 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Phenotype Prediction using Long-Range Spatio-Temporal Dynamics of Functional Connectivity
Sep 07, 2021
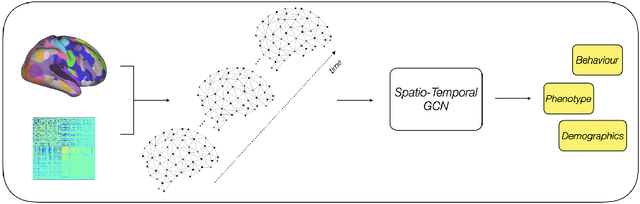
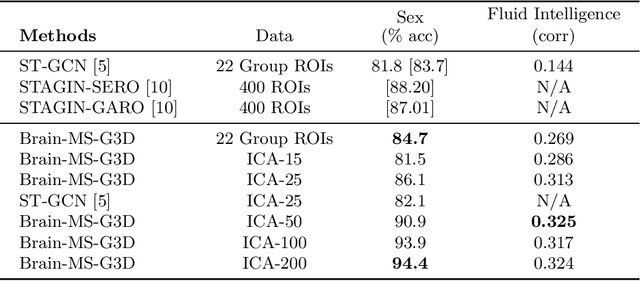
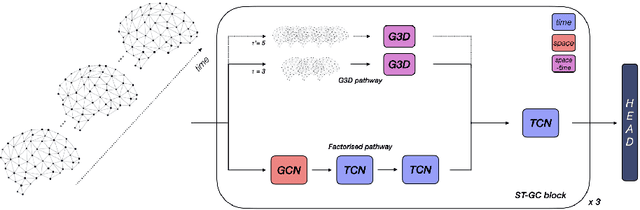
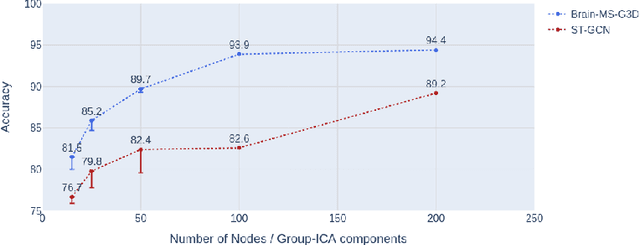
The study of functional brain connectivity (FC) is important for understanding the underlying mechanisms of many psychiatric disorders. Many recent analyses adopt graph convolutional networks, to study non-linear interactions between functionally-correlated states. However, although patterns of brain activation are known to be hierarchically organised in both space and time, many methods have failed to extract powerful spatio-temporal features. To overcome those challenges, and improve understanding of long-range functional dynamics, we translate an approach, from the domain of skeleton-based action recognition, designed to model interactions across space and time. We evaluate this approach using the Human Connectome Project (HCP) dataset on sex classification and fluid intelligence prediction. To account for subject topographic variability of functional organisation, we modelled functional connectomes using multi-resolution dual-regressed (subject-specific) ICA nodes. Results show a prediction accuracy of 94.4% for sex classification (an increase of 6.2% compared to other methods), and an improvement of correlation with fluid intelligence of 0.325 vs 0.144, relative to a baseline model that encodes space and time separately. Results suggest that explicit encoding of spatio-temporal dynamics of brain functional activity may improve the precision with which behavioural and cognitive phenotypes may be predicted in the future.
