 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ambiguous Dynamic Treatment Regimes: A Reinforcement Learning Approach
Dec 08, 2021
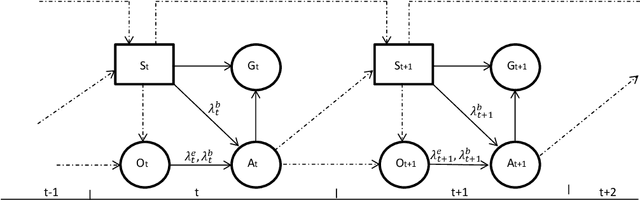
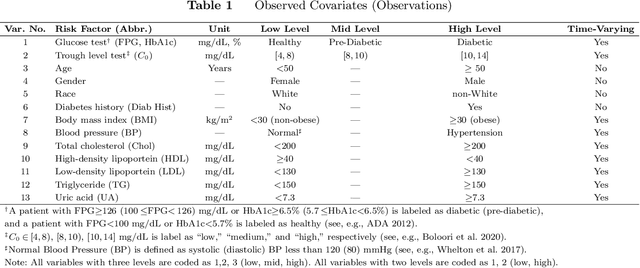
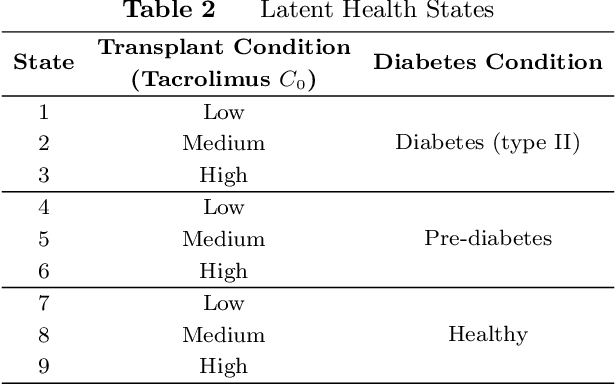
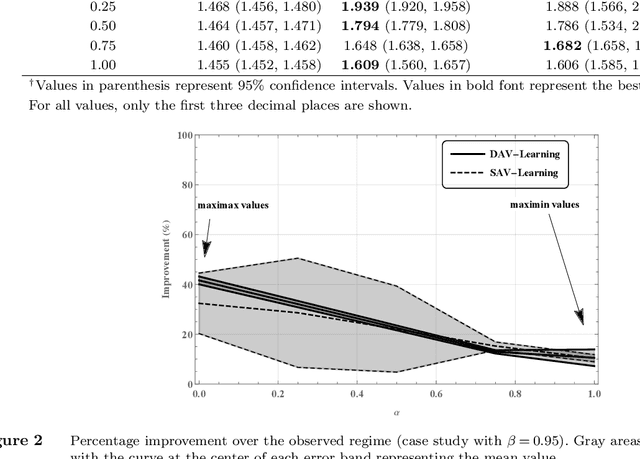
A main research goal in various studies is to use an observational data set and provide a new set of counterfactual guidelines that can yield causal improvements. Dynamic Treatment Regimes (DTRs) are widely studied to formalize this process. However, available methods in finding optimal DTRs often rely on assumptions that are violated in real-world applications (e.g., medical decision-making or public policy), especially when (a) the existence of unobserved confounders cannot be ignored, and (b) the unobserved confounders are time-varying (e.g., affected by previous actions). When such assumptions are violated, one often faces ambiguity regarding the underlying causal model that is needed to be assumed to obtain an optimal DTR. This ambiguity is inevitable, since the dynamics of unobserved confounders and their causal impact on the observed part of the data cannot be understood from the observed data. Motivated by a case study of finding superior treatment regimes for patients who underwent transplantation in our partner hospital and faced a medical condition known as New Onset Diabetes After Transplantation (NODAT), we extend DTRs to a new class termed Ambiguous Dynamic Treatment Regimes (ADTRs), in which the casual impact of treatment regimes is evaluated based on a "cloud" of potential causal models. We then connect ADTRs to Ambiguous Partially Observable Mark Decision Processes (APOMDPs) proposed by Saghafian (2018), and develop two Reinforcement Learning methods termed Direct Augmented V-Learning (DAV-Learning) and Safe Augmented V-Learning (SAV-Learning), which enable using the observed data to efficiently learn an optimal treatment regime. We establish theoretical results for these learning methods, including (weak) consistency and asymptotic normality. We further evaluate the performance of these learning methods both in our case study and in simulation experiments.
