 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-Spec: Expert Budgeting for Efficient Speculative Decoding
Feb 17, 2026Speculative decoding accelerates Large Language Model (LLM) inference by verifying multiple drafted tokens in parallel. However, for Mixture-of-Experts (MoE) models, this parallelism introduces a severe bottleneck: large draft trees activate many unique experts, significantly increasing memory pressure and diminishing speedups from speculative decoding relative to autoregressive decoding. Prior methods reduce speculation depth when MoE verification becomes expensive. We propose MoE-Spec, a training-free verification-time expert budgeting method that decouples speculation depth from memory cost by enforcing a fixed expert capacity limit at each layer, loading only the experts that contribute most to verification and dropping the long tail of rarely used experts that drive bandwidth overhead. Experiments across multiple model scales and datasets show that this method yields 10--30\% higher throughput than state-of-the-art speculative decoding baselines (EAGLE-3) at comparable quality, with flexibility to trade accuracy for further latency reductions through tighter budgets.
CLAA: Cross-Layer Attention Aggregation for Accelerating LLM Prefill
Feb 17, 2026The prefill stage in long-context LLM inference remains a computational bottleneck. Recent token-ranking heuristics accelerate inference by selectively processing a subset of semantically relevant tokens. However, existing methods suffer from unstable token importance estimation, often varying between layers. Evaluating token-ranking quality independently from heuristic-specific architectures is challenging. To address this, we introduce an Answer-Informed Oracle, which defines ground-truth token importance by measuring attention from generated answers back to the prompt. This oracle reveals that existing heuristics exhibit high variance across layers: rankings can degrade sharply at specific layers, a failure mode invisible to end-to-end benchmarks. The diagnosis suggests a simple fix: aggregate scores across layers rather than relying on any single one. We implement this as Cross-Layer Attention Aggregation (CLAA), which closes the gap to the oracle upper bound and reduces Time-to-First-Token (TTFT) by up to 39\% compared to the Full KV Cache baseline.
PipeSpec: Breaking Stage Dependencies in Hierarchical LLM Decoding
May 02, 2025Speculative decoding accelerates large language model inference by using smaller draft models to generate candidate tokens for parallel verification. However, current approaches are limited by sequential stage dependencies that prevent full hardware utilization. We present PipeSpec, a framework that generalizes speculative decoding to $k$ models arranged in a hierarchical pipeline, enabling asynchronous execution with lightweight coordination for prediction verification and rollback. Our analytical model characterizes token generation rates across pipeline stages and proves guaranteed throughput improvements over traditional decoding for any non-zero acceptance rate. We further derive closed-form expressions for steady-state verification probabilities that explain the empirical benefits of pipeline depth. Experimental results show that PipeSpec achieves up to 2.54$\times$ speedup while outperforming state-of-the-art methods. We validate PipeSpec across text summarization and code generation tasks using LLaMA 2 and 3 models, demonstrating that pipeline efficiency increases with model depth, providing a scalable approach to accelerating LLM inference on multi-device systems.
Speculative Decoding and Beyond: An In-Depth Review of Techniques
Feb 27, 2025Sequential dependencies present a fundamental bottleneck in deploying large-scale autoregressive models, particularly for real-time applications. While traditional optimization approaches like pruning and quantization often compromise model quality, recent advances in generation-refinement frameworks demonstrate that this trade-off can be significantly mitigated. This survey presents a comprehensive taxonomy of generation-refinement frameworks, analyzing methods across autoregressive sequence tasks. We categorize methods based on their generation strategies (from simple n-gram prediction to sophisticated draft models) and refinement mechanisms (including single-pass verification and iterative approaches). Through systematic analysis of both algorithmic innovations and system-level implementations, we examine deployment strategies across computing environments and explore applications spanning text, images, and speech generation. This systematic examination of both theoretical frameworks and practical implementations provides a foundation for future research in efficient autoregressive decoding.
