 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Communication and Energy Efficient Slimmable Federated Learning via Superposition Coding and Successive Decoding
Dec 05, 2021
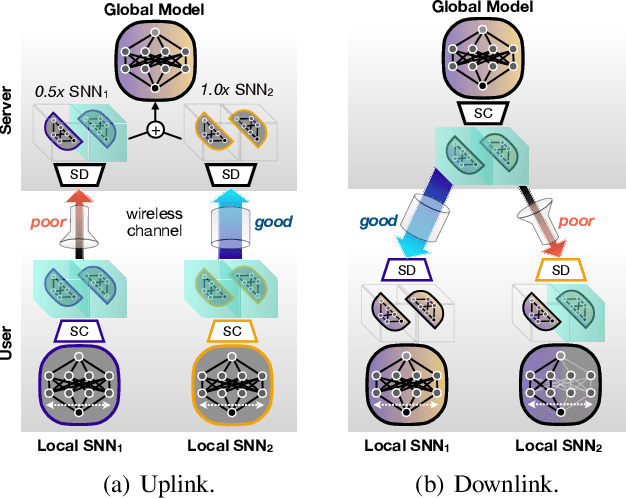
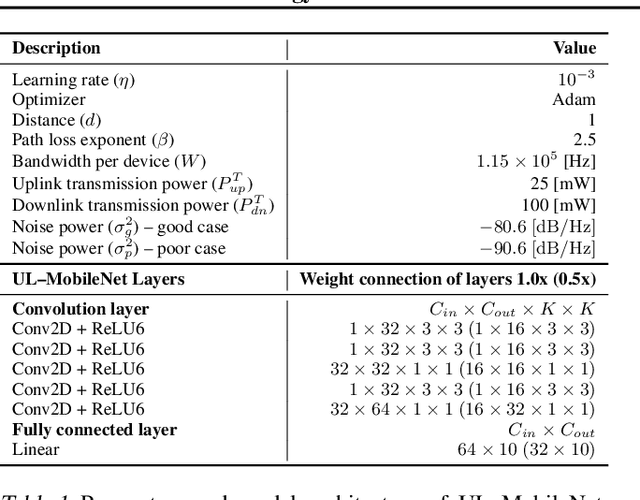
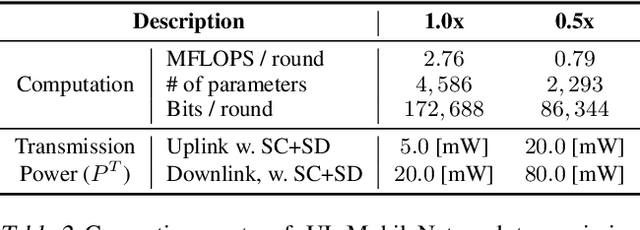

Mobile devices are indispensable sources of big data. Federated learning (FL) has a great potential in exploiting these private data by exchanging locally trained models instead of their raw data. However, mobile devices are often energy limited and wirelessly connected, and FL cannot cope flexibly with their heterogeneous and time-varying energy capacity and communication throughput, limiting the adoption. Motivated by these issues, we propose a novel energy and communication efficient FL framework, coined SlimFL. To resolve the heterogeneous energy capacity problem, each device in SlimFL runs a width-adjustable slimmable neural network (SNN). To address the heterogeneous communication throughput problem, each full-width (1.0x) SNN model and its half-width ($0.5$x) model are superposition-coded before transmission, and successively decoded after reception as the 0.5x or $1.0$x model depending on the channel quality. Simulation results show that SlimFL can simultaneously train both $0.5$x and $1.0$x models with reasonable accuracy and convergence speed, compared to its vanilla FL counterpart separately training the two models using $2$x more communication resources. Surprisingly, SlimFL achieves even higher accuracy with lower energy footprints than vanilla FL for poor channels and non-IID data distributions, under which vanilla FL converges slowly.