Improving Unsupervised Stain-To-Stain Translation using Self-Supervision and Meta-Learning
Dec 16, 2021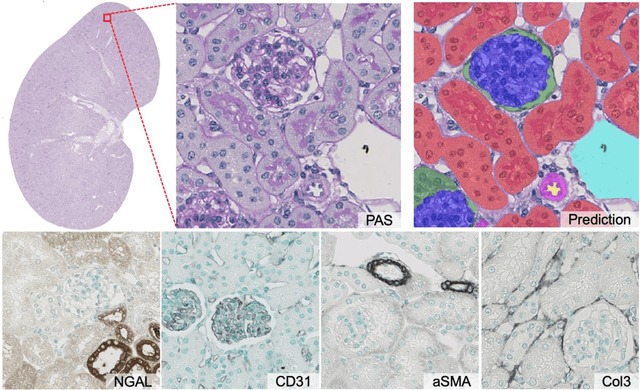

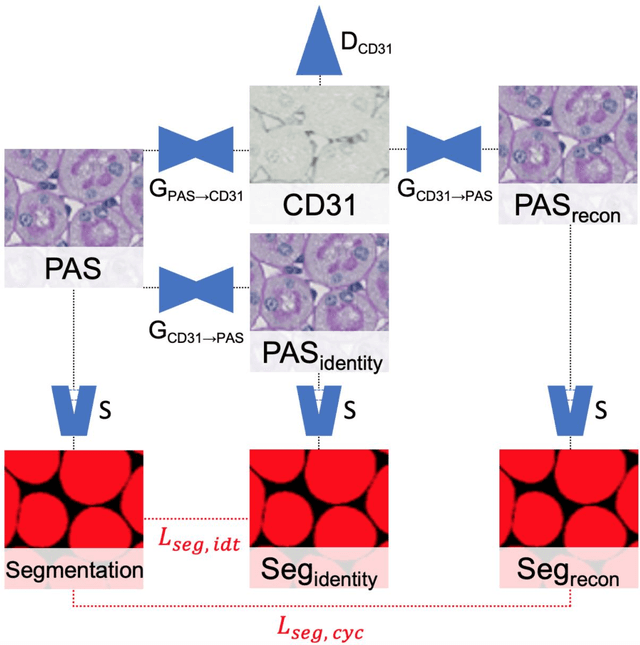
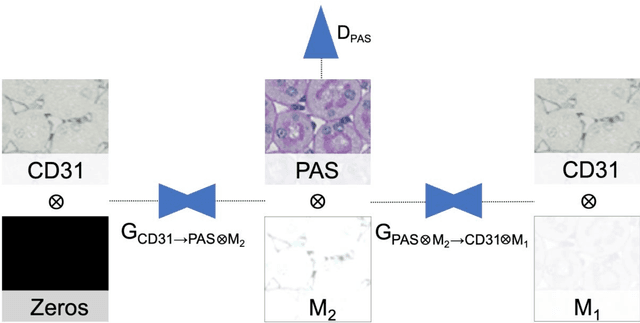
In digital pathology, many image analysis tasks are challenged by the need for large and time-consuming manual data annotations to cope with various sources of variability in the image domain. Unsupervised domain adaptation based on image-to-image translation is gaining importance in this field by addressing variabilities without the manual overhead. Here, we tackle the variation of different histological stains by unsupervised stain-to-stain translation to enable a stain-independent applicability of a deep learning segmentation model. We use CycleGANs for stain-to-stain translation in kidney histopathology, and propose two novel approaches to improve translational effectivity. First, we integrate a prior segmentation network into the CycleGAN for a self-supervised, application-oriented optimization of translation through semantic guidance, and second, we incorporate extra channels to the translation output to implicitly separate artificial meta-information otherwise encoded for tackling underdetermined reconstructions. The latter showed partially superior performances to the unmodified CycleGAN, but the former performed best in all stains providing instance-level Dice scores ranging between 78% and 92% for most kidney structures, such as glomeruli, tubules, and veins. However, CycleGANs showed only limited performance in the translation of other structures, e.g. arteries. Our study also found somewhat lower performance for all structures in all stains when compared to segmentation in the original stain. Our study suggests that with current unsupervised technologies, it seems unlikely to produce generally applicable fake stains.
