 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sound Event Detection in Multichannel Audio using Convolutional Time-Frequency-Channel Squeeze and Excitation
Aug 04, 2019
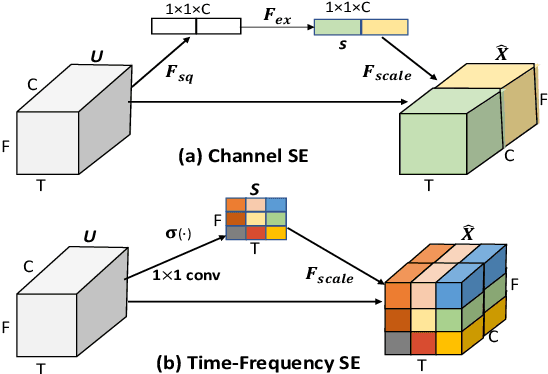
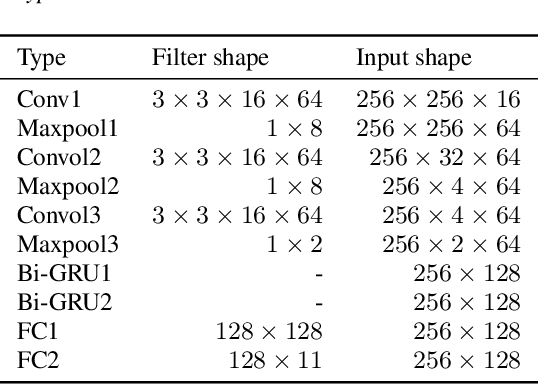
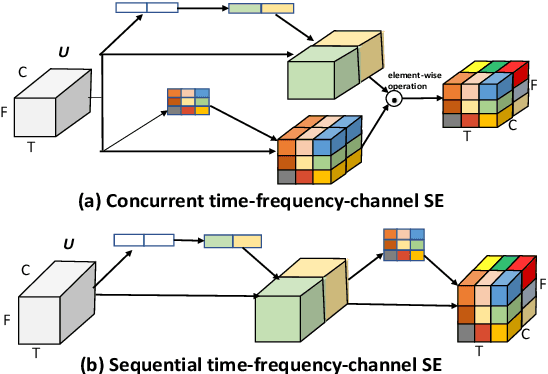
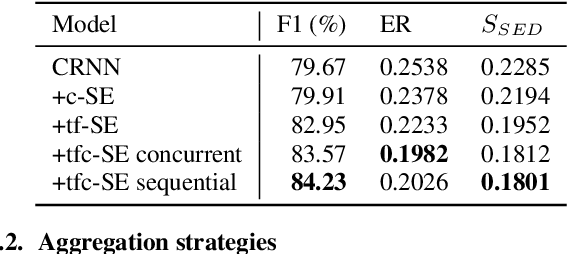
In this study, we introduce a convolutional time-frequency-channel "Squeeze and Excitation" (tfc-SE) module to explicitly model inter-dependencies between the time-frequency domain and multiple channels. The tfc-SE module consists of two parts: tf-SE block and c-SE block which are designed to provide attention on time-frequency and channel domain, respectively, for adaptively recalibrating the input feature map. The proposed tfc-SE module, together with a popular Convolutional Recurrent Neural Network (CRNN) model, are evaluated on a multi-channel sound event detection task with overlapping audio sources: the training and test data are synthesized TUT Sound Events 2018 datasets, recorded with microphone arrays. We show that the tfc-SE module can be incorporated into the CRNN model at a small additional computational cost and bring significant improvements on sound event detection accuracy. We also perform detailed ablation studies by analyzing various factors that may influence the performance of the SE blocks. We show that with the best tfc-SE block, error rate (ER) decreases from 0.2538 to 0.2026, relative 20.17\% reduction of ER, and 5.72\% improvement of F1 score. The results indicate that the learned acoustic embeddings with the tfc-SE module efficiently strengthen time-frequency and channel-wise feature representations to improve the discriminative performance.