Comparison of Neural Network based Soft Computing Techniques for Electromagnetic Modeling of a Microstrip Patch Antenna
Sep 21, 2021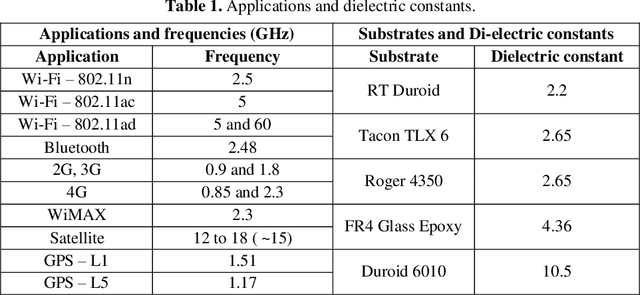
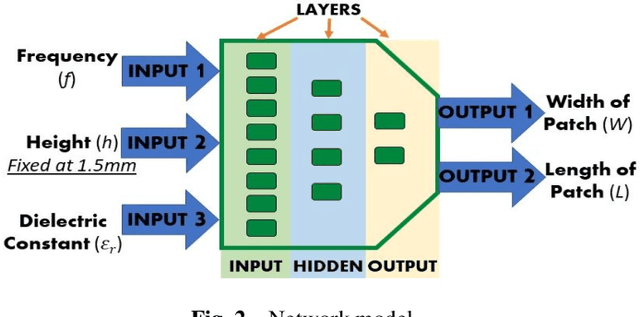
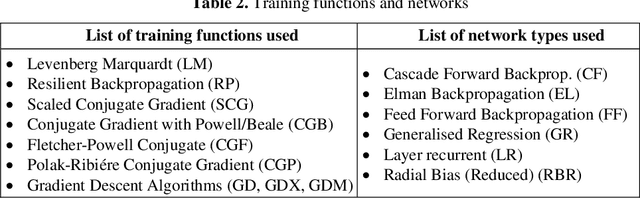
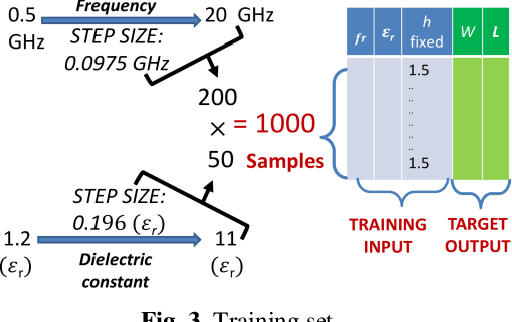
This paper presents the comparison of various neural networks and algorithms based on accuracy, quickness, and consistency for antenna modelling. Using Nntool by MATLAB, 22 different combinations of networks and training algorithms are used to predict the dimensions of a rectangular microstrip antenna using dielectric constant, height of substrate, and frequency of operation as input. Comparison and characterization of networks is done based on accuracy, mean square error, and training time. Algorithms, on the other hand, are analyzed by their accuracy, speed, reliability, and smoothness in the training process. Finally, these results are analyzed, and recommendations are made for each neural network and algorithm based on uses, advantages, and disadvantages. For example, it is observed that Reduced Radial Bias network is the most accurate network and Scaled Conjugate Gradient is the most reliable algorithm for electromagnetic modelling. This paper will help a researcher find the optimum network and algorithm directly without doing time-taking experimentation.
