 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Meta-Auto-Decoder for Solving Parametric Partial Differential Equations
Nov 15, 2021
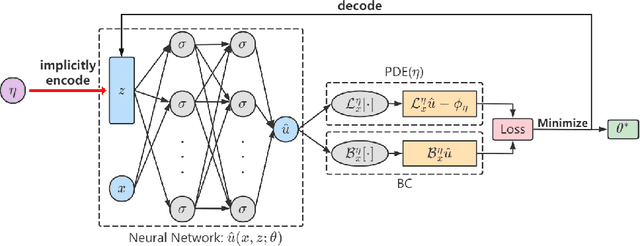
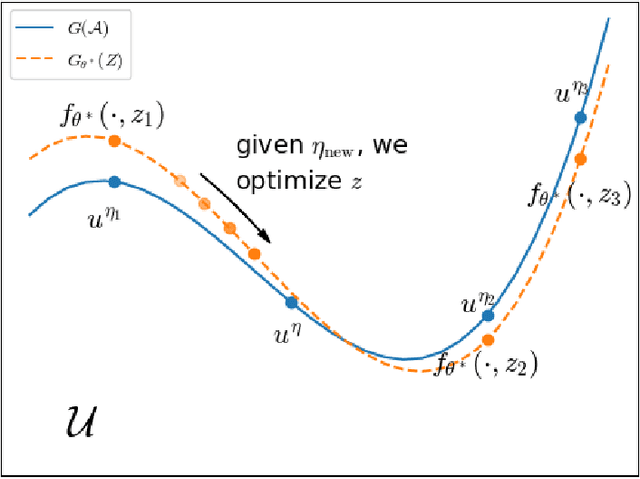
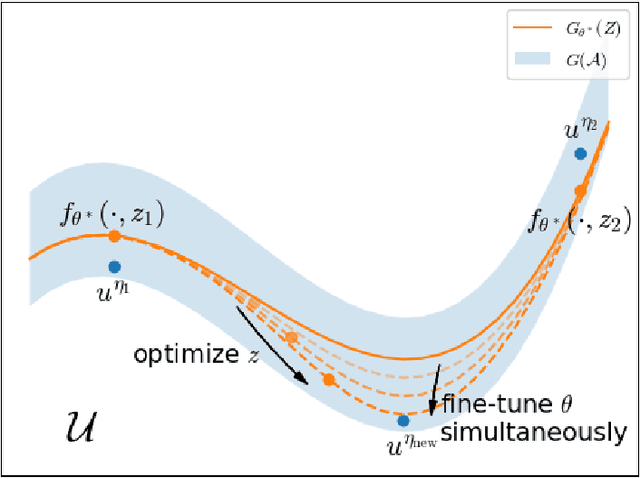
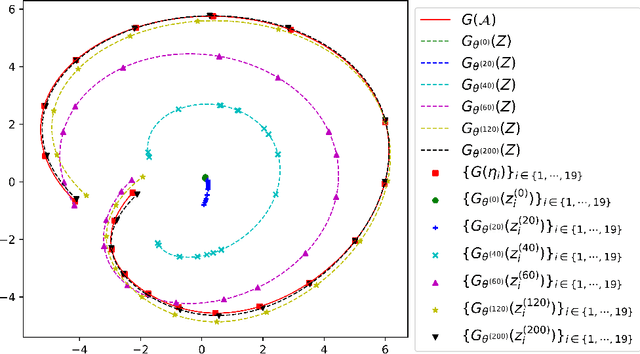
Partial Differential Equations (PDEs) are ubiquitous in many disciplines of science and engineering and notoriously difficult to solve. In general, closed-form solutions of PDEs are unavailable and numerical approximation methods are computationally expensive. The parameters of PDEs are variable in many applications, such as inverse problems, control and optimization, risk assessment, and uncertainty quantification. In these applications, our goal is to solve parametric PDEs rather than one instance of them. Our proposed approach, called Meta-Auto-Decoder (MAD), treats solving parametric PDEs as a meta-learning problem and utilizes the Auto-Decoder structure in \cite{park2019deepsdf} to deal with different tasks/PDEs. Physics-informed losses induced from the PDE governing equations and boundary conditions is used as the training losses for different tasks. The goal of MAD is to learn a good model initialization that can generalize across different tasks, and eventually enables the unseen task to be learned faster. The inspiration of MAD comes from (conjectured) low-dimensional structure of parametric PDE solutions and we explain our approach from the perspective of manifold learning. Finally, we demonstrate the power of MAD though extensive numerical studies, including Burgers' equation, Laplace's equation and time-domain Maxwell's equations. MAD exhibits faster convergence speed without losing the accuracy compared with other deep learning methods.
