 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Financial Time Series Data Processing for Machine Learning
Jul 03, 2019
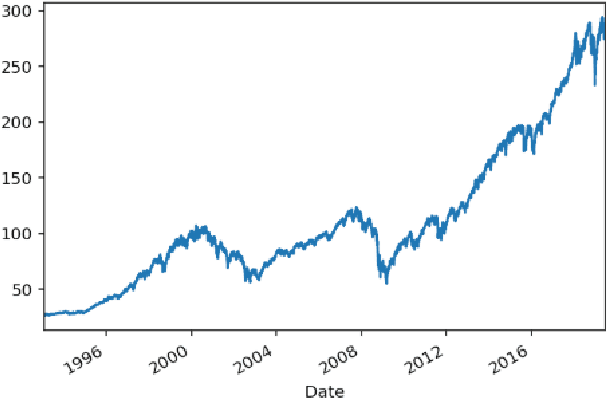

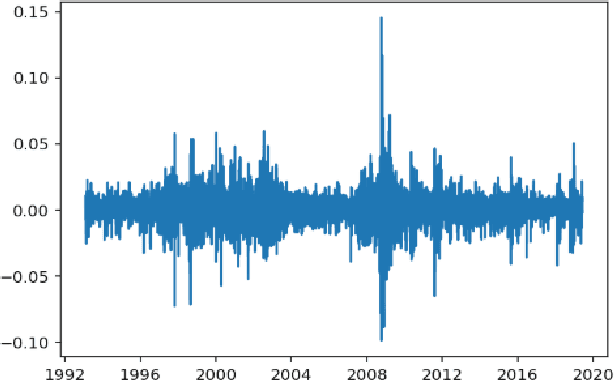

This article studies the financial time series data processing for machine learning. It introduces the most frequent scaling methods, then compares the resulting stationarity and preservation of useful information for trend forecasting. It proposes an empirical test based on the capability to learn simple data relationship with simple models. It also speaks about the data split method specific to time series, avoiding unwanted overfitting and proposes various labelling for classification and regression.
Towards an Efficient Semantic Segmentation Method of ID Cards for Verification Systems
Nov 24, 2021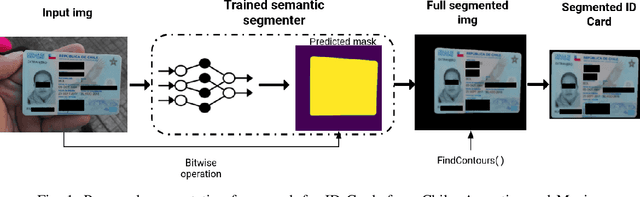

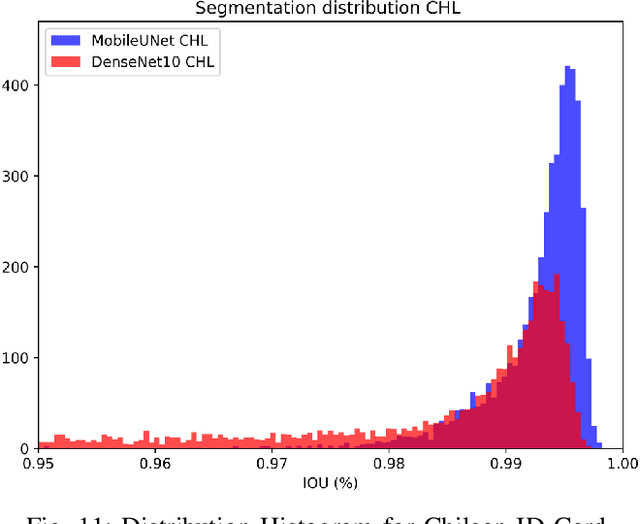
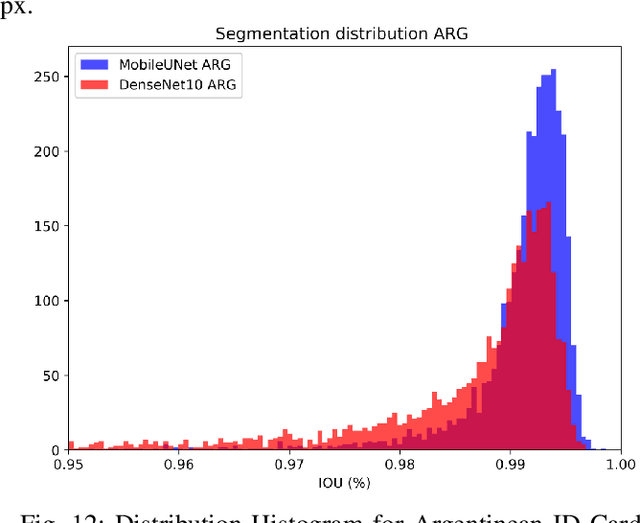
Removing the background in ID Card images is a real challenge for remote verification systems because many of the re-digitalised images present cluttered backgrounds, poor illumination conditions, distortion and occlusions. The background in ID Card images confuses the classifiers and the text extraction. Due to the lack of available images for research, this field represents an open problem in computer vision today. This work proposes a method for removing the background using semantic segmentation of ID Cards. In the end, images captured in the wild from the real operation, using a manually labelled dataset consisting of 45,007 images, with five types of ID Cards from three countries (Chile, Argentina and Mexico), including typical presentation attack scenarios, were used. This method can help to improve the following stages in a regular identity verification or document tampering detection system. Two Deep Learning approaches were explored, based on MobileUNet and DenseNet10. The best results were obtained using MobileUNet, with 6.5 million parameters. A Chilean ID Card's mean Intersection Over Union (IoU) was 0.9926 on a private test dataset of 4,988 images. The best results for the fused multi-country dataset of ID Card images from Chile, Argentina and Mexico reached an IoU of 0.9911. The proposed methods are lightweight enough to be used in real-time operation on mobile devices.