Physics perception in sloshing scenes with guaranteed thermodynamic consistency
Jun 24, 2021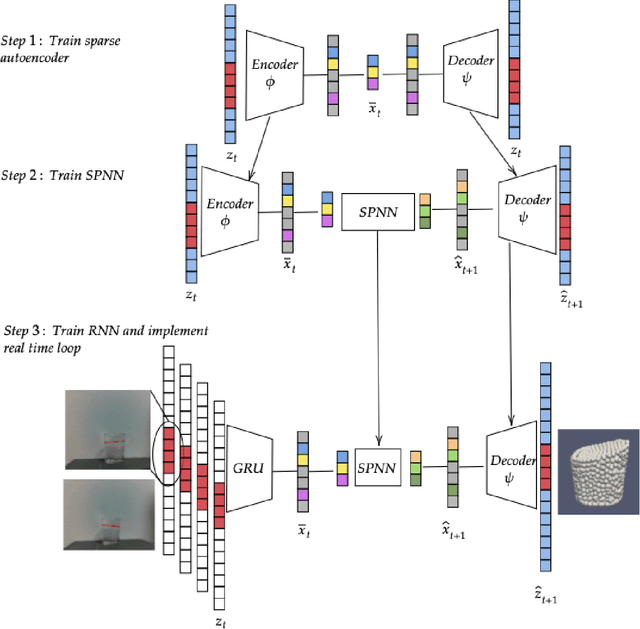

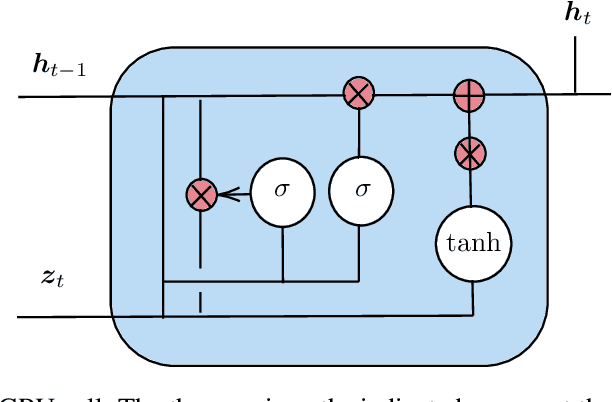
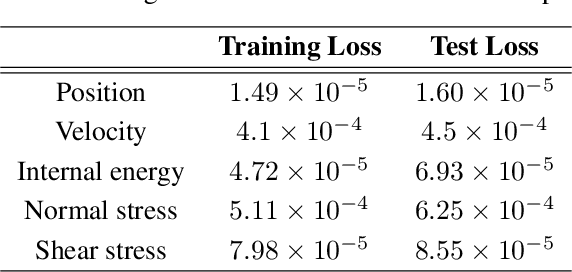
Physics perception very often faces the problem that only limited data or partial measurements on the scene are available. In this work, we propose a strategy to learn the full state of sloshing liquids from measurements of the free surface. Our approach is based on recurrent neural networks (RNN) that project the limited information available to a reduced-order manifold so as to not only reconstruct the unknown information, but also to be capable of performing fluid reasoning about future scenarios in real time. To obtain physically consistent predictions, we train deep neural networks on the reduced-order manifold that, through the employ of inductive biases, ensure the fulfillment of the principles of thermodynamics. RNNs learn from history the required hidden information to correlate the limited information with the latent space where the simulation occurs. Finally, a decoder returns data back to the high-dimensional manifold, so as to provide the user with insightful information in the form of augmented reality. This algorithm is connected to a computer vision system to test the performance of the proposed methodology with real information, resulting in a system capable of understanding and predicting future states of the observed fluid in real-time.