FAST: DNN Training Under Variable Precision Block Floating Point with Stochastic Rounding
Oct 28, 2021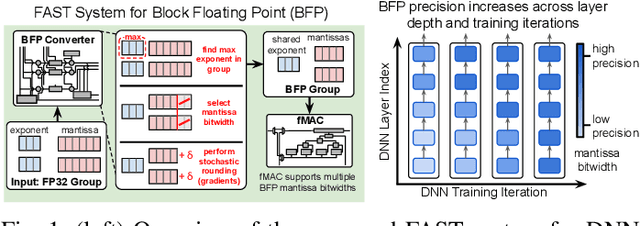
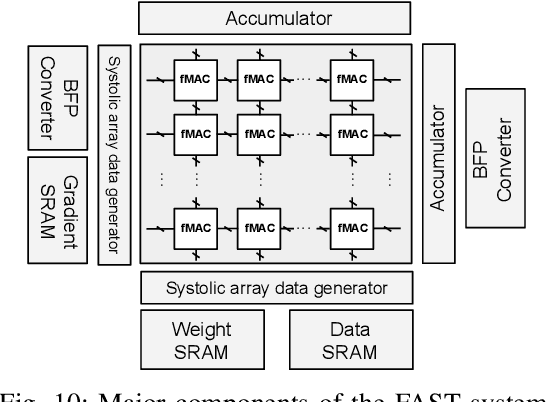
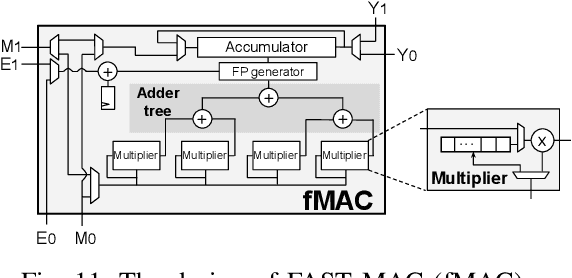
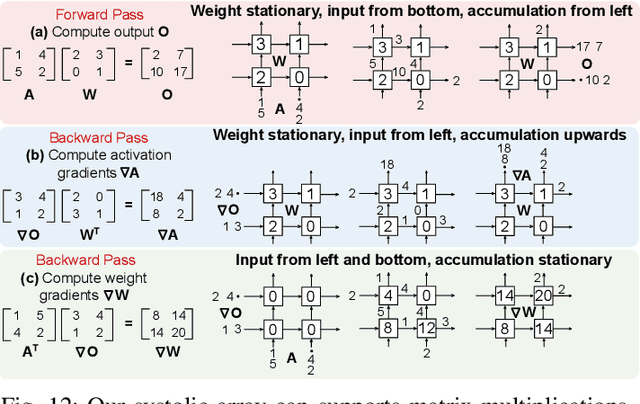
Block Floating Point (BFP) can efficiently support quantization for Deep Neural Network (DNN) training by providing a wide dynamic range via a shared exponent across a group of values. In this paper, we propose a Fast First, Accurate Second Training (FAST) system for DNNs, where the weights, activations, and gradients are represented in BFP. FAST supports matrix multiplication with variable precision BFP input operands, enabling incremental increases in DNN precision throughout training. By increasing the BFP precision across both training iterations and DNN layers, FAST can greatly shorten the training time while reducing overall hardware resource usage. Our FAST Multipler-Accumulator (fMAC) supports dot product computations under multiple BFP precisions. We validate our FAST system on multiple DNNs with different datasets, demonstrating a 2-6$\times$ speedup in training on a single-chip platform over prior work based on \textbf{mixed-precision or block} floating point number systems while achieving similar performance in validation accuracy.
