 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How May I Help You? Using Neural Text Simplification to Improve Downstream NLP Tasks
Sep 14, 2021

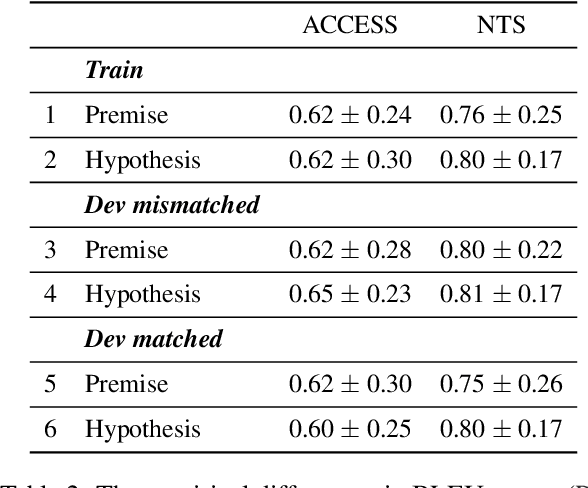
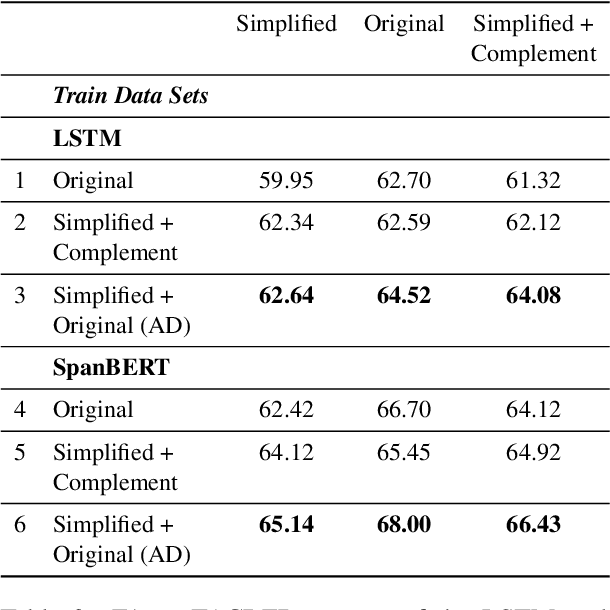
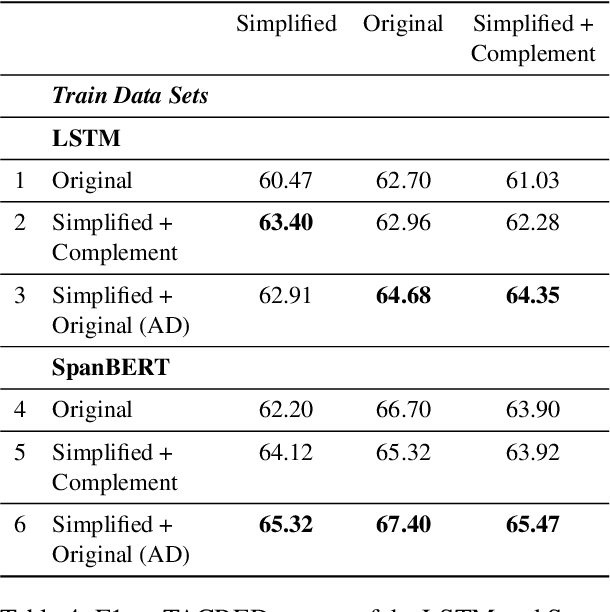
The general goal of text simplification (TS) is to reduce text complexity for human consumption. This paper investigates another potential use of neural TS: assisting machines performing natural language processing (NLP) tasks. We evaluate the use of neural TS in two ways: simplifying input texts at prediction time and augmenting data to provide machines with additional information during training. We demonstrate that the latter scenario provides positive effects on machine performance on two separate datasets. In particular, the latter use of TS improves the performances of LSTM (1.82-1.98%) and SpanBERT (0.7-1.3%) extractors on TACRED, a complex, large-scale, real-world relation extraction task. Further, the same setting yields improvements of up to 0.65% matched and 0.62% mismatched accuracies for a BERT text classifier on MNLI, a practical natural language inference dataset.
