 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021
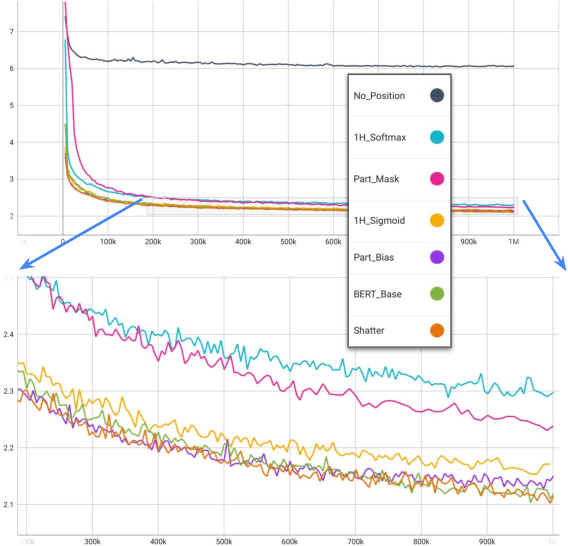
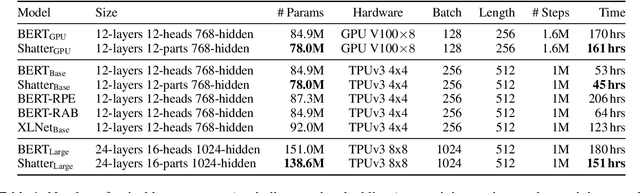

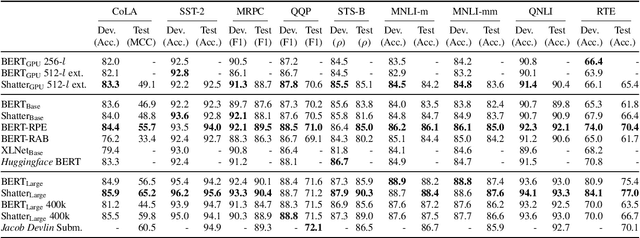
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Improved Signed Distance Function for 2D Real-time SLAM and Accurate Localization
Jan 20, 2021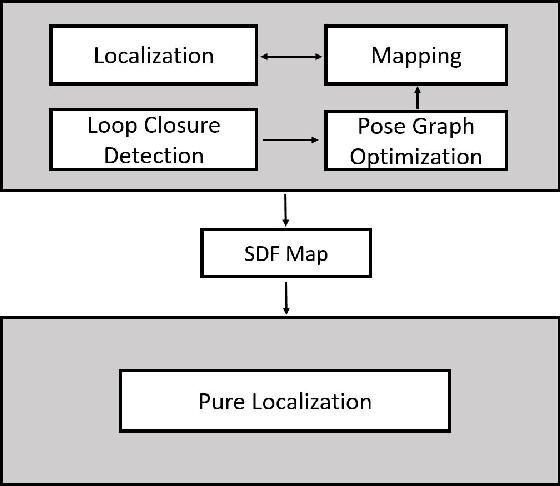
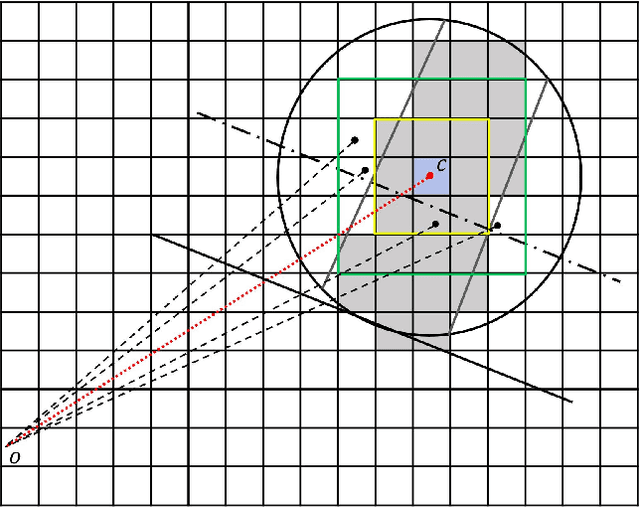

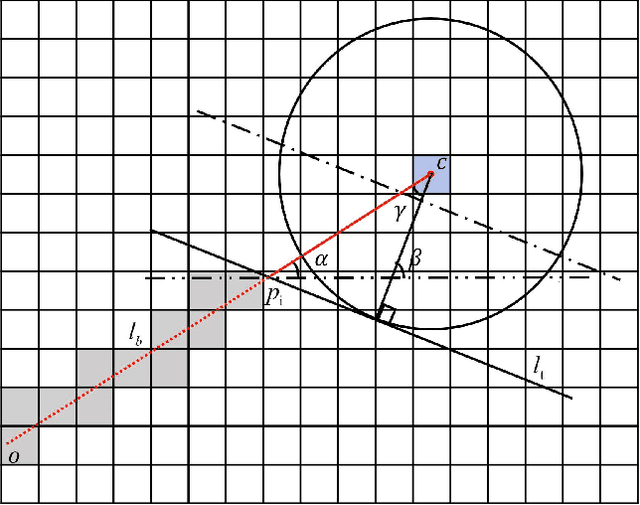
Accurate mapping and localization are very important for many industrial robotics applications. In this paper, we propose an improved Signed Distance Function (SDF) for both 2D SLAM and pure localization to improve the accuracy of mapping and localization. To achieve this goal, firstly we improved the back-end mapping to build a more accurate SDF map by extending the update range and building free space, etc. Secondly, to get more accurate pose estimation for the front-end, we proposed a new iterative registration method to align the current scan to the SDF submap by removing random outliers of laser scanners. Thirdly, we merged all the SDF submaps to produce an integrated SDF map for highly accurate pure localization. Experimental results show that based on the merged