 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF3DV-1K: A Large-Scale Dataset and Benchmark for Distractor-Free Novel View Synthesis
Apr 15, 2026Advances in radiance fields have enabled photorealistic novel view synthesis. In several domains, large-scale real-world datasets have been developed to support comprehensive benchmarking and to facilitate progress beyond scene-specific reconstruction. However, for distractor-free radiance fields, a large-scale dataset with clean and cluttered images per scene remains lacking, limiting the development. To address this gap, we introduce DF3DV-1K, a large-scale real-world dataset comprising 1,048 scenes, each providing clean and cluttered image sets for benchmarking. In total, the dataset contains 89,924 images captured using consumer cameras to mimic casual capture, spanning 128 distractor types and 161 scene themes across indoor and outdoor environments. A curated subset of 41 scenes, DF3DV-41, is systematically designed to evaluate the robustness of distractor-free radiance field methods under challenging scenarios. Using DF3DV-1K, we benchmark nine recent distractor-free radiance field methods and 3D Gaussian Splatting, identifying the most robust methods and the most challenging scenarios. Beyond benchmarking, we demonstrate an application of DF3DV-1K by fine-tuning a diffusion-based 2D enhancer to improve radiance field methods, achieving average improvements of 0.96 dB PSNR and 0.057 LPIPS on the held-out set (e.g., DF3DV-41) and the On-the-go dataset. We hope DF3DV-1K facilitates the development of distractor-free vision and promotes progress beyond scene-specific approaches.
An Empirical Study of Multi-Agent Collaboration for Automated Research
Mar 31, 2026As AI agents evolve, the community is rapidly shifting from single Large Language Models (LLMs) to Multi-Agent Systems (MAS) to overcome cognitive bottlenecks in automated research. However, the optimal multi-agent coordination framework for these autonomous agents remains largely unexplored. In this paper, we present a systematic empirical study investigating the comparative efficacy of distinct multi-agent structures for automated machine learning optimization. Utilizing a rigorously controlled, execution-based testbed equipped with Git worktree isolation and explicit global memory, we benchmark a single-agent baseline against two multi-agent paradigms: a subagent architecture (parallel exploration with post-hoc consolidation) and an agent team architecture (experts with pre-execution handoffs). By evaluating these systems under strictly fixed computational time budgets, our findings reveal a fundamental trade-off between operational stability and theoretical deliberation. The subagent mode functions as a highly resilient, high-throughput search engine optimal for broad, shallow optimizations under strict time constraints. Conversely, the agent team topology exhibits higher operational fragility due to multi-author code generation but achieves the deep theoretical alignment necessary for complex architectural refactoring given extended compute budgets. These empirical insights provide actionable guidelines for designing future autoresearch systems, advocating for dynamically routed architectures that adapt their collaborative structures to real-time task complexity.
Neuro-Cognitive Reward Modeling for Human-Centered Autonomous Vehicle Control
Mar 26, 2026Recent advancements in computer vision have accelerated the development of autonomous driving. Despite these advancements, training machines to drive in a way that aligns with human expectations remains a significant challenge. Human factors are still essential, as humans possess a sophisticated cognitive system capable of rapidly interpreting scene information and making accurate decisions. Aligning machine with human intent has been explored with Reinforcement Learning with Human Feedback (RLHF). Conventional RLHF methods rely on collecting human preference data by manually ranking generated outputs, which is time-consuming and indirect. In this work, we propose an electroencephalography (EEG)-guided decision-making framework to incorporate human cognitive insights without behaviour response interruption into reinforcement learning (RL) for autonomous driving. We collected EEG signals from 20 participants in a realistic driving simulator and analyzed event-related potentials (ERP) in response to sudden environmental changes. Our proposed framework employs a neural network to predict the strength of ERP based on the cognitive information from visual scene information. Moreover, we explore the integration of such cognitive information into the reward signal of the RL algorithm. Experimental results show that our framework can improve the collision avoidance ability of the RL algorithm, highlighting the potential of neuro-cognitive feedback in enhancing autonomous driving systems. Our project page is: https://alex95gogo.github.io/Cognitive-Reward/.
Inter- and Intra-Subject Variability in EEG: A Systematic Survey
Feb 01, 2026Electroencephalography (EEG) underpins neuroscience, clinical neurophysiology, and brain-computer interfaces (BCIs), yet pronounced inter- and intra-subject variability limits reliability, reproducibility, and translation. This systematic review studies that quantified or modeled EEG variability across resting-state, event-related potentials (ERPs), and task-related/BCI paradigms (including motor imagery and SSVEP) in healthy and clinical cohorts. Across paradigms, inter-subject differences are typically larger than within-subject fluctuations, but both affect inference and model generalization. Stability is feature-dependent: alpha-band measures and individual alpha peak frequency are often relatively reliable, whereas higher-frequency and many connectivity-derived metrics show more heterogeneous reliability; ERP reliability varies by component, with P300 measures frequently showing moderate-to-good stability. We summarize major sources of variability (biological, state-related, technical, and analytical), review common quantification and modeling approaches (e.g., ICC, CV, SNR, generalizability theory, and multivariate/learning-based methods), and provide recommendations for study design, reporting, and harmonization. Overall, EEG variability should be treated as both a practical constraint to manage and a meaningful signal to leverage for precision neuroscience and robust neurotechnology.
AEGIS: Human Attention-based Explainable Guidance for Intelligent Vehicle Systems
Apr 08, 2025



