 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finding needles in a haystack: Sampling Structurally-diverse Training Sets from Synthetic Data for Compositional Generalization
Sep 06, 2021
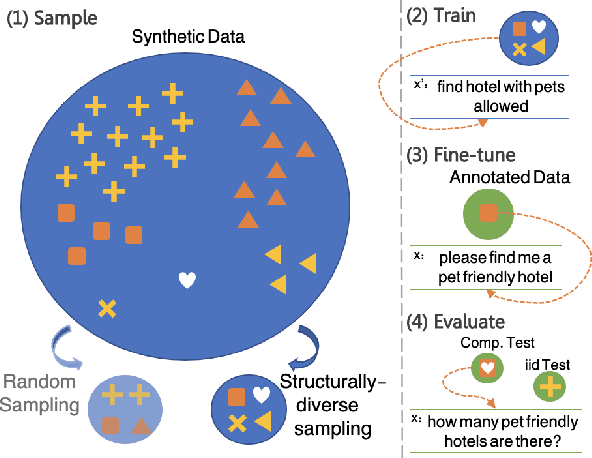



Modern semantic parsers suffer from two principal limitations. First, training requires expensive collection of utterance-program pairs. Second, semantic parsers fail to generalize at test time to new compositions/structures that have not been observed during training. Recent research has shown that automatic generation of synthetic utterance-program pairs can alleviate the first problem, but its potential for the second has thus far been under-explored. In this work, we investigate automatic generation of synthetic utterance-program pairs for improving compositional generalization in semantic parsing. Given a small training set of annotated examples and an "infinite" pool of synthetic examples, we select a subset of synthetic examples that are structurally-diverse and use them to improve compositional generalization. We evaluate our approach on a new split of the schema2QA dataset, and show that it leads to dramatic improvements in compositional generalization as well as moderate improvements in the traditional i.i.d setup. Moreover, structurally-diverse sampling achieves these improvements with as few as 5K examples, compared to 1M examples when sampling uniformly at random -- a 200x improvement in data efficiency.
Marginally calibrated response distributions for end-to-end learning in autonomous driving
Oct 03, 2021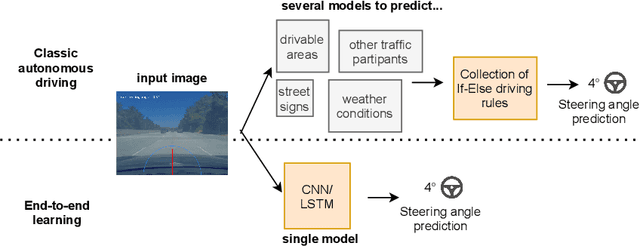
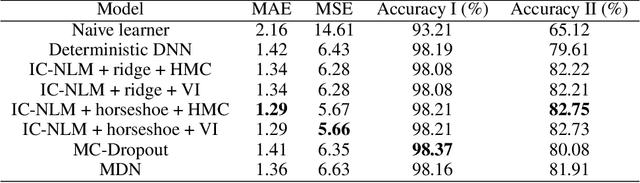

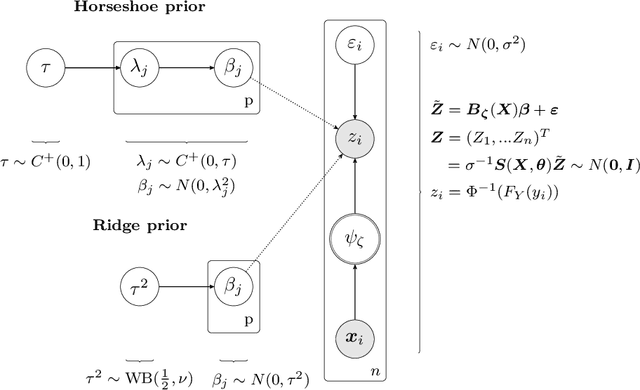
End-to-end learners for autonomous driving are deep neural networks that predict the instantaneous steering angle directly from images of the ahead-lying street. These learners must provide reliable uncertainty estimates for their predictions in order to meet safety requirements and initiate a switch to manual control in areas of high uncertainty. Yet end-to-end learners typically only deliver point predictions, since distributional predictions are associated with large increases in training time or additional computational resources during prediction. To address this shortcoming we investigate efficient and scalable approximate inference for the implicit copula neural linear model of Klein, Nott and Smith (2021) in order to quantify uncertainty for the predictions of end-to-end learners. The result are densities for the steering angle that are marginally calibrated, i.e.