Chatter Detection in Turning Using Machine Learning and Similarity Measures of Time Series via Dynamic Time Warping
Aug 05, 2019
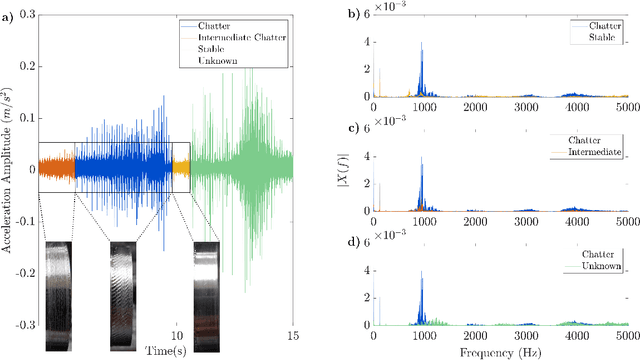
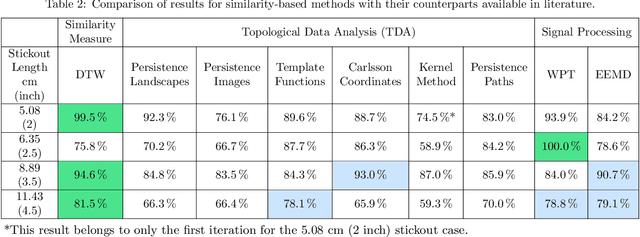
Chatter detection from sensor signals has been an active field of research. While some success has been reported using several featurization tools and machine learning algorithms, existing methods have several drawbacks such as manual preprocessing and requiring a large data set. In this paper, we present an alternative approach for chatter detection based on K-Nearest Neighbor (kNN) algorithm for classification and the Dynamic Time Warping (DTW) as a time series similarity measure. The used time series are the acceleration signals acquired from the tool holder in a series of turning experiments. Our results, show that this approach achieves detection accuracies that in most cases outperform existing methods. We compare our results to the traditional methods based on Wavelet Packet Transform (WPT) and the Ensemble Empirical Mode Decomposition (EEMD), as well as to the more recent Topological Data Analysis (TDA) based approach. We show that in three out of four cutting configurations our DTW-based approach attains the highest average classification rate reaching in one case as high as 99% accuracy. Our approach does not require feature extraction, is capable of reusing a classifier across different cutting configurations, and it uses reasonably sized training sets. Although the resulting high accuracy in our approach is associated with high computational cost, this is specific to the DTW implementation that we used. Specifically, we highlight available, very fast DTW implementations that can even be implemented on small consumer electronics. Therefore, further code optimization and the significantly reduced computational effort during the implementation phase make our approach a viable option for in-process chatter detection.