L4-Norm Weight Adjustments for Converted Spiking Neural Networks
Nov 17, 2021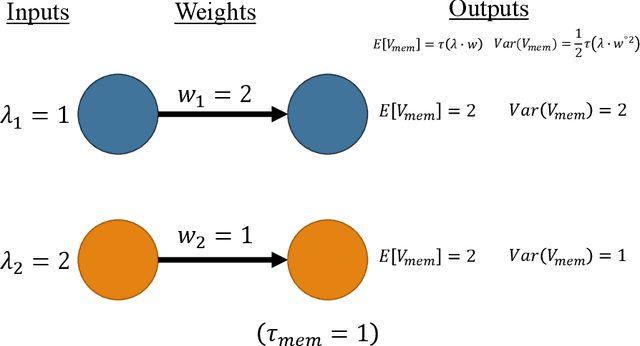
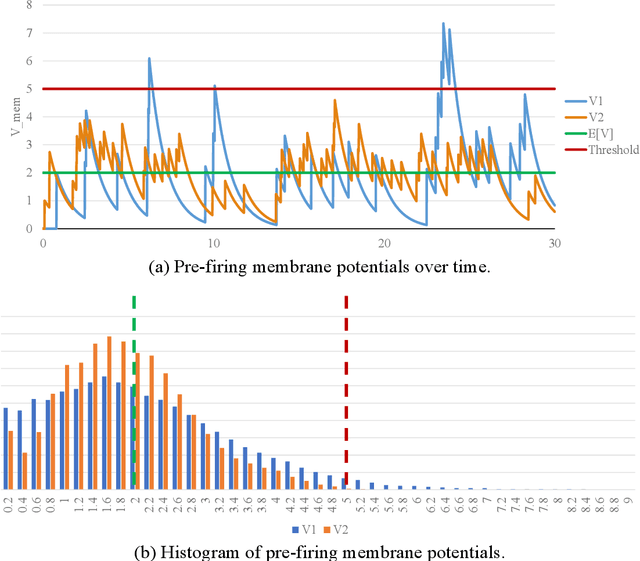

Spiking Neural Networks (SNNs) are being explored for their potential energy efficiency benefits due to sparse, event-driven computation. Non-spiking artificial neural networks are typically trained with stochastic gradient descent using backpropagation. The calculation of true gradients for backpropagation in spiking neural networks is impeded by the non-differentiable firing events of spiking neurons. On the other hand, using approximate gradients is effective, but computationally expensive over many time steps. One common technique, then, for training a spiking neural network is to train a topologically-equivalent non-spiking network, and then convert it to an spiking network, replacing real-valued inputs with proportionally rate-encoded Poisson spike trains. Converted SNNs function sufficiently well because the mean pre-firing membrane potential of a spiking neuron is proportional to the dot product of the input rate vector and the neuron weight vector, similar to the functionality of a non-spiking network. However, this conversion only considers the mean and not the temporal variance of the membrane potential. As the standard deviation of the pre-firing membrane potential is proportional to the L4-norm of the neuron weight vector, we propose a weight adjustment based on the L4-norm during the conversion process in order to improve classification accuracy of the converted network.
LLOL: Low-Latency Odometry for Spinning Lidars
Oct 04, 2021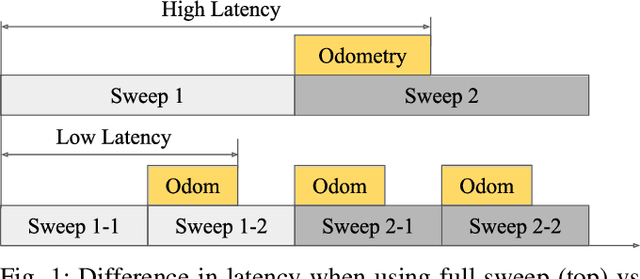


In this paper, we present a low-latency odometry system designed for spinning lidars. Many existing lidar odometry methods wait for an entire sweep from the lidar before processing the data. This introduces a large delay between the first laser firing and its pose estimate. To reduce this latency, we treat the spinning lidar as a streaming sensor and process packets as they arrive. This effectively distributes expensive operations across time, resulting in a very fast and lightweight system with much higher throughput and lower latency. Our open-source implementation is available at \url{https://github.com/versatran01/llol}.
