 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Mind-Map Generation via Sequence-to-Graph and Reinforced Graph Refinement
Sep 06, 2021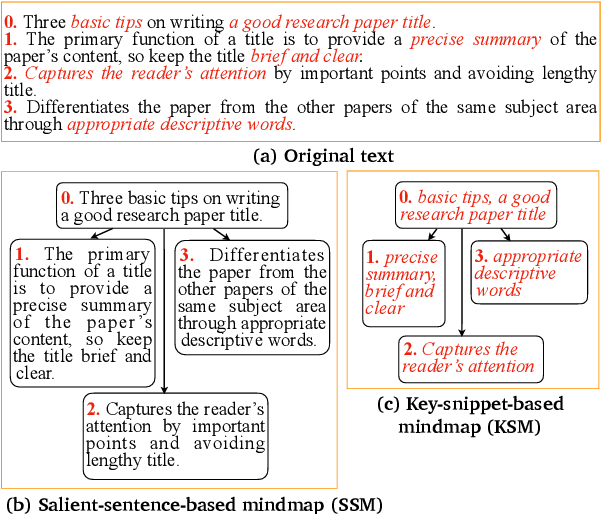
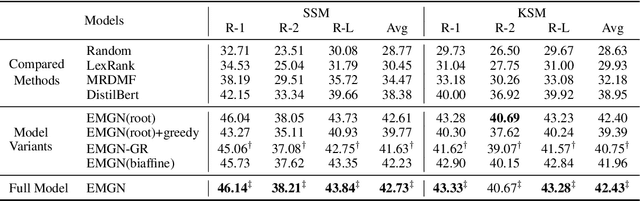
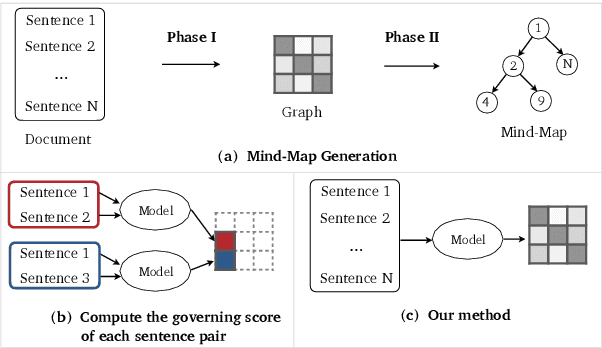
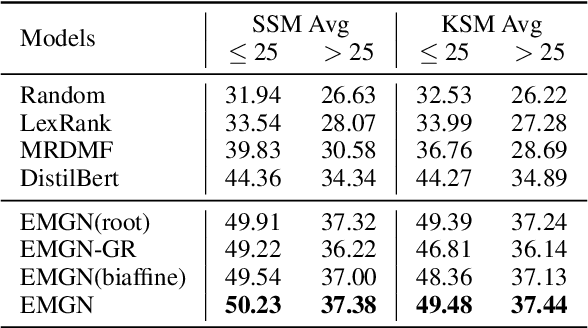
A mind-map is a diagram that represents the central concept and key ideas in a hierarchical way. Converting plain text into a mind-map will reveal its key semantic structure and be easier to understand. Given a document, the existing automatic mind-map generation method extracts the relationships of every sentence pair to generate the directed semantic graph for this document. The computation complexity increases exponentially with the length of the document. Moreover, it is difficult to capture the overall semantics. To deal with the above challenges, we propose an efficient mind-map generation network that converts a document into a graph via sequence-to-graph. To guarantee a meaningful mind-map, we design a graph refinement module to adjust the relation graph in a reinforcement learning manner. Extensive experimental results demonstrate that the proposed approach is more effective and efficient than the existing methods. The inference time is reduced by thousands of times compared with the existing methods. The case studies verify that the generated mind-maps better reveal the underlying semantic structures of the document.