Short Term Prediction of Parking Area states Using Real Time Data and Machine Learning Techniques
Nov 29, 2019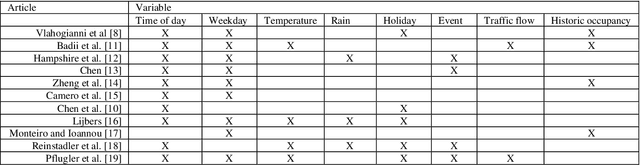
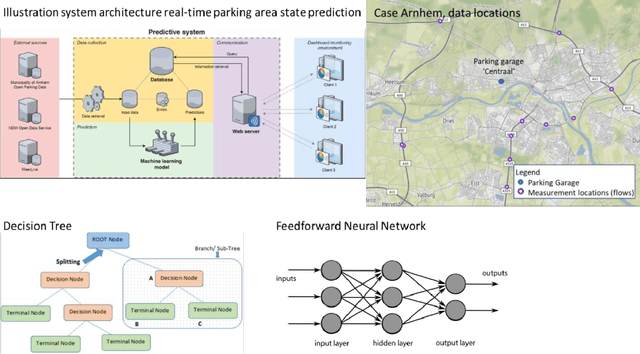
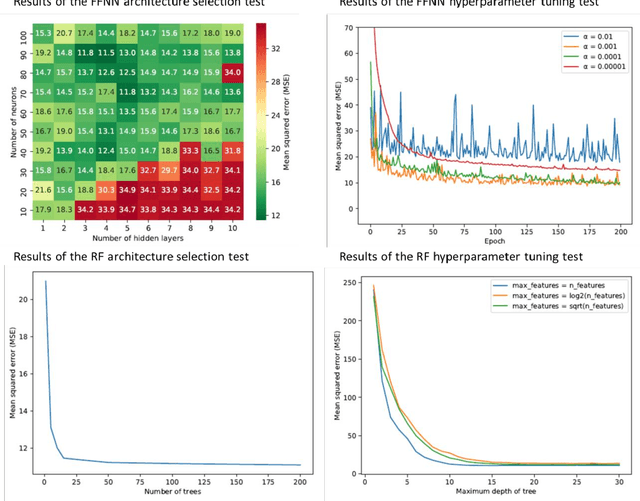
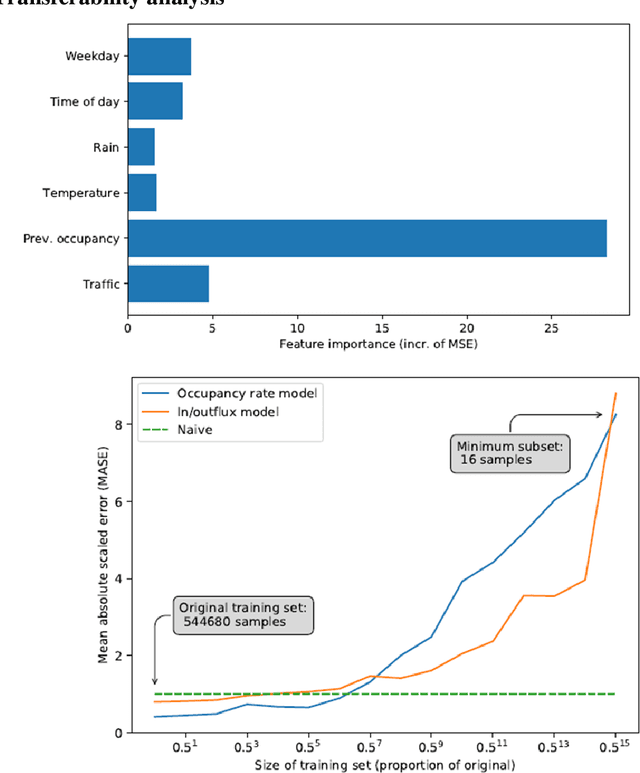
Public road authorities and private mobility service providers need information derived from the current and predicted traffic states to act upon the daily urban system and its spatial and temporal dynamics. In this research, a real-time parking area state (occupancy, in- and outflux) prediction model (up to 60 minutes ahead) has been developed using publicly available historic and real time data sources. Based on a case study in a real-life scenario in the city of Arnhem, a Neural Network-based approach outperforms a Random Forest-based one on all assessed performance measures, although the differences are small. Both are outperforming a naive seasonal random walk model. Although the performance degrades with increasing prediction horizon, the model shows a performance gain of over 150% at a prediction horizon of 60 minutes compared with the naive model. Furthermore, it is shown that predicting the in- and outflux is a far more difficult task (i.e. performance gains of 30%) which needs more training data, not based exclusively on occupancy rate. However, the performance of predicting in- and outflux is less sensitive to the prediction horizon. In addition, it is shown that real-time information of current occupancy rate is the independent variable with the highest contribution to the performance, although time, traffic flow and weather variables also deliver a significant contribution. During real-time deployment, the model performs three times better than the naive model on average. As a result, it can provide valuable information for proactive traffic management as well as mobility service providers.