Online Coverage Planning for an Autonomous Weed Mowing Robot with Curvature Constraints
Nov 19, 2021
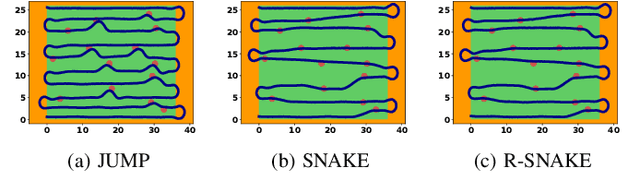
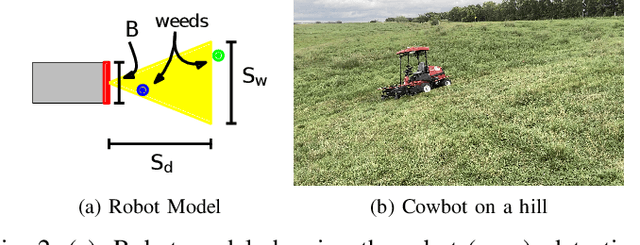
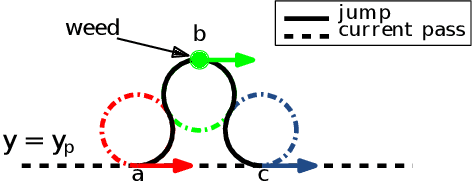
The land used for grazing cattle takes up about one-third of the land in the United States. These areas can be highly rugged. Yet, they need to be maintained to prevent weeds from taking over the nutritious grassland. This can be a daunting task especially in the case of organic farming since herbicides cannot be used. In this paper, we present the design of Cowbot, an autonomous weed mowing robot for pastures. Cowbot is an electric mower designed to operate in the rugged environments on cow pastures and provide a cost-effective method for weed control in organic farms. Path planning for the Cowbot is challenging since weed distribution on pastures is unknown. Given a limited field of view, online path planning is necessary to detect weeds and plan paths to mow them. We study the general online path planning problem for an autonomous mower with curvature and field of view constraints. We develop two online path planning algorithms that are able to utilize new information about weeds to optimize path length and ensure coverage. We deploy our algorithms on the Cowbot and perform field experiments to validate the suitability of our methods for real-time path planning. We also perform extensive simulation experiments which show that our algorithms result in up to 60 % reduction in path length as compared to baseline boustrophedon and random-search based coverage paths.
Unified Sample-Optimal Property Estimation in Near-Linear Time
Nov 08, 2019
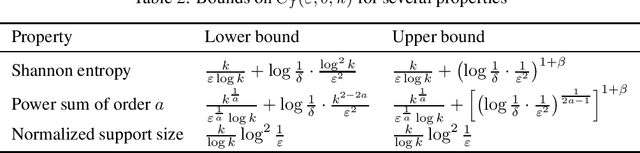
We consider the fundamental learning problem of estimating properties of distributions over large domains. Using a novel piecewise-polynomial approximation technique, we derive the first unified methodology for constructing sample- and time-efficient estimators for all sufficiently smooth, symmetric and non-symmetric, additive properties. This technique yields near-linear-time computable estimators whose approximation values are asymptotically optimal and highly-concentrated, resulting in the first: 1) estimators achieving the $\mathcal{O}(k/(\varepsilon^2\log k))$ min-max $\varepsilon$-error sample complexity for all $k$-symbol Lipschitz properties; 2) unified near-optimal differentially private estimators for a variety of properties; 3) unified estimator achieving optimal bias and near-optimal variance for five important properties; 4) near-optimal sample-complexity estimators for several important symmetric properties over both domain sizes and confidence levels. In addition, we establish a McDiarmid's inequality under Poisson sampling, which is of independent interest.