Open-Domain, Content-based, Multi-modal Fact-checking of Out-of-Context Images via Online Resources
Dec 07, 2021
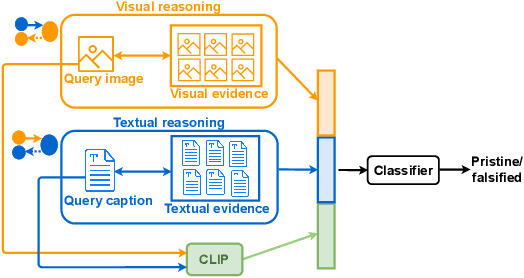
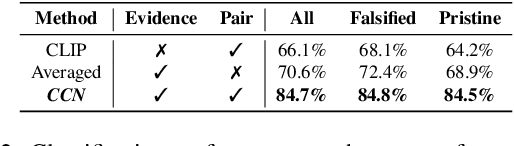
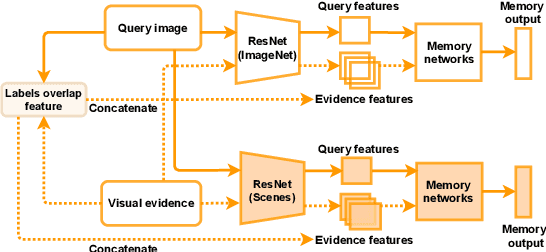
Misinformation is now a major problem due to its potential high risks to our core democratic and societal values and orders. Out-of-context misinformation is one of the easiest and effective ways used by adversaries to spread viral false stories. In this threat, a real image is re-purposed to support other narratives by misrepresenting its context and/or elements. The internet is being used as the go-to way to verify information using different sources and modalities. Our goal is an inspectable method that automates this time-consuming and reasoning-intensive process by fact-checking the image-caption pairing using Web evidence. To integrate evidence and cues from both modalities, we introduce the concept of 'multi-modal cycle-consistency check'; starting from the image/caption, we gather textual/visual evidence, which will be compared against the other paired caption/image, respectively. Moreover, we propose a novel architecture, Consistency-Checking Network (CCN), that mimics the layered human reasoning across the same and different modalities: the caption vs. textual evidence, the image vs. visual evidence, and the image vs. caption. Our work offers the first step and benchmark for open-domain, content-based, multi-modal fact-checking, and significantly outperforms previous baselines that did not leverage external evidence.
Maximum Entropy Model-based Reinforcement Learning
Dec 02, 2021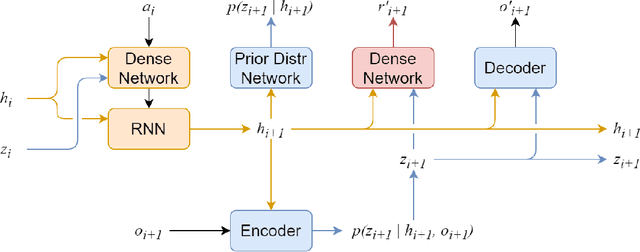
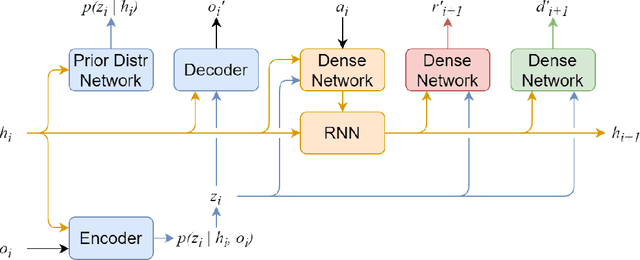
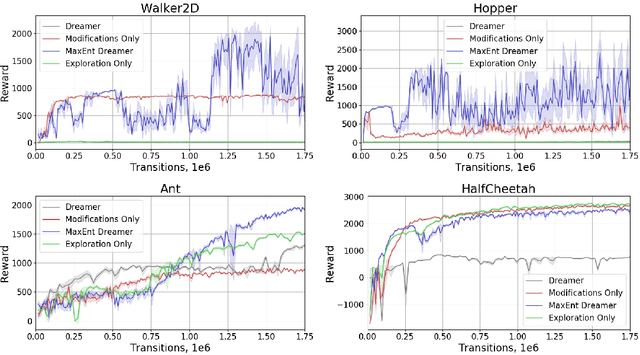
Recent advances in reinforcement learning have demonstrated its ability to solve hard agent-environment interaction tasks on a super-human level. However, the application of reinforcement learning methods to practical and real-world tasks is currently limited due to most RL state-of-art algorithms' sample inefficiency, i.e., the need for a vast number of training episodes. For example, OpenAI Five algorithm that has beaten human players in Dota 2 has trained for thousands of years of game time. Several approaches exist that tackle the issue of sample inefficiency, that either offers a more efficient usage of already gathered experience or aim to gain a more relevant and diverse experience via a better exploration of an environment. However, to our knowledge, no such approach exists for model-based algorithms, that showed their high sample efficiency in solving hard control tasks with high-dimensional state space. This work connects exploration techniques and model-based reinforcement learning. We have designed a novel exploration method that takes into account features of the model-based approach. We also demonstrate through experiments that our method significantly improves the performance of the model-based algorithm Dreamer.