SDF map, a localization accuracy of a few millimeters (5mm) can be achieved globally within the map. We believe that this method is important for mobile robots working in scenarios where high localization accuracy matters.
Neural Symbolic Regression that Scales
Jun 11, 2021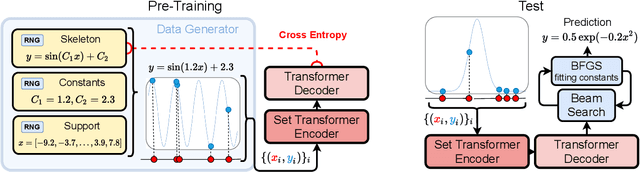
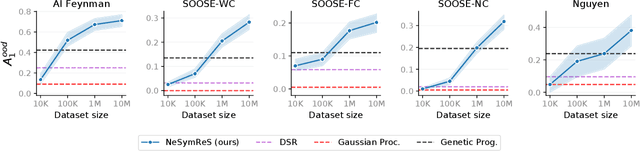
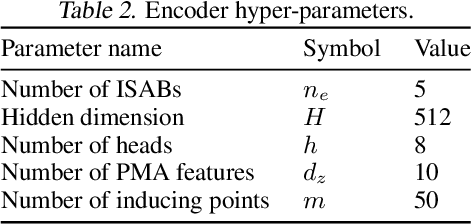
Symbolic equations are at the core of scientific discovery. The task of discovering the underlying equation from a set of input-output pairs is called symbolic regression. Traditionally, symbolic regression methods use hand-designed strategies that do not improve with experience. In this paper, we introduce the first symbolic regression method that leverages large scale pre-training. We procedurally generate an unbounded set of equations, and simultaneously pre-train a Transformer to predict the symbolic equation from a corresponding set of input-output-pairs. At test time, we query the model on a new set of points and use its output to guide the search for the equation. We show empirically that this approach can re-discover a set of well-known physical equations, and that it improves over time with more data and compute.