Amortized Causal Discovery: Learning to Infer Causal Graphs from Time-Series Data
Jun 18, 2020
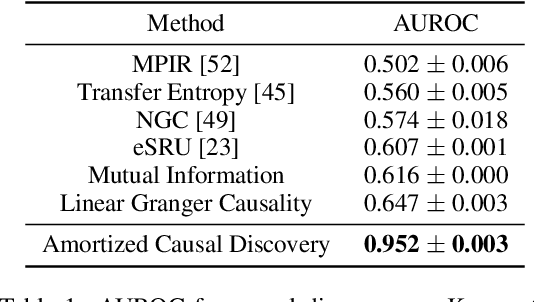
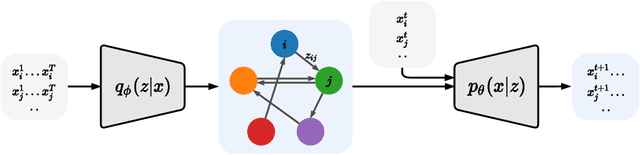
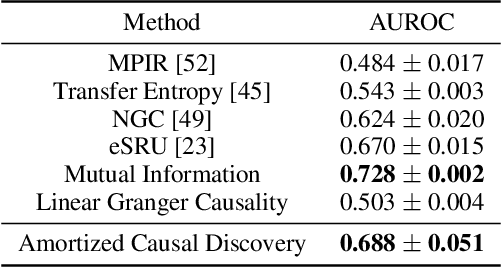
Standard causal discovery methods must fit a new model whenever they encounter samples from a new underlying causal graph. However, these samples often share relevant information - for instance, the dynamics describing the effects of causal relations - which is lost when following this approach. We propose Amortized Causal Discovery, a novel framework that leverages such shared dynamics to learn to infer causal relations from time-series data. This enables us to train a single, amortized model that infers causal relations across samples with different underlying causal graphs, and thus makes use of the information that is shared. We demonstrate experimentally that this approach, implemented as a variational model, leads to significant improvements in causal discovery performance, and show how it can be extended to perform well under hidden confounding.
Who will dropout from university? Academic risk prediction based on interpretable machine learning
Dec 02, 2021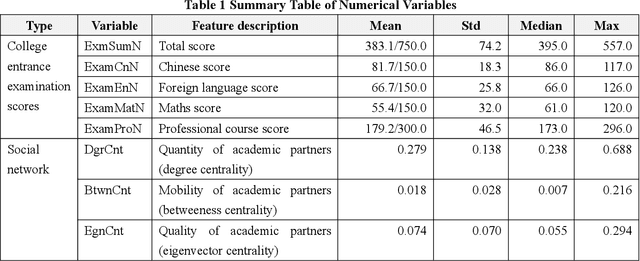
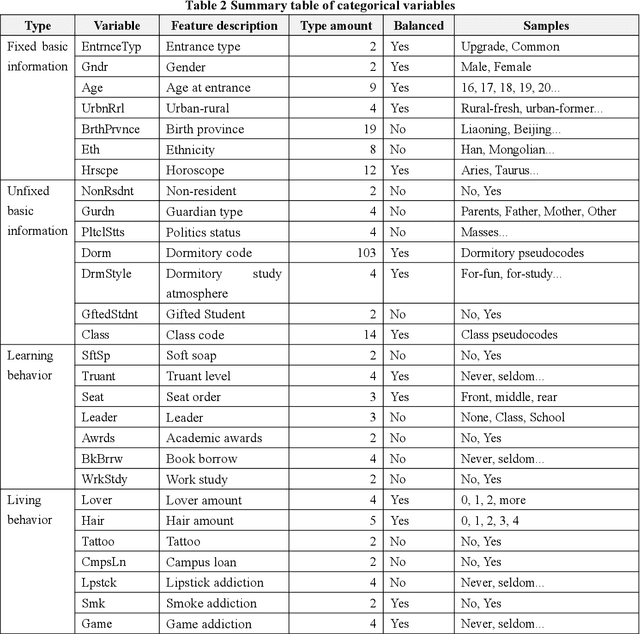
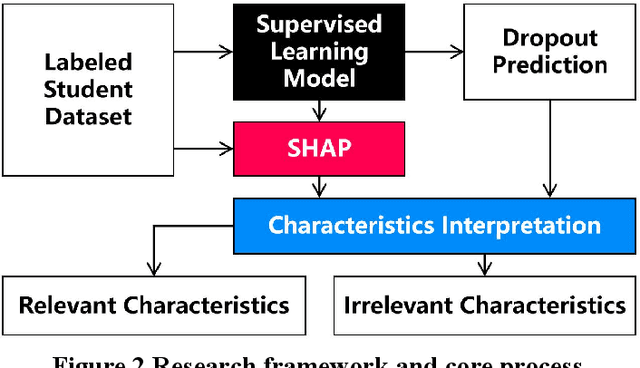
In the institutional research mode, in order to explore which characteristics are the best indicators for predicting academic risk from the student behavior data sets that have high-dimensional, unbalanced classified small sample, it transforms the academic risk prediction of college students into a binary classification task. It predicts academic risk based on the LightGBM model and the interpretable machine learning method of Shapley value. The simulation results show that from the global perspective of the prediction model, characteristics such as the quality of academic partners, the seating position in classroom, the dormitory study atmosphere, the English scores of the college entrance examination, the quantity of academic partners, the addiction level of video games, the mobility of academic partners, and the degree of truancy are the best 8 predictors for academic risk. It is contrary to intuition that characteristics such as living in campus or not, work-study, lipstick addiction, student leader or not, lover amount, and smoking have little correlation with university academic risk in this experiment. From the local perspective of the sample, the factors affecting academic risk vary from person to person. It can perform personalized interpretable analysis through Shapley values, which cannot be done by traditional mathematical statistical prediction models. The academic contributions of this research are mainly in two aspects: First, the learning interaction networks is proposed for the first time, so that social behavior can be used to compensate for the one-sided individual behavior and improve the performance of academic risk prediction. Second, the introduction of Shapley value calculation makes machine learning that lacks a clear reasoning process visualized, and provides intuitive decision support for education managers.