Multi-Label Few-Shot Learning for Aspect Category Detection
May 29, 2021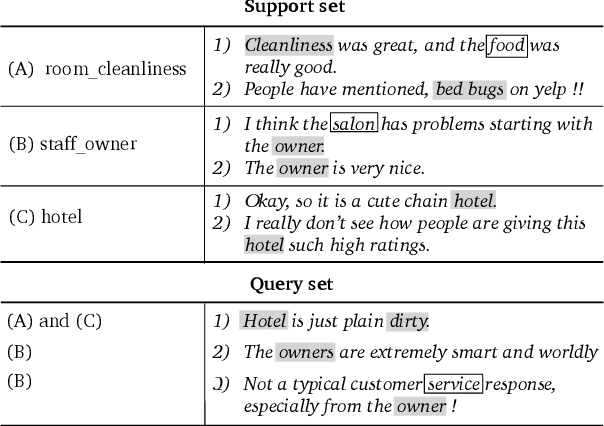

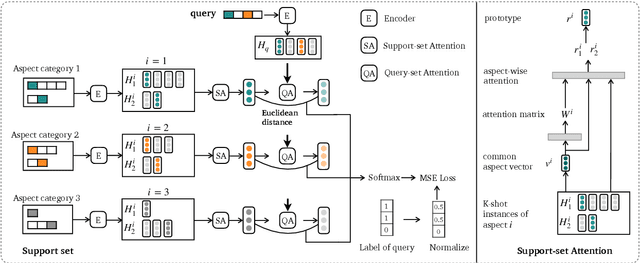
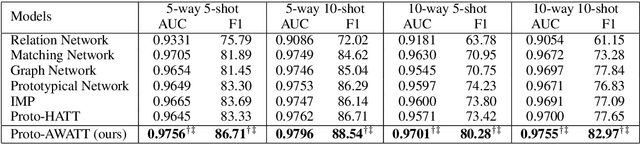
Aspect category detection (ACD) in sentiment analysis aims to identify the aspect categories mentioned in a sentence. In this paper, we formulate ACD in the few-shot learning scenario. However, existing few-shot learning approaches mainly focus on single-label predictions. These methods can not work well for the ACD task since a sentence may contain multiple aspect categories. Therefore, we propose a multi-label few-shot learning method based on the prototypical network. To alleviate the noise, we design two effective attention mechanisms. The support-set attention aims to extract better prototypes by removing irrelevant aspects. The query-set attention computes multiple prototype-specific representations for each query instance, which are then used to compute accurate distances with the corresponding prototypes. To achieve multi-label inference, we further learn a dynamic threshold per instance by a policy network. Extensive experimental results on three datasets demonstrate that the proposed method significantly outperforms strong baselines.
D2A: A Dataset Built for AI-Based Vulnerability Detection Methods Using Differential Analysis
Feb 16, 2021
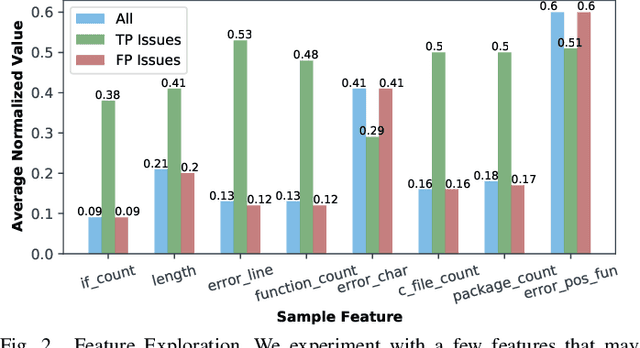


Static analysis tools are widely used for vulnerability detection as they understand programs with complex behavior and millions of lines of code. Despite their popularity, static analysis tools are known to generate an excess of false positives. The recent ability of Machine Learning models to understand programming languages opens new possibilities when applied to static analysis. However, existing datasets to train models for vulnerability identification suffer from multiple limitations such as limited bug context, limited size, and synthetic and unrealistic source code. We propose D2A, a differential analysis based approach to label issues reported by static analysis tools. The D2A dataset is built by analyzing version pairs from multiple open source projects. From each project, we select bug fixing commits and we run static analysis on the versions before and after such commits. If some issues detected in a before-commit version disappear in the corresponding after-commit version, they are very likely to be real bugs that got fixed by the commit. We use D2A to generate a large labeled dataset to train models for vulnerability identification. We show that the dataset can be used to build a classifier to identify possible false alarms among the issues reported by static analysis, hence helping developers prioritize and investigate potential true positives first.
