 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Action Segmentation for Renorrhaphy in Robot-Assisted Partial Nephrectomy
Apr 10, 2026Fine-grained action segmentation during renorrhaphy in robot-assisted partial nephrectomy requires frame-level recognition of visually similar suturing gestures with variable duration and substantial class imbalance. The SIA-RAPN benchmark defines this problem on 50 clinical videos acquired with the da Vinci Xi system and annotated with 12 frame-level labels. The benchmark compares four temporal models built on I3D features: MS-TCN++, AsFormer, TUT, and DiffAct. Evaluation uses balanced accuracy, edit score, segmental F1 at overlap thresholds of 10, 25, and 50, frame-wise accuracy, and frame-wise mean average precision. In addition to the primary evaluation across five released split configurations on SIA-RAPN, the benchmark reports cross-domain results on a separate single-port RAPN dataset. Across the strongest reported values over those five runs on the primary dataset, DiffAct achieves the highest F1, frame-wise accuracy, edit score, and frame mAP, while MS-TCN++ attains the highest balanced accuracy.
120 Minutes and a Laptop: Minimalist Image-goal Navigation via Unsupervised Exploration and Offline RL
Mar 27, 2026The prevailing paradigm for image-goal visual navigation often assumes access to large-scale datasets, substantial pretraining, and significant computational resources. In this work, we challenge this assumption. We show that we can collect a dataset, train an in-domain policy, and deploy it to the real world (1) in less than 120 minutes, (2) on a consumer laptop, (3) without any human intervention. Our method, MINav, formulates image-goal navigation as an offline goal-conditioned reinforcement learning problem, combining unsupervised data collection with hindsight goal relabeling and offline policy learning. Experiments in simulation and the real world show that MINav improves exploration efficiency, outperforms zero-shot navigation baselines in target environments, and scales favorably with dataset size. These results suggest that effective real-world robotic learning can be achieved with high computational efficiency, lowering the barrier to rapid policy prototyping and deployment.
SignNav: Leveraging Signage for Semantic Visual Navigation in Large-Scale Indoor Environments
Mar 17, 2026Humans routinely leverage semantic hints provided by signage to navigate to destinations within novel Large-Scale Indoor (LSI) environments, such as hospitals and airport terminals. However, this capability remains underexplored within the field of embodied navigation. This paper introduces a novel embodied navigation task, SignNav, which requires the agent to interpret semantic hint from signage and reason about the subsequent action based on current observation. To facilitate research in this domain, we construct the LSI-Dataset for the training and evaluation of various SignNav agents. Dynamically changing semantic hints and sparse placement of signage in LSI environments present significant challenges to the SignNav task. To address these challenges, we propose the Spatial-Temporal Aware Transformer (START) model for end-to-end decision-making. The spatial-aware module grounds the semantic hint of signage into physical world, while the temporal-aware module captures long-range dependencies between historical states and current observation. Leveraging a two-stage training strategy with Dataset Aggregation (DAgger), our approach achieves state-of-the-art performance, recording an 80% Success Rate (SR) and 0.74 NDTW on val-unseen split. Real-world deployment further demonstrates the practicality of our method in physical environment without pre-built map.
RAP: Runtime-Adaptive Pruning for LLM Inference
May 26, 2025



Large language models (LLMs) excel at language understanding and generation, but their enormous computational and memory requirements hinder deployment. Compression offers a potential solution to mitigate these constraints. However, most existing methods rely on fixed heuristics and thus fail to adapt to runtime memory variations or heterogeneous KV-cache demands arising from diverse user requests. To address these limitations, we propose RAP, an elastic pruning framework driven by reinforcement learning (RL) that dynamically adjusts compression strategies in a runtime-aware manner. Specifically, RAP dynamically tracks the evolving ratio between model parameters and KV-cache across practical execution. Recognizing that FFNs house most parameters, whereas parameter -light attention layers dominate KV-cache formation, the RL agent retains only those components that maximize utility within the current memory budget, conditioned on instantaneous workload and device state. Extensive experiments results demonstrate that RAP outperforms state-of-the-art baselines, marking the first time to jointly consider model weights and KV-cache on the fly.
TacGNN:Learning Tactile-based In-hand Manipulation with a Blind Robot
Apr 03, 2023



In this paper, we propose a novel framework for tactile-based dexterous manipulation learning with a blind anthropomorphic robotic hand, i.e. without visual sensing. First, object-related states were extracted from the raw tactile signals by a graph-based perception model - TacGNN. The resulting tactile features were then utilized in the policy learning of an in-hand manipulation task in the second stage. This method was examined by a Baoding ball task - simultaneously manipulating two spheres around each other by 180 degrees in hand. We conducted experiments on object states prediction and in-hand manipulation using a reinforcement learning algorithm (PPO). Results show that TacGNN is effective in predicting object-related states during manipulation by decreasing the RMSE of prediction to 0.096cm comparing to other methods, such as MLP, CNN, and GCN. Finally, the robot hand could finish an in-hand manipulation task solely relying on the robotic own perception - tactile sensing and proprioception. In addition, our methods are tested on three tasks with different difficulty levels and transferred to the real robot without further training.