Short-Term Power Prediction for Renewable Energy Using Hybrid Graph Convolutional Network and Long Short-Term Memory Approach
Nov 15, 2021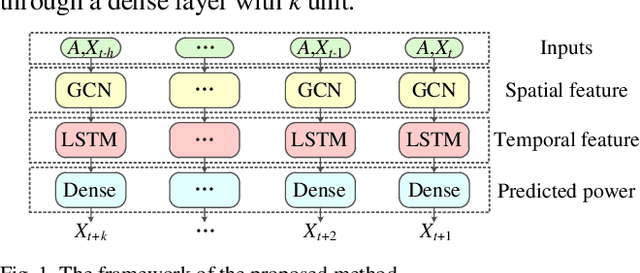
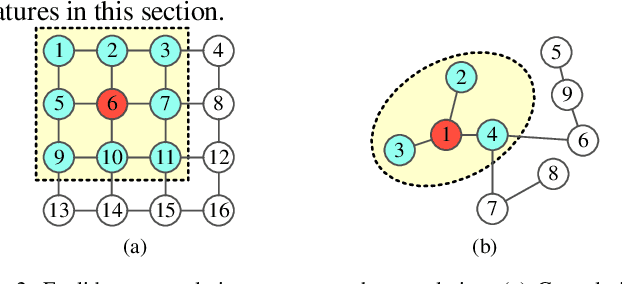
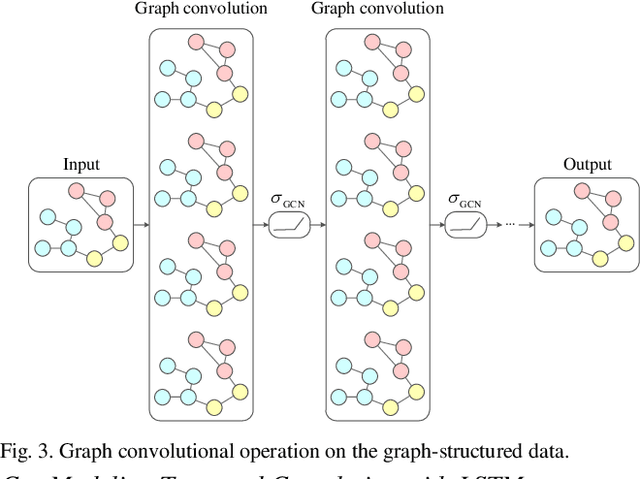
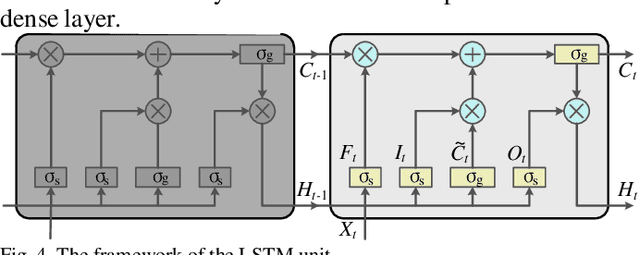
Accurate short-term solar and wind power predictions play an important role in the planning and operation of power systems. However, the short-term power prediction of renewable energy has always been considered a complex regression problem, owing to the fluctuation and intermittence of output powers and the law of dynamic change with time due to local weather conditions, i.e. spatio-temporal correlation. To capture the spatio-temporal features simultaneously, this paper proposes a new graph neural network-based short-term power forecasting approach, which combines the graph convolutional network (GCN) and long short-term memory (LSTM). Specifically, the GCN is employed to learn complex spatial correlations between adjacent renewable energies, and the LSTM is used to learn dynamic changes of power curves. The simulation results show that the proposed hybrid approach can model the spatio-temporal correlation of renewable energies, and its performance outperforms popular baselines on real-world datasets.
