 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloChrome: Polychromatic Illumination for Speckle Reduction in Holographic Near-Eye Displays
Oct 31, 2024Holographic displays hold the promise of providing authentic depth cues, resulting in enhanced immersive visual experiences for near-eye applications. However, current holographic displays are hindered by speckle noise, which limits accurate reproduction of color and texture in displayed images. We present HoloChrome, a polychromatic holographic display framework designed to mitigate these limitations. HoloChrome utilizes an ultrafast, wavelength-adjustable laser and a dual-Spatial Light Modulator (SLM) architecture, enabling the multiplexing of a large set of discrete wavelengths across the visible spectrum. By leveraging spatial separation in our dual-SLM setup, we independently manipulate speckle patterns across multiple wavelengths. This novel approach effectively reduces speckle noise through incoherent averaging achieved by wavelength multiplexing. Our method is complementary to existing speckle reduction techniques, offering a new pathway to address this challenge. Furthermore, the use of polychromatic illumination broadens the achievable color gamut compared to traditional three-color primary holographic displays. Our simulations and tabletop experiments validate that HoloChrome significantly reduces speckle noise and expands the color gamut. These advancements enhance the performance of holographic near-eye displays, moving us closer to practical, immersive next-generation visual experiences.
Practical High-Contrast Holography
Oct 25, 2024Holographic displays are a promising technology for immersive visual experiences, and their potential for compact form factor makes them a strong candidate for head-mounted displays. However, at the short propagation distances needed for a compact, head-mounted architecture, image contrast is low when using a traditional phase-only spatial light modulator (SLM). Although a complex SLM could restore contrast, these modulators require bulky lenses to optically co-locate the amplitude and phase components, making them poorly suited for a compact head-mounted design. In this work, we introduce a novel architecture to improve contrast: by adding a low resolution amplitude SLM a short distance away from the phase modulator, we demonstrate peak signal-to-noise ratio improvement up to 31 dB in simulation compared to phase-only, even when the amplitude modulator is 60$\times$ lower resolution than its phase counterpart. We analyze the relationship between diffraction angle and amplitude modulator pixel size, and validate the concept with a benchtop experimental prototype. By showing that low resolution modulation is sufficient to improve contrast, we pave the way towards practical high-contrast holography in a compact form factor.
3D Imaging of Complex Specular Surfaces by Fusing Polarimetric and Deflectometric Information
Jun 04, 2024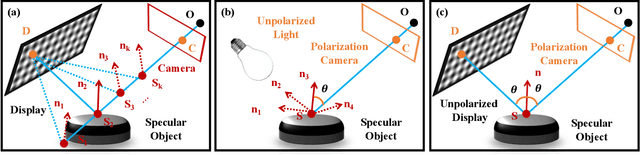

Accurate and fast 3D imaging of specular surfaces still poses major challenges for state-of-the-art optical measurement principles. Frequently used methods, such as phase-measuring deflectometry (PMD) or shape-from-polarization (SfP), rely on strong assumptions about the measured objects, limiting their generalizability in broader application areas like medical imaging, industrial inspection, virtual reality, or cultural heritage analysis. In this paper, we introduce a measurement principle that utilizes a novel technique to effectively encode and decode the information contained in a light field reflected off a specular surface. We combine polarization cues from SfP with geometric information obtained from PMD to resolve all arising ambiguities in the 3D measurement. Moreover, our approach removes the unrealistic orthographic imaging assumption for SfP, which significantly improves the respective results. We showcase our new technique by demonstrating single-shot and multi-shot measurements on complex-shaped specular surfaces, displaying an evaluated accuracy of surface normals below $0.6^\circ$.
Event-based Shape from Polarization with Spiking Neural Networks
Dec 26, 2023Recent advances in event-based shape determination from polarization offer a transformative approach that tackles the trade-off between speed and accuracy in capturing surface geometries. In this paper, we investigate event-based shape from polarization using Spiking Neural Networks (SNNs), introducing the Single-Timestep and Multi-Timestep Spiking UNets for effective and efficient surface normal estimation. Specificially, the Single-Timestep model processes event-based shape as a non-temporal task, updating the membrane potential of each spiking neuron only once, thereby reducing computational and energy demands. In contrast, the Multi-Timestep model exploits temporal dynamics for enhanced data extraction. Extensive evaluations on synthetic and real-world datasets demonstrate that our models match the performance of state-of-the-art Artifical Neural Networks (ANNs) in estimating surface normals, with the added advantage of superior energy efficiency. Our work not only contributes to the advancement of SNNs in event-based sensing but also sets the stage for future explorations in optimizing SNN architectures, integrating multi-modal data, and scaling for applications on neuromorphic hardware.
Event-based Motion-Robust Accurate Shape Estimation for Mixed Reflectance Scenes
Nov 16, 2023



Event-based structured light systems have recently been introduced as an exciting alternative to conventional frame-based triangulation systems for the 3D measurements of diffuse surfaces. Important benefits include the fast capture speed and the high dynamic range provided by the event camera - albeit at the cost of lower data quality. So far, both low-accuracy event-based as well as high-accuracy frame-based 3D imaging systems are tailored to a specific surface type, such as diffuse or specular, and can not be used for a broader class of object surfaces ("mixed reflectance scenes"). In this paper, we present a novel event-based structured light system that enables fast 3D imaging of mixed reflectance scenes with high accuracy. On the captured events, we use epipolar constraints that intrinsically enable decomposing the measured reflections into diffuse, two-bounce specular, and other multi-bounce reflections. The diffuse objects in the scene are reconstructed using triangulation. Eventually, the reconstructed diffuse scene parts are used as a "display" to evaluate the specular scene parts via deflectometry. This novel procedure allows us to use the entire scene as a virtual screen, using only a scanning laser and an event camera. The resulting system achieves fast and motion-robust (14Hz) reconstructions of mixed reflectance scenes with < 500 $\mu$m accuracy. Moreover, we introduce a "superfast" capture mode (250Hz) for the 3D measurement of diffuse scenes.
Multisource Holography
Sep 19, 2023