Visual resemblance and communicative context constrain the emergence of graphical conventions
Sep 17, 2021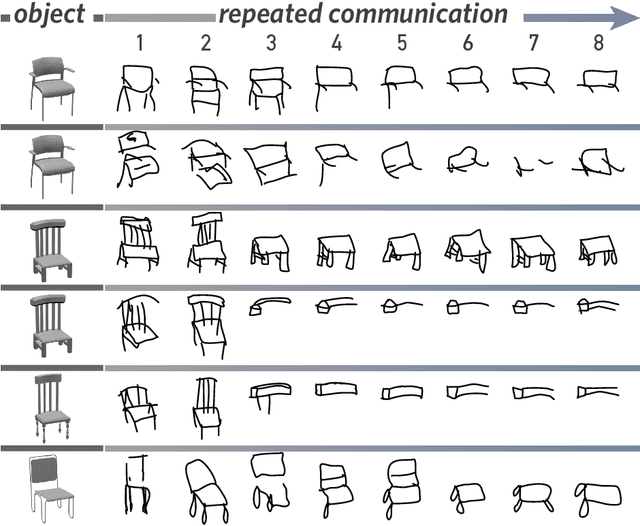
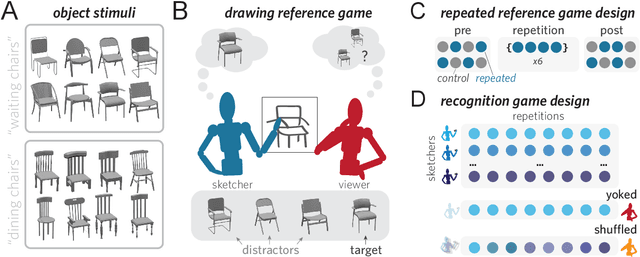
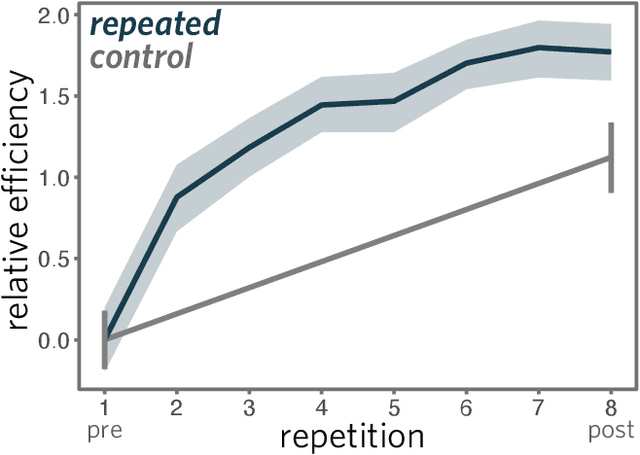
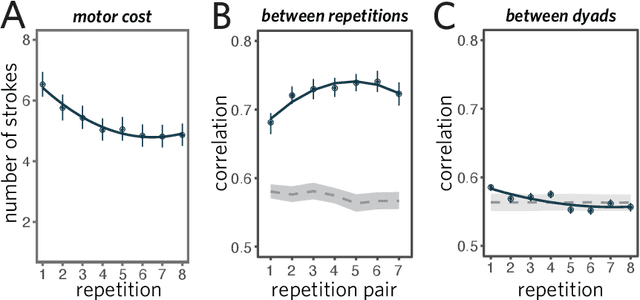
From photorealistic sketches to schematic diagrams, drawing provides a versatile medium for communicating about the visual world. How do images spanning such a broad range of appearances reliably convey meaning? Do viewers understand drawings based solely on their ability to resemble the entities they refer to (i.e., as images), or do they understand drawings based on shared but arbitrary associations with these entities (i.e., as symbols)? In this paper, we provide evidence for a cognitive account of pictorial meaning in which both visual and social information is integrated to support effective visual communication. To evaluate this account, we used a communication task where pairs of participants used drawings to repeatedly communicate the identity of a target object among multiple distractor objects. We manipulated social cues across three experiments and a full internal replication, finding pairs of participants develop referent-specific and interaction-specific strategies for communicating more efficiently over time, going beyond what could be explained by either task practice or a pure resemblance-based account alone. Using a combination of model-based image analyses and crowdsourced sketch annotations, we further determined that drawings did not drift toward arbitrariness, as predicted by a pure convention-based account, but systematically preserved those visual features that were most distinctive of the target object. Taken together, these findings advance theories of pictorial meaning and have implications for how successful graphical conventions emerge via complex interactions between visual perception, communicative experience, and social context.