A Survey: Deep Learning for Hyperspectral Image Classification with Few Labeled Samples
Dec 03, 2021

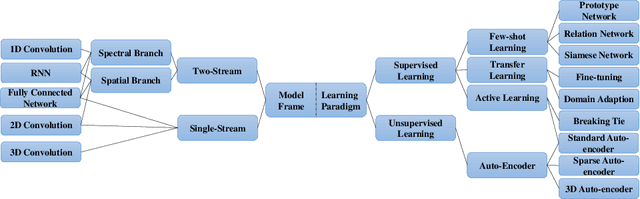
With the rapid development of deep learning technology and improvement in computing capability, deep learning has been widely used in the field of hyperspectral image (HSI) classification. In general, deep learning models often contain many trainable parameters and require a massive number of labeled samples to achieve optimal performance. However, in regard to HSI classification, a large number of labeled samples is generally difficult to acquire due to the difficulty and time-consuming nature of manual labeling. Therefore, many research works focus on building a deep learning model for HSI classification with few labeled samples. In this article, we concentrate on this topic and provide a systematic review of the relevant literature. Specifically, the contributions of this paper are twofold. First, the research progress of related methods is categorized according to the learning paradigm, including transfer learning, active learning and few-shot learning. Second, a number of experiments with various state-of-the-art approaches has been carried out, and the results are summarized to reveal the potential research directions. More importantly, it is notable that although there is a vast gap between deep learning models (that usually need sufficient labeled samples) and the HSI scenario with few labeled samples, the issues of small-sample sets can be well characterized by fusion of deep learning methods and related techniques, such as transfer learning and a lightweight model. For reproducibility, the source codes of the methods assessed in the paper can be found at https://github.com/ShuGuoJ/HSI-Classification.git.
Reinforcement learning for bandwidth estimation and congestion control in real-time communications
Dec 04, 2019

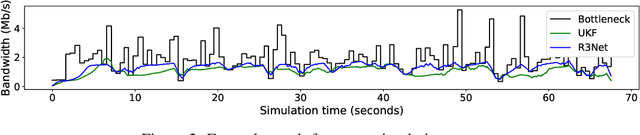
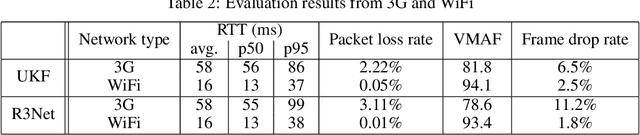
Bandwidth estimation and congestion control for real-time communications (i.e., audio and video conferencing) remains a difficult problem, despite many years of research. Achieving high quality of experience (QoE) for end users requires continual updates due to changing network architectures and technologies. In this paper, we apply reinforcement learning for the first time to the problem of real-time communications (RTC), where we seek to optimize user-perceived quality. We present initial proof-of-concept results, where we learn an agent to control sending rate in an RTC system, evaluating using both network simulation and real Internet video calls. We discuss the challenges we observed, particularly in designing realistic reward functions that reflect QoE, and in bridging the gap between the training environment and real-world networks.