Throughput Maximization for IRS-Aided MIMO FD-WPCN with Non-Linear EH Model
Nov 28, 2021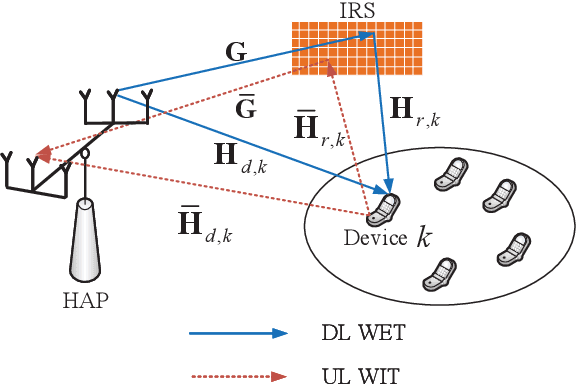
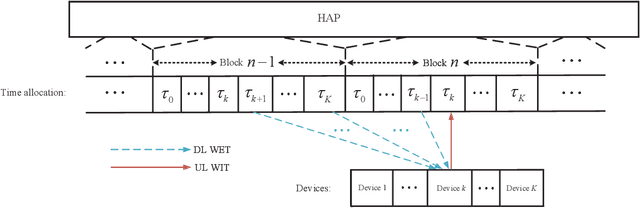
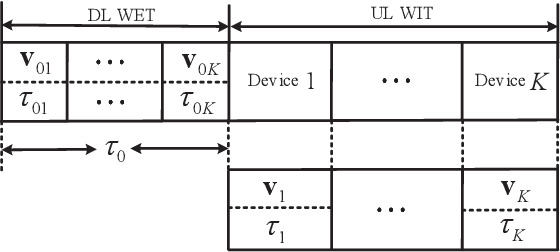
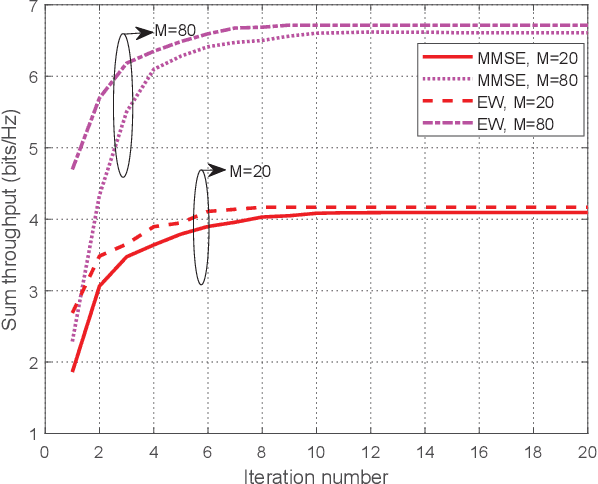
This paper studies an intelligent reflecting surface (IRS)-aided multiple-input-multiple-output (MIMO) full-duplex (FD) wireless-powered communication network (WPCN), where a hybrid access point (HAP) operating in FD broadcasts energy signals to multiple devices for their energy harvesting (EH) in the downlink (DL) and meanwhile receives information signals from devices in the uplink (UL) with the help of an IRS. Taking into account the practical finite self-interference (SI) and the non-linear EH model, we formulate the weighted sum throughput maximization optimization problem by jointly optimizing DL/UL time allocation, precoding matrices at devices, transmit covariance matrices at the HAP, and phase shifts at the IRS. Since the resulting optimization problem is non-convex, there are no standard methods to solve it optimally in general. To tackle this challenge, we first propose an element-wise (EW) based algorithm, where each IRS phase shift is alternately optimized in an iterative manner. To reduce the computational complexity, a minimum mean-square error (MMSE) based algorithm is proposed, where we transform the original problem into an equivalent form based on the MMSE method, which facilities the design of an efficient iterative algorithm. In particular, the IRS phase shift optimization problem is recast as an second-order cone program (SOCP), where all the IRS phase shifts are simultaneously optimized. For comparison, we also study two suboptimal IRS beamforming configurations in simulations, namely partially dynamic IRS beamforming (PDBF) and static IRS beamforming (SBF), which strike a balance between the system performance and practical complexity.