Deep hierarchical reinforcement agents for automated penetration testing
Sep 14, 2021
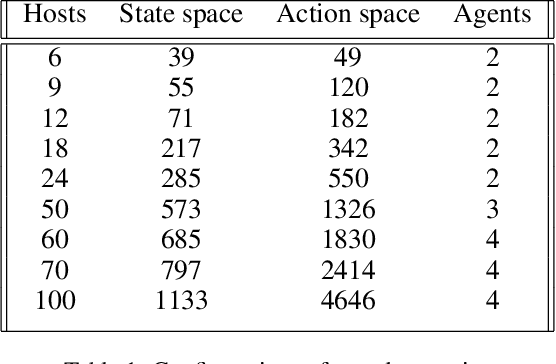
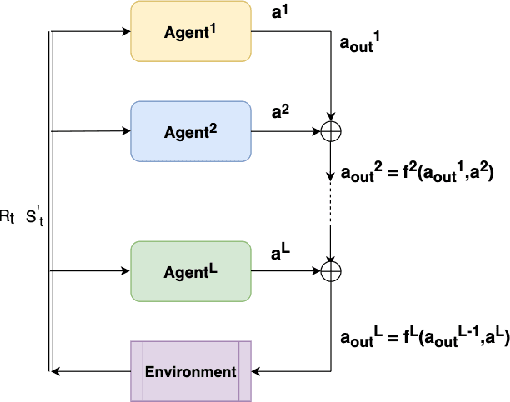
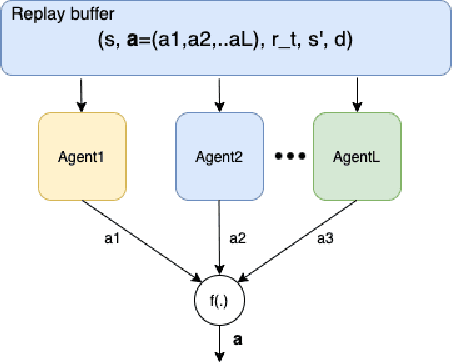
Penetration testing the organised attack of a computer system in order to test existing defences has been used extensively to evaluate network security. This is a time consuming process and requires in-depth knowledge for the establishment of a strategy that resembles a real cyber-attack. This paper presents a novel deep reinforcement learning architecture with hierarchically structured agents called HA-DRL, which employs an algebraic action decomposition strategy to address the large discrete action space of an autonomous penetration testing simulator where the number of actions is exponentially increased with the complexity of the designed cybersecurity network. The proposed architecture is shown to find the optimal attacking policy faster and more stably than a conventional deep Q-learning agent which is commonly used as a method to apply artificial intelligence in automatic penetration testing.
Automated Machine Learning Techniques for Data Streams
Jun 14, 2021
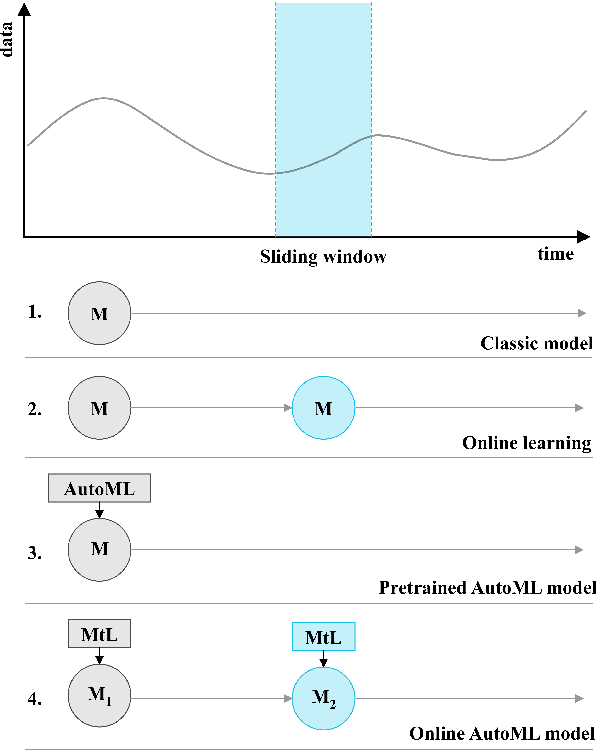
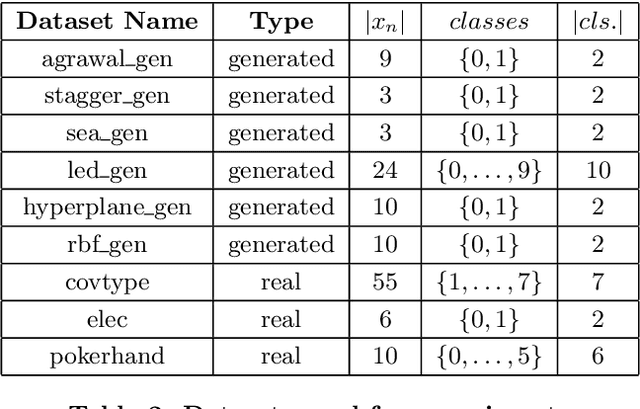
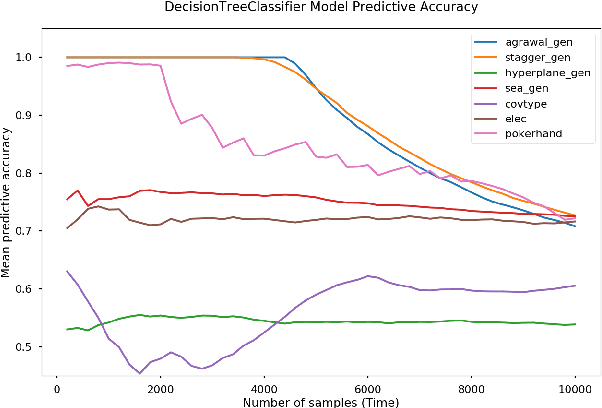
Automated machine learning techniques benefited from tremendous research progress in recently. These developments and the continuous-growing demand for machine learning experts led to the development of numerous AutoML tools. However, these tools assume that the entire training dataset is available upfront and that the underlying distribution does not change over time. These assumptions do not hold in a data stream mining setting where an unbounded stream of data cannot be stored and is likely to manifest concept drift. Industry applications of machine learning on streaming data become more popular due to the increasing adoption of real-time streaming patterns in IoT, microservices architectures, web analytics, and other fields. The research summarized in this paper surveys the state-of-the-art open-source AutoML tools, applies them to data collected from streams, and measures