~the average of the estimated densities equals the empirical distribution of steering angles. To ensure the scalability to large $n$ regimes, we develop efficient estimation based on variational inference as a fast alternative to computationally intensive, exact inference via Hamiltonian Monte Carlo. We demonstrate the accuracy and speed of the variational approach in comparison to Hamiltonian Monte Carlo on two end-to-end learners trained for highway driving using the comma2k19 data set. The implicit copula neural linear model delivers accurate calibration, high-quality prediction intervals and allows to identify overconfident learners. Our approach also contributes to the explainability of black-box end-to-end learners, since predictive densities can be used to understand which steering actions the end-to-end learner sees as valid.
On the Sample Complexity and Metastability of Heavy-tailed Policy Search in Continuous Control
Jun 15, 2021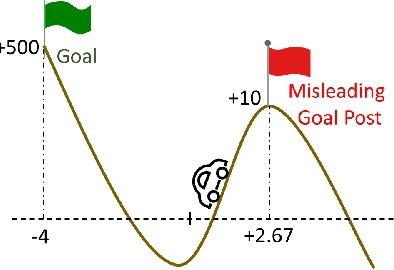

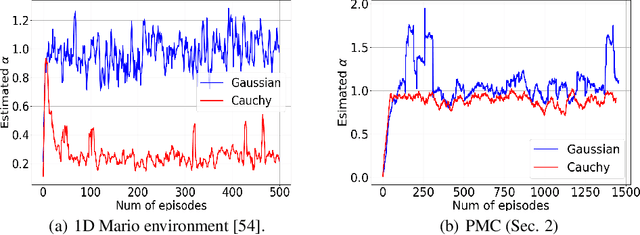
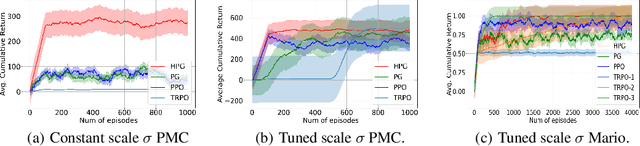
Reinforcement learning is a framework for interactive decision-making with incentives sequentially revealed across time without a system dynamics model. Due to its scaling to continuous spaces, we focus on policy search where one iteratively improves a parameterized policy with stochastic policy gradient (PG) updates. In tabular Markov Decision Problems (MDPs), under persistent exploration and suitable parameterization, global optimality may be obtained. By contrast, in continuous space, the non-convexity poses a pathological challenge as evidenced by existing convergence results being mostly limited to stationarity or arbitrary local extrema. To close this gap, we step towards persistent exploration in continuous space through policy parameterizations defined by distributions of heavier tails defined by tail-index parameter alpha, which increases the likelihood of jumping in state space. Doing so invalidates smoothness conditions of the score function common to PG. Thus, we establish how the convergence rate to stationarity depends on the policy's tail index alpha, a Holder continuity parameter, integrability conditions, and an exploration tolerance parameter introduced here for the first time. Further, we characterize the dependence of the set of local maxima on the tail index through an exit and transition time analysis of a suitably defined Markov chain, identifying that policies associated with Levy Processes of a heavier tail converge to wider peaks. This phenomenon yields improved stability to perturbations in supervised learning, which we corroborate also manifests in improved performance of policy search, especially when myopic and farsighted incentives are misaligned.
