 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommendations on test datasets for evaluating AI solutions in pathology
Apr 21, 2022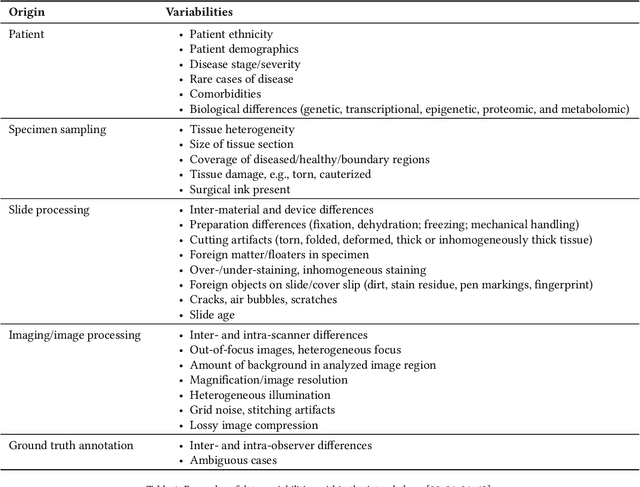

Artificial intelligence (AI) solutions that automatically extract information from digital histology images have shown great promise for improving pathological diagnosis. Prior to routine use, it is important to evaluate their predictive performance and obtain regulatory approval. This assessment requires appropriate test datasets. However, compiling such datasets is challenging and specific recommendations are missing. A committee of various stakeholders, including commercial AI developers, pathologists, and researchers, discussed key aspects and conducted extensive literature reviews on test datasets in pathology. Here, we summarize the results and derive general recommendations for the collection of test datasets. We address several questions: Which and how many images are needed? How to deal with low-prevalence subsets? How can potential bias be detected? How should datasets be reported? What are the regulatory requirements in different countries? The recommendations are intended to help AI developers demonstrate the utility of their products and to help regulatory agencies and end users verify reported performance measures. Further research is needed to formulate criteria for sufficiently representative test datasets so that AI solutions can operate with less user intervention and better support diagnostic workflows in the future.
Improving Unsupervised Stain-To-Stain Translation using Self-Supervision and Meta-Learning
Dec 16, 2021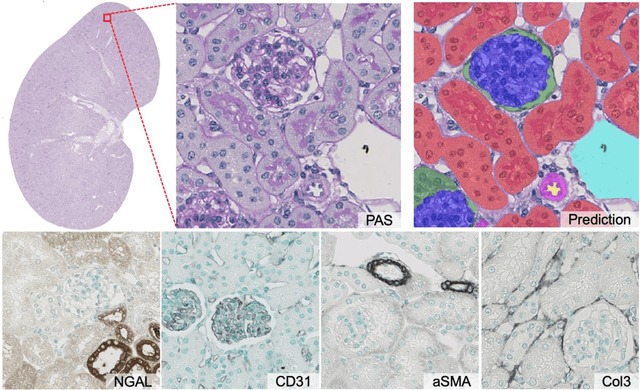

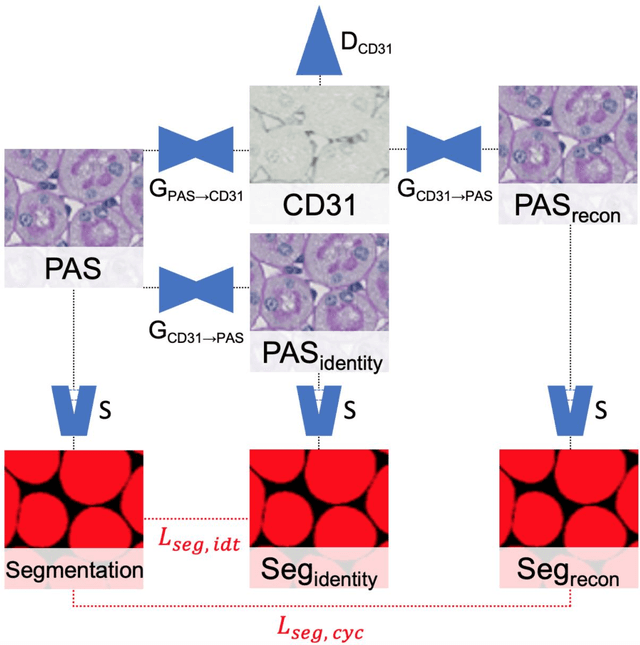
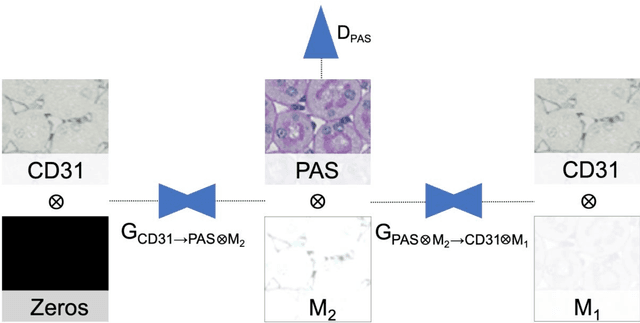
In digital pathology, many image analysis tasks are challenged by the need for large and time-consuming manual data annotations to cope with various sources of variability in the image domain. Unsupervised domain adaptation based on image-to-image translation is gaining importance in this field by addressing variabilities without the manual overhead. Here, we tackle the variation of different histological stains by unsupervised stain-to-stain translation to enable a stain-independent applicability of a deep learning segmentation model. We use CycleGANs for stain-to-stain translation in kidney histopathology, and propose two novel approaches to improve translational effectivity. First, we integrate a prior segmentation network into the CycleGAN for a self-supervised, application-oriented optimization of translation through semantic guidance, and second, we incorporate extra channels to the translation output to implicitly separate artificial meta-information otherwise encoded for tackling underdetermined reconstructions. The latter showed partially superior performances to the unmodified CycleGAN, but the former performed best in all stains providing instance-level Dice scores ranging between 78% and 92% for most kidney structures, such as glomeruli, tubules, and veins. However, CycleGANs showed only limited performance in the translation of other structures, e.g. arteries. Our study also found somewhat lower performance for all structures in all stains when compared to segmentation in the original stain. Our study suggests that with current unsupervised technologies, it seems unlikely to produce generally applicable fake stains.