A Survey of Self-Supervised and Few-Shot Object Detection
Nov 08, 2021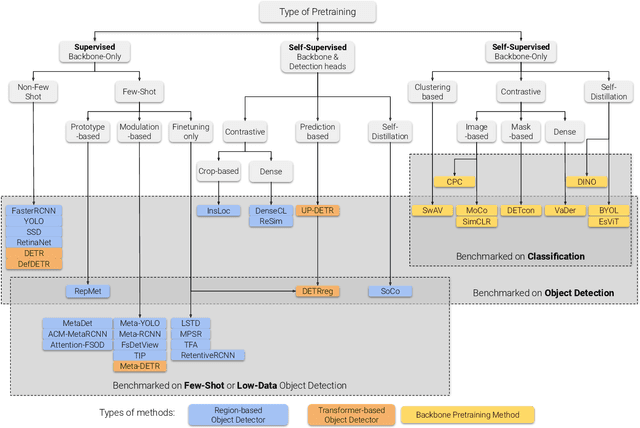

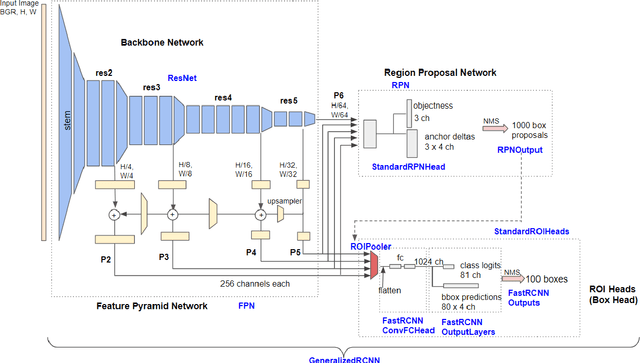
Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions. Project page at https://gabrielhuang.github.io/fsod-survey/
Robustness Certificates for Implicit Neural Networks: A Mixed Monotone Contractive Approach
Dec 10, 2021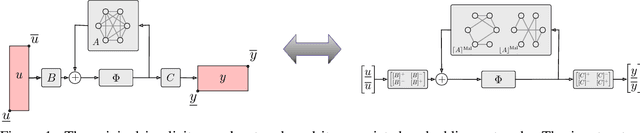
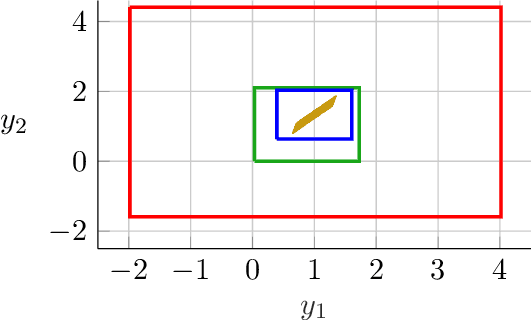
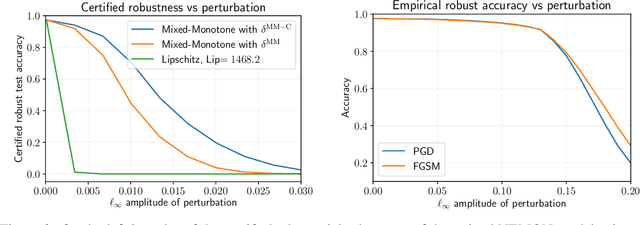
Implicit neural networks are a general class of learning models that replace the layers in traditional feedforward models with implicit algebraic equations. Compared to traditional learning models, implicit networks offer competitive performance and reduced memory consumption. However, they can remain brittle with respect to input adversarial perturbations. This paper proposes a theoretical and computational framework for robustness verification of implicit neural networks; our framework blends together mixed monotone systems theory and contraction theory. First, given an implicit neural network, we introduce a related embedded network and show that, given an $\ell_\infty$-norm box constraint on the input, the embedded network provides an $\ell_\infty$-norm box overapproximation for the output of the given network. Second, using $\ell_{\infty}$-matrix measures, we propose sufficient conditions for well-posedness of both the original and embedded system and design an iterative algorithm to compute the $\ell_{\infty}$-norm box robustness margins for reachability and classification problems. Third, of independent value, we propose a novel relative classifier variable that leads to tighter bounds on the certified adversarial robustness in classification problems. Finally, we perform numerical simulations on a Non-Euclidean Monotone Operator Network (NEMON) trained on the MNIST dataset. In these simulations, we compare the accuracy and run time of our mixed monotone contractive approach with the existing robustness verification approaches in the literature for estimating the certified adversarial robustness.
