 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgraph Concept Networks: Concept Levels in Graph Classification
Apr 20, 2026The reasoning process of Graph Neural Networks is complex and considered opaque, limiting trust in their predictions. To alleviate this issue, prior work has proposed concept-based explanations, extracted from clusters in the model's node embeddings. However, a limitation of concept-based explanations is that they only explain the node embedding space and are obscured by pooling in graph classification. To mitigate this issue and provide a deeper level of understanding, we propose the Subgraph Concept Network. The Subgraph Concept Network is the first graph neural network architecture that distils subgraph and graph-level concepts. It achieves this by performing soft clustering on node concept embeddings to derive subgraph and graph-level concepts. Our results show that the Subgraph Concept Network allows to obtain competitive model accuracy, while discovering meaningful concepts at different levels of the network.
Wasserstein Hypergraph Neural Network
Jun 11, 2025The ability to model relational information using machine learning has driven advancements across various domains, from medicine to social science. While graph representation learning has become mainstream over the past decade, representing higher-order relationships through hypergraphs is rapidly gaining momentum. In the last few years, numerous hypergraph neural networks have emerged, most of them falling under a two-stage, set-based framework. The messages are sent from nodes to edges and then from edges to nodes. However, most of the advancement still takes inspiration from the graph counterpart, often simplifying the aggregations to basic pooling operations. In this paper we are introducing Wasserstein Hypergraph Neural Network, a model that treats the nodes and hyperedge neighbourhood as distributions and aggregate the information using Sliced Wasserstein Pooling. Unlike conventional aggregators such as mean or sum, which only capture first-order statistics, our approach has the ability to preserve geometric properties like the shape and spread of distributions. This enables the learned embeddings to reflect how easily one hyperedge distribution can be transformed into another, following principles of optimal transport. Experimental results demonstrate that applying Wasserstein pooling in a hypergraph setting significantly benefits node classification tasks, achieving top performance on several real-world datasets.
Explaining Hypergraph Neural Networks: From Local Explanations to Global Concepts
Oct 10, 2024



Hypergraph neural networks are a class of powerful models that leverage the message passing paradigm to learn over hypergraphs, a generalization of graphs well-suited to describing relational data with higher-order interactions. However, such models are not naturally interpretable, and their explainability has received very limited attention. We introduce SHypX, the first model-agnostic post-hoc explainer for hypergraph neural networks that provides both local and global explanations. At the instance-level, it performs input attribution by discretely sampling explanation subhypergraphs optimized to be faithful and concise. At the model-level, it produces global explanation subhypergraphs using unsupervised concept extraction. Extensive experiments across four real-world and four novel, synthetic hypergraph datasets demonstrate that our method finds high-quality explanations which can target a user-specified balance between faithfulness and concision, improving over baselines by 25 percent points in fidelity on average.
SPHINX: Structural Prediction using Hypergraph Inference Network
Oct 04, 2024



The importance of higher-order relations is widely recognized in a large number of real-world systems. However, annotating them is a tedious and sometimes impossible task. Consequently, current approaches for data modelling either ignore the higher-order interactions altogether or simplify them into pairwise connections. In order to facilitate higher-order processing, even when a hypergraph structure is not available, we introduce Structural Prediction using Hypergraph Inference Network (SPHINX), a model that learns to infer a latent hypergraph structure in an unsupervised way, solely from the final node-level signal. The model consists of a soft, differentiable clustering method used to sequentially predict, for each hyperedge, the probability distribution over the nodes and a sampling algorithm that converts them into an explicit hypergraph structure. We show that the recent advancement in k-subset sampling represents a suitable tool for producing discrete hypergraph structures, addressing some of the training instabilities exhibited by prior works. The resulting model can generate the higher-order structure necessary for any modern hypergraph neural network, facilitating the capture of higher-order interaction in domains where annotating them is difficult. Through extensive ablation studies and experiments conducted on two challenging datasets for trajectory prediction, we demonstrate that our model is capable of inferring suitable latent hypergraphs, that are interpretable and enhance the final performance.
Heterogeneous Sheaf Neural Networks
Sep 12, 2024