Learning to Detect Opinion Snippet for Aspect-Based Sentiment Analysis
Sep 25, 2019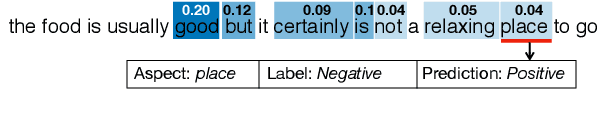
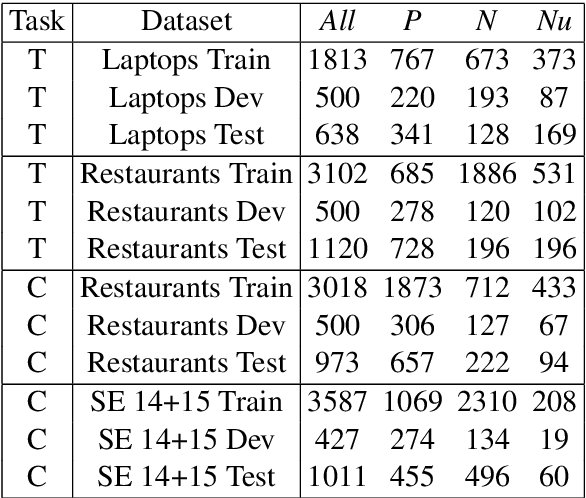
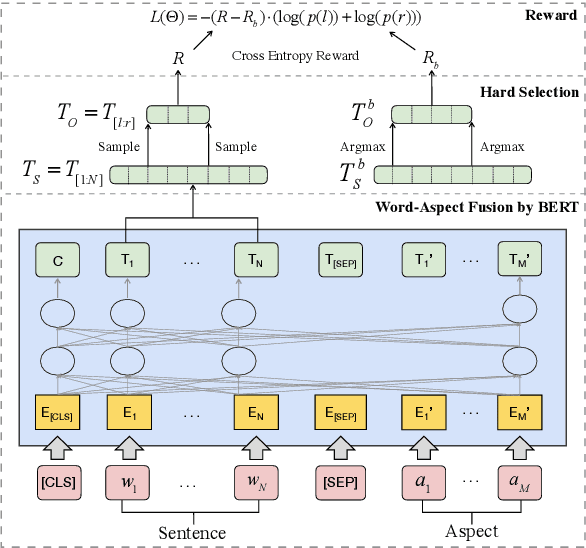
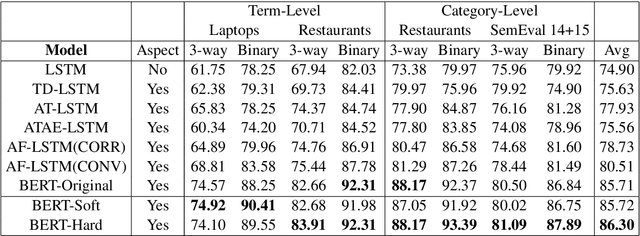
Aspect-based sentiment analysis (ABSA) is to predict the sentiment polarity towards a particular aspect in a sentence. Recently, this task has been widely addressed by the neural attention mechanism, which computes attention weights to softly select words for generating aspect-specific sentence representations. The attention is expected to concentrate on opinion words for accurate sentiment prediction. However, attention is prone to be distracted by noisy or misleading words, or opinion words from other aspects. In this paper, we propose an alternative hard-selection approach, which determines the start and end positions of the opinion snippet, and selects the words between these two positions for sentiment prediction. Specifically, we learn deep associations between the sentence and aspect, and the long-term dependencies within the sentence by leveraging the pre-trained BERT model. We further detect the opinion snippet by self-critical reinforcement learning. Especially, experimental results demonstrate the effectiveness of our method and prove that our hard-selection approach outperforms soft-selection approaches when handling multi-aspect sentences.
Domain-Invariant Feature Distillation for Cross-Domain Sentiment Classification
Aug 24, 2019
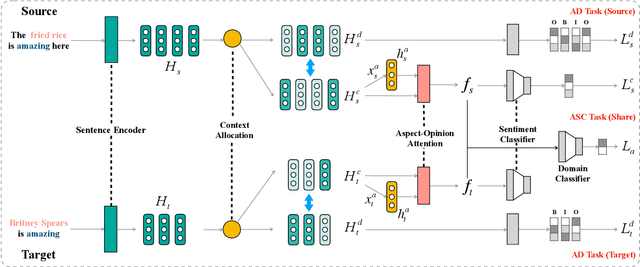
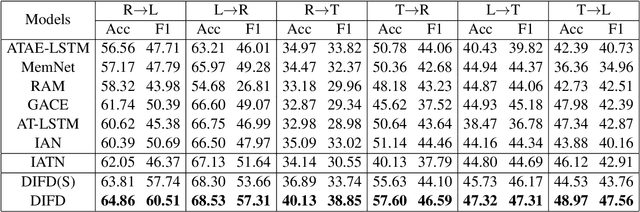
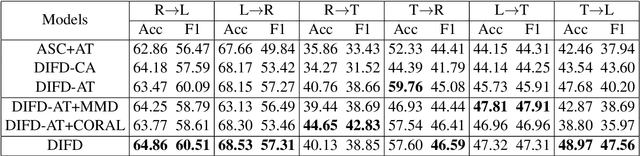
Cross-domain sentiment classification has drawn much attention in recent years. Most existing approaches focus on learning domain-invariant representations in both the source and target domains, while few of them pay attention to the domain-specific information. Despite the non-transferability of the domain-specific information, simultaneously learning domain-dependent representations can facilitate the learning of domain-invariant representations. In this paper, we focus on aspect-level cross-domain sentiment classification, and propose to distill the domain-invariant sentiment features with the help of an orthogonal domain-dependent task, i.e. aspect detection, which is built on the aspects varying widely in different domains. We conduct extensive experiments on three public datasets and the experimental results demonstrate the effectiveness of our method.