Improving Sum-Rate of Cell-Free Massive MIMO with Expanded Compute-and-Forward
Nov 21, 2021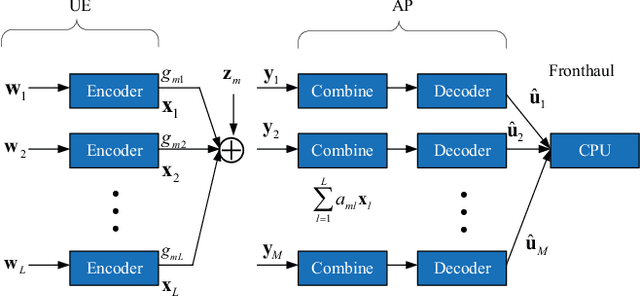

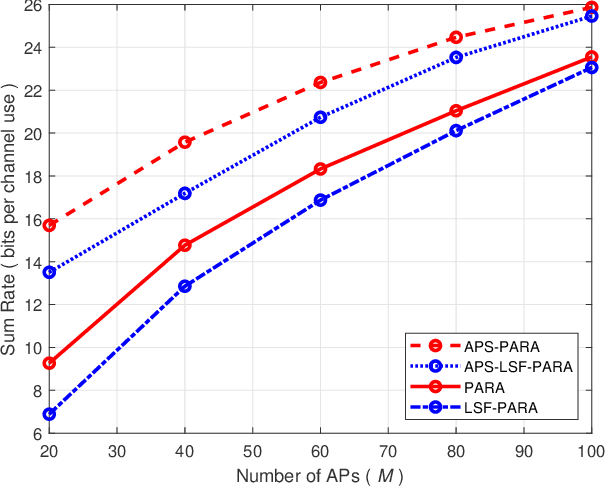
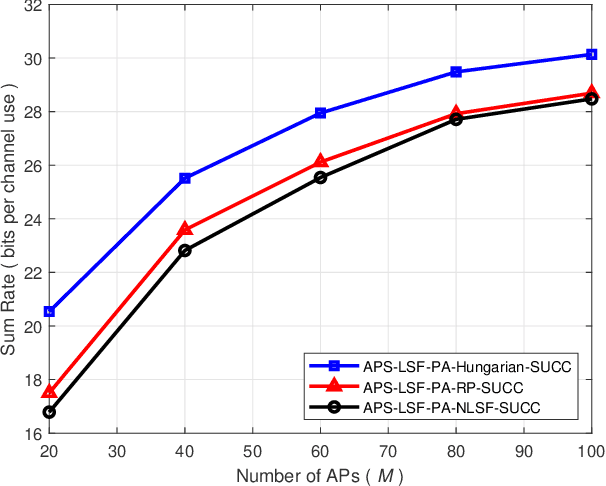
Cell-free massive multiple-input multiple-output (MIMO) employs a large number of distributed access points (APs) to serve a small number of user equipments (UEs) via the same time/frequency resource. Due to the strong macro diversity gain, cell-free massive MIMO can considerably improve the achievable sum-rate compared to conventional cellular massive MIMO. However, the performance of cell-free massive MIMO is upper limited by inter-user interference (IUI) when employing simple maximum ratio combining (MRC) at receivers. To harness IUI, the expanded compute-and-forward (ECF) framework is adopted. In particular, we propose power control algorithms for the parallel computation and successive computation in the ECF framework, respectively, to exploit the performance gain and then improve the system performance. Furthermore, we propose an AP selection scheme and the application of different decoding orders for the successive computation. Finally, numerical results demonstrate that ECF frameworks outperform the conventional CF and MRC frameworks in terms of achievable sum-rate.
