 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recurrent Space-time Graphs for Video Understanding
Apr 11, 2019
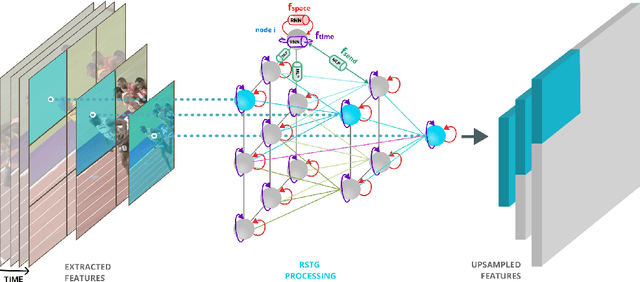
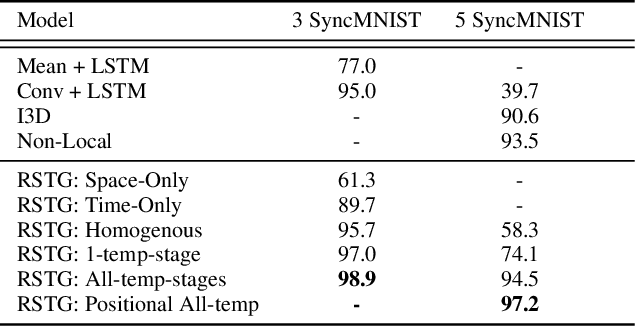
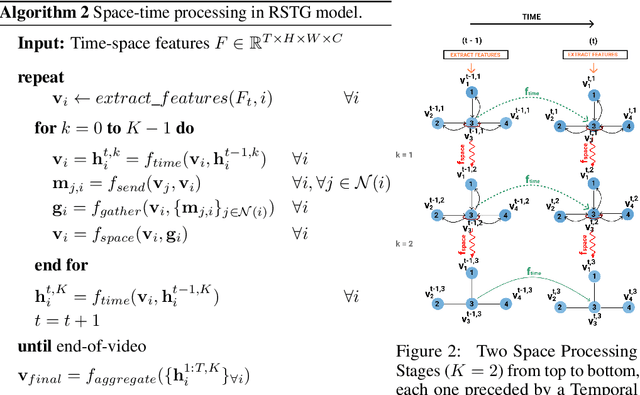
Visual learning in the space-time domain remains a very challenging problem in artificial intelligence. Current computational models for understanding video data are heavily rooted in the classical single-image based paradigm. It is not yet well understood how to integrate visual information from space and time into a single, general model. We propose a neural graph model, recurrent in space and time, suitable for capturing both the appearance and the complex interactions of different entities and objects within the changing world scene. Nodes and links in our graph have dedicated neural networks for processing information. Edges process messages between connected nodes at different locations and scales or between past and present time. Nodes compute over features extracted from local parts in space and time and over messages received from their neighbours and previous memory states. Messages are passed iteratively in order to transmit information globally and establish long range interactions. Our model is general and could learn to recognize a variety of high level spatio-temporal concepts and be applied to different learning tasks. We demonstrate, through extensive experiments, a competitive performance over strong baselines on the tasks of recognizing complex patterns of movement in video.