A General Optimization Framework for Dynamic Time Warping
May 31, 2019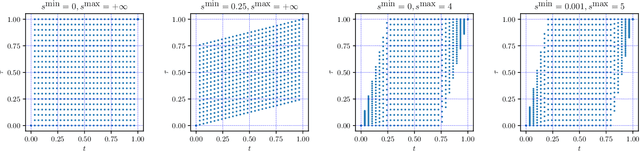
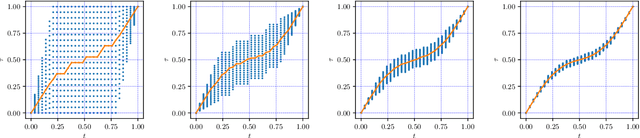
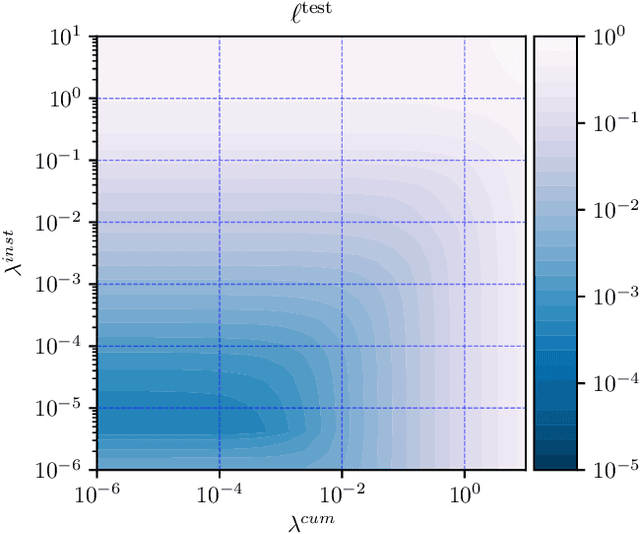
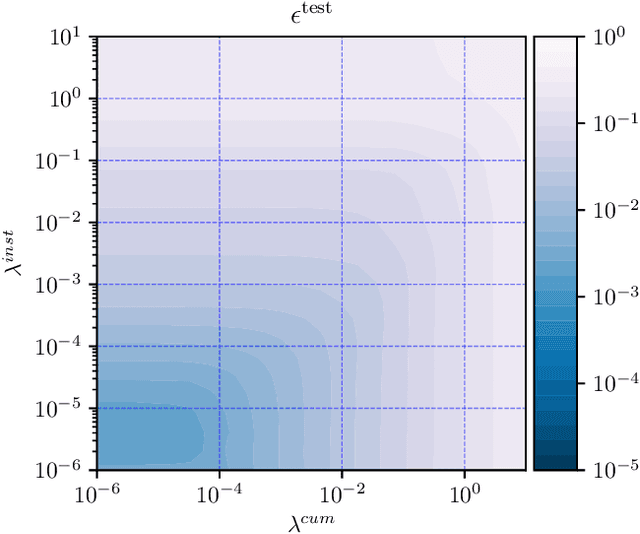
The goal of dynamic time warping is to transform or warp time in order to approximately align two signals together. We pose the choice of warping function as an optimization problem with several terms in the objective. The first term measures the misalignment of the time-warped signals. Two additional regularization terms penalize the cumulative warping and the instantaneous rate of time warping; constraints on the warping can be imposed by assigning the value +inf to the regularization terms. Different choices of the three objective terms yield different time warping functions that trade off signal fit or alignment and properties of the warping function. The optimization problem we formulate is a classical optimal control problem, with initial and terminal constraints, and a state dimension of one. We describe an effective general method that minimizes the objective by discretizing the values of the original and warped time, and using standard dynamic programming to compute the (globally) optimal warping function with the discretized values. Iterated refinement of this scheme yields a high accuracy warping function in just a few iterations. Our method is implemented as an open source Python package GDTW.