A Comparison of Supervised and Unsupervised Deep Learning Methods for Anomaly Detection in Images
Jul 20, 2021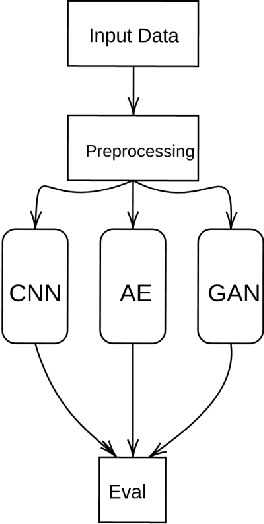
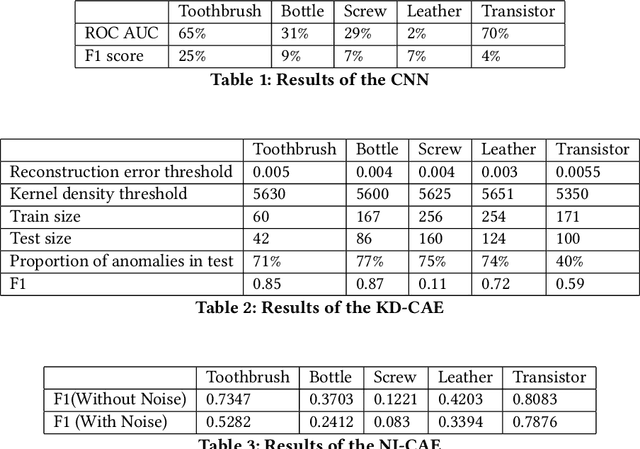
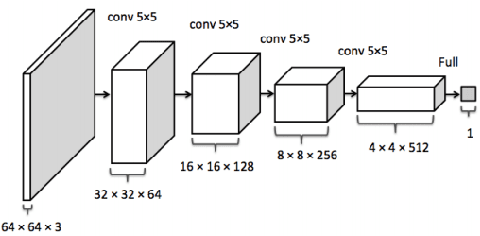

Anomaly detection in images plays a significant role for many applications across all industries, such as disease diagnosis in healthcare or quality assurance in manufacturing. Manual inspection of images, when extended over a monotonously repetitive period of time is very time consuming and can lead to anomalies being overlooked.Artificial neural networks have proven themselves very successful on simple, repetitive tasks, in some cases even outperforming humans. Therefore, in this paper we investigate different methods of deep learning, including supervised and unsupervised learning, for anomaly detection applied to a quality assurance use case. We utilize the MVTec anomaly dataset and develop three different models, a CNN for supervised anomaly detection, KD-CAE for autoencoder anomaly detection, NI-CAE for noise induced anomaly detection and a DCGAN for generating reconstructed images. By experiments, we found that KD-CAE performs better on the anomaly datasets compared to CNN and NI-CAE, with NI-CAE performing the best on the Transistor dataset. We also implemented a DCGAN for the creation of new training data but due to computational limitation and lack of extrapolating the mechanics of AnoGAN, we restricted ourselves just to the generation of GAN based images. We conclude that unsupervised methods are more powerful for anomaly detection in images, especially in a setting where only a small amount of anomalous data is available, or the data is unlabeled.