Real-time Surgical Environment Enhancement for Robot-Assisted Minimally Invasive Surgery Based on Super-Resolution
Nov 08, 2020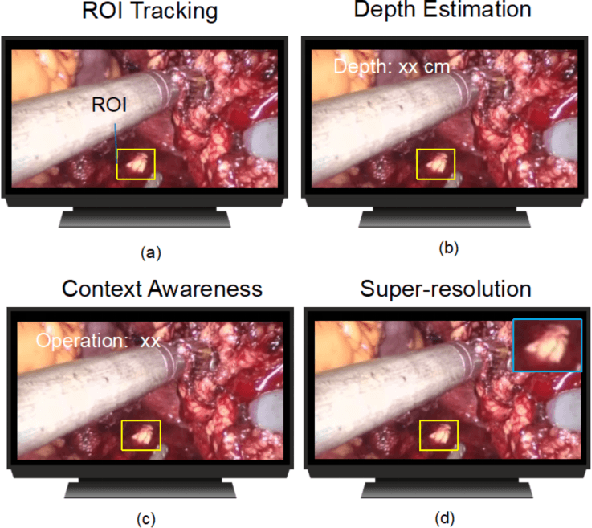
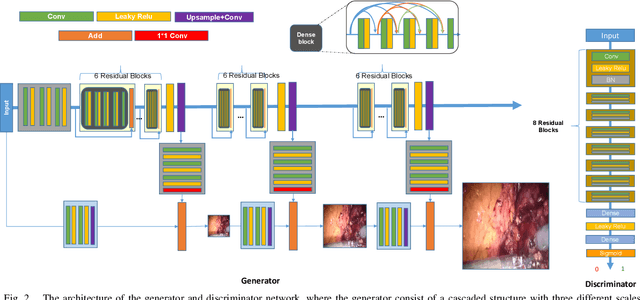
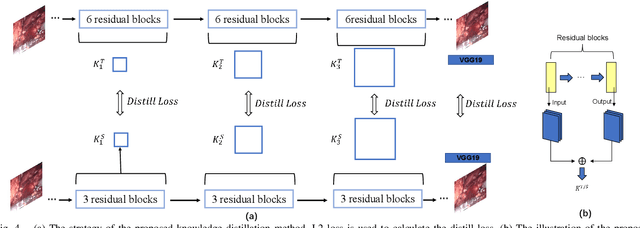
In Robot-Assisted Minimally Invasive Surgery (RAMIS), a camera assistant is normally required to control the position and zooming ratio of the laparoscope, following the surgeon's instructions. However, moving the laparoscope frequently may lead to unstable and suboptimal views, while the adjustment of zooming ratio may interrupt the workflow of the surgical operation. To this end, we propose a multi-scale Generative Adversarial Network (GAN)-based video super-resolution method to construct a framework for automatic zooming ratio adjustment. It can provide automatic real-time zooming for high-quality visualization of the Region Of Interest (ROI) during the surgical operation. In the pipeline of the framework, the Kernel Correlation Filter (KCF) tracker is used for tracking the tips of the surgical tools, while the Semi-Global Block Matching (SGBM) based depth estimation and Recurrent Neural Network (RNN)-based context-awareness are developed to determine the upscaling ratio for zooming. The framework is validated with the JIGSAW dataset and Hamlyn Centre Laparoscopic/Endoscopic Video Datasets, with results demonstrating its practicability.