IrisNet: Deep Learning for Automatic and Real-time Tongue Contour Tracking in Ultrasound Video Data using Peripheral Vision
Nov 10, 2019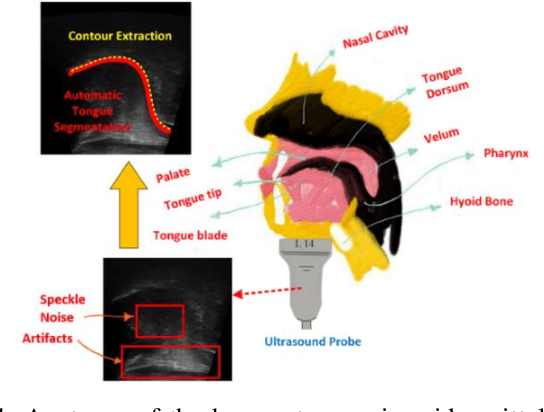
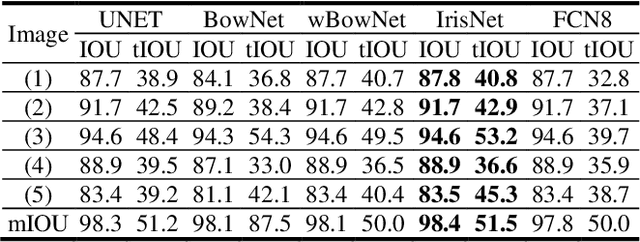

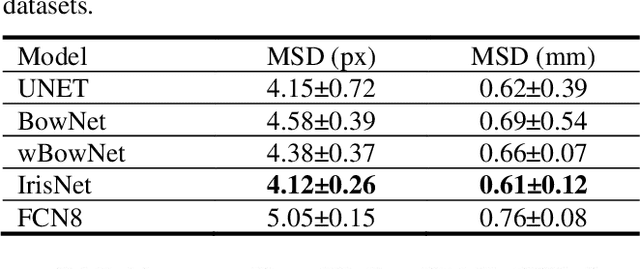
The progress of deep convolutional neural networks has been successfully exploited in various real-time computer vision tasks such as image classification and segmentation. Owing to the development of computational units, availability of digital datasets, and improved performance of deep learning models, fully automatic and accurate tracking of tongue contours in real-time ultrasound data became practical only in recent years. Recent studies have shown that the performance of deep learning techniques is significant in the tracking of ultrasound tongue contours in real-time applications such as pronunciation training using multimodal ultrasound-enhanced approaches. Due to the high correlation between ultrasound tongue datasets, it is feasible to have a general model that accomplishes automatic tongue tracking for almost all datasets. In this paper, we proposed a deep learning model comprises of a convolutional module mimicking the peripheral vision ability of the human eye to handle real-time, accurate, and fully automatic tongue contour tracking tasks, applicable for almost all primary ultrasound tongue datasets. Qualitative and quantitative assessment of IrisNet on different ultrasound tongue datasets and PASCAL VOC2012 revealed its outstanding generalization achievement in compare with similar techniques.
First Order Methods take Exponential Time to Converge to Global Minimizers of Non-Convex Functions
Feb 28, 2020
Machine learning algorithms typically perform optimization over a class of non-convex functions. In this work, we provide bounds on the fundamental hardness of identifying the global minimizer of a non convex function. Specifically, we design a family of parametrized non-convex functions and employ statistical lower bounds for parameter estimation. We show that the parameter estimation problem is equivalent to the problem of function identification in the given family. We then claim that non convex optimization is at least as hard as function identification. Jointly, we prove that any first order method can take exponential time to converge to a global minimizer.