A Virtual Reality Simulation Pipeline for Online Mental Workload Modeling
Nov 24, 2021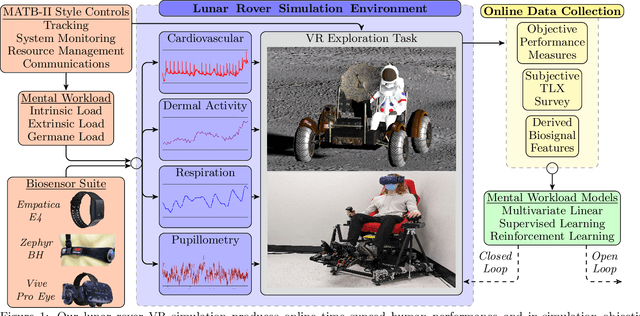
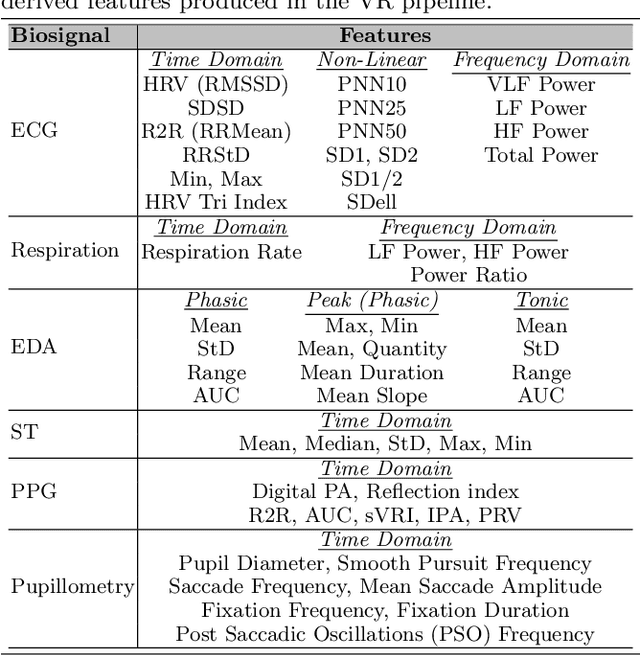

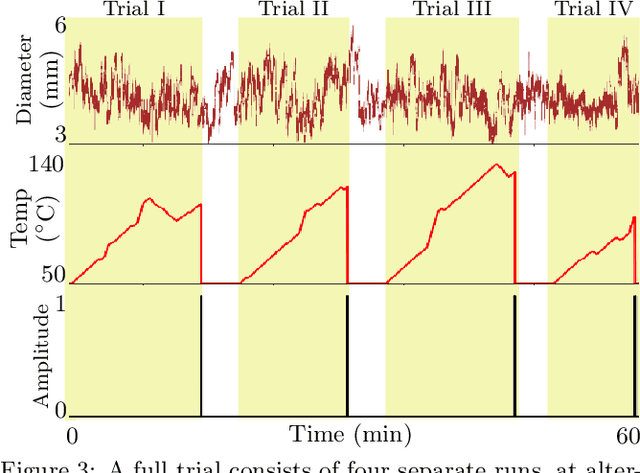
Seamless human robot interaction (HRI) and cooperative human-robot (HR) teaming critically rely upon accurate and timely human mental workload (MW) models. Cognitive Load Theory (CLT) suggests representative physical environments produce representative mental processes; physical environment fidelity corresponds with improved modeling accuracy. Virtual Reality (VR) systems provide immersive environments capable of replicating complicated scenarios, particularly those associated with high-risk, high-stress scenarios. Passive biosignal modeling shows promise as a noninvasive method of MW modeling. However, VR systems rarely include multimodal psychophysiological feedback or capitalize on biosignal data for online MW modeling. Here, we develop a novel VR simulation pipeline, inspired by the NASA Multi-Attribute Task Battery II (MATB-II) task architecture, capable of synchronous collection of objective performance, subjective performance, and passive human biosignals in a simulated hazardous exploration environment. Our system design extracts and publishes biofeatures through the Robot Operating System (ROS), facilitating real time psychophysiology-based MW model integration into complete end-to-end systems. A VR simulation pipeline capable of evaluating MWs online could be foundational for advancing HR systems and VR experiences by enabling these systems to adaptively alter their behaviors in response to operator MW.
Differentiable Generalised Predictive Coding
Dec 08, 2021This paper deals with differentiable dynamical models congruent with neural process theories that cast brain function as the hierarchical refinement of an internal generative model explaining observations. Our work extends existing implementations of gradient-based predictive coding with automatic differentiation and allows to integrate deep neural networks for non-linear state parameterization. Gradient-based predictive coding optimises inferred states and weights locally in for each layer by optimising precision-weighted prediction errors that propagate from stimuli towards latent states. Predictions flow backwards, from latent states towards lower layers. The model suggested here optimises hierarchical and dynamical predictions of latent states. Hierarchical predictions encode expected content and hierarchical structure. Dynamical predictions capture changes in the encoded content along with higher order derivatives. Hierarchical and dynamical predictions interact and address different aspects of the same latent states. We apply the model to various perception and planning tasks on sequential data and show their mutual dependence. In particular, we demonstrate how learning sampling distances in parallel address meaningful locations data sampled at discrete time steps. We discuss possibilities to relax the assumption of linear hierarchies in favor of more flexible graph structure with emergent properties. We compare the granular structure of the model with canonical microcircuits describing predictive coding in biological networks and review the connection to Markov Blankets as a tool to characterize modularity. A final section sketches out ideas for efficient perception and planning in nested spatio-temporal hierarchies.