Beyond Trusting Trust: Multi-Model Validation for Robust Code Generation
Feb 22, 2025This paper explores the parallels between Thompson's "Reflections on Trusting Trust" and modern challenges in LLM-based code generation. We examine how Thompson's insights about compiler backdoors take on new relevance in the era of large language models, where the mechanisms for potential exploitation are even more opaque and difficult to analyze. Building on this analogy, we discuss how the statistical nature of LLMs creates novel security challenges in code generation pipelines. As a potential direction forward, we propose an ensemble-based validation approach that leverages multiple independent models to detect anomalous code patterns through cross-model consensus. This perspective piece aims to spark discussion about trust and validation in AI-assisted software development.
AMUSD: Asynchronous Multi-Device Speculative Decoding for LLM Acceleration
Oct 22, 2024



Large language models typically generate tokens autoregressively, using each token as input for the next. Recent work on Speculative Decoding has sought to accelerate this process by employing a smaller, faster draft model to more quickly generate candidate tokens. These candidates are then verified in parallel by the larger (original) verify model, resulting in overall speedup compared to using the larger model by itself in an autoregressive fashion. In this work, we introduce AMUSD (Asynchronous Multi-device Speculative Decoding), a system that further accelerates generation by decoupling the draft and verify phases into a continuous, asynchronous approach. Unlike conventional speculative decoding, where only one model (draft or verify) performs token generation at a time, AMUSD enables both models to perform predictions independently on separate devices (e.g., GPUs). We evaluate our approach over multiple datasets and show that AMUSD achieves an average 29% improvement over speculative decoding and up to 1.96$\times$ speedup over conventional autoregressive decoding, while achieving identical output quality. Our system is open-source and available at https://github.com/BradMcDanel/AMUSD/.
Accelerating Vision Transformer Training via a Patch Sampling Schedule
Aug 19, 2022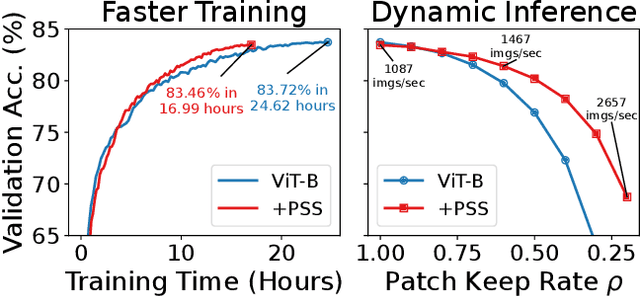
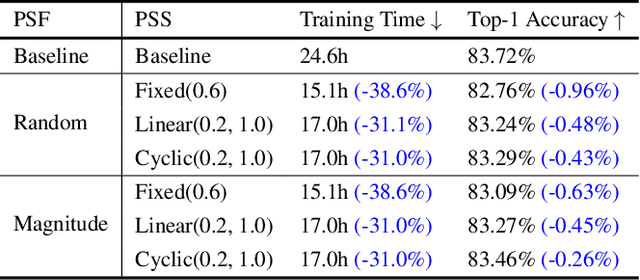
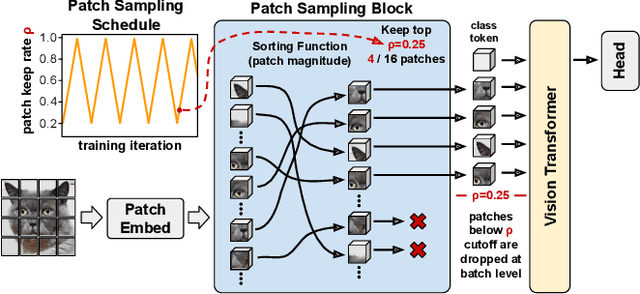
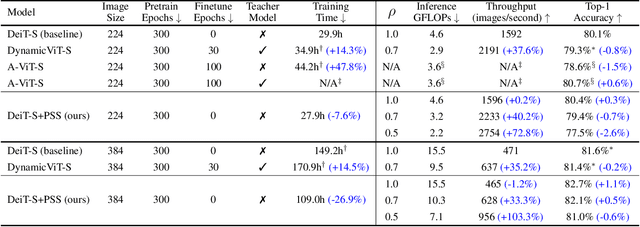
We introduce the notion of a Patch Sampling Schedule (PSS), that varies the number of Vision Transformer (ViT) patches used per batch during training. Since all patches are not equally important for most vision objectives (e.g., classification), we argue that less important patches can be used in fewer training iterations, leading to shorter training time with minimal impact on performance. Additionally, we observe that training with a PSS makes a ViT more robust to a wider patch sampling range during inference. This allows for a fine-grained, dynamic trade-off between throughput and accuracy during inference. We evaluate using PSSs on ViTs for ImageNet both trained from scratch and pre-trained using a reconstruction loss function. For the pre-trained model, we achieve a 0.26% reduction in classification accuracy for a 31% reduction in training time (from 25 to 17 hours) compared to using all patches each iteration. Code, model checkpoints and logs are available at https://github.com/BradMcDanel/pss.