Discovering Representation Sprachbund For Multilingual Pre-Training
Sep 01, 2021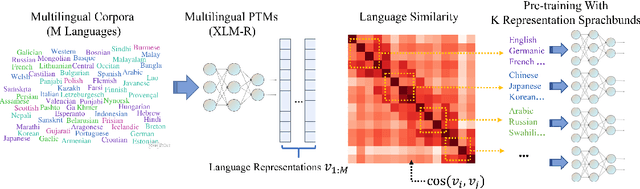

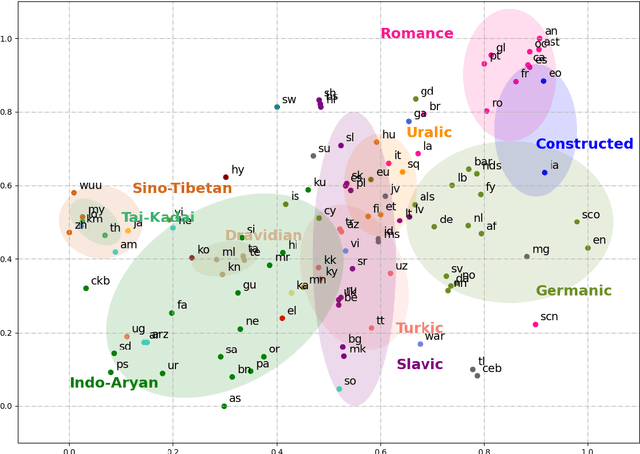

Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
BioNetExplorer: Architecture-Space Exploration of Bio-Signal Processing Deep Neural Networks for Wearables
Sep 07, 2021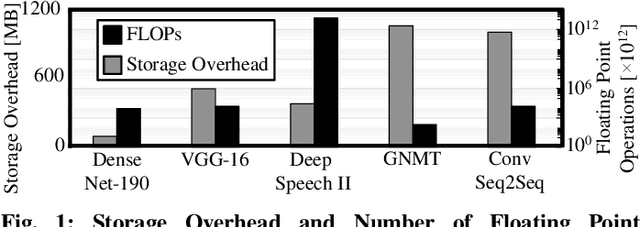
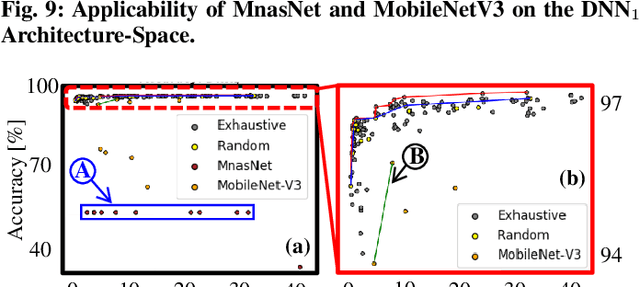
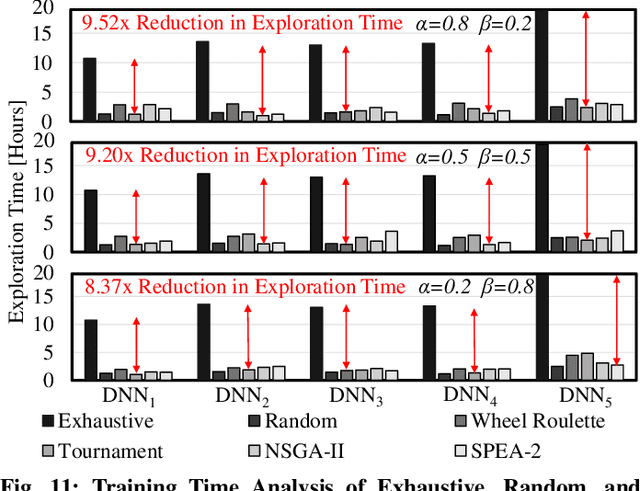
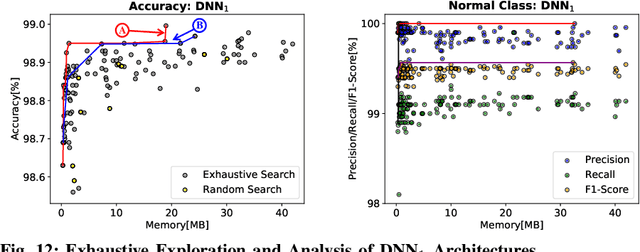
In this work, we propose the BioNetExplorer framework to systematically generate and explore multiple DNN architectures for bio-signal processing in wearables. Our framework adapts key neural architecture parameters to search for an embedded DNN with a low hardware overhead, which can be deployed in wearable edge devices to analyse the bio-signal data and to extract the relevant information, such as arrhythmia and seizure. Our framework also enables hardware-aware DNN architecture search using genetic algorithms by imposing user requirements and hardware constraints (storage, FLOPs, etc.) during the exploration stage, thereby limiting the number of networks explored. Moreover, BioNetExplorer can also be used to search for DNNs based on the user-required output classes; for instance, a user might require a specific output class due to genetic predisposition or a pre-existing heart condition. The use of genetic algorithms reduces the exploration time, on average, by 9x, compared to exhaustive exploration. We are successful in identifying Pareto-optimal designs, which can reduce the storage overhead of the DNN by ~30MB for a quality loss of less than 0.5%. To enable low-cost embedded DNNs, BioNetExplorer also employs different model compression techniques to further reduce the storage overhead of the network by up to 53x for a quality loss of <0.2%.