Timely Status Updating Over Erasure Channels Using an Energy Harvesting Sensor: Single and Multiple Sources
Sep 14, 2021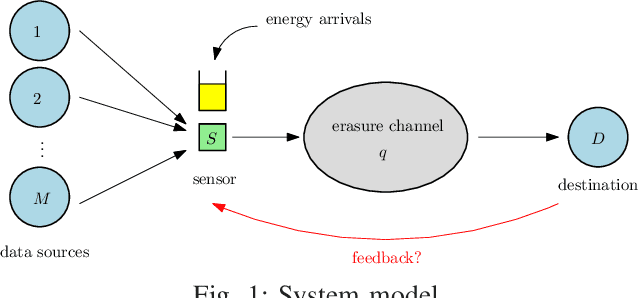
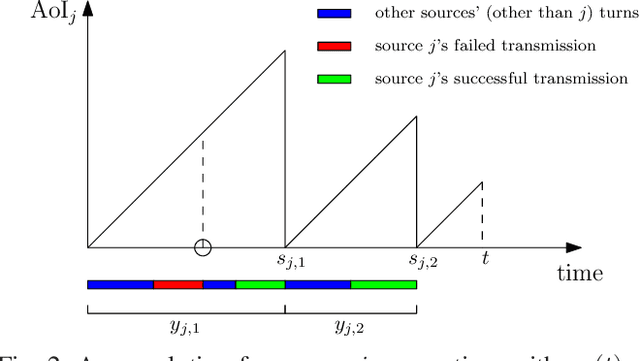
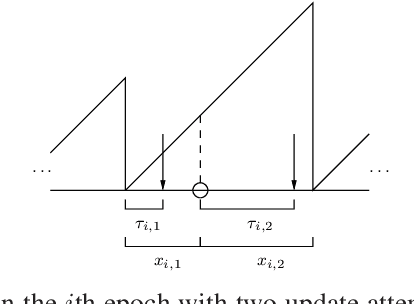
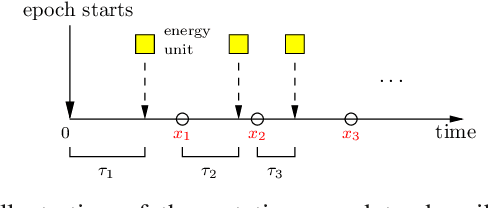
A status updating system is considered in which data from multiple sources are sampled by an energy harvesting sensor and transmitted to a remote destination through an erasure channel. The goal is to deliver status updates of all sources in a timely manner, such that the cumulative long-term average age-of-information (AoI) is minimized. The AoI for each source is defined as the time elapsed since the generation time of the latest successful status update received at the destination from that source. Transmissions are subject to energy availability, which arrives in units according to a Poisson process, with each energy unit capable of carrying out one transmission from only one source. The sensor is equipped with a unit-sized battery to save the incoming energy. A scheduling policy is designed in order to determine which source is sampled using the available energy. The problem is studied in two main settings: no erasure status feedback, and perfect instantaneous feedback.