Spatiotemporal Weather Data Predictions with Shortcut Recurrent-Convolutional Networks: A Solution for the Weather4cast challenge
Nov 03, 2021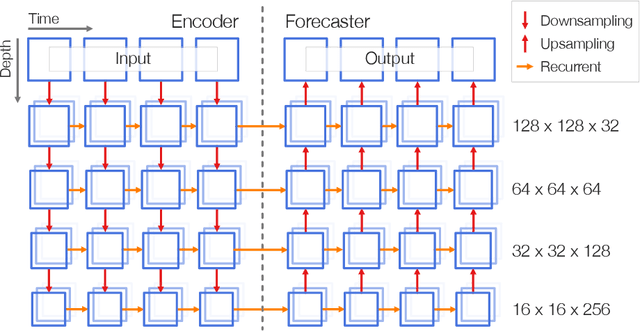
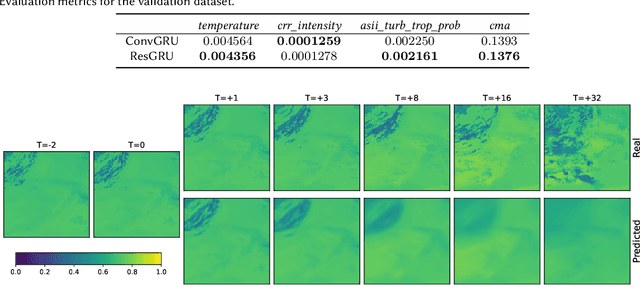
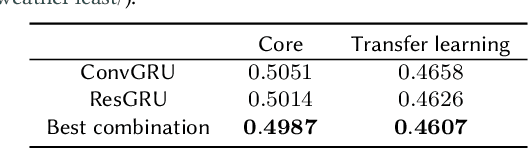

This paper presents the neural network model that was used by the author in the Weather4cast 2021 Challenge Stage 1, where the objective was to predict the time evolution of satellite-based weather data images. The network is based on an encoder-forecaster architecture making use of gated recurrent units (GRU), residual blocks and a contracting/expanding architecture with shortcuts similar to U-Net. A GRU variant utilizing residual blocks in place of convolutions is also introduced. Example predictions and evaluation metrics for the model are presented. These demonstrate that the model can retain sharp features of the input for the first predictions, while the later predictions become more blurred to reflect the increasing uncertainty.
Self-Supervised Dynamic Graph Representation Learning via Temporal Subgraph Contrast
Dec 16, 2021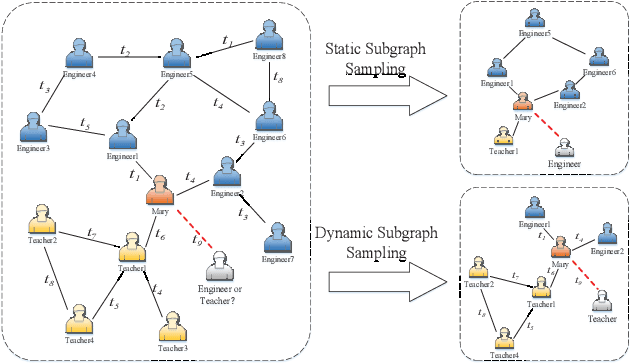
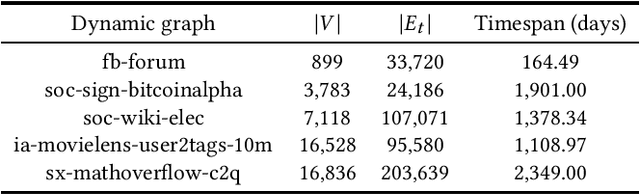
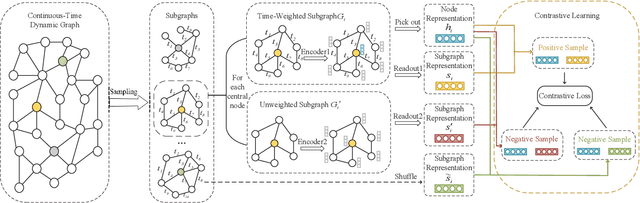
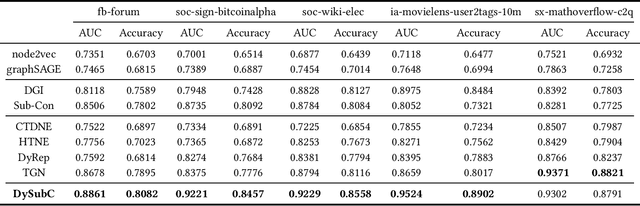
Self-supervised learning on graphs has recently drawn a lot of attention due to its independence from labels and its robustness in representation. Current studies on this topic mainly use static information such as graph structures but cannot well capture dynamic information such as timestamps of edges. Realistic graphs are often dynamic, which means the interaction between nodes occurs at a specific time. This paper proposes a self-supervised dynamic graph representation learning framework (DySubC), which defines a temporal subgraph contrastive learning task to simultaneously learn the structural and evolutional