DeepScale: An Online Frame Size Adaptation Approach to Accelerate Visual Multi-object Tracking
Aug 18, 2021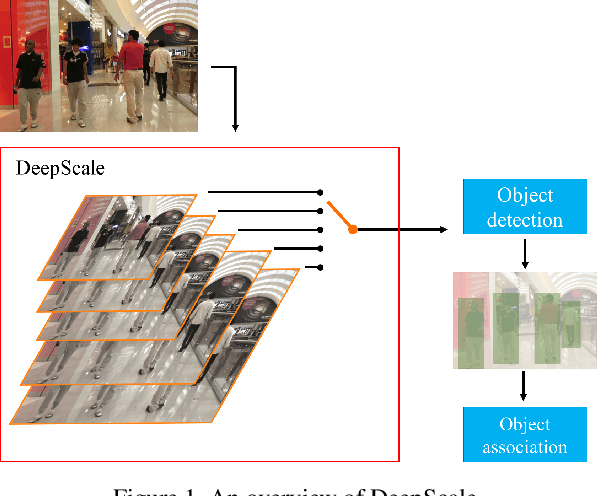

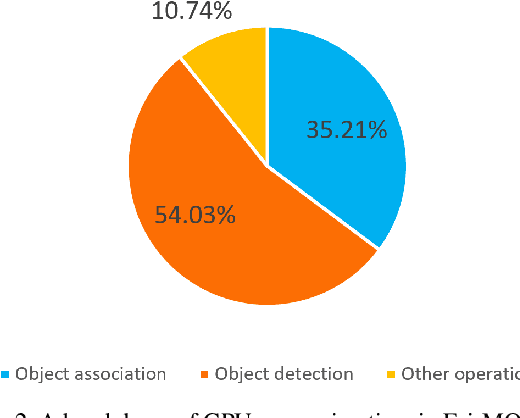
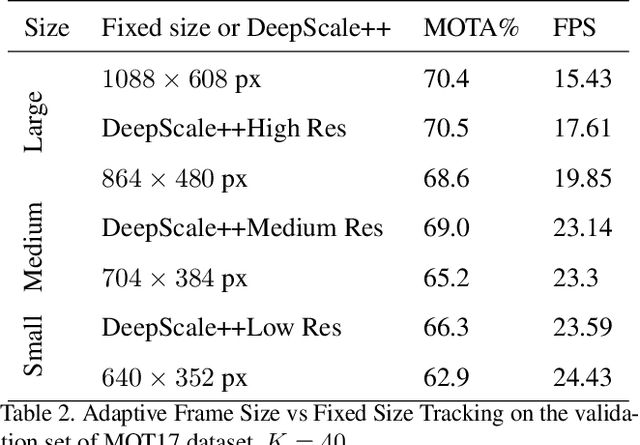
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today's MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. {During inference, it can adapt frame sizes according to the complexity of visual contents based on user-controlled parameters.} Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (~ 2.3%) in tracking accuracy on the MOT15 dataset in one configuration.