TinyDefectNet: Highly Compact Deep Neural Network Architecture for High-Throughput Manufacturing Visual Quality Inspection
Nov 29, 2021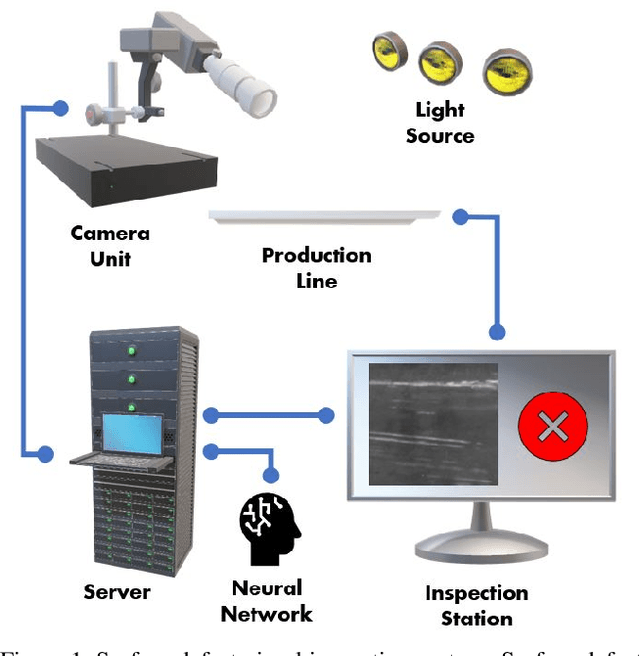
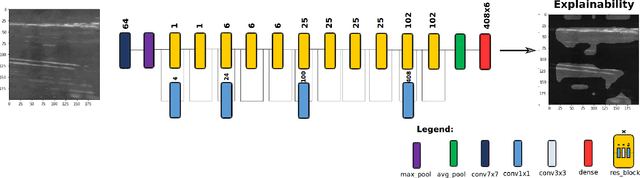

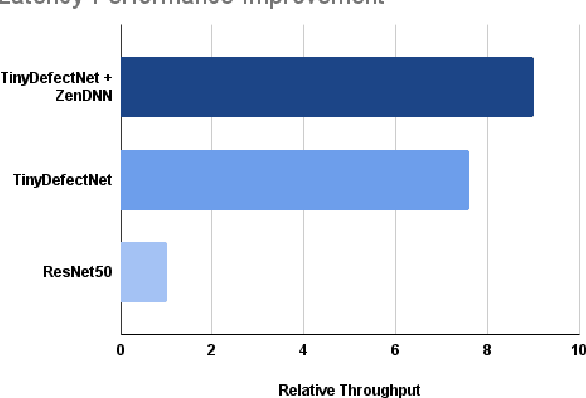
A critical aspect in the manufacturing process is the visual quality inspection of manufactured components for defects and flaws. Human-only visual inspection can be very time-consuming and laborious, and is a significant bottleneck especially for high-throughput manufacturing scenarios. Given significant advances in the field of deep learning, automated visual quality inspection can lead to highly efficient and reliable detection of defects and flaws during the manufacturing process. However, deep learning-driven visual inspection methods often necessitate significant computational resources, thus limiting throughput and act as a bottleneck to widespread adoption for enabling smart factories. In this study, we investigated the utilization of a machine-driven design exploration approach to create TinyDefectNet, a highly compact deep convolutional network architecture tailored for high-throughput manufacturing visual quality inspection. TinyDefectNet comprises of just ~427K parameters and has a computational complexity of ~97M FLOPs, yet achieving a detection accuracy of a state-of-the-art architecture for the task of surface defect detection on the NEU defect benchmark dataset. As such, TinyDefectNet can achieve the same level of detection performance at 52$\times$ lower architectural complexity and 11x lower computational complexity. Furthermore, TinyDefectNet was deployed on an AMD EPYC 7R32, and achieved 7.6x faster throughput using the native Tensorflow environment and 9x faster throughput using AMD ZenDNN accelerator library. Finally, explainability-driven performance validation strategy was conducted to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its usage by operators and inspectors.