how their performance changes over time. For comparative purposes, batch, batch incremental and instance incremental estimators are applied and compared. Moreover, a meta-learning technique for online algorithm selection based on meta-feature extraction is proposed and compared while model replacement and continual AutoML techniques are discussed. The results show that off-the-shelf AutoML tools can provide satisfactory results but in the presence of concept drift, detection or adaptation techniques have to be applied to maintain the predictive accuracy over time.
Cost-effective vibration analysis through data-backed pipeline optimisation
Aug 16, 2021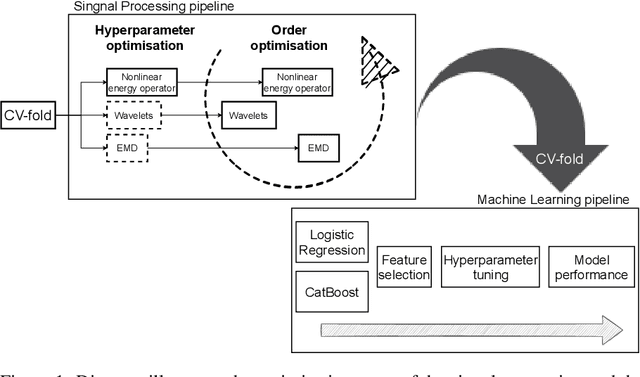

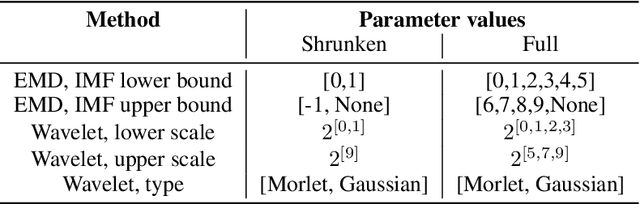
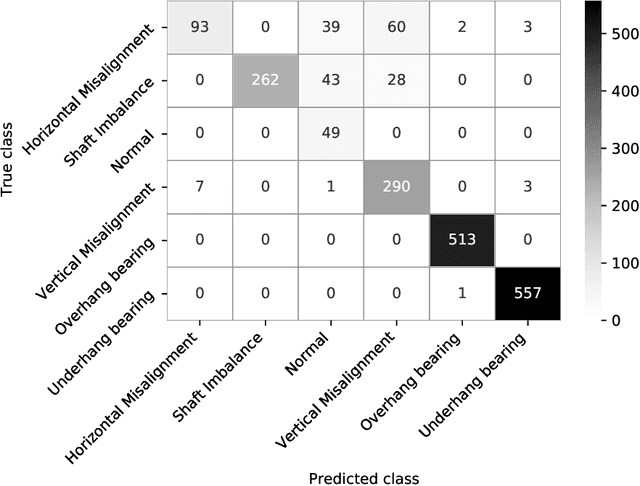
Vibration analysis is an active area of research, aimed, among other targets, at an accurate classification of machinery failure modes. This often leads to complex and convoluted signal processing pipeline designs, which are computationally demanding and cannot be deployed in the Edge devices. In the current work, we address this issue by proposing a data-driven methodology that allows optimising and justifying the complexity of the signal processing pipelines. Additionally, aiming to make IoT vibration analysis systems more cost- and computationally effective, on the example of MAFAULDA vibration dataset, we assess the changes in the failure classification performance at low sampling rates as well as short observation time windows. We find out that a decrease of the sampling rate from 50 kHz to 1 kHz leads to a statistically significant classification performance drop. A statistically significant decrease is also observed for the 0.1 second time windows compared to the 5-second ones. However, the effect sizes are small to medium, suggesting that in certain settings lower sampling rates and shorter observation windows can be used. The proposed optimisation approach, as well as statistically supported findings of the study, allow a more efficient design of IoT vibration analysis systems, both in terms of complexity and costs, bringing us one step closer to the IoT/Edge-based vibration analysis.