Accelerating DNN Training with Structured Data Gradient Pruning
Feb 01, 2022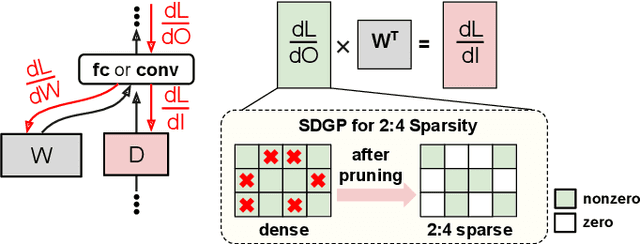
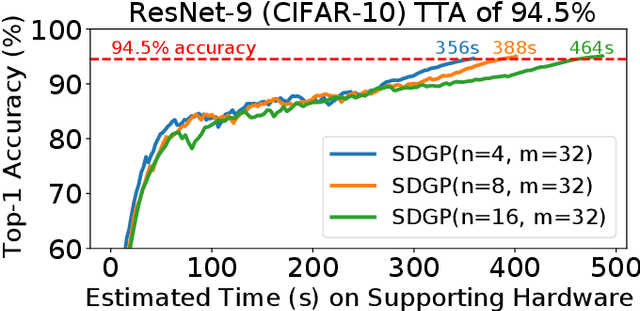
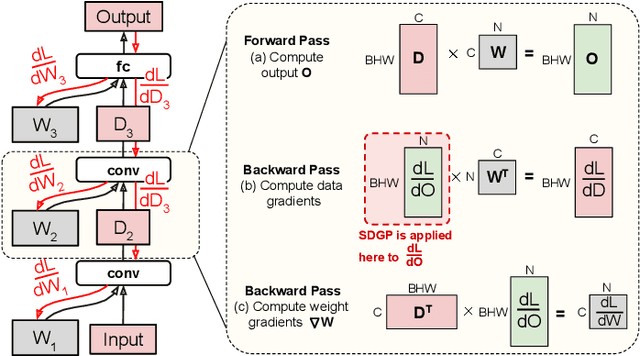
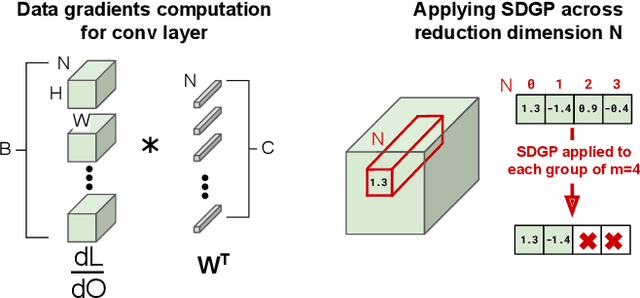
Weight pruning is a technique to make Deep Neural Network (DNN) inference more computationally efficient by reducing the number of model parameters over the course of training. However, most weight pruning techniques generally does not speed up DNN training and can even require more iterations to reach model convergence. In this work, we propose a novel Structured Data Gradient Pruning (SDGP) method that can speed up training without impacting model convergence. This approach enforces a specific sparsity structure, where only N out of every M elements in a matrix can be nonzero, making it amenable to hardware acceleration. Modern accelerators such as the Nvidia A100 GPU support this type of structured sparsity for 2 nonzeros per 4 elements in a reduction. Assuming hardware support for 2:4 sparsity, our approach can achieve a 15-25\% reduction in total training time without significant impact to performance. Source code and pre-trained models are available at \url{https://github.com/BradMcDanel/sdgp}.