Automatic Recall of Software Lessons Learned for Software Project Managers
Oct 11, 2021
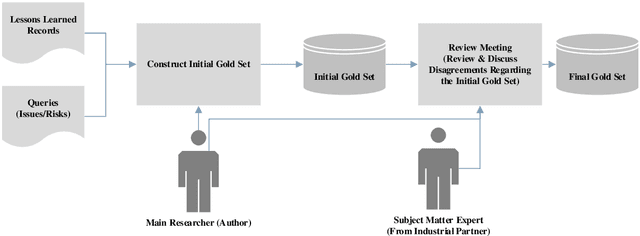

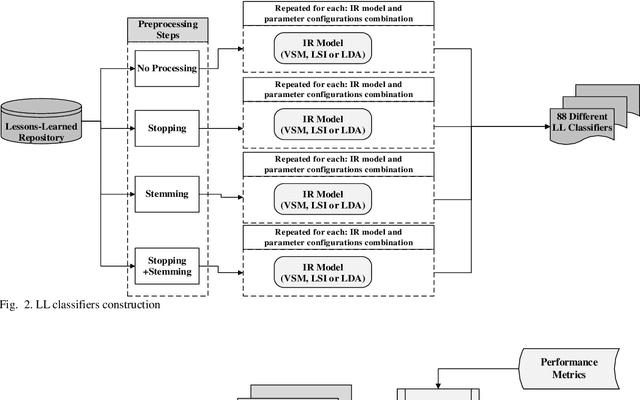
Lessons learned (LL) records constitute the software organization memory of successes and failures. LL are recorded within the organization repository for future reference to optimize planning, gain experience, and elevate market competitiveness. However, manually searching this repository is a daunting task, so it is often disregarded. This can lead to the repetition of previous mistakes or even missing potential opportunities. This, in turn, can negatively affect the profitability and competitiveness of organizations. We aim to present a novel solution that provides an automatic process to recall relevant LL and to push those LL to project managers. This will dramatically save the time and effort of manually searching the unstructured LL repositories and thus encourage the LL exploitation. We exploit existing project artifacts to build the LL search queries on-the-fly in order to bypass the tedious manual searching. An empirical case study is conducted to build the automatic LL recall solution and evaluate its effectiveness. The study employs three of the most popular information retrieval models to construct the solution. Furthermore, a real-world dataset of 212 LL records from 30 different software projects is used for validation. Top-k and MAP well-known accuracy metrics are used as well. Our case study results confirm the effectiveness of the automatic LL recall solution. Also, the results prove the success of using existing project artifacts to dynamically build the search query string. This is supported by a discerning accuracy of about 70% achieved in the case of top-k. The automatic LL recall solution is valid with high accuracy. It will eliminate the effort needed to manually search the LL repository. Therefore, this will positively encourage project managers to reuse the available LL knowledge, which will avoid old pitfalls and unleash hidden business opportunities.
Neural ODE Processes
Mar 23, 2021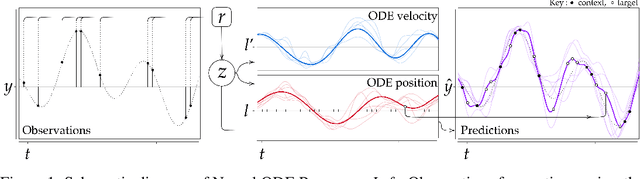


Neural Ordinary Differential Equations (NODEs) use a neural network to model the instantaneous rate of change in the state of a system. However, despite their apparent suitability for dynamics-governed time-series, NODEs present a few disadvantages. First, they are unable to adapt to incoming data-points, a fundamental requirement for real-time applications imposed by the natural direction of time. Second, time-series are often composed of a sparse set of measurements that could be explained by many possible underlying dynamics. NODEs do not capture this uncertainty. In contrast, Neural Processes (NPs) are a family of models providing uncertainty estimation and fast data-adaptation, but lack an explicit treatment of the flow of time. To address these problems, we introduce Neural ODE Processes (NDPs), a new class of stochastic processes determined by a distribution over Neural ODEs. By maintaining an adaptive data-dependent distribution over the underlying ODE, we show that our model can successfully capture the dynamics of low-dimensional systems from just a few data-points. At the same time, we demonstrate that NDPs scale up to challenging high-dimensional time-series with unknown latent dynamics such as rotating MNIST digits.