MC$^2$-SF: Slow-Fast Learning for Mobile-Cloud Collaborative Recommendation
Sep 25, 2021
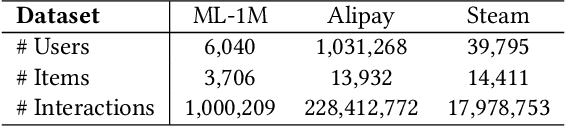
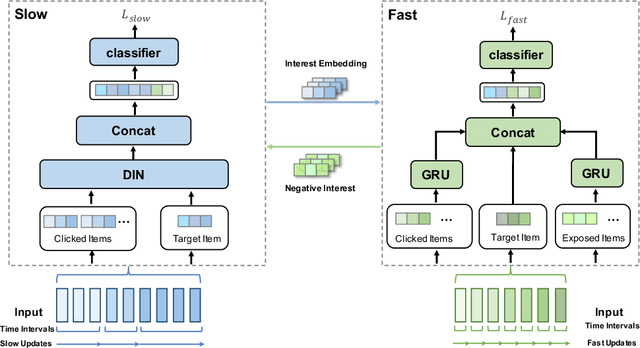
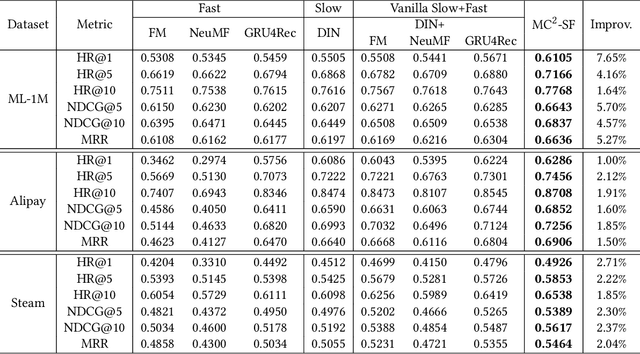
With the hardware development of mobile devices, it is possible to build the recommendation models on the mobile side to utilize the fine-grained features and the real-time feedbacks. Compared to the straightforward mobile-based modeling appended to the cloud-based modeling, we propose a Slow-Fast learning mechanism to make the Mobile-Cloud Collaborative recommendation (MC$^2$-SF) mutual benefit. Specially, in our MC$^2$-SF, the cloud-based model and the mobile-based model are respectively treated as the slow component and the fast component, according to their interaction frequency in real-world scenarios. During training and serving, they will communicate the prior/privileged knowledge to each other to help better capture the user interests about the candidates, resembling the role of System I and System II in the human cognition. We conduct the extensive experiments on three benchmark datasets and demonstrate the proposed MC$^2$-SF outperforms several state-of-the-art methods.
