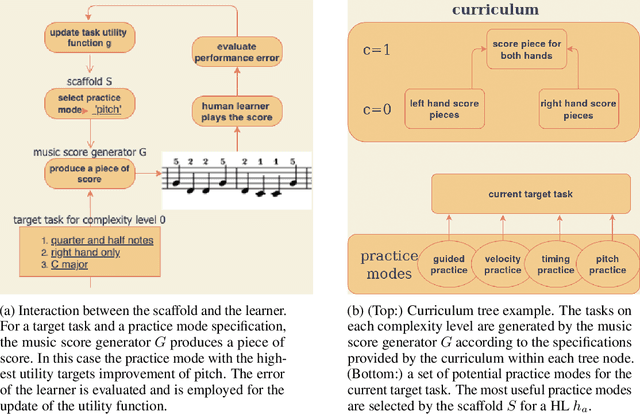
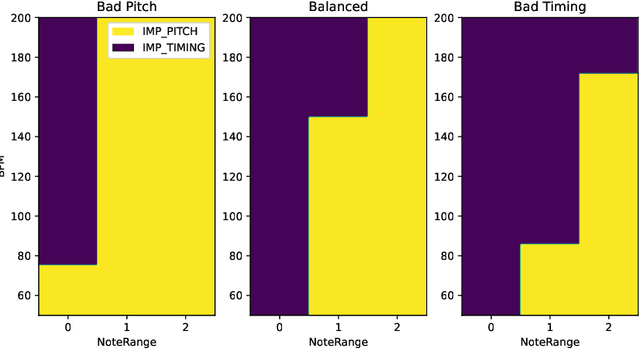
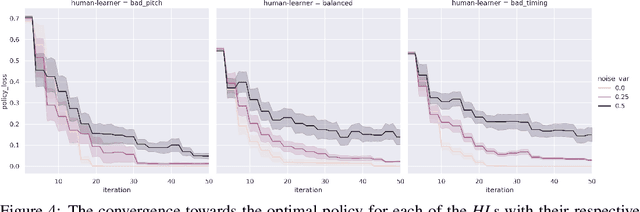
A typical part of learning to play the piano is the progression through a series of practice units that focus on individual dimensions of the skill, such as hand coordination, correct posture, or correct timing. Ideally, a focus on a particular practice method should be made in a way to maximize the learner's progress in learning to play the piano. Because we each learn differently, and because there are many choices for possible piano practice tasks and methods, the set of practice tasks should be dynamically adapted to the human learner. However, having a human teacher guide individual practice is not always feasible since it is time consuming, expensive, and not always available. Instead, we suggest to optimize in the space of practice methods, the so-called practice modes. The proposed optimization process takes into account the skills of the individual learner and their history of learning. In this work we present a modeling framework to guide the human learner through the learning process by choosing practice modes that have the highest expected utility (i.e., improvement in piano playing skill). To this end, we propose a human learner utility model based on a Gaussian process, and exemplify the model training and its application for practice scaffolding on an example of simulated human learners.
Sleep Staging Based on Serialized Dual Attention Network
Jul 18, 2021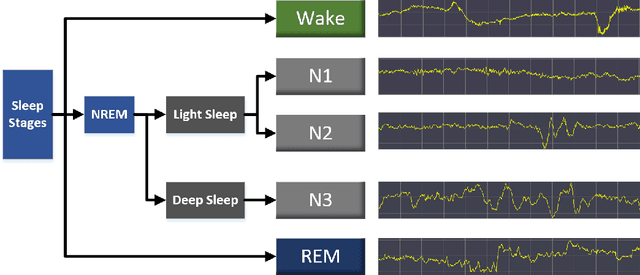