Heterogeneous graphs, with nodes and edges of different types, are commonly used to model relational structures in many real-world applications. Standard Graph Neural Networks (GNNs) struggle to process heterogeneous data due to oversmoothing. Instead, current approaches have focused on accounting for the heterogeneity in the model architecture, leading to increasingly complex models. Inspired by recent work, we propose using cellular sheaves to model the heterogeneity in the graph's underlying topology. Instead of modelling the data as a graph, we represent it as cellular sheaves, which allows us to encode the different data types directly in the data structure, eliminating the need to inject them into the architecture. We introduce HetSheaf, a general framework for heterogeneous sheaf neural networks, and a series of heterogeneous sheaf predictors to better encode the data's heterogeneity into the sheaf structure. Finally, we empirically evaluate HetSheaf on several standard heterogeneous graph benchmarks, achieving competitive results whilst being more parameter-efficient.
Joint Diffusion Processes as an Inductive Bias in Sheaf Neural Networks
Jul 30, 2024Sheaf Neural Networks (SNNs) naturally extend Graph Neural Networks (GNNs) by endowing a cellular sheaf over the graph, equipping nodes and edges with vector spaces and defining linear mappings between them. While the attached geometric structure has proven to be useful in analyzing heterophily and oversmoothing, so far the methods by which the sheaf is computed do not always guarantee a good performance in such settings. In this work, drawing inspiration from opinion dynamics concepts, we propose two novel sheaf learning approaches that (i) provide a more intuitive understanding of the involved structure maps, (ii) introduce a useful inductive bias for heterophily and oversmoothing, and (iii) infer the sheaf in a way that does not scale with the number of features, thus using fewer learnable parameters than existing methods. In our evaluation, we show the limitations of the real-world benchmarks used so far on SNNs, and design a new synthetic task -- leveraging the symmetries of n-dimensional ellipsoids -- that enables us to better assess the strengths and weaknesses of sheaf-based models. Our extensive experimentation on these novel datasets reveals valuable insights into the scenarios and contexts where SNNs in general -- and our proposed approaches in particular -- can be beneficial.
Sheaf Hypergraph Networks
Sep 29, 2023