Intelli-Paint: Towards Developing Human-like Painting Agents
Dec 16, 2021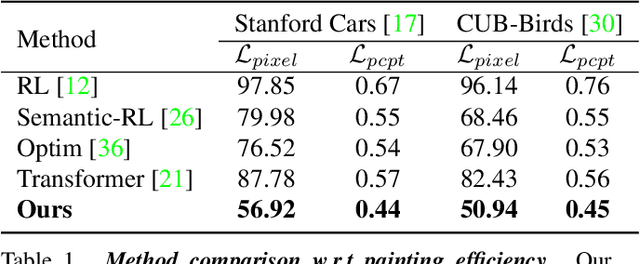
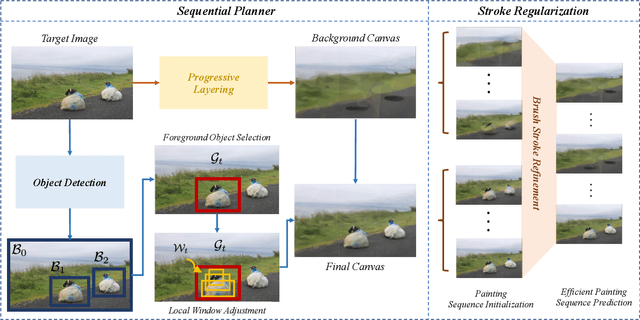


The generation of well-designed artwork is often quite time-consuming and assumes a high degree of proficiency on part of the human painter. In order to facilitate the human painting process, substantial research efforts have been made on teaching machines how to "paint like a human", and then using the trained agent as a painting assistant tool for human users. However, current research in this direction is often reliant on a progressive grid-based division strategy wherein the agent divides the overall image into successively finer grids, and then proceeds to paint each of them in parallel. This inevitably leads to artificial painting sequences which are not easily intelligible to human users. To address this, we propose a novel painting approach which learns to generate output canvases while exhibiting a more human-like painting style. The proposed painting pipeline Intelli-Paint consists of 1) a progressive layering strategy which allows the agent to first paint a natural background scene representation before adding in each of the foreground objects in a progressive fashion. 2) We also introduce a novel sequential brushstroke guidance strategy which helps the painting agent to shift its attention between different image regions in a semantic-aware manner. 3) Finally, we propose a brushstroke regularization strategy which allows for ~60-80% reduction in the total number of required brushstrokes without any perceivable differences in the quality of the generated canvases. Through both quantitative and qualitative results, we show that the resulting agents not only show enhanced efficiency in output canvas generation but also exhibit a more natural-looking painting style which would better assist human users express their ideas through digital artwork.
OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
Oct 12, 2021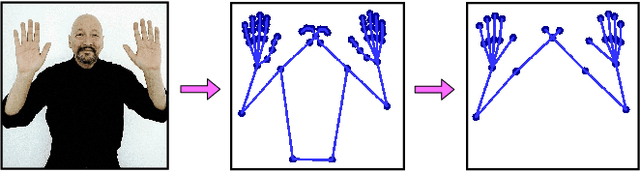
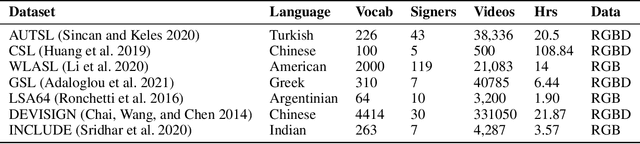
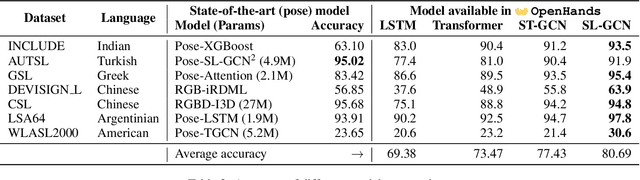
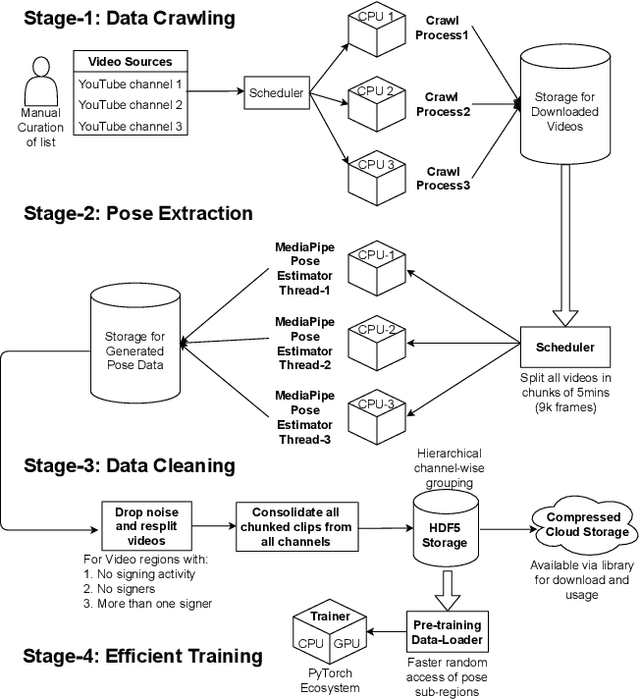
AI technologies for Natural Languages have made tremendous progress recently. However, commensurate progress has not been made on Sign Languages, in particular, in recognizing signs as individual words or as complete sentences. We introduce OpenHands, a library where we take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition. First, we propose using pose extracted through pretrained models as the standard modality of data to reduce training time and enable efficient inference, and we release standardized pose datasets for 6 different sign languages - American, Argentinian, Chinese, Greek, Indian, and