A Fast Computational Optimization for Optimal Control and Trajectory Planning for Obstacle Avoidance between Polytopes
Sep 25, 2021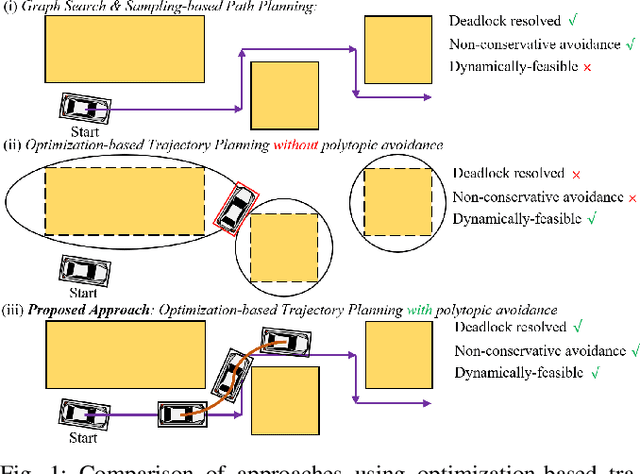

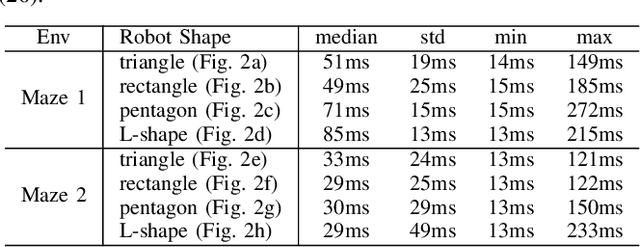
Obstacle avoidance between polytopes is a challenging topic for optimal control and optimization-based trajectory planning problems. Existing work either solves this problem through mixed-integer optimization, relying on simplification of system dynamics, or through model predictive control with dual variables using distance constraints, requiring long horizons for obstacle avoidance. In either case, the solution can only be applied as an offline planning algorithm. In this paper, we exploit the property that a smaller horizon is sufficient for obstacle avoidance by using discrete-time control barrier function (DCBF) constraints and we propose a novel optimization formulation with dual variables based on DCBFs to generate a collision-free dynamically-feasible trajectory. The proposed optimization formulation has lower computational complexity compared to existing work and can be used as a fast online algorithm for control and planning for general nonlinear dynamical systems. We validate our algorithm on different robot shapes using numerical simulations with a kinematic bicycle model, resulting in successful navigation through maze environments with polytopic obstacles.
Spatio-Temporal Dual-Stream Neural Network for Sequential Whole-Body PET Segmentation
Jun 09, 2021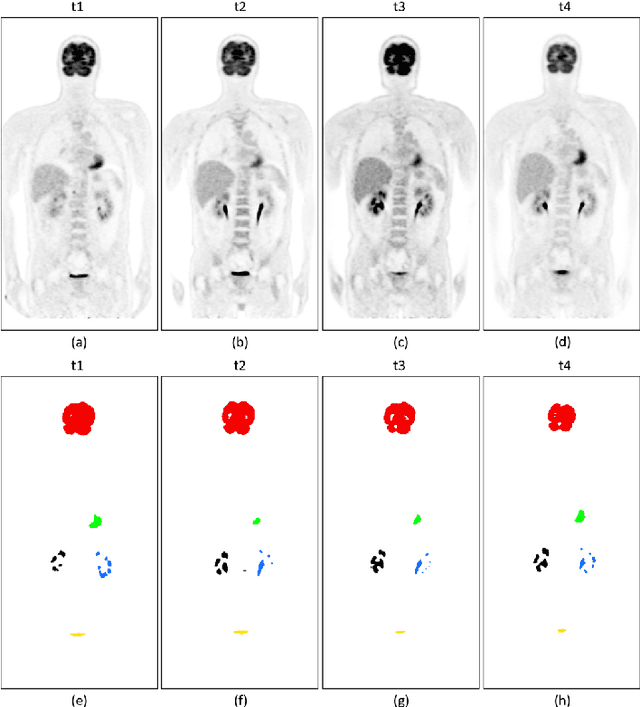

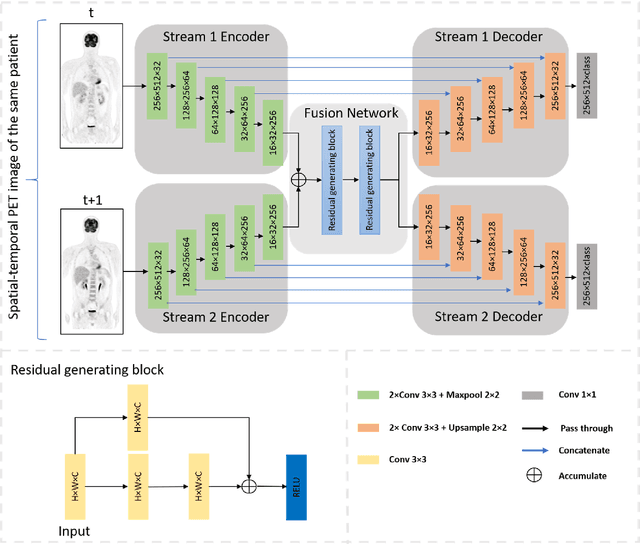
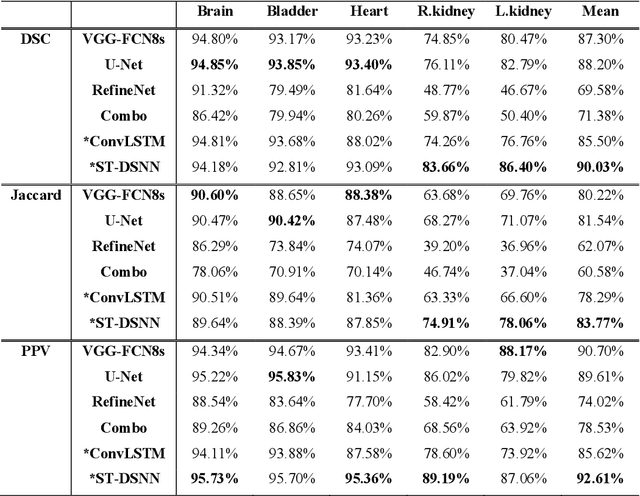