Deep Time-Stream Framework for Click-Through Rate Prediction by Tracking Interest Evolution
Jan 08, 2020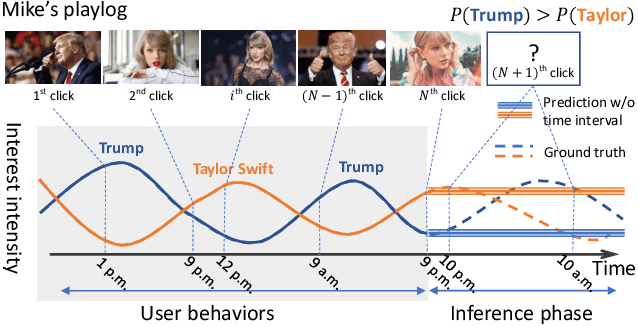
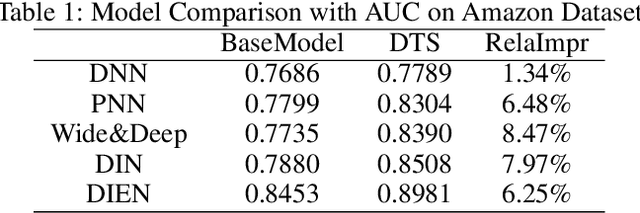
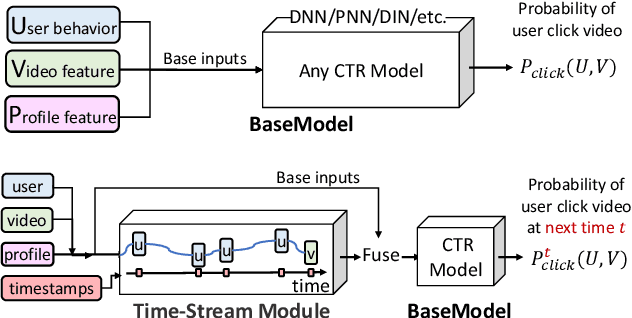
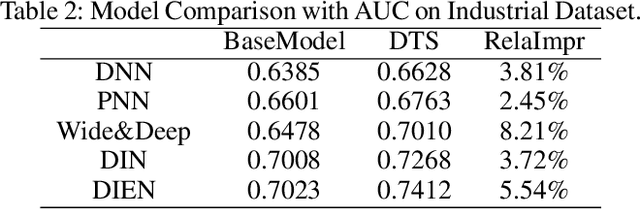
Click-through rate (CTR) prediction is an essential task in industrial applications such as video recommendation. Recently, deep learning models have been proposed to learn the representation of users' overall interests, while ignoring the fact that interests may dynamically change over time. We argue that it is necessary to consider the continuous-time information in CTR models to track user interest trend from rich historical behaviors. In this paper, we propose a novel Deep Time-Stream framework (DTS) which introduces the time information by an ordinary differential equations (ODE). DTS continuously models the evolution of interests using a neural network, and thus is able to tackle the challenge of dynamically representing users' interests based on their historical behaviors. In addition, our framework can be seamlessly applied to any existing deep CTR models by leveraging the additional Time-Stream Module, while no changes are made to the original CTR models. Experiments on public dataset as well as real industry dataset with billions of samples demonstrate the effectiveness of proposed approaches, which achieve superior performance compared with existing methods.