Nimber-Preserving Reductions and Homomorphic Sprague-Grundy Game Encodings
Sep 12, 2021
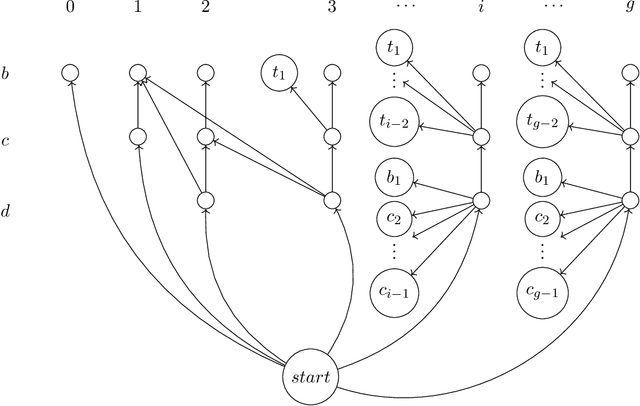
The concept of nimbers--a.k.a. Grundy-values or nim-values--is fundamental to combinatorial game theory. Nimbers provide a complete characterization of strategic interactions among impartial games in their disjunctive sums as well as the winnability. In this paper, we initiate a study of nimber-preserving reductions among impartial games. These reductions enhance the winnability-preserving reductions in traditional computational characterizations of combinatorial games. We prove that Generalized Geography is complete for the natural class, $\cal{I}^P$ , of polynomially-short impartial rulesets under nimber-preserving reductions, a property we refer to as Sprague-Grundy-complete. In contrast, we also show that not every PSPACE-complete ruleset in $\cal{I}^P$ is Sprague-Grundy-complete for $\cal{I}^P$ . By considering every impartial game as an encoding of its nimber, our technical result establishes the following striking cryptography-inspired homomorphic theorem: Despite the PSPACE-completeness of nimber computation for $\cal{I}^P$ , there exists a polynomial-time algorithm to construct, for any pair of games $G_1$, $G_2$ of $\cal{I}^P$ , a prime game (i.e. a game that cannot be written as a sum) $H$ of $\cal{I}^P$ , satisfying: nimber($H$) = nimber($G_1$) $\oplus$ nimber($G_2$).
Dynamic Error-bounded Lossy Compression (EBLC) to Reduce the Bandwidth Requirement for Real-time Vision-based Pedestrian Safety Applications
Jan 29, 2020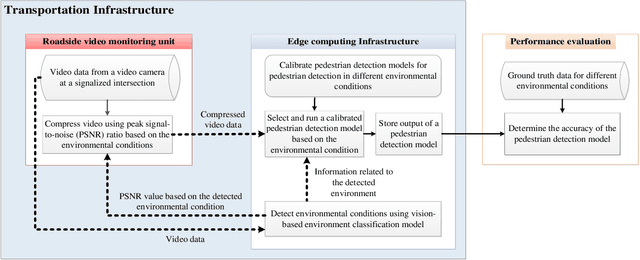
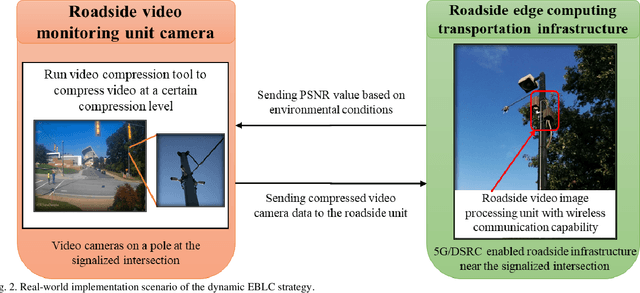
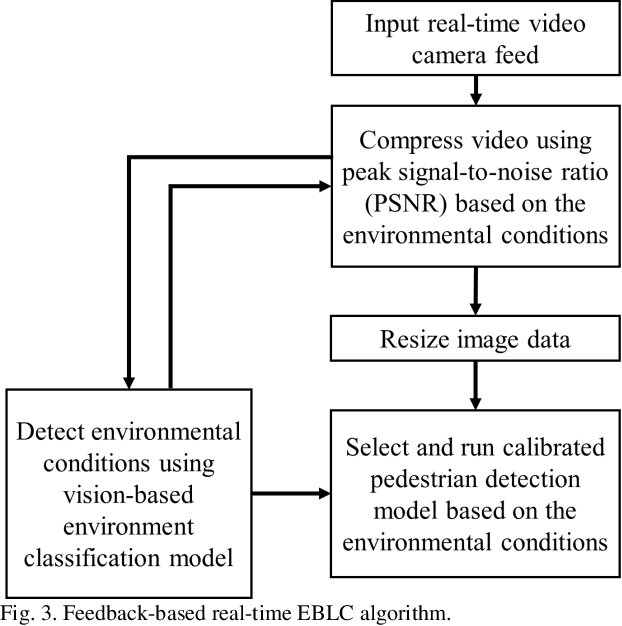

As camera quality improves and their deployment moves to areas with limited bandwidth, communication bottlenecks can impair real-time constraints of an ITS application, such as video-based real-time pedestrian detection. Video compression reduces the bandwidth requirement to transmit the video but degrades the video quality. As the quality level of the video decreases, it results in