Sequential whole-body 18F-Fluorodeoxyglucose (FDG) positron emission tomography (PET) scans are regarded as the imaging modality of choice for the assessment of treatment response in the lymphomas because they detect treatment response when there may not be changes on anatomical imaging. Any computerized analysis of lymphomas in whole-body PET requires automatic segmentation of the studies so that sites of disease can be quantitatively monitored over time. State-of-the-art PET image segmentation methods are based on convolutional neural networks (CNNs) given their ability to leverage annotated datasets to derive high-level features about the disease process. Such methods, however, focus on PET images from a single time-point and discard information from other scans or are targeted towards specific organs and cannot cater for the multiple structures in whole-body PET images. In this study, we propose a spatio-temporal 'dual-stream' neural network (ST-DSNN) to segment sequential whole-body PET scans. Our ST-DSNN learns and accumulates image features from the PET images done over time. The accumulated image features are used to enhance the organs / structures that are consistent over time to allow easier identification of sites of active lymphoma. Our results show that our method outperforms the state-of-the-art PET image segmentation methods.
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Aug 04, 2021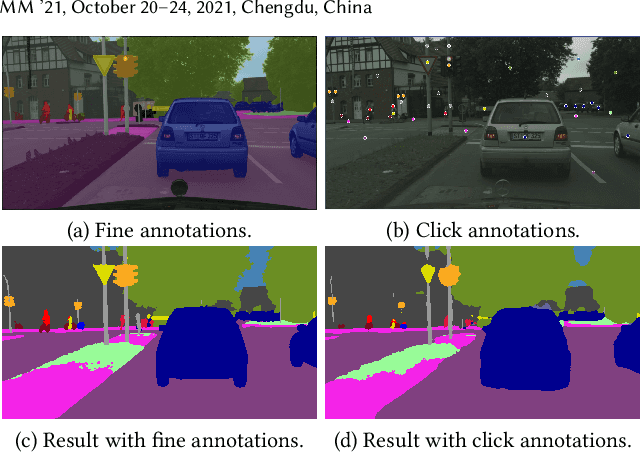
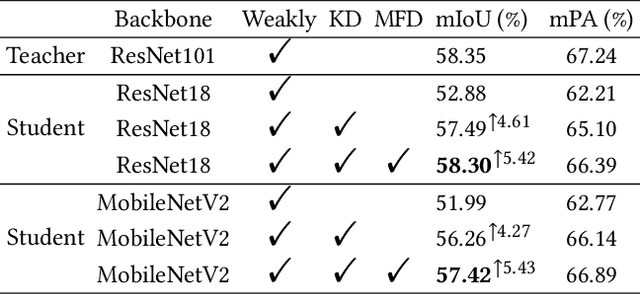
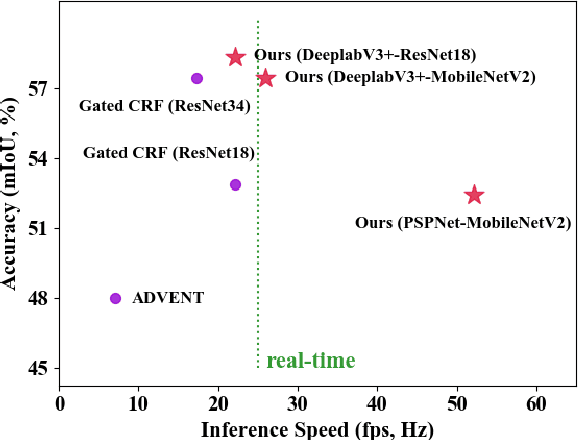
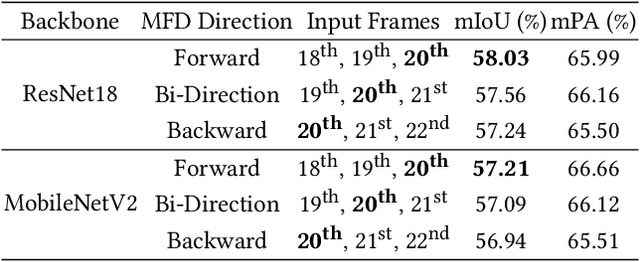
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Efficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation
Oct 13, 2021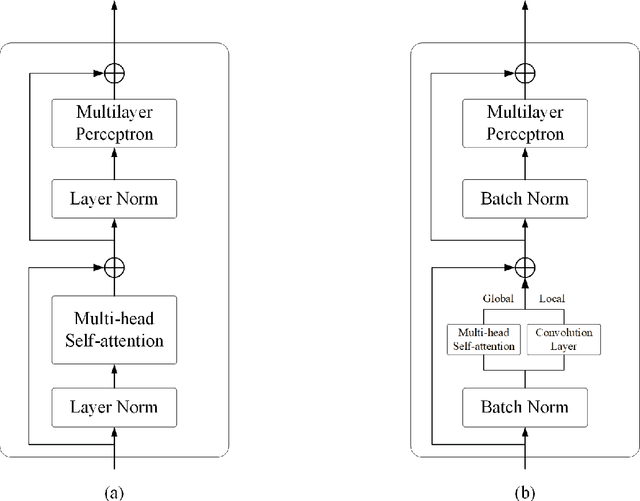

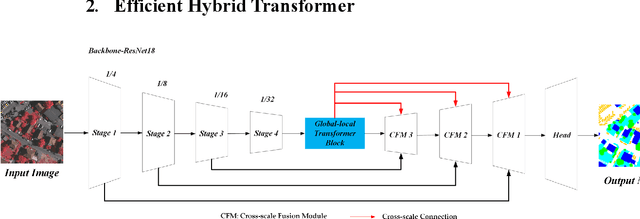
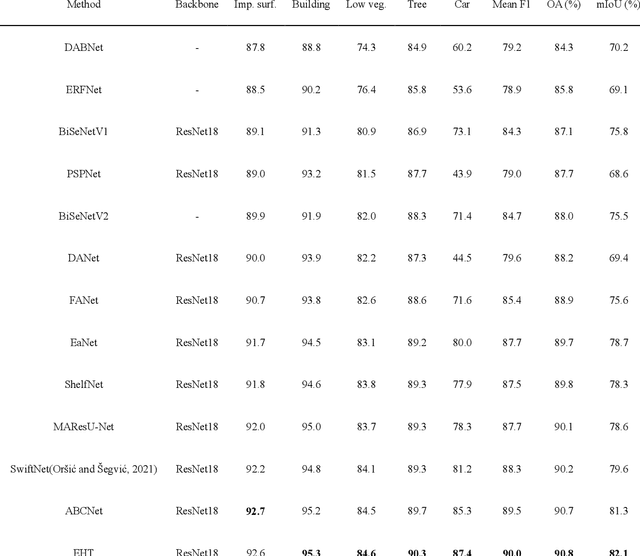
Semantic segmentation of fine-resolution urban scene images plays a vital role in extensive practical applications, such as land cover mapping, urban change detection, environmental protection and economic assessment. Driven by rapid developments in deep learning technologies, the convolutional neural network (CNN) has dominated the semantic segmentation task for many years. Convolutional neural networks adopt hierarchical feature representation, demonstrating strong local information extraction. However, the local property of the convolution layer limits the network from capturing global context that is crucial for precise segmentation. Recently, Transformer comprise a hot topic in the computer vision domain. Transformer demonstrates the great capability of global information modelling, boosting many vision tasks, such as image classification, object detection and especially semantic segmentation. In this paper, we propose an efficient hybrid Transformer (EHT) for real-time urban scene segmentation. The EHT adopts a hybrid structure with and CNN-based encoder and a transformer-based decoder, learning global-local context with lower computation. Extensive experiments demonstrate that our EHT has faster inference speed with competitive accuracy compared with state-of-the-art lightweight models. Specifically, the proposed EHT achieves a 66.9% mIoU on the UAVid test set and outperforms other benchmark networks significantly. The code will be available soon.