Small or Far Away? Exploiting Deep Super-Resolution and Altitude Data for Aerial Animal Surveillance
Nov 12, 2021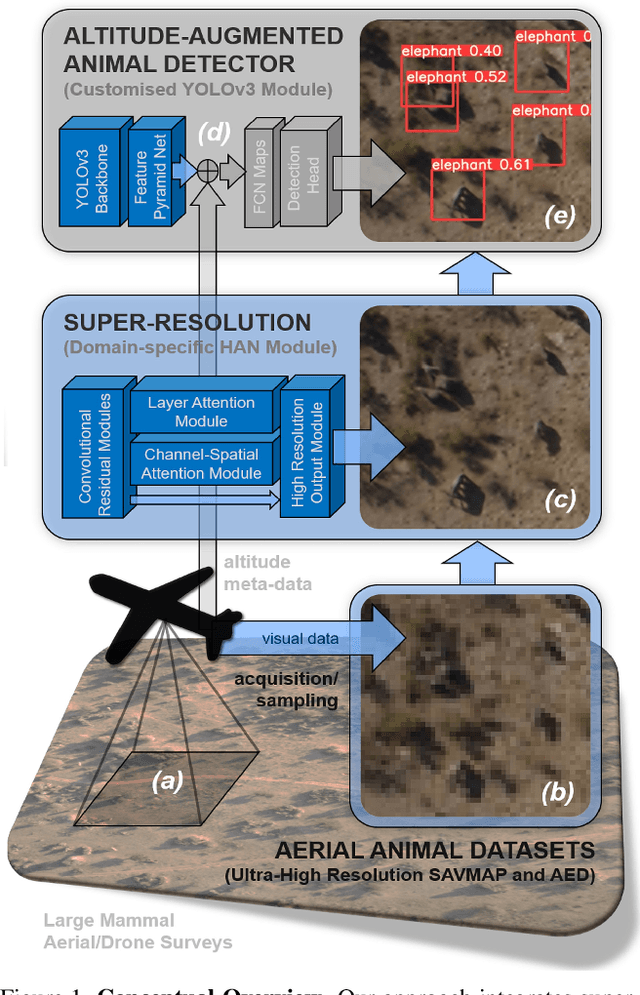
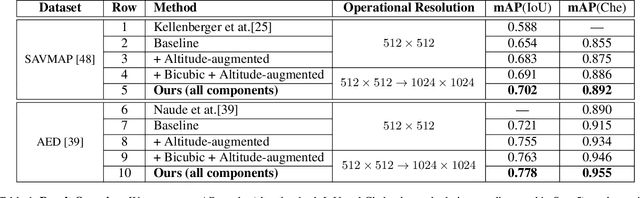

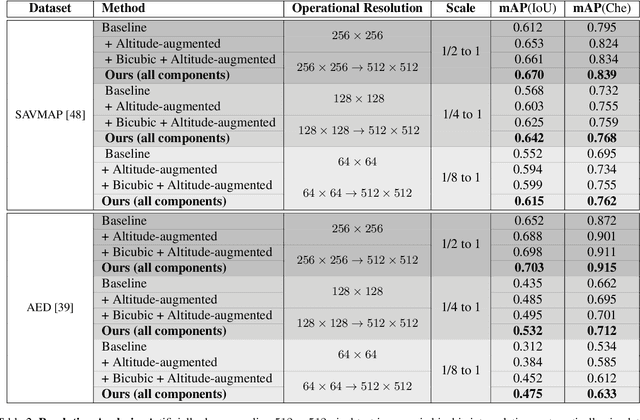
Visuals captured by high-flying aerial drones are increasingly used to assess biodiversity and animal population dynamics around the globe. Yet, challenging acquisition scenarios and tiny animal depictions in airborne imagery, despite ultra-high resolution cameras, have so far been limiting factors for applying computer vision detectors successfully with high confidence. In this paper, we address the problem for the first time by combining deep object detectors with super-resolution techniques and altitude data. In particular, we show that the integration of a holistic attention network based super-resolution approach and a custom-built altitude data exploitation network into standard recognition pipelines can considerably increase the detection efficacy in real-world settings. We evaluate the system on two public, large aerial-capture animal datasets, SAVMAP and AED. We find that the proposed approach can consistently improve over ablated baselines and the state-of-the-art performance for both datasets. In addition, we provide a systematic analysis of the relationship between animal resolution and detection performance. We conclude that super-resolution and altitude knowledge exploitation techniques can significantly increase benchmarks across settings and, thus, should be used routinely when detecting minutely resolved animals in aerial imagery.