Turkish. Second, we train and release checkpoints of 4 pose-based isolated sign language recognition models across all 6 languages, providing baselines and ready checkpoints for deployment. Third, to address the lack of labelled data, we propose self-supervised pretraining on unlabelled data. We curate and release the largest pose-based pretraining dataset on Indian Sign Language (Indian-SL). Fourth, we compare different pretraining strategies and for the first time establish that pretraining is effective for sign language recognition by demonstrating (a) improved fine-tuning performance especially in low-resource settings, and (b) high crosslingual transfer from Indian-SL to few other sign languages. We open-source all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible, available here at https://github.com/AI4Bharat/OpenHands .
Efficacy of Statistical and Artificial Intelligence-based False Information Cyberattack Detection Models for Connected Vehicles
Aug 02, 2021

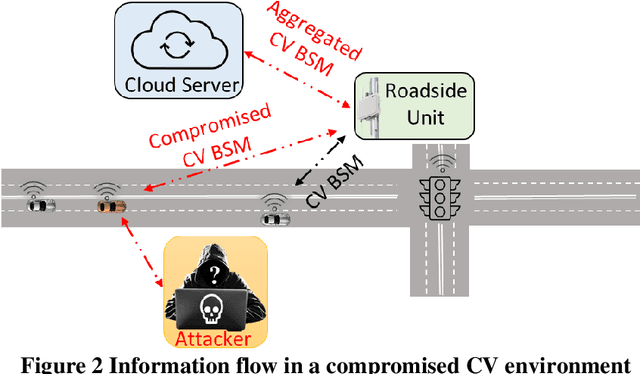
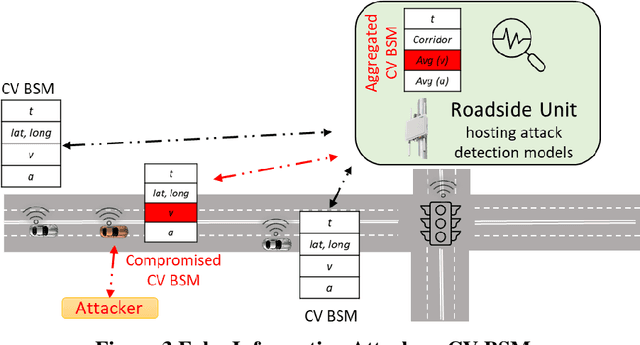
Connected vehicles (CVs), because of the external connectivity with other CVs and connected infrastructure, are vulnerable to cyberattacks that can instantly compromise the safety of the vehicle itself and other connected vehicles and roadway infrastructure. One such cyberattack is the false information attack, where an external attacker injects inaccurate information into the connected vehicles and eventually can cause catastrophic consequences by compromising safety-critical applications like the forward collision warning. The occurrence and target of such attack events can be very dynamic, making real-time and near-real-time detection challenging. Change point models, can be used for real-time anomaly detection caused by the false information attack. In this paper, we have evaluated three change point-based statistical models; Expectation Maximization, Cumulative Summation, and Bayesian Online Change Point Algorithms for cyberattack detection in the CV data. Also, data-driven artificial intelligence (AI) models, which can be used to detect known and unknown underlying patterns in the dataset, have the potential of detecting a real-time anomaly in the CV data. We have used six AI models to detect false information attacks and compared the performance for detecting the attacks with our developed change point models. Our study shows that change points models performed better in real-time false information attack detection compared to the performance of the AI models. Change point models having the advantage of no training requirements can be a feasible and computationally efficient alternative to AI models for false information attack detection in connected vehicles.