the corresponding decreases in the accuracy of the vision-based pedestrian detection model. Furthermore, environmental conditions (e.g., rain and darkness) alter the compression ratio and can make maintaining a high pedestrian detection accuracy more difficult. The objective of this study is to develop a real-time error-bounded lossy compression (EBLC) strategy to dynamically change the video compression level depending on different environmental conditions in order to maintain a high pedestrian detection accuracy. We conduct a case study to show the efficacy of our dynamic EBLC strategy for real-time vision-based pedestrian detection under adverse environmental conditions. Our strategy selects the error tolerances dynamically for lossy compression that can maintain a high detection accuracy across a representative set of environmental conditions. Analyses reveal that our strategy increases pedestrian detection accuracy up to 14% and reduces the communication bandwidth up to 14x for adverse environmental conditions compared to the same conditions but without our dynamic EBLC strategy. Our dynamic EBLC strategy is independent of detection models and environmental conditions allowing other detection models and environmental conditions to be easily incorporated in our strategy.
Temporal-Clustering Invariance in Irregular Healthcare Time Series
Apr 27, 2019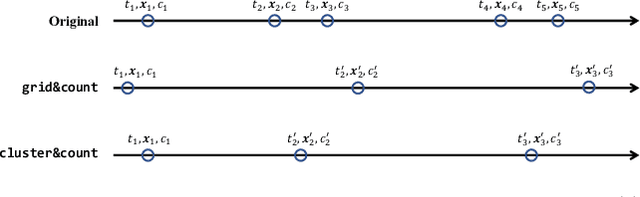
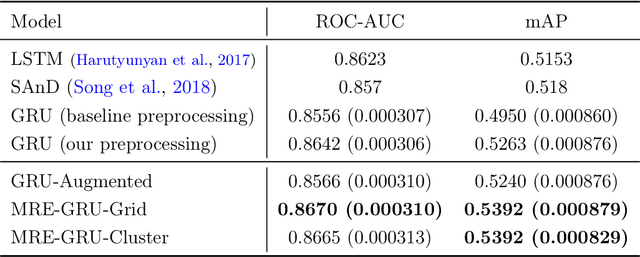
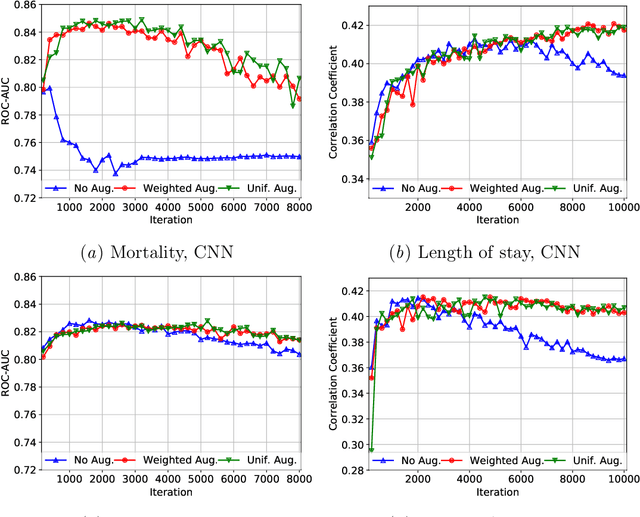
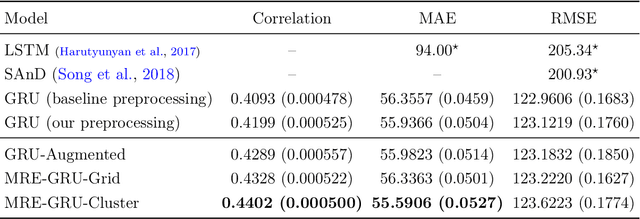
Electronic records contain sequences of events, some of which take place all at once in a single visit, and others that are dispersed over multiple visits, each with a different timestamp. We postulate that fine temporal detail, e.g., whether a series of blood tests are completed at once or in rapid succession should not alter predictions based on this data. Motivated by this intuition, we propose models for analyzing sequences of multivariate clinical time series data that are invariant to this temporal clustering. We propose an efficient data