Machine-Learned HASDM Model with Uncertainty Quantification
Sep 16, 2021
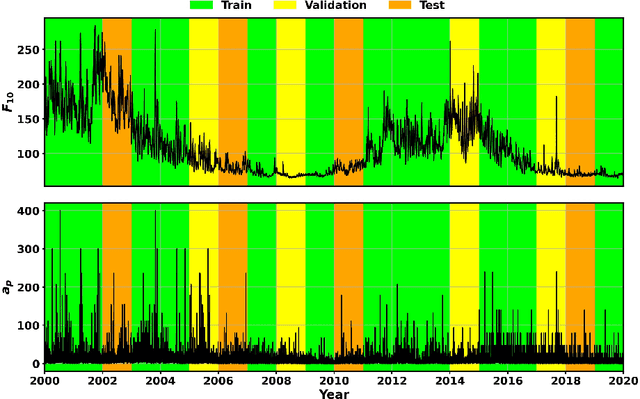
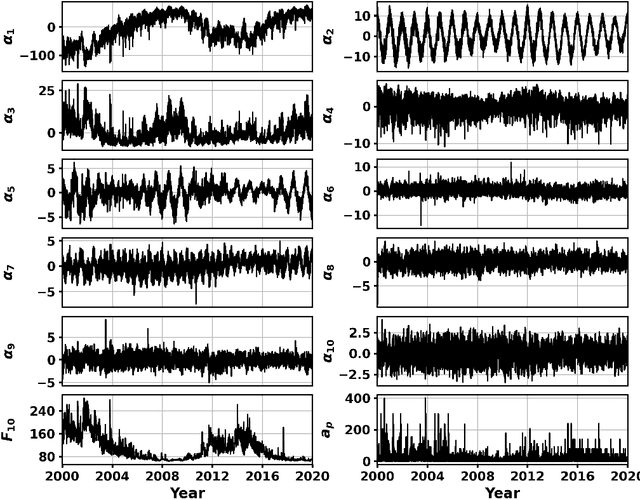
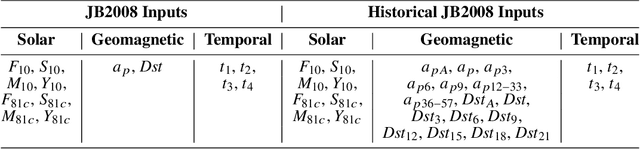
The first thermospheric neutral mass density model with robust and reliable uncertainty estimates is developed based on the SET HASDM density database. This database, created by Space Environment Technologies (SET), contains 20 years of outputs from the U.S. Space Force's High Accuracy Satellite Drag Model (HASDM), which represents the state-of-the-art for density and drag modeling. We utilize principal component analysis (PCA) for dimensionality reduction, creating the coefficients upon which nonlinear machine-learned (ML) regression models are trained. These models use three unique loss functions: mean square error (MSE), negative logarithm of predictive density (NLPD), and continuous ranked probability score (CRPS). Three input sets are also tested, showing improved performance when introducing time histories for geomagnetic indices. These models leverage Monte Carlo (MC) dropout to provide uncertainty estimates, and the use of the NLPD loss function results in well-calibrated uncertainty estimates without sacrificing model accuracy (<10% mean absolute error). By comparing the best HASDM-ML model to the HASDM database along satellite orbits, we found that the model provides robust and reliable uncertainties in the density space over all space weather conditions. A storm-time comparison shows that HASDM-ML also supplies meaningful uncertainty measurements during extreme events.