Towards Scalable Continuous-Time Trajectory Optimization for Multi-Robot Navigation
Oct 29, 2019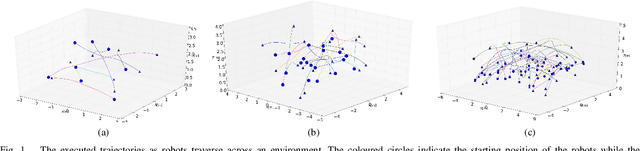
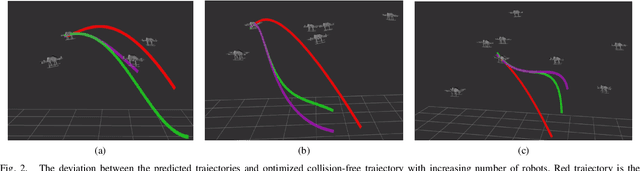
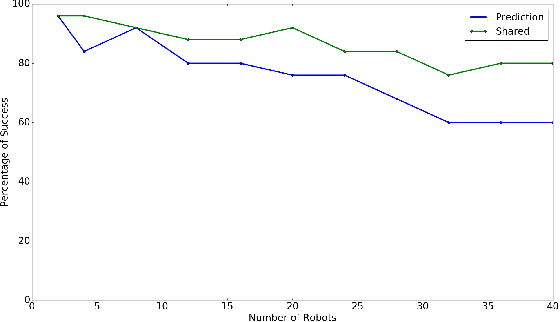
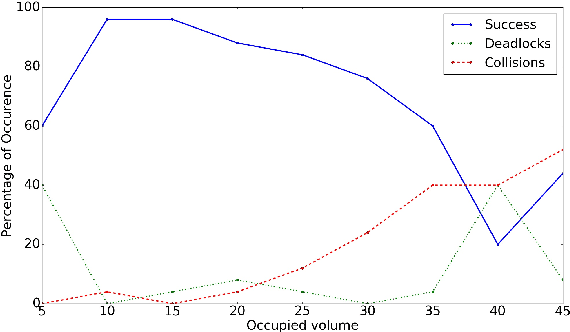
Scalable multi-robot transition is essential for ubiquitous adoption of robots. As a step towards it, a computationally efficient decentralized algorithm for continuous-time trajectory optimization in multi-robot scenarios based upon model predictive control is introduced. The robots communicate only their current states and goals rather than sharing their whole trajectory; using this data each robot predicts a continuous-time trajectory for every other robot exploiting optimal control based motion primitives that are corrected for spatial inter-robot interactions using least squares. A non linear program (NLP) is formulated for collision avoidance with the predicted trajectories of other robots. The NLP is condensed by using time as a parametrization resulting in an unconstrained optimization problem and can be solved in a fast and efficient manner. Additionally, the algorithm resizes the robot to accommodate it's trajectory tracking error. The algorithm was tested in simulations on Gazebo with aerial robots. Early results indicate that the proposed algorithm is efficient for upto forty homogeneous robots and twenty one heterogeneous robots occupying 20\% of the available space.
Neural networks based post-equalization in coherent optical systems: regression versus classification
Oct 17, 2021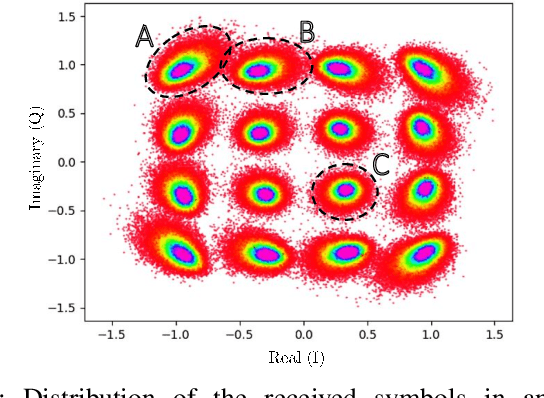
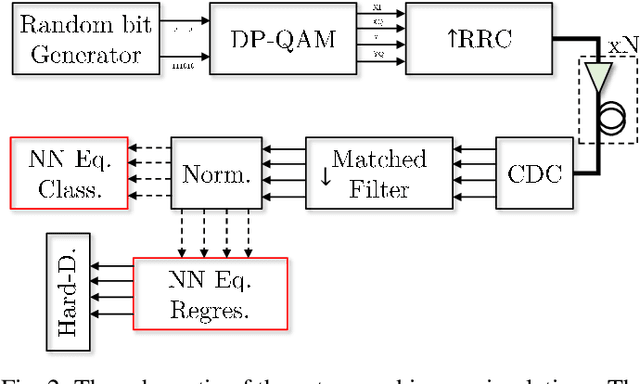
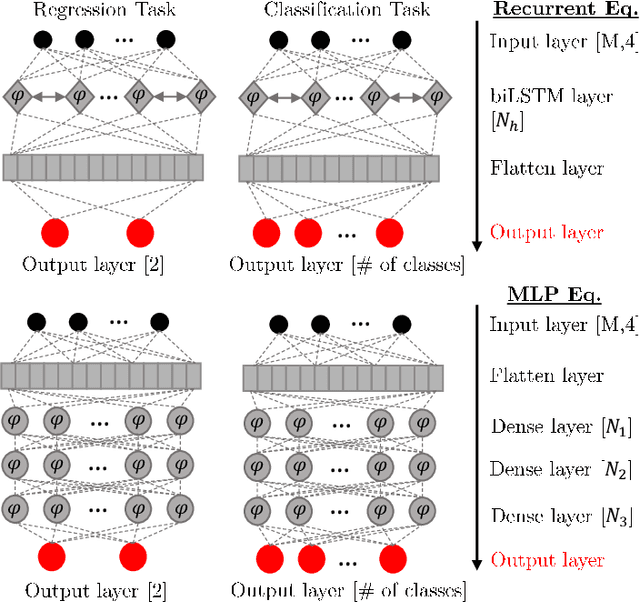
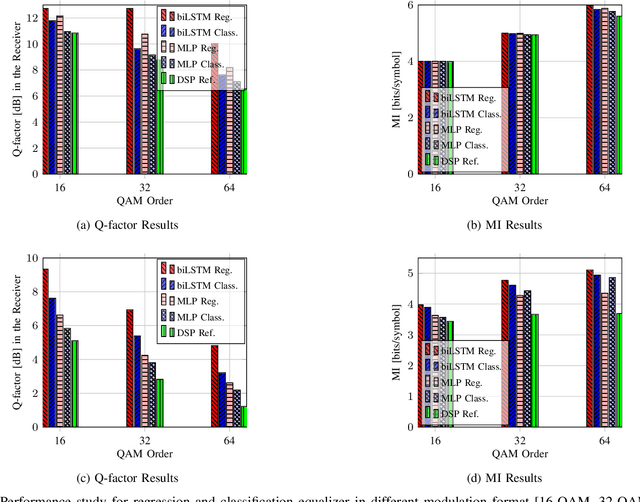
In this paper, we address the question of which type of predictive modeling, classification, or regression, fits better the task of equalization using neural networks (NN) based post-processing in coherent optical communication, where the transmission channel is nonlinear and dispersive. For the first time, we presented some possible drawbacks in using each type of predictive task in a machine