augmentation technique that exploits the postulated temporal-clustering invariance to regularize deep neural networks optimized for several clinical prediction tasks. We introduce two techniques to temporally coarsen (downsample) irregular time series: (i) grouping the data points based on regularly-spaced timestamps; and (ii) clustering them, yielding irregularly-paced timestamps. Moreover, we propose a MultiResolution Ensemble (MRE) model, improving predictive accuracy by ensembling predictions based on inputs sequences transformed by different coarsening operators. Our experiments show that MRE improves the mAP on the benchmark mortality prediction task from 51.53% to 53.92%.
Efficient Mind-Map Generation via Sequence-to-Graph and Reinforced Graph Refinement
Sep 06, 2021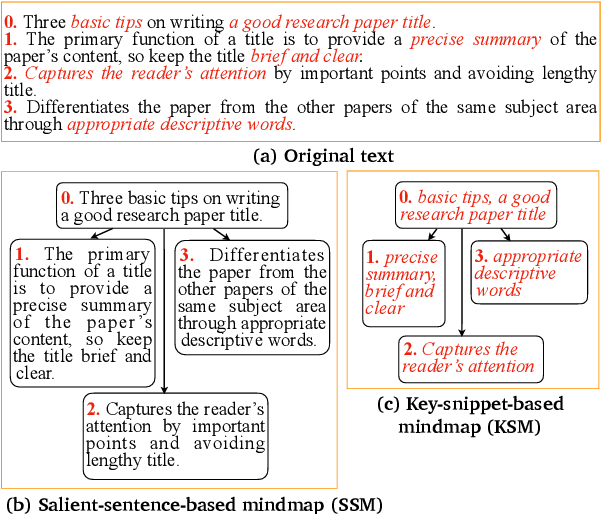
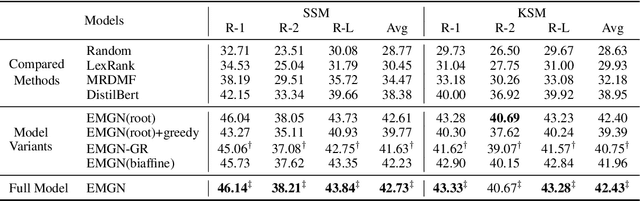
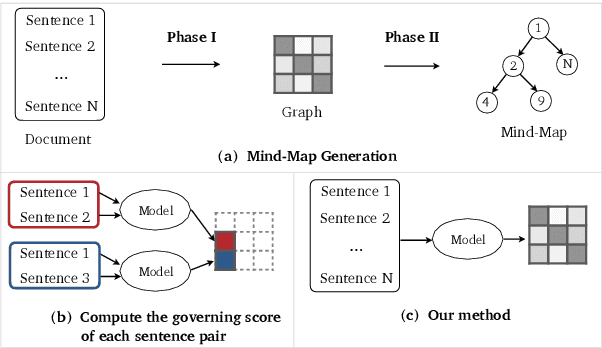
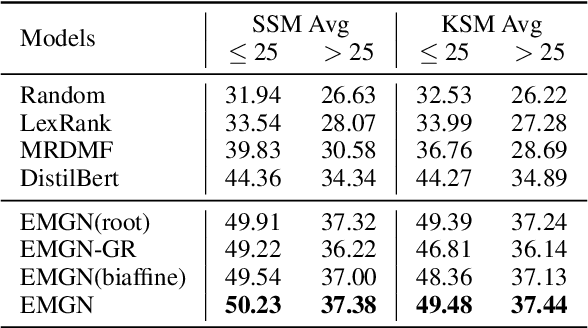
A mind-map is a diagram that represents the central concept and key ideas in a hierarchical way. Converting plain text into a mind-map will reveal its key semantic structure and be easier to understand. Given a document, the existing automatic mind-map generation method extracts the relationships of every sentence pair to generate the directed semantic graph for this document. The computation complexity increases exponentially with the length of the document. Moreover, it is difficult to capture the overall semantics. To deal with the above challenges, we propose an efficient mind-map generation network that converts a document into a graph via sequence-to-graph. To guarantee a meaningful mind-map, we design a graph refinement module to adjust the relation graph in a reinforcement learning manner. Extensive experimental results demonstrate that the proposed approach is more effective and efficient than the existing methods. The inference time is reduced by thousands of times compared with the existing methods. The case studies verify that the generated mind-maps better reveal the underlying semantic structures of the document.