Accelerating Multi-Agent Planning Using Graph Transformers with Bounded Suboptimality
Jan 20, 2023



Conflict-Based Search is one of the most popular methods for multi-agent path finding. Though it is complete and optimal, it does not scale well. Recent works have been proposed to accelerate it by introducing various heuristics. However, whether these heuristics can apply to non-grid-based problem settings while maintaining their effectiveness remains an open question. In this work, we find that the answer is prone to be no. To this end, we propose a learning-based component, i.e., the Graph Transformer, as a heuristic function to accelerate the planning. The proposed method is provably complete and bounded-suboptimal with any desired factor. We conduct extensive experiments on two environments with dense graphs. Results show that the proposed Graph Transformer can be trained in problem instances with relatively few agents and generalizes well to a larger number of agents, while achieving better performance than state-of-the-art methods.
Learning to Navigate using Visual Sensor Networks
Aug 05, 2022
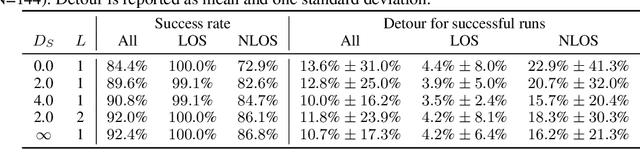
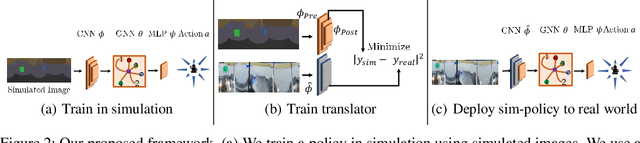
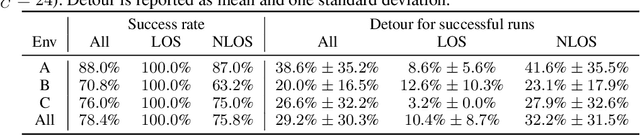
We consider the problem of navigating a mobile robot towards a target in an unknown environment that is endowed with visual sensors, where neither the robot nor the sensors have access to global positioning information and only use first-person-view images. While prior work in sensor network-based navigation uses explicit mapping and planning techniques, and is often aided by external positioning systems, we propose a vision-only based learning approach that leverages a Graph Neural Network (GNN) to encode and communicate relevant viewpoint information to the mobile robot. During navigation, the robot is guided by a model that we train through imitation learning to approximate optimal motion primitives, thereby predicting the effective cost-to-go (to the target). In our experiments, we first demonstrate generalizability to previously unseen environments with various sensor layouts. The results show that communication among the sensors and robot facilitates a significant improvement in success rate while decreasing path detour mean and variability. This is done without requiring a global map, positioning data, nor pre-calibration of the sensor network. Second, we perform a zero-shot transfer of our model from simulation to the real world. To this end, we train a`translator' model that translates between {latent encodings of} real and simulated images so that the navigation policy (which is trained entirely in simulation) can be used directly on the real robot, without additional fine-tuning. Physical experiments demonstrate the feasibility of our approach in various cluttered environments.
A Framework for Real-World Multi-Robot Systems Running Decentralized GNN-Based Policies
Nov 02, 2021
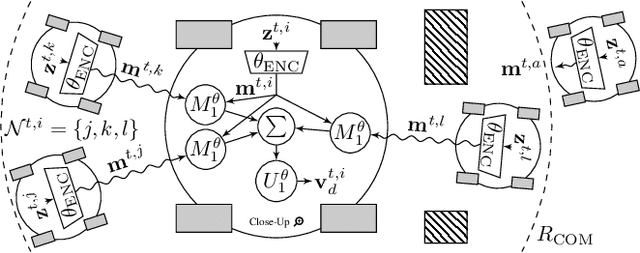
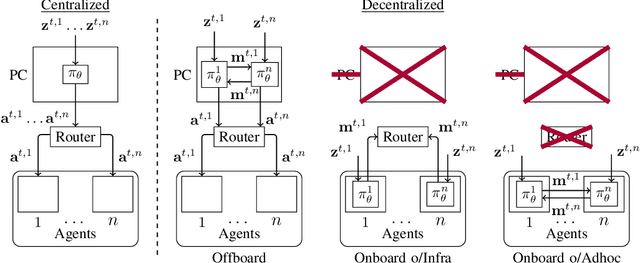
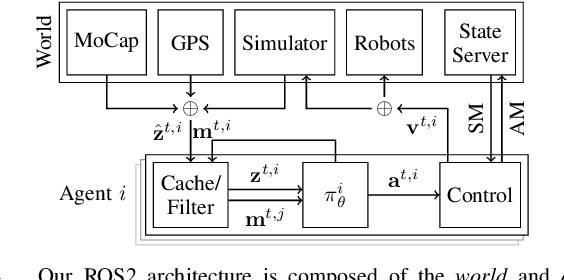