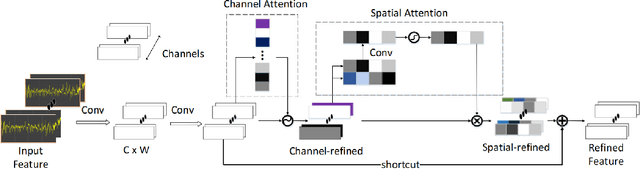

Sleep staging assumes an important role in the diagnosis of sleep disorders. In general, experts classify sleep stages manually based on polysomnography (PSG), which is quite time-consuming. Meanwhile, the acquisition of multiple signals is complex, which can affect the subject's sleep. Therefore, the use of single-channel electroencephalogram (EEG) for automatic sleep staging has become mainstream. In the literature, a large number of sleep staging methods based on single-channel EEG have been proposed with good results and realize the preliminary automation of sleep staging. However, the performance for most of these methods in the N1 stage is generally not high. In this paper, we propose a deep learning model SDAN based on raw EEG. The method utilises a one-dimensional convolutional neural network (CNN) to automatically extract features from raw EEG. It serially combines the channel attention and spatial attention mechanisms to filter and highlight key information and then uses soft threshold to eliminate redundant information. Additionally, we introduce a residual network to avoid degradation problems caused by network deepening. Experiments were conducted using two datasets with 5-fold cross-validation and hold-out validation method. The final average accuracy, overall accuracy, macro F1 score and Cohen's Kappa coefficient of the model reach 96.74%, 91.86%, 82.64% and 0.8742 on the Sleep-EDF dataset, and 95.98%, 89.96%, 79.08% and 0.8216 on the Sleep-EDFx dataset. Significantly, our model performed superiorly in the N1 stage, with F1 scores of 54.08% and 52.49% on the two datasets respectively. The results show the superiority of our network over the best existing methods, reaching a new state-of-the-art. In particular, the present method achieves excellent results in the N1 sleep stage compared to other methods.
OSTSC: Over Sampling for Time Series Classification in R
Nov 27, 2017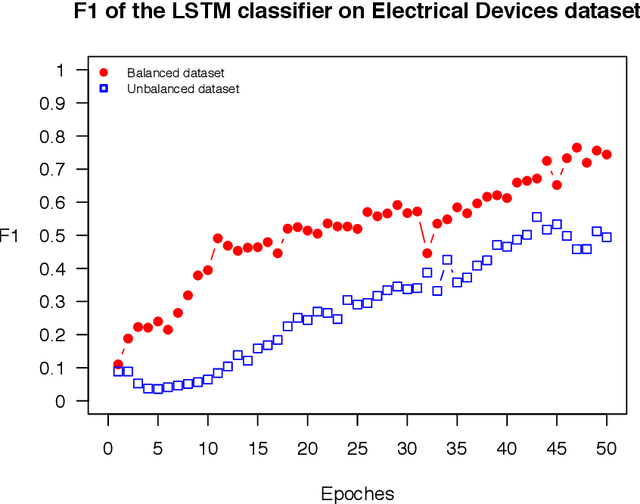
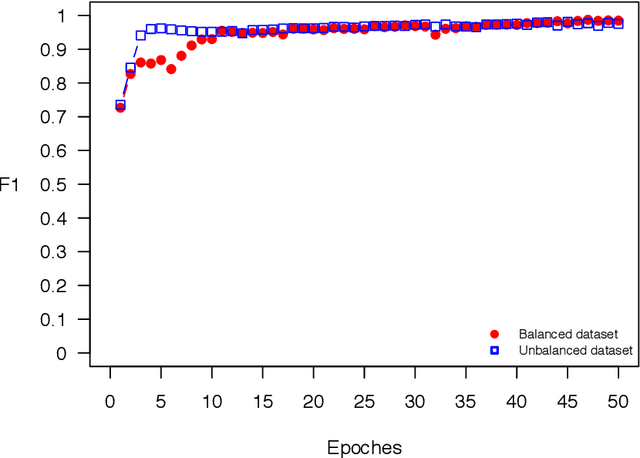
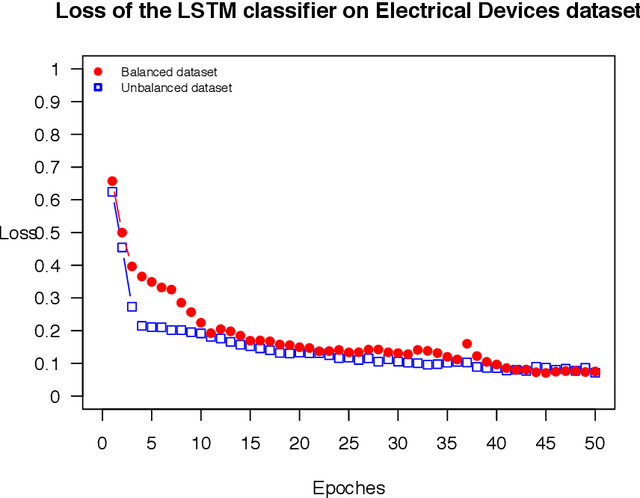

The OSTSC package is a powerful oversampling approach for classifying univariant, but multinomial time series data in R. This article provides a brief overview of the oversampling methodology implemented by the package. A tutorial of the OSTSC package is provided. We begin by providing three test cases for the user to quickly validate the functionality in the package. To demonstrate the performance impact of OSTSC, we then provide two medium size imbalanced time series datasets. Each example applies a TensorFlow implementation of a Long Short-Term Memory (LSTM) classifier - a type of a Recurrent Neural Network (RNN) classifier - to imbalanced time series. The classifier performance is compared with and without oversampling. Finally, larger versions of these two datasets are evaluated to demonstrate the scalability of the package. The examples demonstrate that the OSTSC package improves the performance of RNN classifiers applied to highly imbalanced time series data. In particular, OSTSC is observed to increase the AUC of LSTM from 0.543 to 0.784 on a high frequency trading dataset consisting of 30,000 time series observations.