learning context for the nonlinear channel equalization problem. We studied two types of equalizers based on the feed-forward and recurrent neural networks over several different transmission scenarios, in linear and nonlinear regimes of the optical channel. We observed in all those cases that the training based on regression results in faster convergence and finally a superior performance, in terms of Q-factor and achievable information rate.
Temporally Consistent Online Depth Estimation in Dynamic Scenes
Nov 17, 2021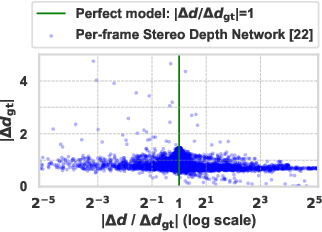
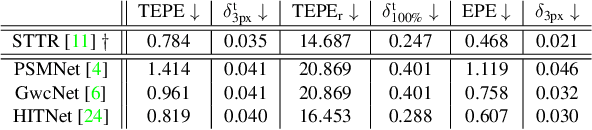
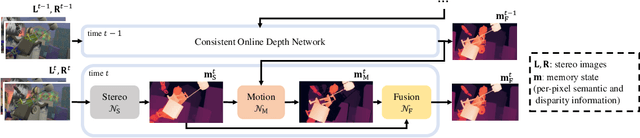
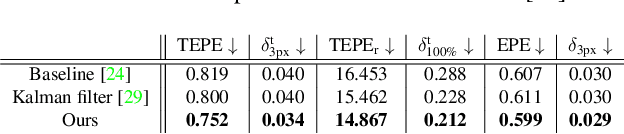
Temporally consistent depth estimation is crucial for real-time applications such as augmented reality. While stereo depth estimation has received substantial attention that led to improvements on a frame-by-frame basis, there is relatively little work focused on maintaining temporal consistency across frames. Indeed, based on our analysis, current stereo depth estimation techniques still suffer from poor temporal consistency. Stabilizing depth temporally in dynamic scenes is challenging due to concurrent object and camera motion. In an online setting, this process is further aggravated because only past frames are available. In this paper, we present a technique to produce temporally consistent depth estimates in dynamic scenes in an online setting. Our network augments current per-frame stereo networks with novel motion and fusion networks. The motion network accounts for both object and camera motion by predicting a per-pixel SE3 transformation. The fusion network improves consistency in prediction by aggregating the current and previous predictions with regressed weights. We conduct extensive experiments across varied datasets (synthetic, outdoor, indoor and medical). In both zero-shot generalization and domain fine-tuning, we demonstrate that our proposed approach outperforms competing methods in terms of temporal stability and per-frame accuracy, both quantitatively and qualitatively. Our code will be available online.
Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction
Nov 22, 2021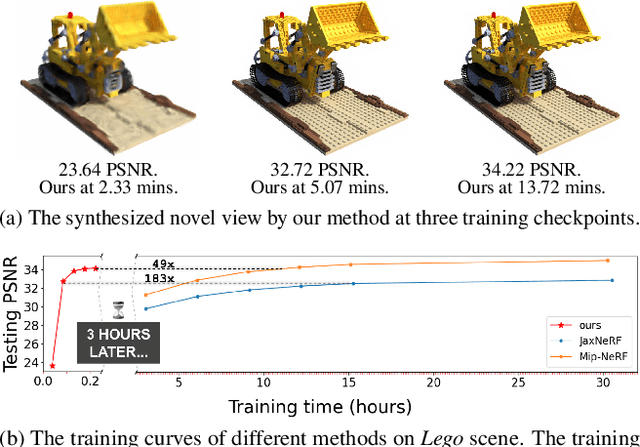
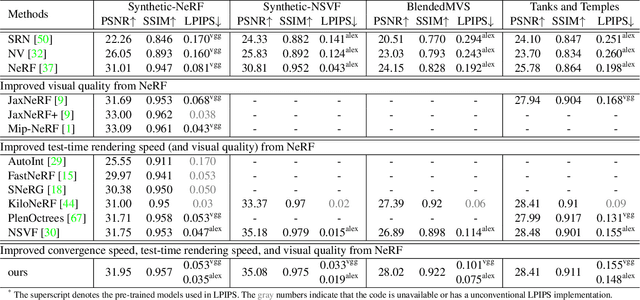
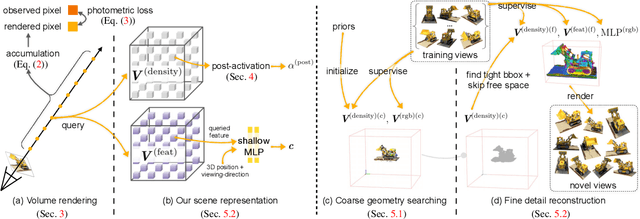
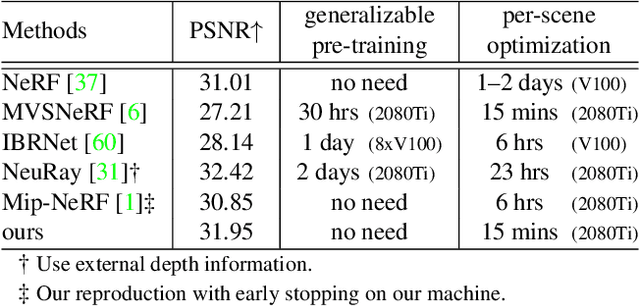
We present a super-fast convergence approach to reconstructing the per-scene radiance field from a set of images that capture the scene with known poses. This task, which is often applied to novel view synthesis, is recently revolutionized by Neural Radiance Field (NeRF) for its state-of-the-art quality and flexibility. However, NeRF and its variants require a lengthy training time ranging from hours to days for a single scene. In contrast, our approach achieves NeRF-comparable quality and converges rapidly from scratch in less than 15 minutes with a single GPU. We adopt a representation consisting of a density voxel grid for scene geometry and a feature voxel grid with a shallow network for complex view-dependent appearance. Modeling with explicit and discretized volume representations is not new, but we propose two simple yet non-trivial techniques that contribute to fast convergence speed and high-quality output. First, we introduce the post-activation interpolation on voxel density, which is capable of producing sharp surfaces in lower grid resolution. Second, direct voxel density optimization is prone to suboptimal geometry solutions, so we robustify the optimization process by imposing several priors. Finally, evaluation on five inward-facing benchmarks shows that our method matches, if not surpasses, NeRF's quality, yet it only takes about 15 minutes to train from scratch for a new scene.