* 8 pages. arXiv admin note: text overlap with arXiv:1809.03672 by other authors
Dynamic Neural Network Architectural and Topological Adaptation and Related Methods -- A Survey
Jul 28, 2021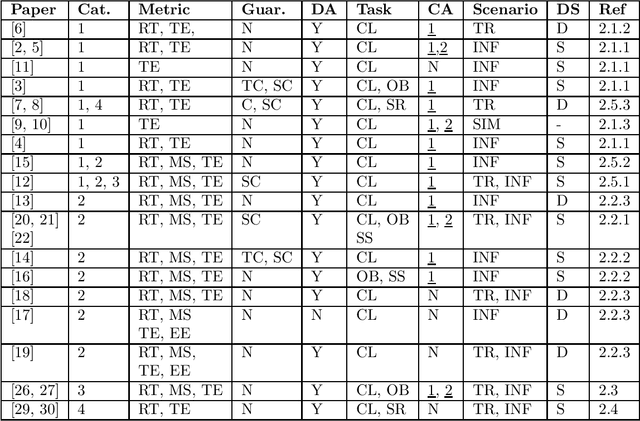
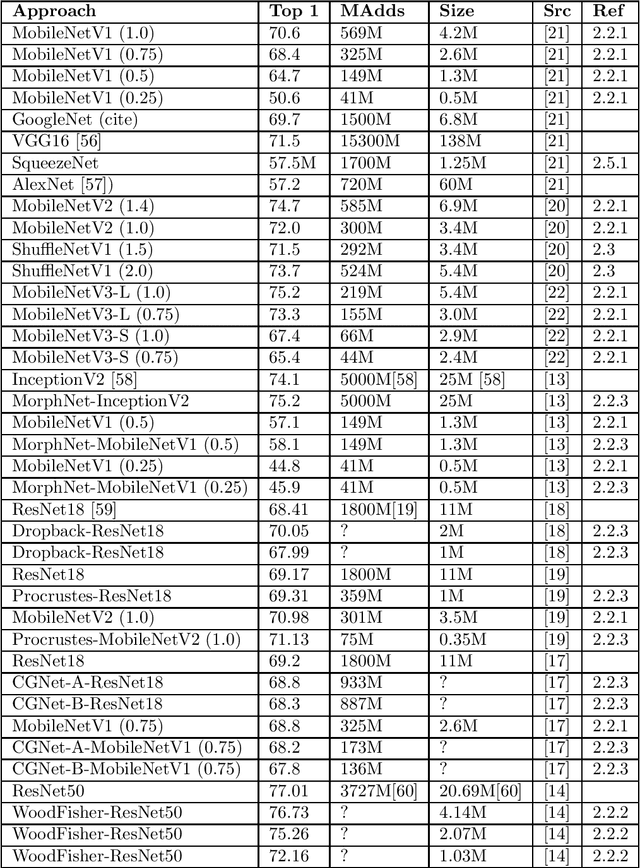
Training and inference in deep neural networks (DNNs) has, due to a steady increase in architectural complexity and data set size, lead to the development of strategies for reducing time and space requirements of DNN training and inference, which is of particular importance in scenarios where training takes place in resource constrained computation environments or inference is part of a time critical application. In this survey, we aim to provide a general overview and categorization of state-of-the-art (SOTA) of techniques to reduced DNN training and inference time and space complexities with a particular focus on architectural adaptions.
LiveView: Dynamic Target-Centered MPI for View Synthesis
Jul 11, 2021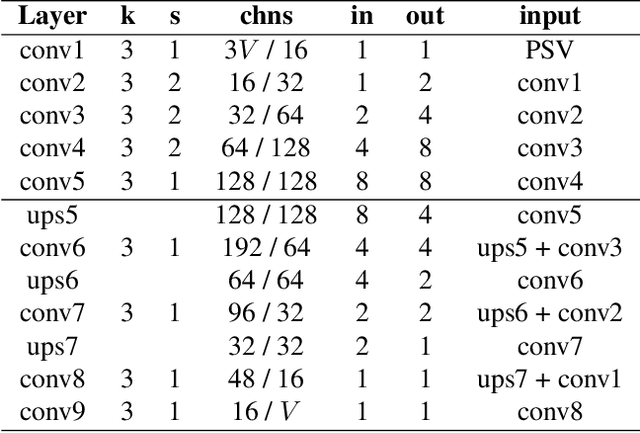
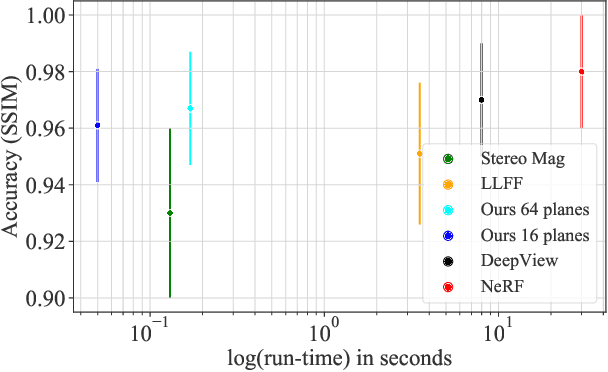
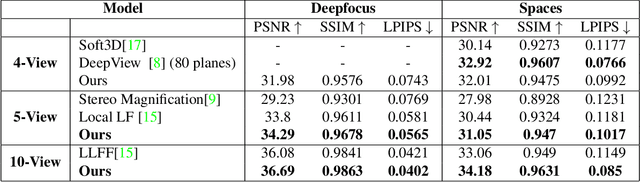
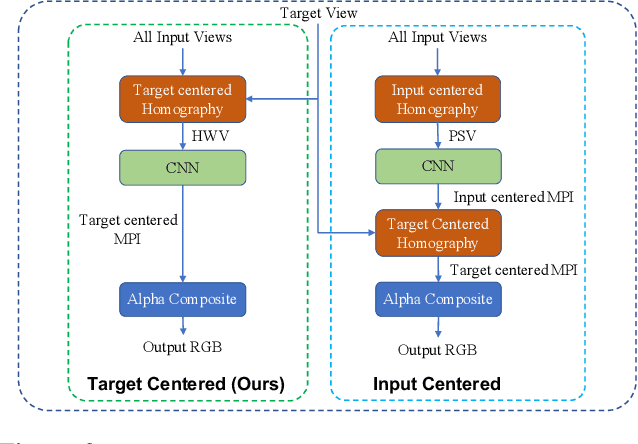
Existing Multi-Plane Image (MPI) based view-synthesis methods generate an MPI aligned with the input view using a fixed number of planes in one forward pass. These methods produce fast, high-quality rendering of novel views, but rely on slow and computationally expensive MPI generation methods unsuitable for real-time applications. In addition, most MPI techniques use fixed depth/disparity planes which cannot be modified once the training is complete, hence offering very little flexibility at run-time. We propose LiveView - a novel MPI generation and rendering technique that produces