Emulating Spatio-Temporal Realizations of Three-Dimensional Isotropic Turbulence via Deep Sequence Learning Models
Dec 07, 2021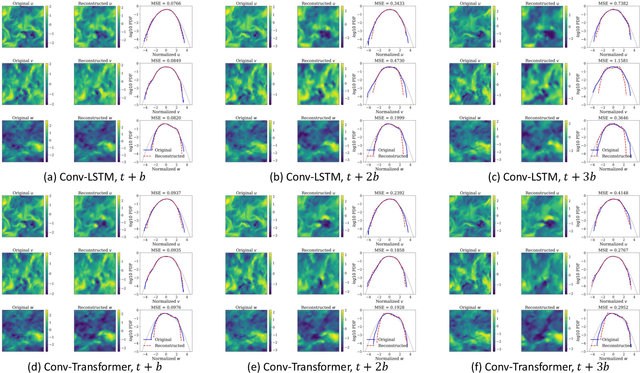
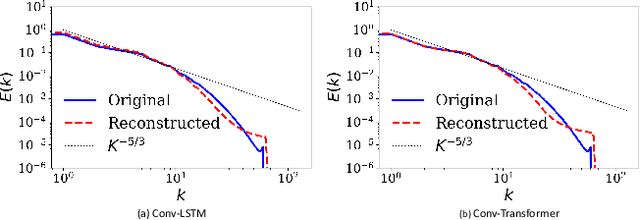
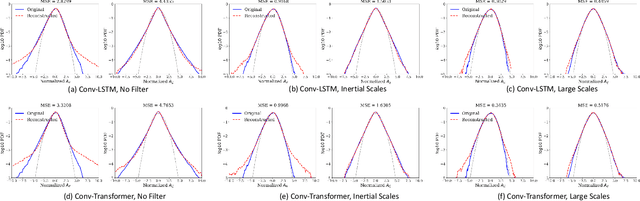
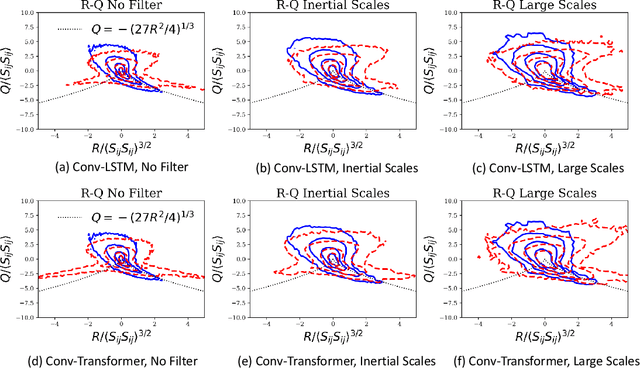
We use a data-driven approach to model a three-dimensional turbulent flow using cutting-edge Deep Learning techniques. The deep learning framework incorporates physical constraints on the flow, such as preserving incompressibility and global statistical invariants of velocity gradient tensor. The accuracy of the model is assessed using statistical and physics-based metrics. The data set comes from Direct Numerical Simulation of an incompressible, statistically stationary, isotropic turbulent flow in a cubic box. Since the size of the dataset is memory intensive, we first generate a low-dimensional representation of the velocity data, and then pass it to a sequence prediction network that learns the spatial and temporal correlations of the underlying data. The dimensionality reduction is performed via extraction using Vector-Quantized Autoencoder (VQ-AE), which learns the discrete latent variables. For the sequence forecasting, the idea of Transformer architecture from natural language processing is used, and its performance compared against more standard Recurrent Networks (such as Convolutional LSTM). These architectures are designed and trained to perform a sequence to sequence multi-class classification task in which they take an input sequence with a fixed length (k) and predict a sequence with a fixed length (p), representing the future time instants of the flow. Our results for the short-term predictions show that the accuracy of results for both models deteriorates across predicted snapshots due to autoregressive nature of the predictions. Based on our diagnostics tests, the trained Conv-Transformer model outperforms the Conv-LSTM one and can accurately, both quantitatively and qualitatively, retain the large scales and capture well the inertial scales of flow but fails at recovering the small and intermittent fluid motions.
Time-varying Autoregression with Low Rank Tensors
May 21, 2019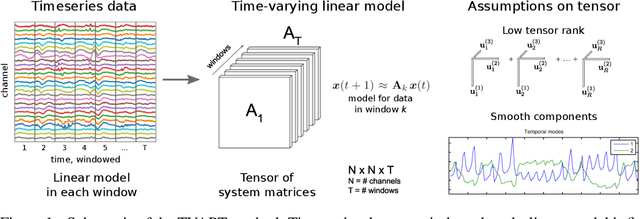
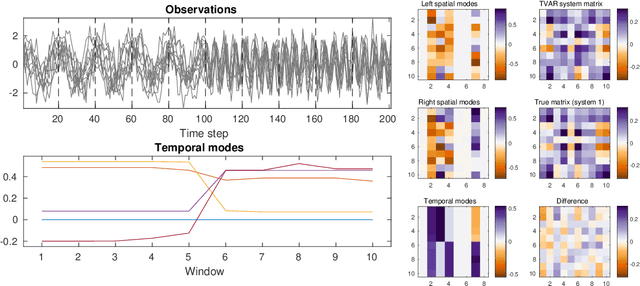
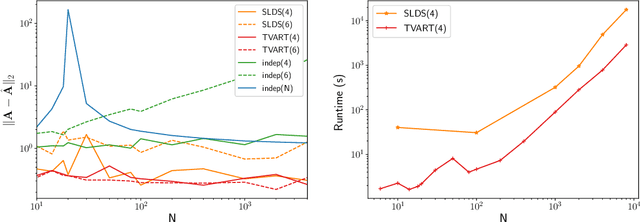
We present a windowed technique to learn parsimonious time-varying autoregressive models from multivariate timeseries. This unsupervised method uncovers spatiotemporal structure in data via non-smooth and non-convex optimization. In each time window, we assume the data follow a linear model parameterized by a potentially different system matrix, and we model this stack of system matrices as a low rank tensor. Because of its structure, the model is scalable to high-dimensional data and can easily incorporate priors such as smoothness over time. We find the components of the tensor using alternating minimization and prove that any stationary point of this algorithm is a local minimum. In a test case, our method identifies the true rank of a switching linear system in the presence of noise. We illustrate our model's utility and superior scalability over extant methods when applied to several synthetic and real examples, including a nonlinear dynamical system, worm behavior, sea surface temperature, and monkey brain recordings.
SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021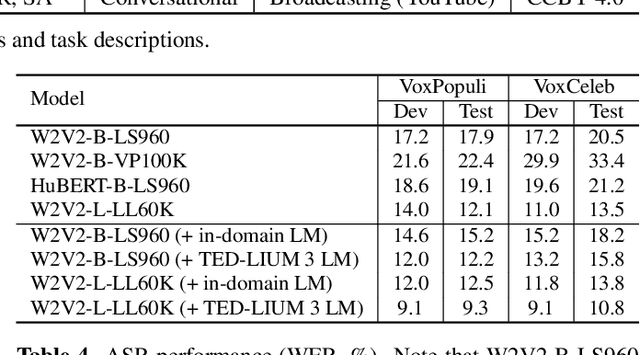
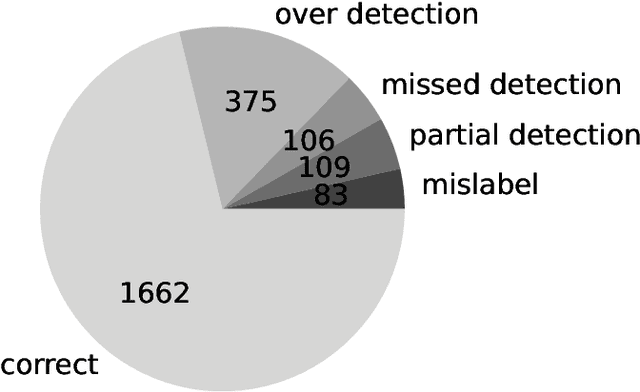
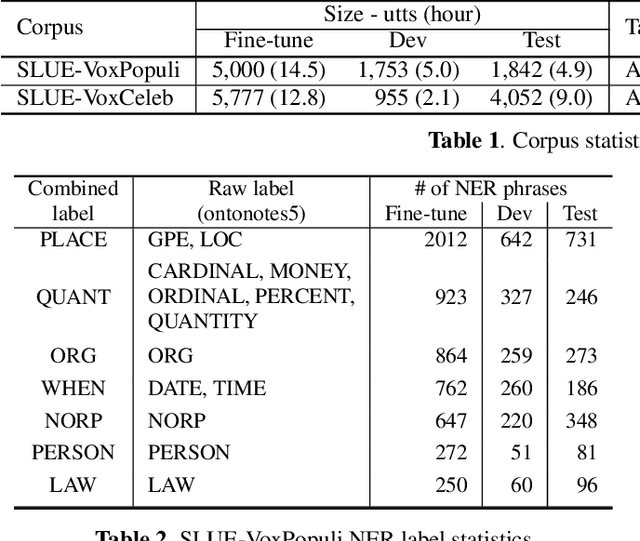
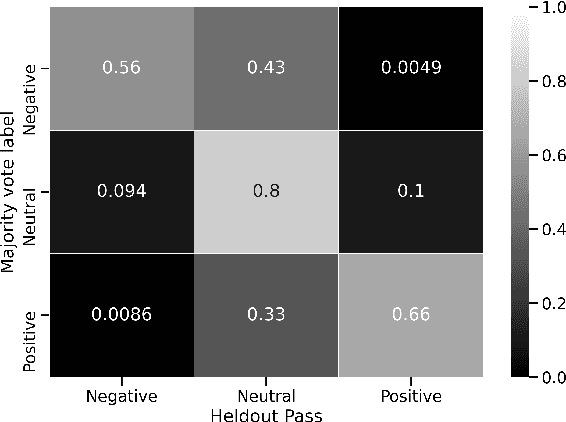
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
Indexing Context-Sensitive Reachability
Sep 03, 2021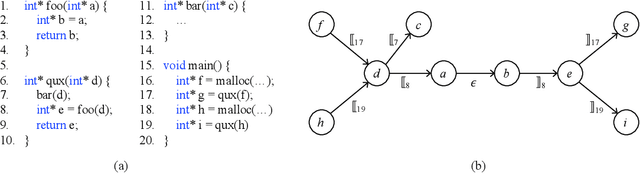
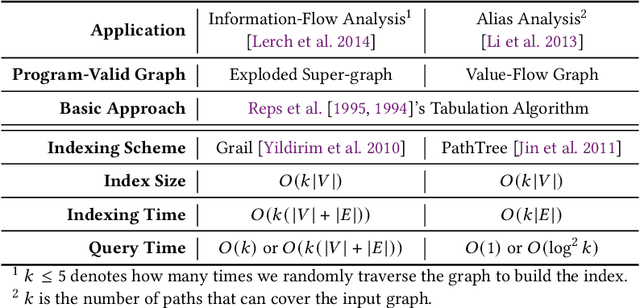
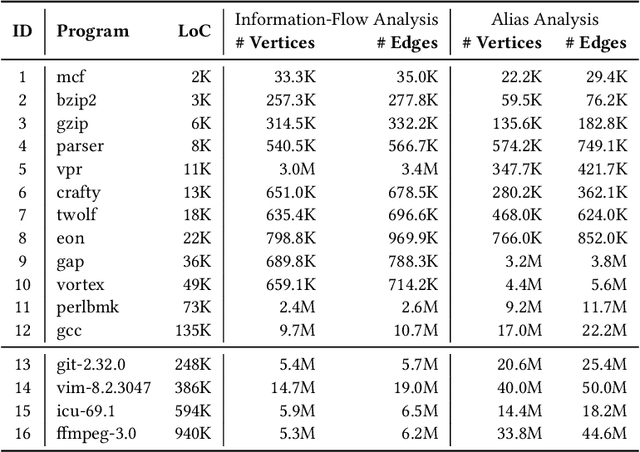
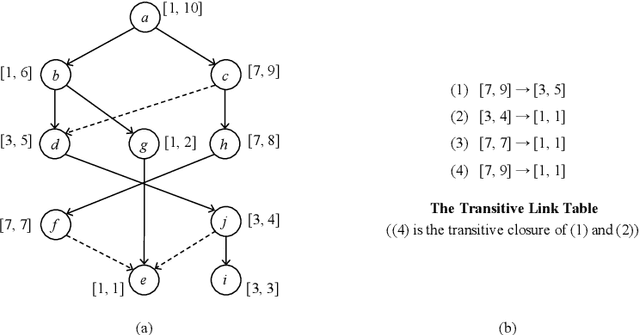
Many context-sensitive data flow analyses can be formulated as a variant of the all-pairs Dyck-CFL reachability problem, which, in general, is of sub-cubic time complexity and quadratic space complexity. Such high complexity significantly limits the scalability of context-sensitive data flow analysis and is not affordable for analyzing large-scale software. This paper presents \textsc{Flare}, a reduction from the CFL reachability problem to the conventional graph reachability problem for context-sensitive data flow analysis. This reduction allows us to benefit from recent advances in reachability indexing schemes, which often consume almost linear space for answering reachability queries in almost constant time. We have applied our reduction to a context-sensitive alias analysis and a context-sensitive information-flow analysis for C/C++ programs. Experimental results on standard benchmarks and open-source software demonstrate that we can achieve orders of magnitude speedup at the cost of only moderate space to store the indexes. The implementation of our approach is publicly available.