Learning stable reduced-order models for hybrid twins
Jun 07, 2021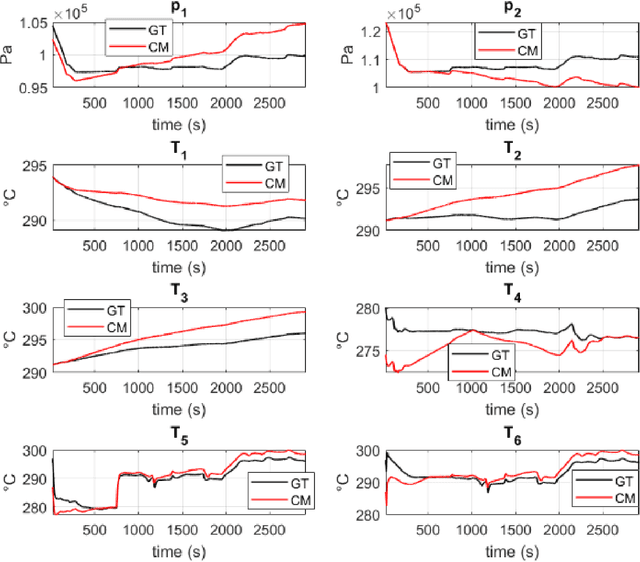
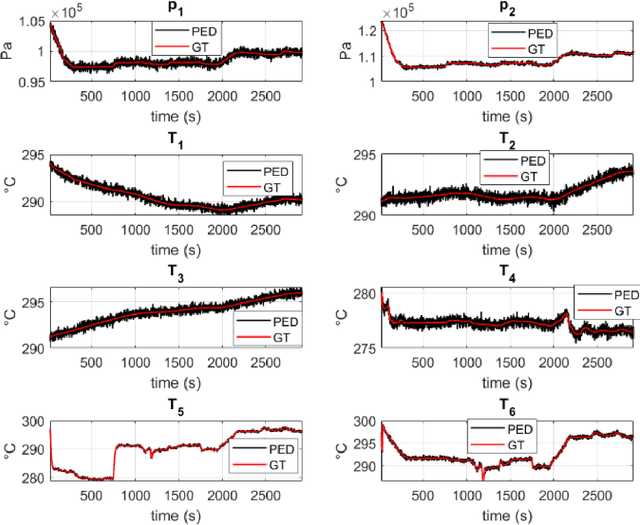
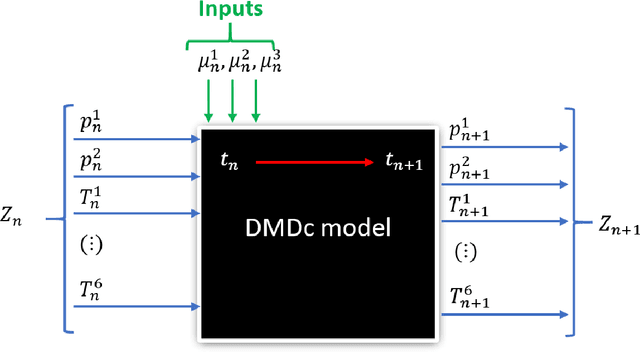
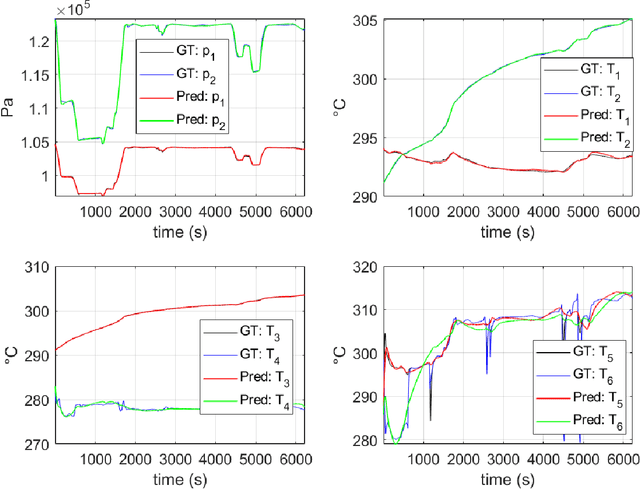
The concept of Hybrid Twin (HT) has recently received a growing interest thanks to the availability of powerful machine learning techniques. This twin concept combines physics-based models within a model-order reduction framework-to obtain real-time feedback rates-and data science. Thus, the main idea of the HT is to develop on-the-fly data-driven models to correct possible deviations between measurements and physics-based model predictions. This paper is focused on the computation of stable, fast and accurate corrections in the Hybrid Twin framework. Furthermore, regarding the delicate and important problem of stability, a new approach is proposed, introducing several sub-variants and guaranteeing a low computational cost as well as the achievement of a stable time-integration.