Optimal Discrete Constellation Inputs for Aggregated LiFi-WiFi Networks
Nov 04, 2021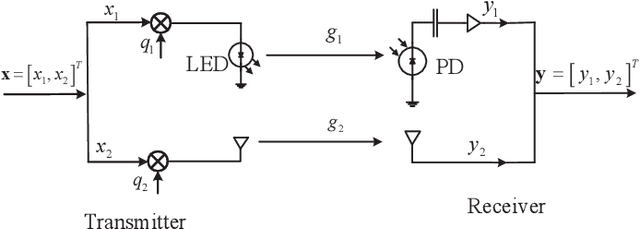

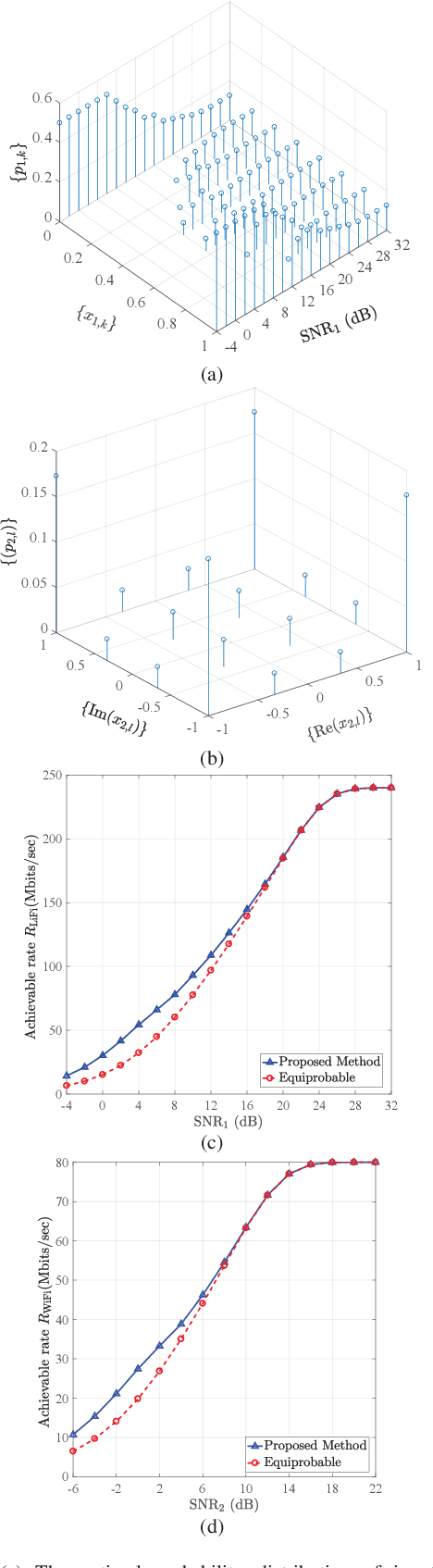

In this paper, we investigate the performance of a practical aggregated LiFi-WiFi system with the discrete constellation inputs from a practical view. We derive the achievable rate expressions of the aggregated LiFi-WiFi system for the first time. Then, we study the rate maximization problem via optimizing the constellation distribution and power allocation jointly. Specifically, a multilevel mercy-filling power allocation scheme is proposed by exploiting the relationship between the mutual information and minimum mean-squared error (MMSE) of discrete inputs. Meanwhile, an inexact gradient descent method is proposed for obtaining the optimal probability distributions. To strike a balance between the computational complexity and the transmission performance, we further develop a framework that maximizes the lower bound of the achievable rate where the optimal power allocation can be obtained in closed forms and the constellation distributions problem can be solved efficiently by Frank-Wolfe method. Extensive numerical results show that the optimized strategies are able to provide significant gains over the state-of-the-art schemes in terms of the achievable rate.