features of a dynamic graph. Specifically, a novel temporal subgraph sampling strategy is firstly proposed, which takes each node of the dynamic graph as the central node and uses both neighborhood structures and edge timestamps to sample the corresponding temporal subgraph. The subgraph representation function is then designed according to the influence of neighborhood nodes on the central node after encoding the nodes in each subgraph. Finally, the structural and temporal contrastive loss are defined to maximize the mutual information between node representation and temporal subgraph representation. Experiments on five real-world datasets demonstrate that (1) DySubC performs better than the related baselines including two graph contrastive learning models and four dynamic graph representation learning models in the downstream link prediction task, and (2) the use of temporal information can not only sample more effective subgraphs, but also learn better representation by temporal contrastive loss.
Classification of the Chess Endgame problem using Logistic Regression, Decision Trees, and Neural Networks
Nov 10, 2021
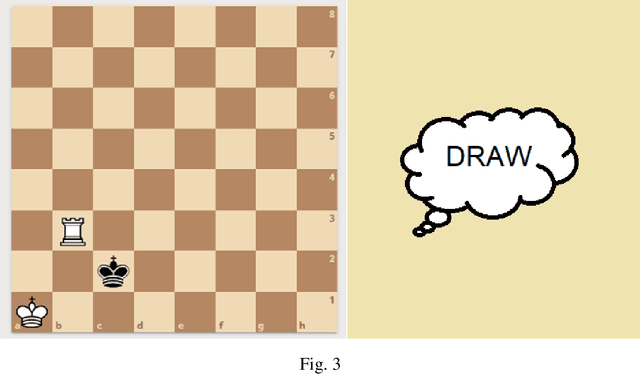
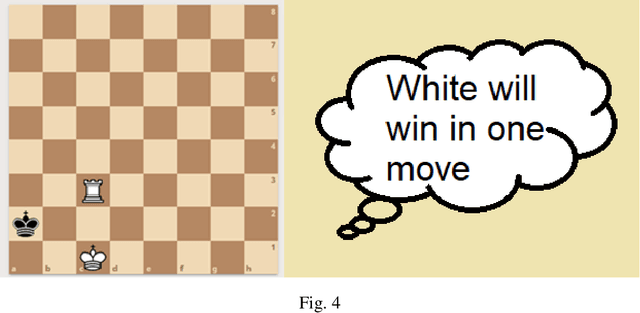
In this study we worked on the classification of the Chess Endgame problem using different algorithms like logistic regression, decision trees and neural networks. Our experiments indicates that the Neural Networks provides the best accuracy (85%) then the decision trees (79%). We did these experiments using Microsoft Azure Machine Learning as a case-study on using Visual Programming in classification. Our experiments demonstrates that this tool is powerful and save a lot of time, also it could be improved with more features that increase the usability and reduce the learning curve. We also developed an application for dataset visualization using a new programming language called Ring, our experiments demonstrates that this language have simple design like Python while integrates RAD tools like Visual Basic which is good for GUI development in the open-source world