AI-HRI 2021 Proceedings
Sep 23, 2021The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. During that time, these symposia provided a fertile ground for numerous collaborations and pioneered many discussions revolving trust in HRI, XAI for HRI, service robots, interactive learning, and more. This year, we aim to review the achievements of the AI-HRI community in the last decade, identify the challenges facing ahead, and welcome new researchers who wish to take part in this growing community. Taking this wide perspective, this year there will be no single theme to lead the symposium and we encourage AI-HRI submissions from across disciplines and research interests. Moreover, with the rising interest in AR and VR as part of an interaction and following the difficulties in running physical experiments during the pandemic, this year we specifically encourage researchers to submit works that do not include a physical robot in their evaluation, but promote HRI research in general. In addition, acknowledging that ethics is an inherent part of the human-robot interaction, we encourage submissions of works on ethics for HRI. Over the course of the two-day meeting, we will host a collaborative forum for discussion of current efforts in AI-HRI, with additional talks focused on the topics of ethics in HRI and ubiquitous HRI.
ISTHMUS: Secure, Scalable, Real-time and Robust Machine Learning Platform for Healthcare
Oct 01, 2019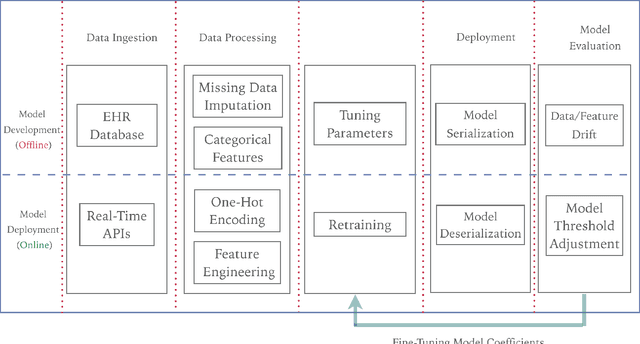
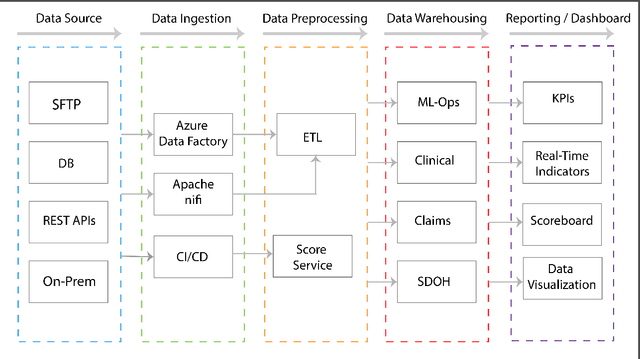
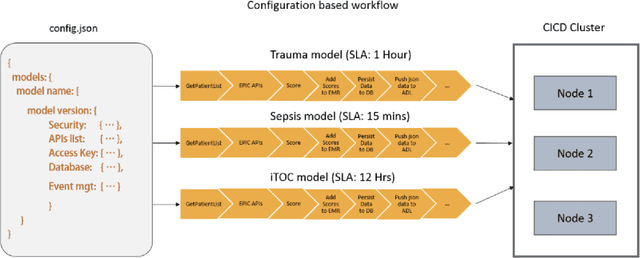
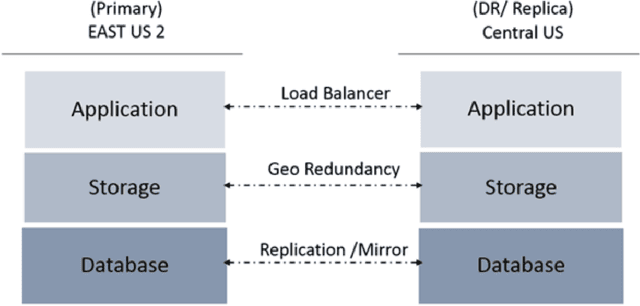
In recent times, machine learning (ML) and artificial intelligence (AI) based systems have evolved and scaled across different industries such as finance, retail, insurance, energy utilities, etc. Among other things, they have been used to predict patterns of customer behavior, to generate pricing models, and to predict the return on investments. But the successes in deploying machine learning models at scale in those industries have not translated into the healthcare setting. There are multiple reasons why integrating ML models into healthcare has not been widely successful, but from a technical perspective, general-purpose commercial machine learning platforms are not a good fit for healthcare due to complexities in handling data quality issues, mandates to demonstrate clinical relevance, and a lack of ability to monitor performance in a highly regulated environment with stringent security and privacy needs. In this paper, we describe Isthmus, a turnkey, cloud-based platform which addresses the challenges above and reduces time to market for operationalizing ML/AI in healthcare. Towards