Graph Neural Networks (GNNs) are a paradigm-shifting neural architecture to facilitate the learning of complex multi-agent behaviors. Recent work has demonstrated remarkable performance in tasks such as flocking, multi-agent path planning and cooperative coverage. However, the policies derived through GNN-based learning schemes have not yet been deployed to the real-world on physical multi-robot systems. In this work, we present the design of a system that allows for fully decentralized execution of GNN-based policies. We create a framework based on ROS2 and elaborate its details in this paper. We demonstrate our framework on a case-study that requires tight coordination between robots, and present first-of-a-kind results that show successful real-world deployment of GNN-based policies on a decentralized multi-robot system relying on Adhoc communication. A video demonstration of this case-study can be found online. https://www.youtube.com/watch?v=COh-WLn4iO4
Graph Neural Network Guided Local Search for the Traveling Salesperson Problem
Oct 12, 2021
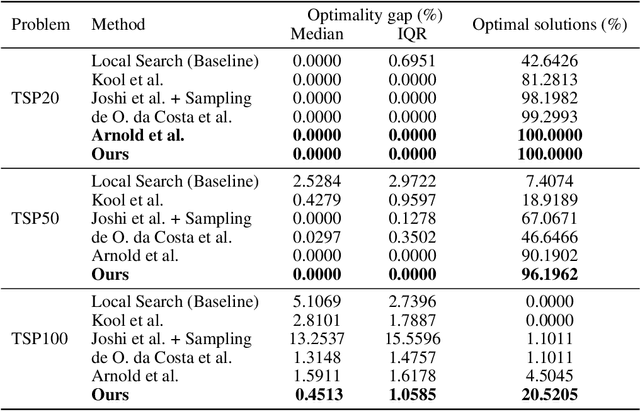

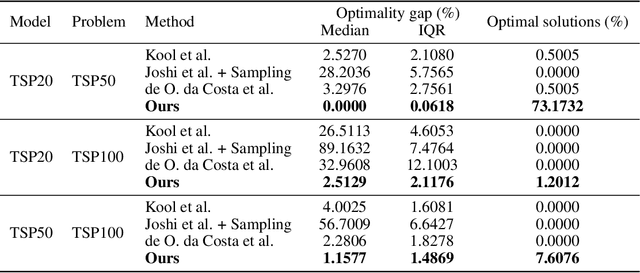
Solutions to the Traveling Salesperson Problem (TSP) have practical applications to processes in transportation, logistics, and automation, yet must be computed with minimal delay to satisfy the real-time nature of the underlying tasks. However, solving large TSP instances quickly without sacrificing solution quality remains challenging for current approximate algorithms. To close this gap, we present a hybrid data-driven approach for solving the TSP based on Graph Neural Networks (GNNs) and Guided Local Search (GLS). Our model predicts the regret of including each edge of the problem graph in the solution; GLS uses these predictions in conjunction with the original problem graph to find solutions. Our experiments demonstrate that this approach converges to optimal solutions at a faster rate than state-of-the-art learning-based approaches and non-learning GLS algorithms for the TSP, notably finding optimal solutions to 96% of the 50-node problem set, 7% more than the next best benchmark, and to 20% of the 100-node problem set, 4.5x more than the next best benchmark. When generalizing from 20-node problems to the 100-node problem set, our approach finds solutions with an average optimality gap of 2.5%, a 10x improvement over the next best learning-based benchmark.
The Holy Grail of Multi-Robot Planning: Learning to Generate Online-Scalable Solutions from Offline-Optimal Experts
Jul 26, 2021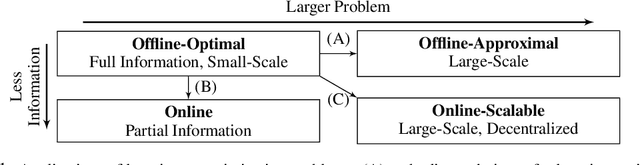
Many multi-robot planning problems are burdened by the curse of dimensionality, which compounds the difficulty of applying solutions to large-scale problem instances. The use of learning-based methods in multi-robot planning holds great promise as it enables us to offload the online computational burden of expensive, yet optimal solvers, to an offline learning procedure. Simply put, the idea is to train a policy to copy an optimal pattern generated by a small-scale system, and then transfer that policy to much larger systems, in the hope that the learned strategy scales, while maintaining near-optimal performance. Yet, a number of issues impede us from leveraging this idea to its full potential. This blue-sky paper elaborates some of the key challenges that remain.