Always Be Dreaming: A New Approach for Data-Free Class-Incremental Learning
Jun 17, 2021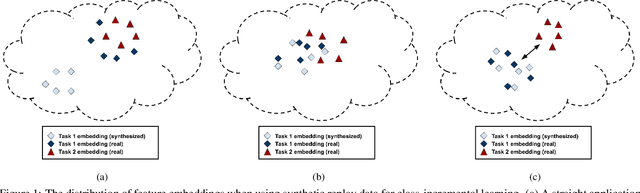
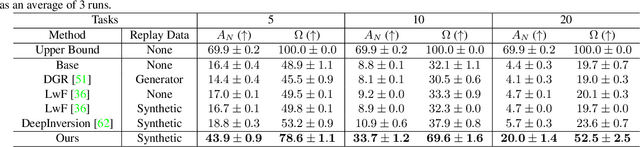
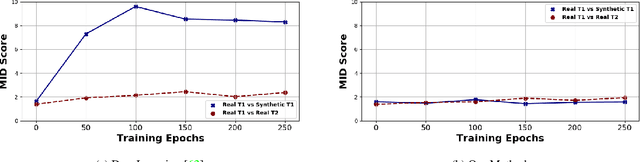

Modern computer vision applications suffer from catastrophic forgetting when incrementally learning new concepts over time. The most successful approaches to alleviate this forgetting require extensive replay of previously seen data, which is problematic when memory constraints or data legality concerns exist. In this work, we consider the high-impact problem of Data-Free Class-Incremental Learning (DFCIL), where an incremental learning agent must learn new concepts over time without storing generators or training data from past tasks. One approach for DFCIL is to replay synthetic images produced by inverting a frozen copy of the learner's classification model, but we show this approach fails for common class-incremental benchmarks when using standard distillation strategies. We diagnose the cause of this failure and propose a novel incremental distillation strategy for DFCIL, contributing a modified cross-entropy training and importance-weighted feature distillation, and show that our method results in up to a 25.1% increase in final task accuracy (absolute difference) compared to SOTA DFCIL methods for common class-incremental benchmarks. Our method even outperforms several standard replay based methods which store a coreset of images.
Dynamic Network selection for the Object Detection task: why it matters and what we (didn't) achieve
May 27, 2021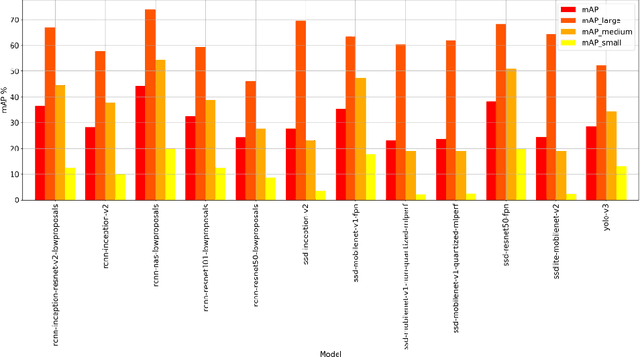

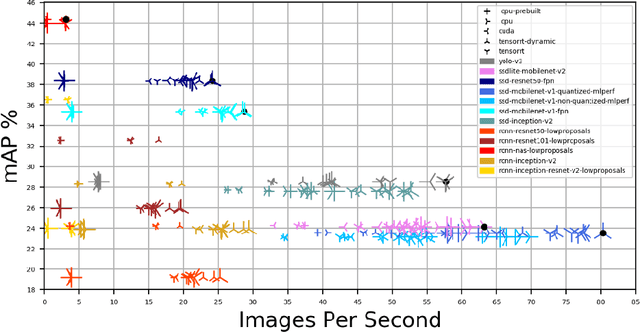

In this paper, we want to show the potential benefit of a dynamic auto-tuning approach for the inference process in the Deep Neural Network (DNN) context, tackling the object detection challenge. We benchmarked different neural networks to find the optimal detector for the well-known COCO 17 database, and we demonstrate that even if we only consider the quality of the prediction there is not a single optimal network. This is even more evident if we also consider the time to solution as a metric to evaluate, and then select, the most suitable network. This opens to the possibility for an adaptive methodology to switch among different object detection networks according to run-time requirements (e.g. maximum quality subject to a time-to-solution constraint). Moreover, we demonstrated by developing an ad hoc oracle, that an additional proactive methodology could provide even greater benefits, allowing us to select the best network among the available ones given some characteristics of the processed image. To exploit this method, we need to identify some image features that can be used to steer the decision on the most promising network. Despite the optimization opportunity that has been identified, we were not able to identify a predictor function that validates this attempt neither adopting classical image features nor by using a DNN classifier.