the end, we describe three case studies which shed light on Isthmus capabilities. These include (1) supporting an end-to-end lifecycle of a model which predicts trauma survivability at hospital trauma centers, (2) bringing in and harmonizing data from disparate sources to create a community data platform for inferring population as well as patient level insights for Social Determinants of Health (SDoH), and (3) ingesting live-streaming data from various IoT sensors to build models, which can leverage real-time and longitudinal information to make advanced time-sensitive predictions.
Assessing the Causal Impact of COVID-19 Related Policies on Outbreak Dynamics: A Case Study in the US
May 29, 2021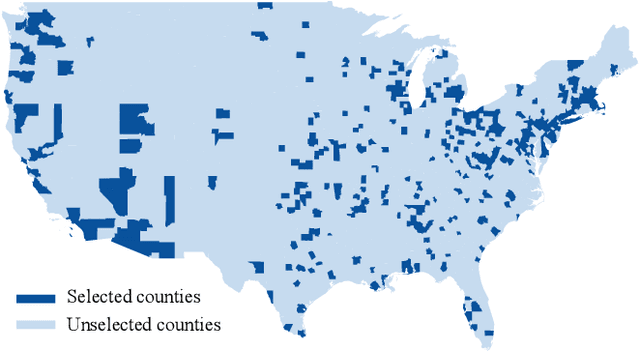

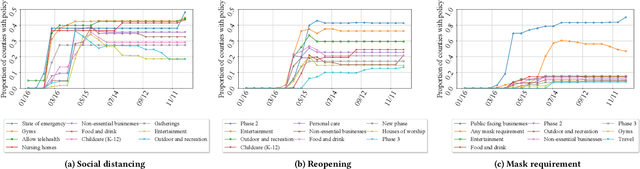
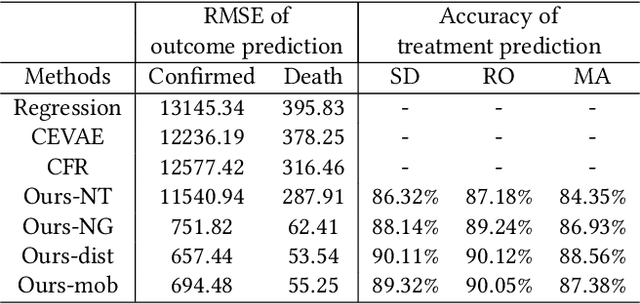
To mitigate the spread of COVID-19 pandemic, decision-makers and public authorities have announced various non-pharmaceutical policies. Analyzing the causal impact of these policies in reducing the spread of COVID-19 is important for future policy-making. The main challenge here is the existence of unobserved confounders (e.g., vigilance of residents). Besides, as the confounders may be time-varying during COVID-19 (e.g., vigilance of residents changes in the course of the pandemic), it is even more difficult to capture them. In this paper, we study the problem of assessing the causal effects of different COVID-19 related policies on the outbreak dynamics in different counties at any given time period. To this end, we integrate data about different COVID-19 related policies (treatment) and outbreak dynamics (outcome) for different United States counties over time and analyze them with respect to variables that can infer the confounders, including the covariates of different counties, their relational information and historical information. Based on these data, we develop a neural network based causal effect estimation framework which leverages above information in observational data and learns the representations of time-varying (unobserved) confounders. In this way, it enables us to quantify the causal impact of policies at different granularities, ranging from a category of policies with a certain goal to a specific policy type in this category. Besides, experimental results also indicate the effectiveness of our proposed framework in capturing the confounders for quantifying the causal impact of different policies. More specifically, compared with several baseline methods, our framework captures the outbreak dynamics more accurately, and our assessment of policies is more consistent with existing epidemiological studies of COVID-19.