Improving decision-making capabilities in Autonomous Intelligent Vehicles (AIVs) has been a heated topic in recent years. Despite advancements, training machines to capture regions of interest for comprehensive scene understanding, like human perception and reasoning, remains a significant challenge. This study introduces a novel framework, Human Attention-based Explainable Guidance for Intelligent Vehicle Systems (AEGIS). AEGIS utilizes human attention, converted from eye-tracking, to guide reinforcement learning (RL) models to identify critical regions of interest for decision-making. AEGIS uses a pre-trained human attention model to guide RL models to identify critical regions of interest for decision-making. By collecting 1.2 million frames from 20 participants across six scenarios, AEGIS pre-trains a model to predict human attention patterns.
Q-MARL: A quantum-inspired algorithm using neural message passing for large-scale multi-agent reinforcement learning
Mar 10, 2025


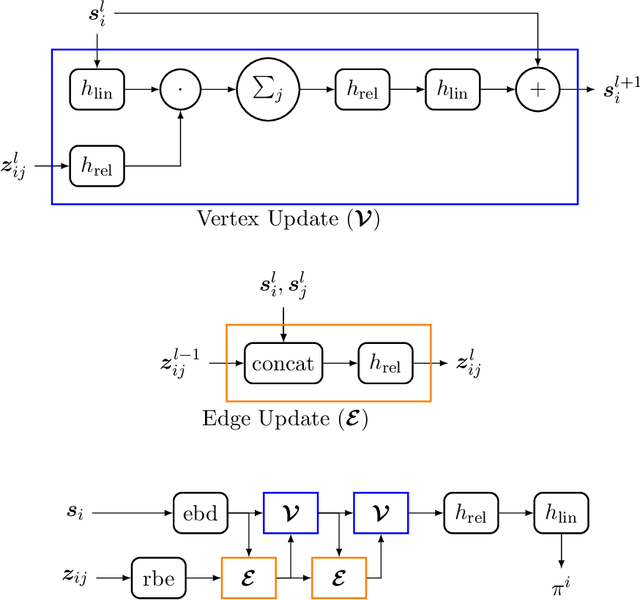
Inspired by a graph-based technique for predicting molecular properties in quantum chemistry -- atoms' position within molecules in three-dimensional space -- we present Q-MARL, a completely decentralised learning architecture that supports very large-scale multi-agent reinforcement learning scenarios without the need for strong assumptions like common rewards or agent order. The key is to treat each agent as relative to its surrounding agents in an environment that is presumed to change dynamically. Hence, in each time step, an agent is the centre of its own neighbourhood and also a neighbour to many other agents. Each role is formulated as a sub-graph, and each sub-graph is used as a training sample. A message-passing neural network supports full-scale vertex and edge interaction within a local neighbourhood, while a parameter governing the depth of the sub-graphs eases the training burden. During testing, an agent's actions are locally ensembled across all the sub-graphs that contain it, resulting in robust decisions. Where other approaches struggle to manage 50 agents, Q-MARL can easily marshal thousands. A detailed theoretical analysis proves improvement and convergence, and simulations with the typical collaborative and competitive scenarios show dramatically faster training speeds and reduced training losses.
Multi-Agent Coordination across Diverse Applications: A Survey
Feb 21, 2025