Higher-order relations are widespread in nature, with numerous phenomena involving complex interactions that extend beyond simple pairwise connections. As a result, advancements in higher-order processing can accelerate the growth of various fields requiring structured data. Current approaches typically represent these interactions using hypergraphs. We enhance this representation by introducing cellular sheaves for hypergraphs, a mathematical construction that adds extra structure to the conventional hypergraph while maintaining their local, higherorder connectivity. Drawing inspiration from existing Laplacians in the literature, we develop two unique formulations of sheaf hypergraph Laplacians: linear and non-linear. Our theoretical analysis demonstrates that incorporating sheaves into the hypergraph Laplacian provides a more expressive inductive bias than standard hypergraph diffusion, creating a powerful instrument for effectively modelling complex data structures. We employ these sheaf hypergraph Laplacians to design two categories of models: Sheaf Hypergraph Neural Networks and Sheaf Hypergraph Convolutional Networks. These models generalize classical Hypergraph Networks often found in the literature. Through extensive experimentation, we show that this generalization significantly improves performance, achieving top results on multiple benchmark datasets for hypergraph node classification.
Dynamic Regions Graph Neural Networks for Spatio-Temporal Reasoning
Sep 17, 2020
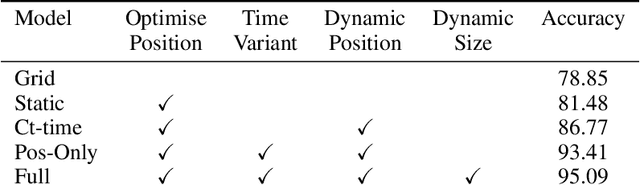
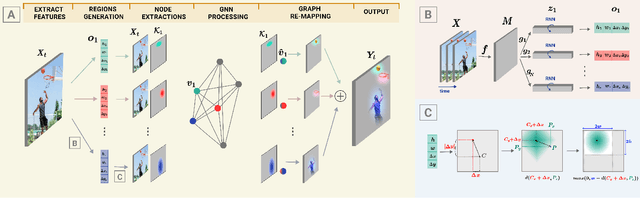
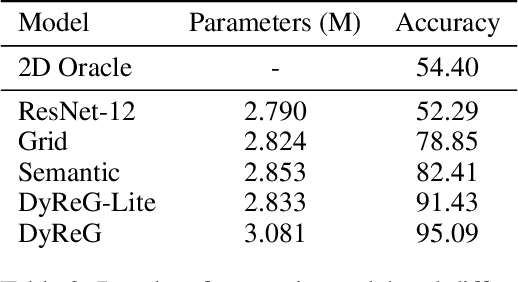
Graph Neural Networks are perfectly suited to capture latent interactions occurring in the spatio-temporal domain. But when an explicit structure is not available, as in the visual domain, it is not obvious what atomic elements should be represented as nodes. They should depend on the context and the kinds of relations that we are interested in. We are focusing on modeling relations between instances by proposing a method that takes advantage of the locality assumption to create nodes that are clearly localised in space. Current works are using external object detectors or fixed regions to extract features corresponding to graph nodes, while we propose a module for generating the regions associated with each node dynamically, without explicit object-level supervision. Conditioned on the input, for each node we predict the location and size of a region and use them to pool node features using a differentiable mechanism. Constructing these localised, adaptive nodes makes our model biased towards object-centric representations and we show that it improves the modeling of visual interactions. By relying on a few localized nodes, our method learns to focus on salient regions leading to a more explainable model. Our model achieves superior results on video classification tasks involving instance interactions.
Recurrent Space-time Graphs for Video Understanding
Apr 11, 2019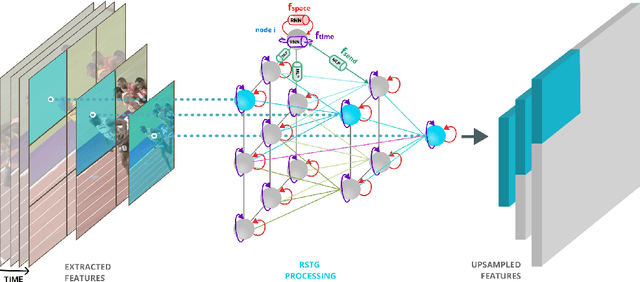
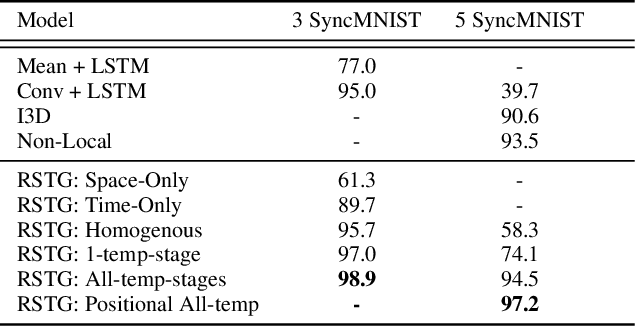
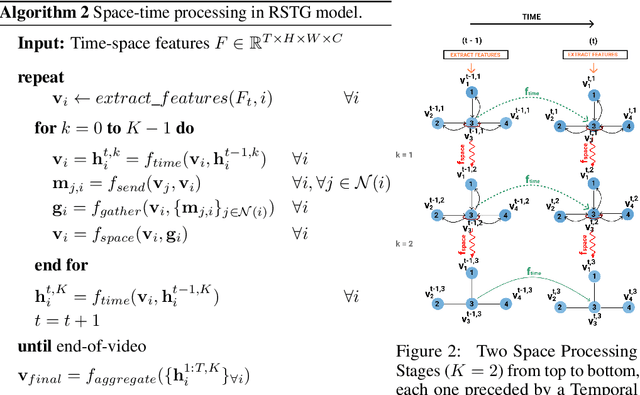
Visual learning in the space-time domain remains a very challenging problem in artificial intelligence. Current computational models for understanding video data are heavily rooted in the classical single-image based paradigm. It is not yet well understood how to integrate visual information from space and time into a single, general model. We propose a neural graph model, recurrent in space and time, suitable for capturing both the appearance and the complex interactions of different entities and objects within the changing world scene. Nodes and links in our graph have dedicated neural networks for processing information. Edges process messages between connected nodes at different locations and scales or between past and present time. Nodes compute over features extracted from local parts in space and time and over messages received from their neighbours and previous memory states. Messages are passed iteratively in order to transmit information globally and establish long range interactions. Our model is general and could learn to recognize a variety of high level spatio-temporal concepts and be applied to different learning tasks. We demonstrate, through extensive experiments, a competitive performance over strong baselines on the tasks of recognizing complex patterns of movement in video.
Mining for meaning: from vision to language through multiple networks consensus
Sep 18, 2018



Describing visual data into natural language is a very challenging task, at the intersection of computer vision, natural language processing and machine learning. Language goes well beyond the description of physical objects and their interactions and can convey the same abstract idea in many ways. It is both about content at the highest semantic level as well as about fluent form. Here we propose an approach to describe videos in natural language by reaching a consensus among multiple encoder-decoder networks. Finding such a consensual linguistic description, which shares common properties with a larger group, has a better chance to convey the correct meaning. We propose and train several network architectures and use different types of image, audio and video features. Each model produces its own description of the input video and the best one is chosen through an efficient, two-phase consensus process. We demonstrate the strength of our approach by obtaining state of the art results on the challenging MSR-VTT dataset.