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021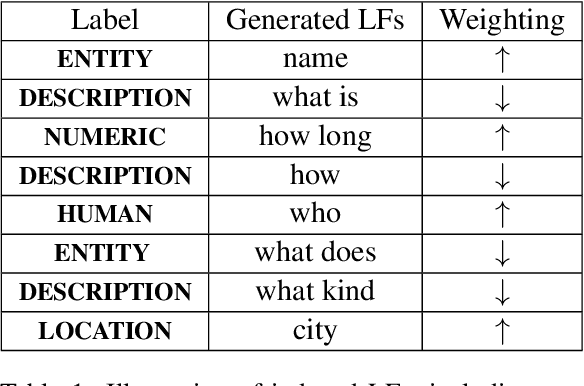
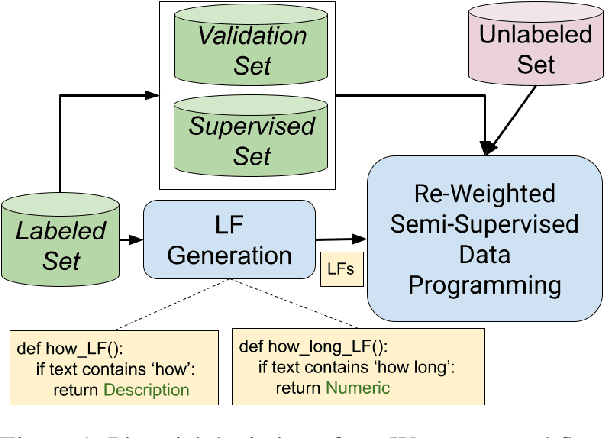
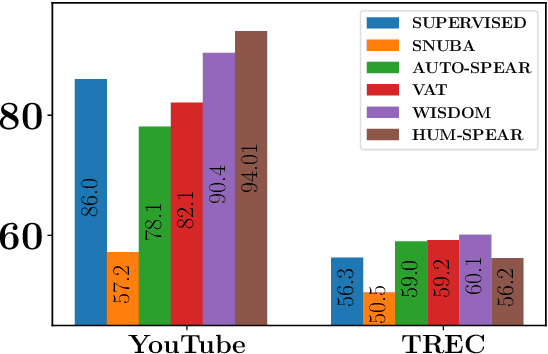
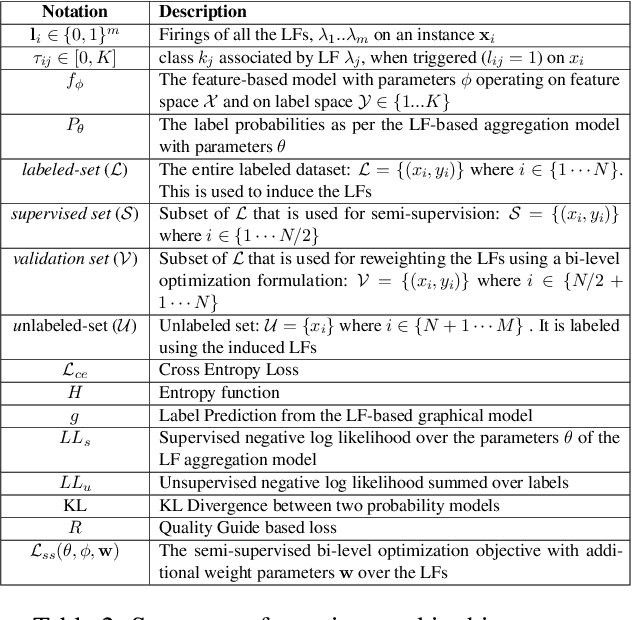
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.