Popularity Bias Is Not Always Evil: Disentangling Benign and Harmful Bias for Recommendation
Sep 16, 2021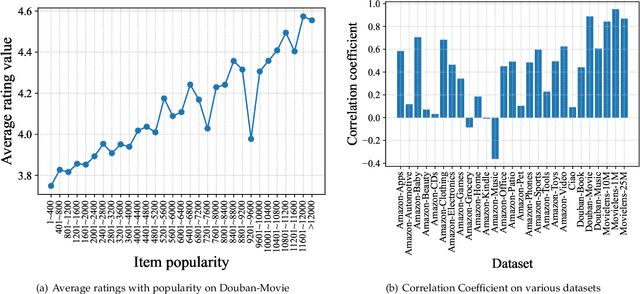

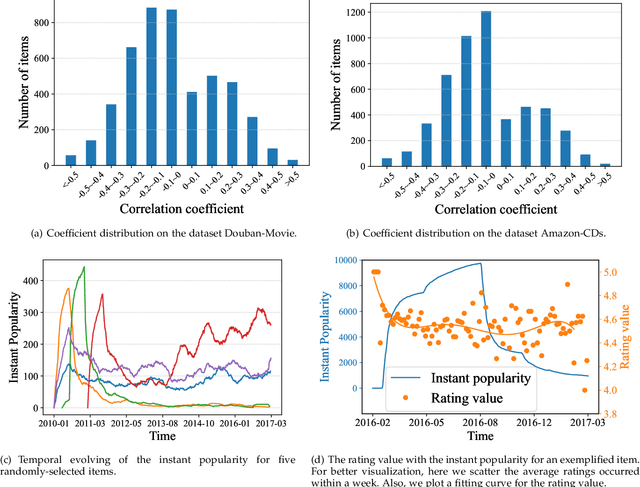

Recommender system usually suffers from severe popularity bias -- the collected interaction data usually exhibits quite imbalanced or even long-tailed distribution over items. Such skewed distribution may result from the users' conformity to the group, which deviates from reflecting users' true preference. Existing efforts for tackling this issue mainly focus on completely eliminating popularity bias. However, we argue that not all popularity bias is evil. Popularity bias not only results from conformity but also item quality, which is usually ignored by existing methods. Some items exhibit higher popularity as they have intrinsic better property. Blindly removing the popularity bias would lose such important signal, and further deteriorate model performance. To sufficiently exploit such important information for recommendation, it is essential to disentangle the benign popularity bias caused by item quality from the harmful popularity bias caused by conformity. Although important, it is quite challenging as we lack an explicit signal to differentiate the two factors of popularity bias. In this paper, we propose to leverage temporal information as the two factors exhibit quite different patterns along the time: item quality revealing item inherent property is stable and static while conformity that depends on items' recent clicks is highly time-sensitive. Correspondingly, we further propose a novel Time-aware DisEntangled framework (TIDE), where a click is generated from three components namely the static item quality, the dynamic conformity effect, as well as the user-item matching score returned by any recommendation model. Lastly, we conduct interventional inference such that the recommendation can benefit from the benign popularity bias while circumvent the harmful one. Extensive experiments on three real-world datasets demonstrated the effectiveness of TIDE.