FAST: DNN Training Under Variable Precision Block Floating Point with Stochastic Rounding
Oct 28, 2021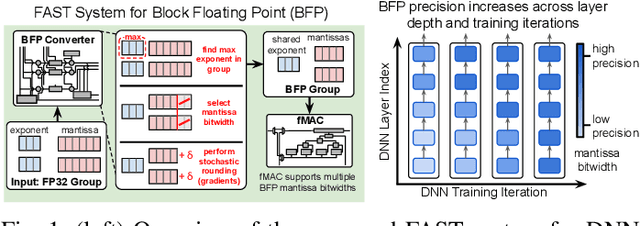
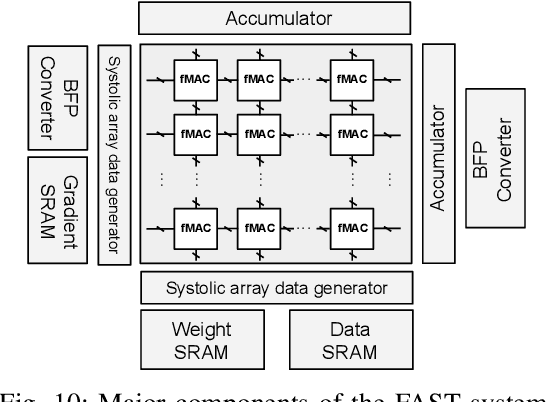
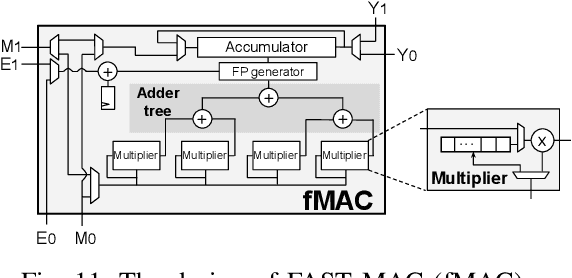
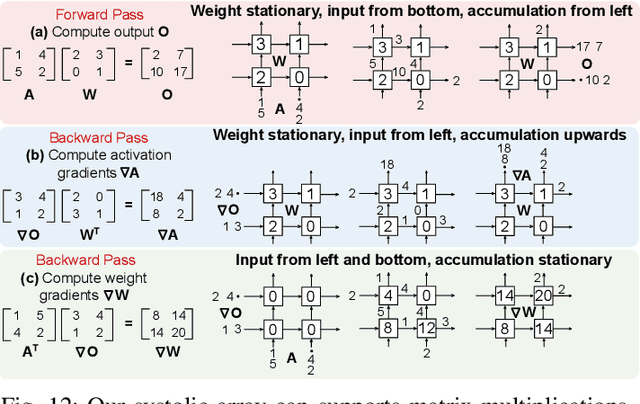
Block Floating Point (BFP) can efficiently support quantization for Deep Neural Network (DNN) training by providing a wide dynamic range via a shared exponent across a group of values. In this paper, we propose a Fast First, Accurate Second Training (FAST) system for DNNs, where the weights, activations, and gradients are represented in BFP. FAST supports matrix multiplication with variable precision BFP input operands, enabling incremental increases in DNN precision throughout training. By increasing the BFP precision across both training iterations and DNN layers, FAST can greatly shorten the training time while reducing overall hardware resource usage. Our FAST Multipler-Accumulator (fMAC) supports dot product computations under multiple BFP precisions. We validate our FAST system on multiple DNNs with different datasets, demonstrating a 2-6$\times$ speedup in training on a single-chip platform over prior work based on \textbf{mixed-precision or block} floating point number systems while achieving similar performance in validation accuracy.