Throughput maximization of an IRS-assisted wireless powered network with interference: A deep unsupervised learning approach
Aug 05, 2021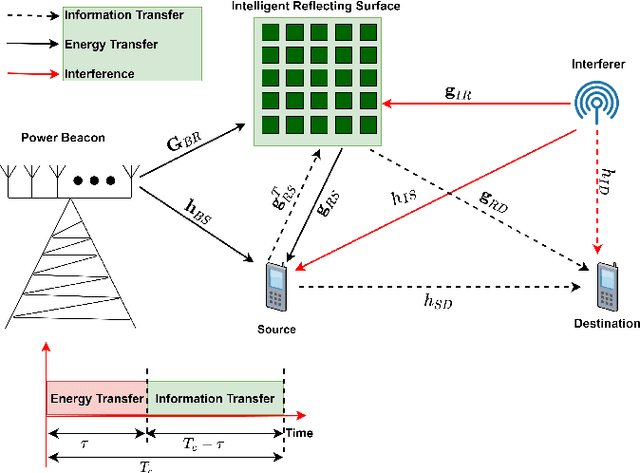
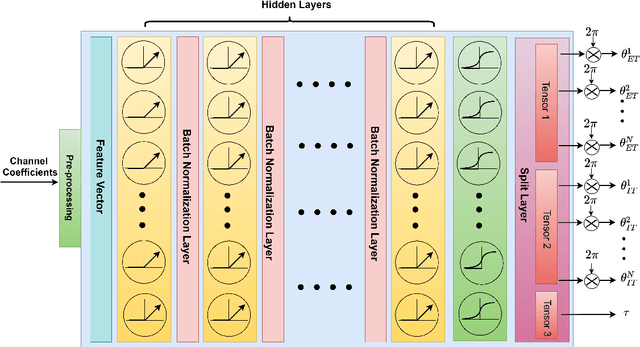
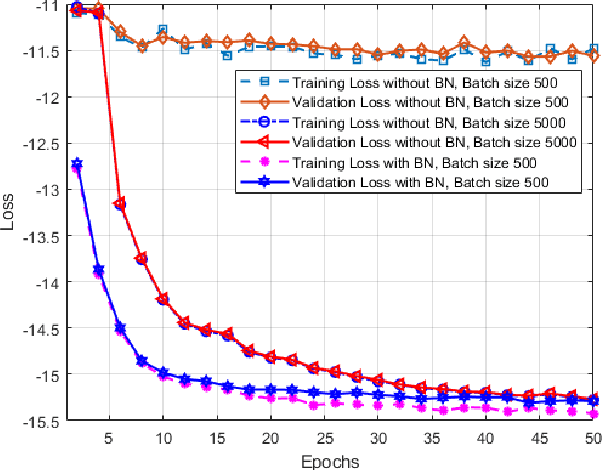
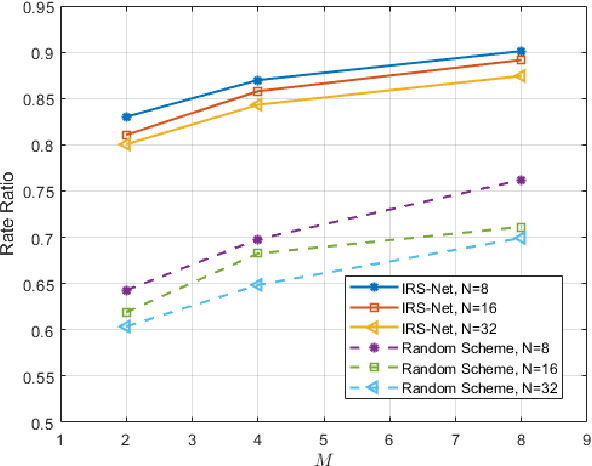
In this paper, we consider an intelligent reflecting surface (IRS)-assisted wireless powered communication network (WPCN) in which a multi antenna power beacon (PB) sends a dedicated energy signal to a wireless powered source. The source first harvests energy and then utilizing this harvested energy, it sends an information signal to destination where an external interference is also present. More specifically, we formulated an analytical problem in which objective is to maximize the throughput by jointly optimizing the energy harvesting (EH) time and IRS phase-shift matrices corresponding to both energy transfer and information transfer phases. The formulated optimization problem is high dimensional non-convex, thus a good quality solution can be obtained by invoking any evolutionary algorithm such as Genetic algorithm (GA). It is well-known that the performance of GA is generally remarkable, however it incurs a high computational complexity. Thus, GA is unable to solve the considered optimization problem within channel coherence time, which limits its practical use. To this end, we propose a deep unsupervised learning (DUL) based approach in which a neural network (NN) is trained very efficiently as time-consuming task of labeling a data set is not required. Numerical examples show that the proposed approach significantly reduces time complexity making it feasible for practical use with a small loss in achievable throughput as compared to the GA. Nevertheless, it is also shown through numerical results that this small loss in throughput can be reduced further either by increasing the number of antennas at the PB and/or decreasing the number of reflecting elements of the IRS.