Holographic displays promise several benefits including high quality 3D imagery, accurate accommodation cues, and compact form-factors. However, holography relies on coherent illumination which can create undesirable speckle noise in the final image. Although smooth phase holograms can be speckle-free, their non-uniform eyebox makes them impractical, and speckle mitigation with partially coherent sources also reduces resolution. Averaging sequential frames for speckle reduction requires high speed modulators and consumes temporal bandwidth that may be needed elsewhere in the system. In this work, we propose multisource holography, a novel architecture that uses an array of sources to suppress speckle in a single frame without sacrificing resolution. By using two spatial light modulators, arranged sequentially, each source in the array can be controlled almost independently to create a version of the target content with different speckle. Speckle is then suppressed when the contributions from the multiple sources are averaged at the image plane. We introduce an algorithm to calculate multisource holograms, analyze the design space, and demonstrate up to a 10 dB increase in peak signal-to-noise ratio compared to an equivalent single source system. Finally, we validate the concept with a benchtop experimental prototype by producing both 2D images and focal stacks with natural defocus cues.
Accurate Eye Tracking from Dense 3D Surface Reconstructions using Single-Shot Deflectometry
Aug 15, 2023



Eye-tracking plays a crucial role in the development of virtual reality devices, neuroscience research, and psychology. Despite its significance in numerous applications, achieving an accurate, robust, and fast eye-tracking solution remains a considerable challenge for current state-of-the-art methods. While existing reflection-based techniques (e.g., "glint tracking") are considered the most accurate, their performance is limited by their reliance on sparse 3D surface data acquired solely from the cornea surface. In this paper, we rethink the way how specular reflections can be used for eye tracking: We propose a novel method for accurate and fast evaluation of the gaze direction that exploits teachings from single-shot phase-measuring-deflectometry (PMD). In contrast to state-of-the-art reflection-based methods, our method acquires dense 3D surface information of both cornea and sclera within only one single camera frame (single-shot). Improvements in acquired reflection surface points("glints") of factors $>3300 \times$ are easily achievable. We show the feasibility of our approach with experimentally evaluated gaze errors of only $\leq 0.25^\circ$ demonstrating a significant improvement over the current state-of-the-art.
Stochastic Light Field Holography
Jul 12, 2023



The Visual Turing Test is the ultimate goal to evaluate the realism of holographic displays. Previous studies have focused on addressing challenges such as limited \'etendue and image quality over a large focal volume, but they have not investigated the effect of pupil sampling on the viewing experience in full 3D holograms. In this work, we tackle this problem with a novel hologram generation algorithm motivated by matching the projection operators of incoherent Light Field and coherent Wigner Function light transport. To this end, we supervise hologram computation using synthesized photographs, which are rendered on-the-fly using Light Field refocusing from stochastically sampled pupil states during optimization. The proposed method produces holograms with correct parallax and focus cues, which are important for passing the Visual Turing Test. We validate that our approach compares favorably to state-of-the-art CGH algorithms that use Light Field and Focal Stack supervision. Our experiments demonstrate that our algorithm significantly improves the realism of the viewing experience for a variety of different pupil states.
Thermal Spread Functions (TSF): Physics-guided Material Classification
Apr 03, 2023

Robust and non-destructive material classification is a challenging but crucial first-step in numerous vision applications. We propose a physics-guided material classification framework that relies on thermal properties of the object. Our key observation is that the rate of heating and cooling of an object depends on the unique intrinsic properties of the material, namely the emissivity and diffusivity. We leverage this observation by gently heating the objects in the scene with a low-power laser for a fixed duration and then turning it off, while a thermal camera captures measurements during the heating and cooling process. We then take this spatial and temporal "thermal spread function" (TSF) to solve an inverse heat equation using the finite-differences approach, resulting in a spatially varying estimate of diffusivity and emissivity. These tuples are then used to train a classifier that produces a fine-grained material label at each spatial pixel. Our approach is extremely simple requiring only a small light source (low power laser) and a thermal camera, and produces robust classification results with 86% accuracy over 16 classes.
Optimization-Based Eye Tracking using Deflectometric Information
Mar 09, 2023Eye tracking is an important tool with a wide range of applications in Virtual, Augmented, and Mixed Reality (VR/AR/MR) technologies. State-of-the-art eye tracking methods are either reflection-based and track reflections of sparse point light sources, or image-based and exploit 2D features of the acquired eye image. In this work, we attempt to significantly improve reflection-based methods by utilizing pixel-dense deflectometric surface measurements in combination with optimization-based inverse rendering algorithms. Utilizing the known geometry of our deflectometric setup, we develop a differentiable rendering pipeline based on PyTorch3D that simulates a virtual eye under screen illumination. Eventually, we exploit the image-screen-correspondence information from the captured measurements to find the eye's rotation, translation, and shape parameters with our renderer via gradient descent. In general, our method does not require a specific pattern and can work with ordinary video frames of the main VR/AR/MR screen itself. We demonstrate real-world experiments with evaluated mean relative gaze errors below 0.45 degrees at a precision better than 0.11 degrees. Moreover, we show an improvement of 6X over a representative reflection-based state-of-the-art method in simulation.