high-quality view synthesis in real-time. Our method can also offer the flexibility to select scene-dependent MPI planes (number of planes and spacing between them) at run-time. LiveView first warps input images to target view (target-centered) and then learns to generate a target view centered MPI, one depth plane at a time (dynamically). The method generates high-quality renderings, while also enabling fast MPI generation and novel view synthesis. As a result, LiveView enables real-time view synthesis applications where an MPI needs to be updated frequently based on a video stream of input views. We demonstrate that LiveView improves the quality of view synthesis while being 70 times faster at run-time compared to state-of-the-art MPI-based methods.
Data-driven Set-based Estimation of Polynomial Systems with Application to SIR Epidemics
Nov 08, 2021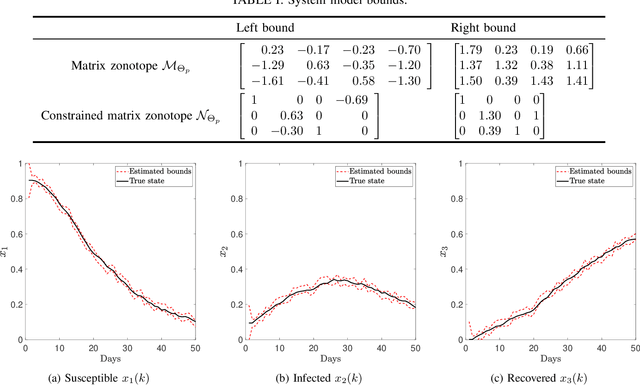
This paper proposes a data-driven set-based estimation algorithm for a class of nonlinear systems with polynomial nonlinearities. Using the system's input-output data, the proposed method computes in real-time a set that guarantees the inclusion of the system's state. Although the system is assumed to be polynomial type, the exact polynomial functions and their coefficients need not be known. To this end, the estimator relies on offline and online phases. The offline phase utilizes past input-output data to estimate a set of possible coefficients of the polynomial system. Then, using this estimated set of coefficients and the side information about the system, the online phase provides a set estimate of the state. Finally, the proposed methodology is evaluated through its application on SIR (Susceptible, Infected, Recovered) epidemic model.