Improving Captioning for Low-Resource Languages by Cycle Consistency
Aug 21, 2019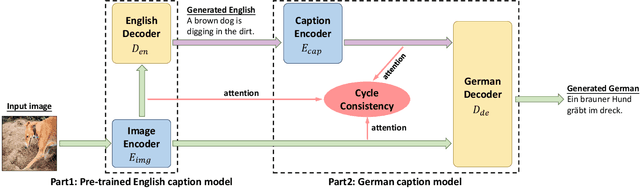
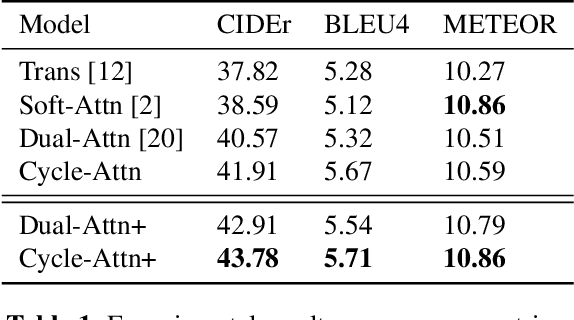
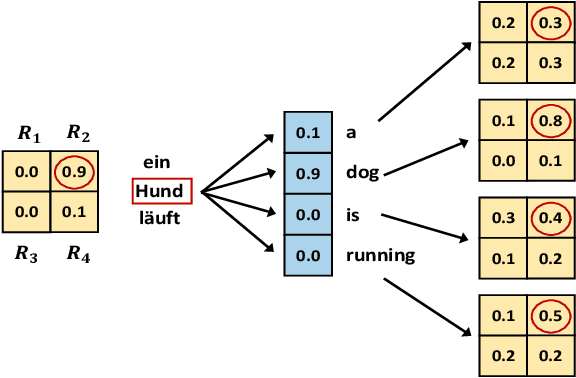

Improving the captioning performance on low-resource languages by leveraging English caption datasets has received increasing research interest in recent years. Existing works mainly fall into two categories: translation-based and alignment-based approaches. In this paper, we propose to combine the merits of both approaches in one unified architecture. Specifically, we use a pre-trained English caption model to generate high-quality English captions, and then take both the image and generated English captions to generate low-resource language captions. We improve the captioning performance by adding the cycle consistency constraint on the cycle of image regions, English words, and low-resource language words. Moreover, our architecture has a flexible design which enables it to benefit from large monolingual English caption datasets. Experimental results demonstrate that our approach outperforms the state-of-the-art methods on common evaluation metrics. The attention visualization also shows that the proposed approach really improves the fine-grained alignment between words and image regions.