LayerPipe: Accelerating Deep Neural Network Training by Intra-Layer and Inter-Layer Gradient Pipelining and Multiprocessor Scheduling
Aug 14, 2021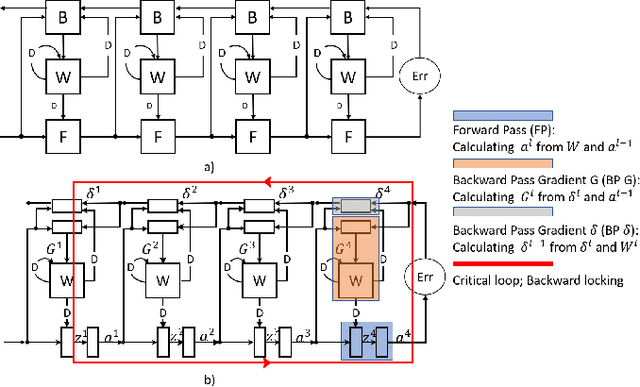
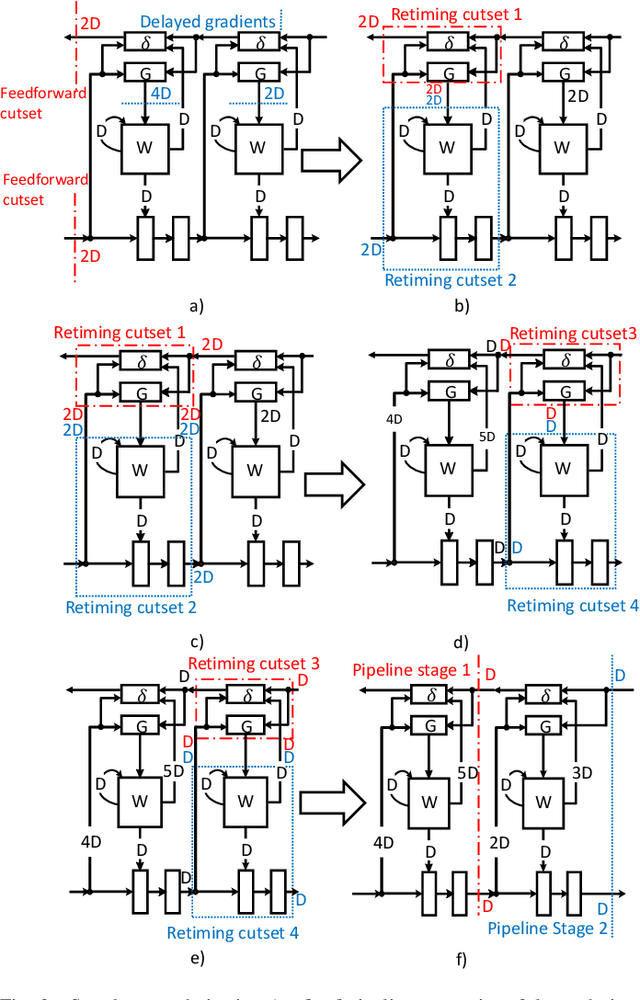
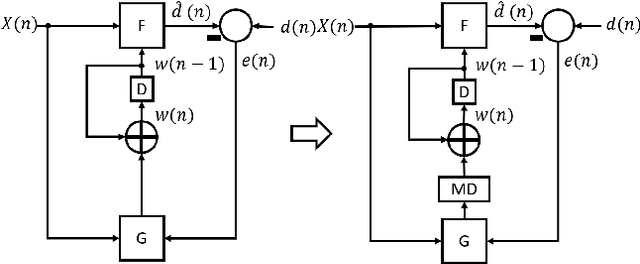
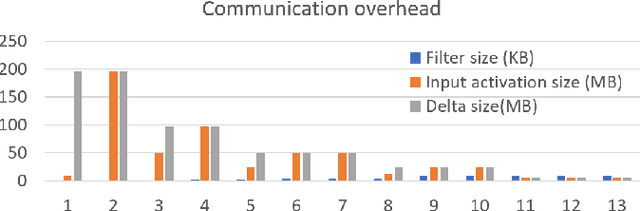
The time required for training the neural networks increases with size, complexity, and depth. Training model parameters by backpropagation inherently creates feedback loops. These loops hinder efficient pipelining and scheduling of the tasks within the layer and between consecutive layers. Prior approaches, such as PipeDream, have exploited the use of delayed gradient to achieve inter-layer pipelining. However, these approaches treat the entire backpropagation as a single task; this leads to an increase in computation time and processor underutilization. This paper presents novel optimization approaches where the gradient computations with respect to the weights and the activation functions are considered independently; therefore, these can be computed in parallel. This is referred to as intra-layer optimization. Additionally, the gradient computation with respect to the activation function is further divided into two parts and distributed to two consecutive layers. This leads to balanced scheduling where the computation time of each layer is the same. This is referred to as inter-layer optimization. The proposed system, referred to as LayerPipe, reduces the number of clock cycles required for training while maximizing processor utilization with minimal inter-processor communication overhead. LayerPipe achieves an average speedup of 25% and upwards of 80% with 7 to 9 processors with less communication overhead when compared to PipeDream.