Multi-agent coordination studies the underlying mechanism enabling the trending spread of diverse multi-agent systems (MAS) and has received increasing attention, driven by the expansion of emerging applications and rapid AI advances. This survey outlines the current state of coordination research across applications through a unified understanding that answers four fundamental coordination questions: (1) what is coordination; (2) why coordination; (3) who to coordinate with; and (4) how to coordinate. Our purpose is to explore existing ideas and expertise in coordination and their connections across diverse applications, while identifying and highlighting emerging and promising research directions. First, general coordination problems that are essential to varied applications are identified and analyzed. Second, a number of MAS applications are surveyed, ranging from widely studied domains, e.g., search and rescue, warehouse automation and logistics, and transportation systems, to emerging fields including humanoid and anthropomorphic robots, satellite systems, and large language models (LLMs). Finally, open challenges about the scalability, heterogeneity, and learning mechanisms of MAS are analyzed and discussed. In particular, we identify the hybridization of hierarchical and decentralized coordination, human-MAS coordination, and LLM-based MAS as promising future directions.
Can ChatGPT Diagnose Alzheimer's Disease?
Feb 10, 2025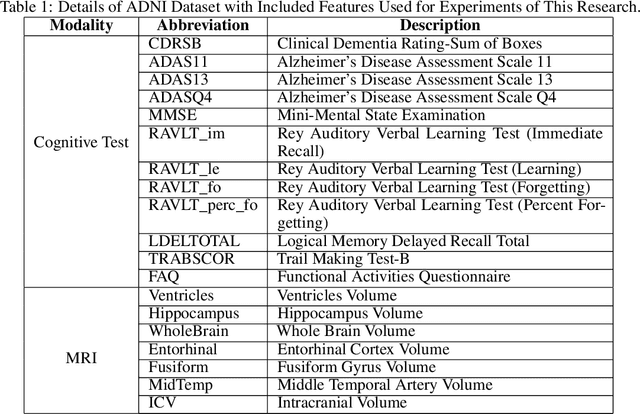



Can ChatGPT diagnose Alzheimer's Disease (AD)? AD is a devastating neurodegenerative condition that affects approximately 1 in 9 individuals aged 65 and older, profoundly impairing memory and cognitive function. This paper utilises 9300 electronic health records (EHRs) with data from Magnetic Resonance Imaging (MRI) and cognitive tests to address an intriguing question: As a general-purpose task solver, can ChatGPT accurately detect AD using EHRs? We present an in-depth evaluation of ChatGPT using a black-box approach with zero-shot and multi-shot methods. This study unlocks ChatGPT's capability to analyse MRI and cognitive test results, as well as its potential as a diagnostic tool for AD. By automating aspects of the diagnostic process, this research opens a transformative approach for the healthcare system, particularly in addressing disparities in resource-limited regions where AD specialists are scarce. Hence, it offers a foundation for a promising method for early detection, supporting individuals with timely interventions, which is paramount for Quality of Life (QoL).
Neural Spelling: A Spell-Based BCI System for Language Neural Decoding
Jan 29, 2025



Brain-computer interfaces (BCIs) present a promising avenue by translating neural activity directly into text, eliminating the need for physical actions. However, existing non-invasive BCI systems have not successfully covered the entire alphabet, limiting their practicality. In this paper, we propose a novel non-invasive EEG-based BCI system with Curriculum-based Neural Spelling Framework, which recognizes all 26 alphabet letters by decoding neural signals associated with handwriting first, and then apply a Generative AI (GenAI) to enhance spell-based neural language decoding tasks. Our approach combines the ease of handwriting with the accessibility of EEG technology, utilizing advanced neural decoding algorithms and pre-trained large language models (LLMs) to translate EEG patterns into text with high accuracy. This system show how GenAI can improve the performance of typical spelling-based neural language decoding task, and addresses the limitations of previous methods, offering a scalable and user-friendly solution for individuals with communication impairments, thereby enhancing inclusive communication options.
Contrastive Masked Autoencoders for Character-Level Open-Set Writer Identification
Jan 21, 2025



In the realm of digital forensics and document authentication, writer identification plays a crucial role in determining the authors of documents based on handwriting styles. The primary challenge in writer-id is the "open-set scenario", where the goal is accurately recognizing writers unseen during the model training. To overcome this challenge, representation learning is the key. This method can capture unique handwriting features, enabling it to recognize styles not previously encountered during training. Building on this concept, this paper introduces the Contrastive Masked Auto-Encoders (CMAE) for Character-level Open-Set Writer Identification. We merge Masked Auto-Encoders (MAE) with Contrastive Learning (CL) to simultaneously and respectively capture sequential information and distinguish diverse handwriting styles. Demonstrating its effectiveness, our model achieves state-of-the-art (SOTA) results on the CASIA online handwriting dataset, reaching an impressive precision rate of 89.7%. Our study advances universal writer-id with a sophisticated representation learning approach, contributing substantially to the ever-evolving landscape of digital handwriting analysis, and catering to the demands of an increasingly interconnected world.