P3SGD: Patient Privacy Preserving SGD for Regularizing Deep CNNs in Pathological Image Classification
May 30, 2019
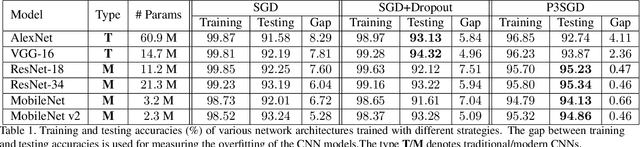
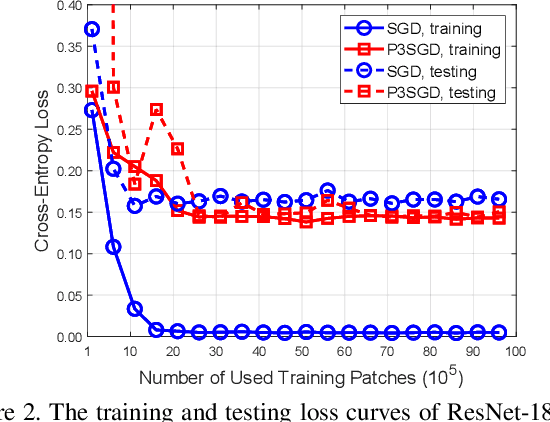
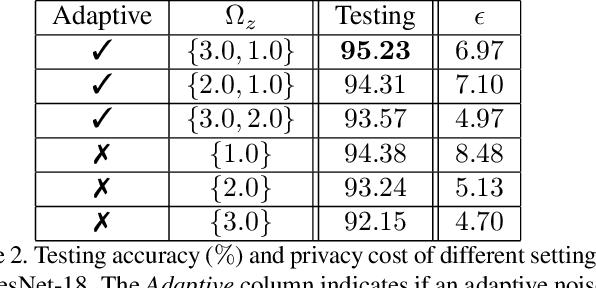
Recently, deep convolutional neural networks (CNNs) have achieved great success in pathological image classification. However, due to the limited number of labeled pathological images, there are still two challenges to be addressed: (1) overfitting: the performance of a CNN model is undermined by the overfitting due to its huge amounts of parameters and the insufficiency of labeled training data. (2) privacy leakage: the model trained using a conventional method may involuntarily reveal the private information of the patients in the training dataset. The smaller the dataset, the worse the privacy leakage. To tackle the above two challenges, we introduce a novel stochastic gradient descent (SGD) scheme, named patient privacy preserving SGD (P3SGD), which performs the model update of the SGD in the patient level via a large-step update built upon each patient's data. Specifically, to protect privacy and regularize the CNN model, we propose to inject the well-designed noise into the updates. Moreover, we equip our P3SGD with an elaborated strategy to adaptively control the scale of the injected noise. To validate the effectiveness of P3SGD, we perform extensive experiments on a real-world clinical dataset and quantitatively demonstrate the superior ability of P3SGD in reducing the risk of overfitting. We also provide a rigorous analysis of the privacy cost under differential privacy. Additionally, we find that the models trained with P3SGD are resistant to the model-inversion attack compared with those trained using non-private SGD.
CAN: Constrained Attention Networks for Multi-Aspect Sentiment Analysis
Dec 27, 2018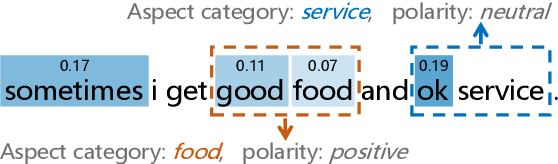
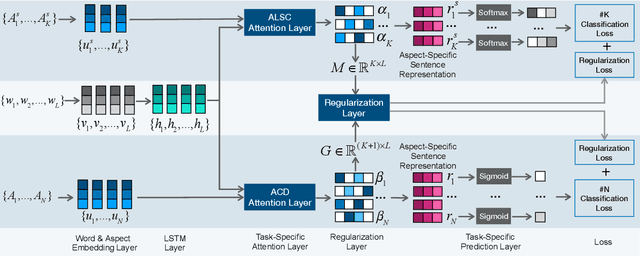
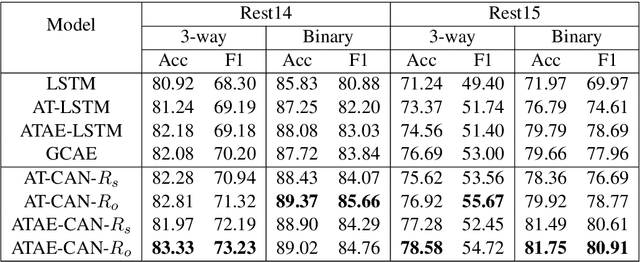
Aspect level sentiment classification is a fine-grained sentiment analysis task, compared to the sentence level classification. A sentence usually contains one or more aspects. To detect the sentiment towards a particular aspect in a sentence, previous studies have developed various methods for generating aspect-specific sentence representations. However, these studies handle each aspect of a sentence separately. In this paper, we argue that multiple aspects of a sentence are usually orthogonal based on the observation that different aspects concentrate on different parts of the sentence. To force the orthogonality among aspects, we propose constrained attention networks (CAN) for multi-aspect sentiment analysis, which handles multiple aspects of a sentence simultaneously. Experimental results on two public datasets demonstrate the effectiveness of our approach. We also extend our approach to multi-task settings, outperforming the state-of-the-arts significantly.