MultiTask-CenterNet (MCN): Efficient and Diverse Multitask Learning using an Anchor Free Approach
Sep 10, 2021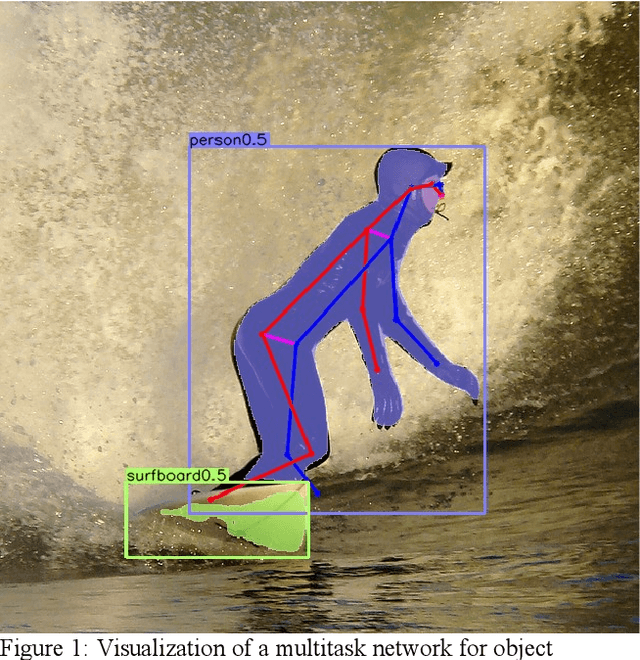

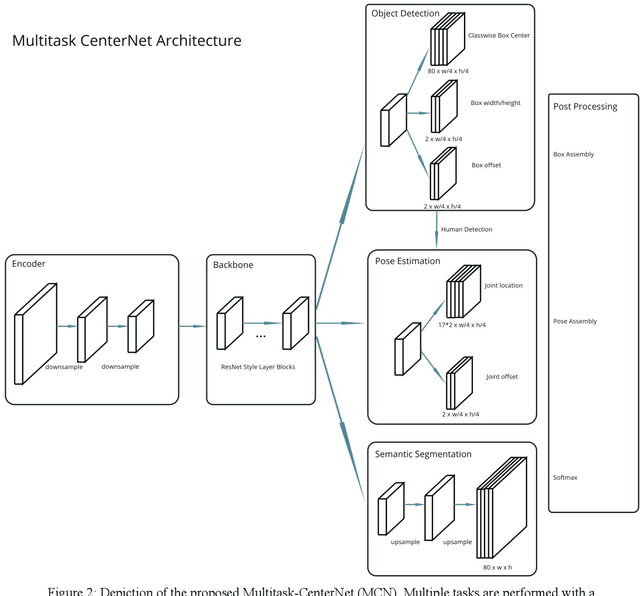
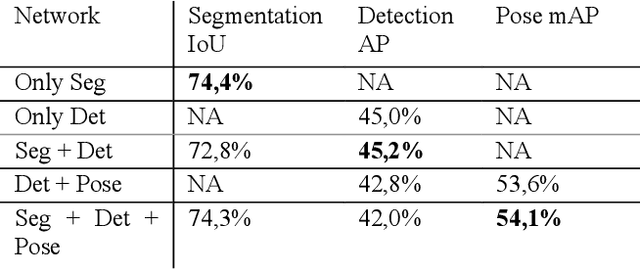
Multitask learning is a common approach in machine learning, which allows to train multiple objectives with a shared architecture. It has been shown that by training multiple tasks together inference time and compute resources can be saved, while the objectives performance remains on a similar or even higher level. However, in perception related multitask networks only closely related tasks can be found, such as object detection, instance and semantic segmentation or depth estimation. Multitask networks with diverse tasks and their effects with respect to efficiency on one another are not well studied. In this paper we augment the CenterNet anchor-free approach for training multiple diverse perception related tasks together, including the task of object detection and semantic segmentation as well as human pose estimation. We refer to this DNN as Multitask-CenterNet (MCN). Additionally, we study different MCN settings for efficiency. The MCN can perform several tasks at once while maintaining, and in some cases even exceeding, the performance values of its corresponding single task networks. More importantly, the MCN architecture decreases inference time and reduces network size when compared to a composition of single task networks.