End-to-end training of time domain audio separation and recognition
Dec 25, 2019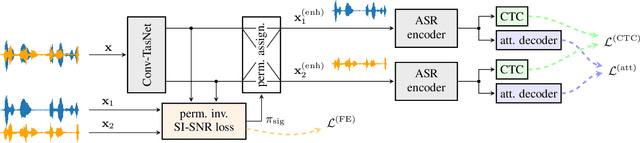


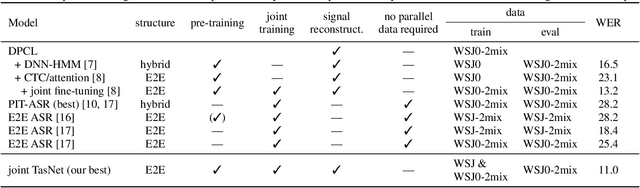
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
Recent Advances in End-to-End Automatic Speech Recognition
Nov 02, 2021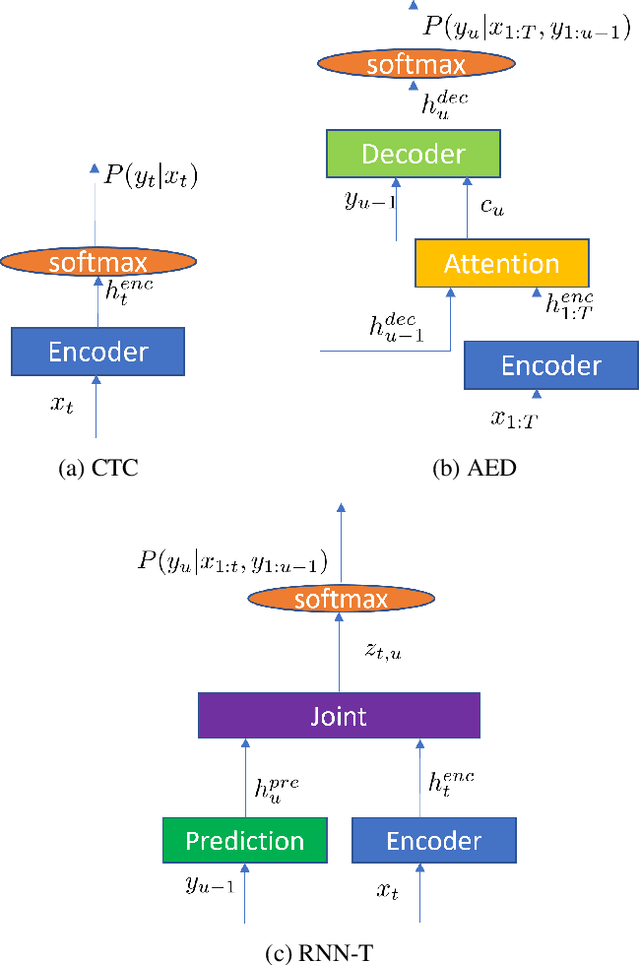
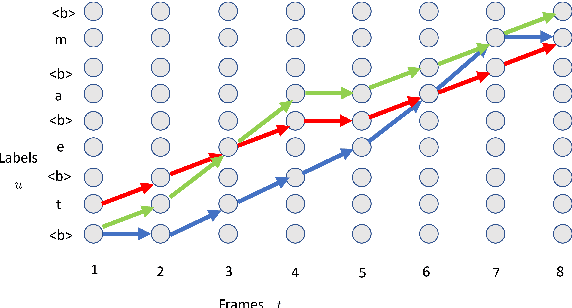

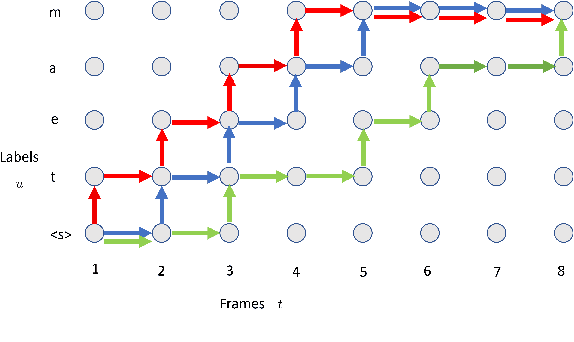
Recently, the speech community is seeing a significant trend of moving from deep neural network based hybrid modeling to end-to-end (E2E) modeling for automatic speech recognition (ASR). While E2E models achieve the state-of-the-art results in most benchmarks in terms of ASR accuracy, hybrid models are still used in a large proportion of commercial ASR systems at the current time. There are lots of practical factors that affect the production model deployment decision. Traditional hybrid models, being optimized for production for decades, are usually good at these factors. Without providing excellent solutions to all these factors, it is hard for E2E models to be widely commercialized. In this paper, we will overview the recent advances in E2E models, focusing on technologies addressing those challenges from the industry's perspective.