DCAN: Improving Temporal Action Detection via Dual Context Aggregation
Dec 07, 2021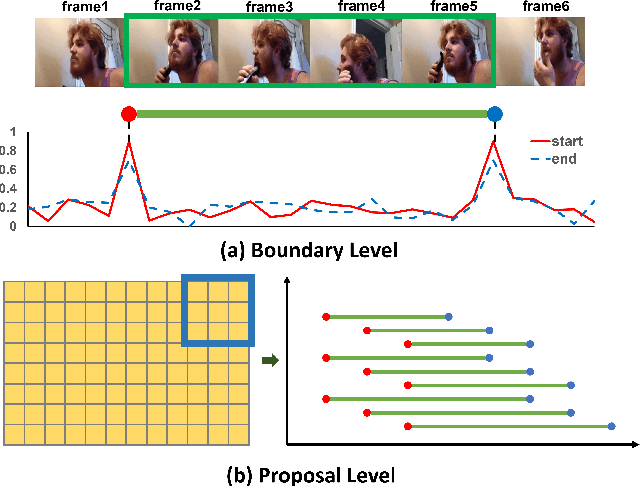
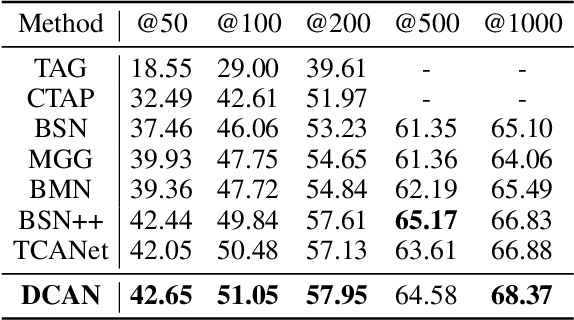
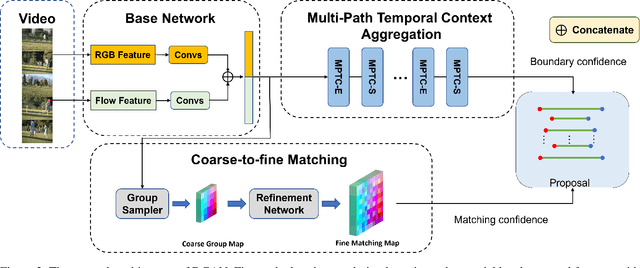
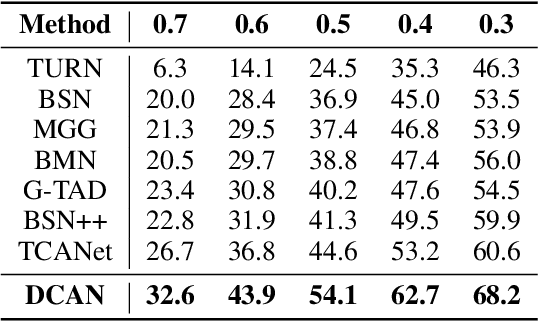
Temporal action detection aims to locate the boundaries of action in the video. The current method based on boundary matching enumerates and calculates all possible boundary matchings to generate proposals. However, these methods neglect the long-range context aggregation in boundary prediction. At the same time, due to the similar semantics of adjacent matchings, local semantic aggregation of densely-generated matchings cannot improve semantic richness and discrimination. In this paper, we propose the end-to-end proposal generation method named Dual Context Aggregation Network (DCAN) to aggregate context on two levels, namely, boundary level and proposal level, for generating high-quality action proposals, thereby improving the performance of temporal action detection. Specifically, we design the Multi-Path Temporal Context Aggregation (MTCA) to achieve smooth context aggregation on boundary level and precise evaluation of boundaries. For matching evaluation, Coarse-to-fine Matching (CFM) is designed to aggregate context on the proposal level and refine the matching map from coarse to fine. We conduct extensive experiments on ActivityNet v1.3 and THUMOS-14. DCAN obtains an average mAP of 35.39% on ActivityNet v1.3 and reaches mAP 54.14% at IoU@0.5 on THUMOS-14, which demonstrates DCAN can generate high-quality proposals and achieve state-of-the-art performance. We release the code at https://github.com/cg1177/DCAN.