Term Revealing: Furthering Quantization at Run Time on Quantized DNNs
Jul 26, 2020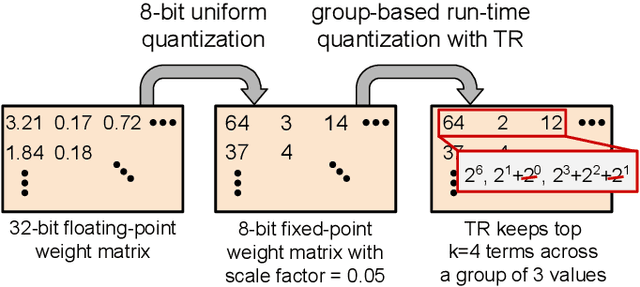
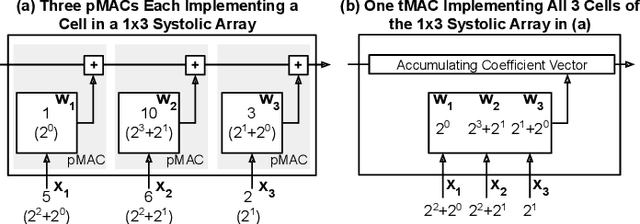
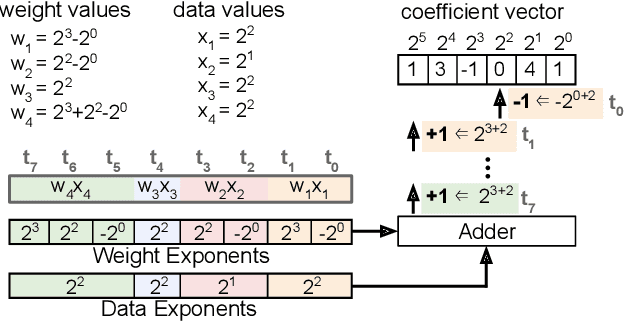
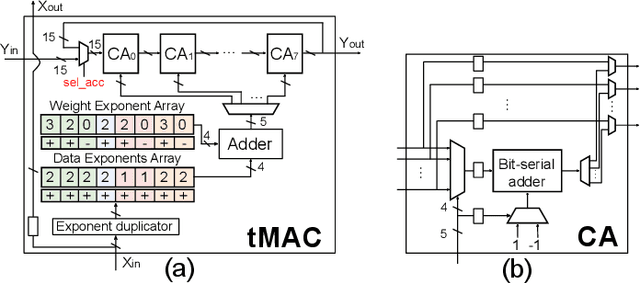
We present a novel technique, called Term Revealing (TR), for furthering quantization at run time for improved performance of Deep Neural Networks (DNNs) already quantized with conventional quantization methods. TR operates on power-of-two terms in binary expressions of values. In computing a dot-product computation, TR dynamically selects a fixed number of largest terms to use from the values of the two vectors in the dot product. By exploiting normal-like weight and data distributions typically present in DNNs, TR has a minimal impact on DNN model performance (i.e., accuracy or perplexity). We use TR to facilitate tightly synchronized processor arrays, such as systolic arrays, for efficient parallel processing. We show an FPGA implementation that can use a small number of control bits to switch between conventional quantization and TR-enabled quantization with a negligible delay. To enhance TR efficiency further, we use a signed digit representation (SDR), as opposed to classic binary encoding with only nonnegative power-of-two terms. To perform conversion from binary to SDR, we develop an efficient encoding method called HESE (Hybrid Encoding for Signed Expressions) that can be performed in one pass looking at only two bits at a time. We evaluate TR with HESE encoded values on an MLP for MNIST, multiple CNNs for ImageNet, and an LSTM for Wikitext-2, and show significant reductions in inference computations (between 3-10x) compared to conventional quantization for the same level of model performance.