Artificial bandwidth extension using deep neural network and $H^\infty$ sampled-data control theory
Aug 30, 2021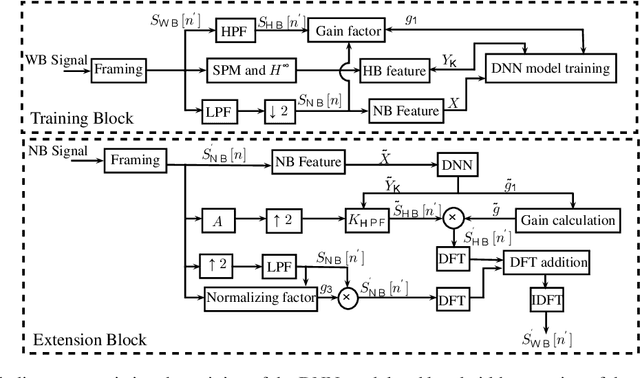


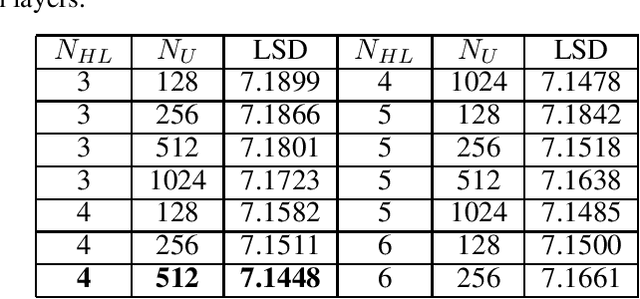
Artificial bandwidth extension is applied to speech signals to improve their quality in narrowband telephonic communication. For accomplishing this, the missing high-frequency (high-band) components of speech signals are recovered by utilizing a new extrapolation process based on sampled-data control theory and deep neural network (DNN). The $H^\infty$ sampled-data control theory helps in designing of a high-band filter to recover the high-frequency signals by optimally utilizing the inter-sample signals. Non-stationary (time-varying) characteristics of speech signals forces to use numerous high-band filters. Hence, we use a deep neural network for estimating the high-band filter information and a gain factor for a specified narrowband information of the unseen signal. The objective analysis is done on the TIMIT dataset and RSR15 dataset. Additionally, the objective analysis is performed separately for the voiced speech as well as for the unvoiced speech as generally needed in speech processing. Subjective analysis is done on the RSR15 dataset.
Reachability Analysis of Neural Feedback Loops
Aug 09, 2021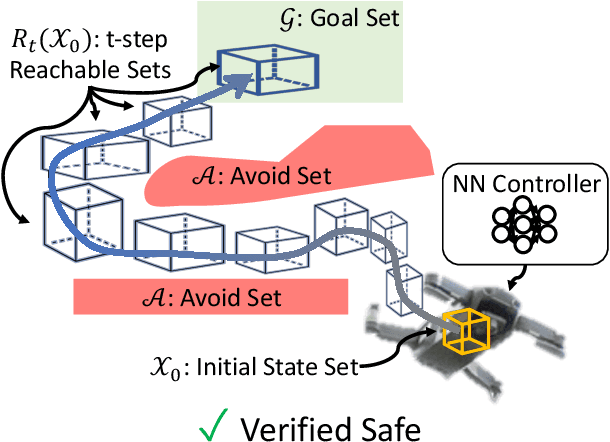
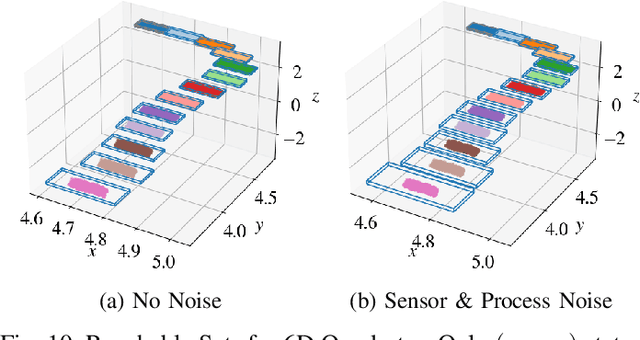
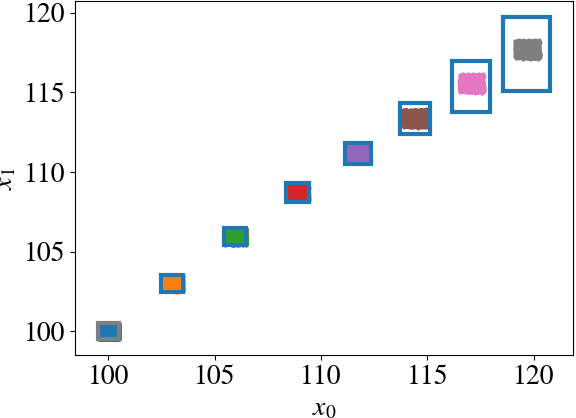
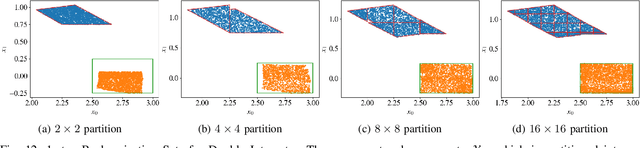
Neural Networks (NNs) can provide major empirical performance improvements for closed-loop systems, but they also introduce challenges in formally analyzing those systems' safety properties. In particular, this work focuses on estimating the forward reachable set of \textit{neural feedback loops} (closed-loop systems with NN controllers). Recent work provides bounds on these reachable sets, but the computationally tractable approaches yield overly conservative bounds (thus cannot be used to verify useful properties), and the methods that yield tighter bounds are too intensive for online computation. This work bridges the gap by formulating a convex optimization problem for the reachability analysis of closed-loop systems with NN controllers. While the solutions are less tight than previous (semidefinite program-based) methods, they are substantially faster to compute, and some of those computational time savings can be used to refine the bounds through new input set partitioning techniques, which is shown to dramatically reduce the tightness gap. The new framework is developed for systems with uncertainty (e.g., measurement and process noise) and nonlinearities (e.g., polynomial dynamics), and thus is shown to be applicable to real-world systems. To inform the design of an initial state set when only the target state set is known/specified, a novel algorithm for backward reachability analysis is also provided, which computes the set of states that are guaranteed to lead to the target set. The numerical experiments show that our approach (based on linear relaxations and partitioning) gives a $5\times$ reduction in conservatism in $150\times$ less computation time compared to the state-of-the-art. Furthermore, experiments on quadrotor, 270-state, and polynomial systems demonstrate the method's ability to handle uncertainty sources, high dimensionality, and nonlinear dynamics, respectively.