 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DNN-based Policies for Stochastic AC OPF
Dec 04, 2021
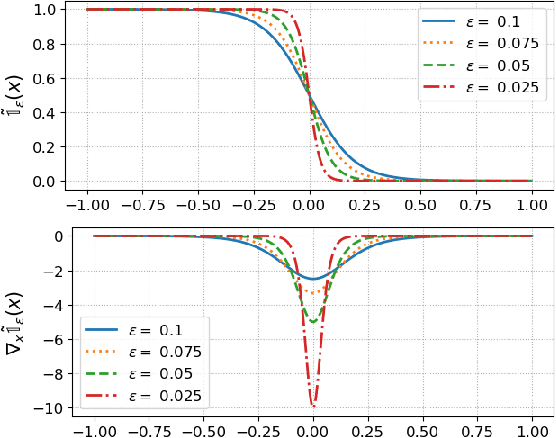
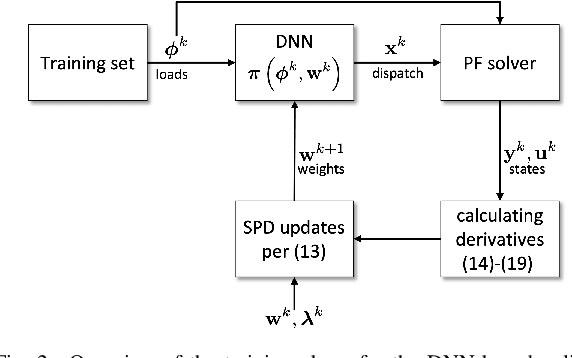
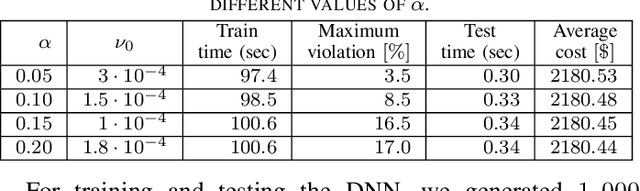

A prominent challenge to the safe and optimal operation of the modern power grid arises due to growing uncertainties in loads and renewables. Stochastic optimal power flow (SOPF) formulations provide a mechanism to handle these uncertainties by computing dispatch decisions and control policies that maintain feasibility under uncertainty. Most SOPF formulations consider simple control policies such as affine policies that are mathematically simple and resemble many policies used in current practice. Motivated by the efficacy of machine learning (ML) algorithms and the potential benefits of general control policies for cost and constraint enforcement, we put forth a deep neural network (DNN)-based policy that predicts the generator dispatch decisions in real time in response to uncertainty. The weights of the DNN are learnt using stochastic primal-dual updates that solve the SOPF without the need for prior generation of training labels and can explicitly account for the feasibility constraints in the SOPF. The advantages of the DNN policy over simpler policies and their efficacy in enforcing safety limits and producing near optimal solutions are demonstrated in the context of a chance constrained formulation on a number of test cases.
Safe Driving via Expert Guided Policy Optimization
Oct 13, 2021
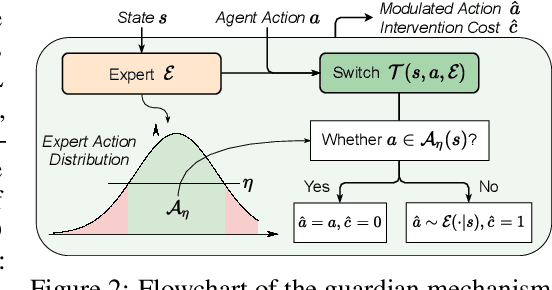
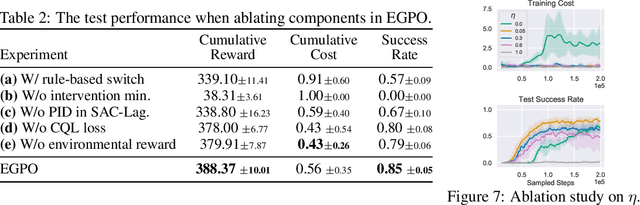

When learning common skills like driving, beginners usually have domain experts standing by to ensure the safety of the learning process. We formulate such learning scheme under the Expert-in-the-loop Reinforcement Learning where a guardian is introduced to safeguard the exploration of the learning agent. While allowing the sufficient exploration in the uncertain environment, the guardian intervenes under dangerous situations and demonstrates the correct actions to avoid potential accidents. Thus ERL enables both exploration and expert's partial demonstration as two training sources. Following such a setting, we develop a novel Expert Guided Policy Optimization (EGPO) method which integrates the guardian in the loop of reinforcement learning. The guardian is composed of an expert policy to generate demonstration and a switch function to decide when to intervene. Particularly, a constrained optimization technique is used to tackle the trivial solution that the agent deliberately behaves dangerously to deceive the expert into taking over. Offline RL technique is further used to learn from the partial demonstration generated by the expert. Safe driving experiments show that our method achieves superior training and test-time safety, outperforms baselines with a substantial margin in sample efficiency, and preserves the generalizabiliy to unseen environments in test-time. Demo video and source code are available at: https://decisionforce.github.io/EGPO/
Securing your Airspace: Detection of Drones Trespassing Protected Areas
Nov 05, 2021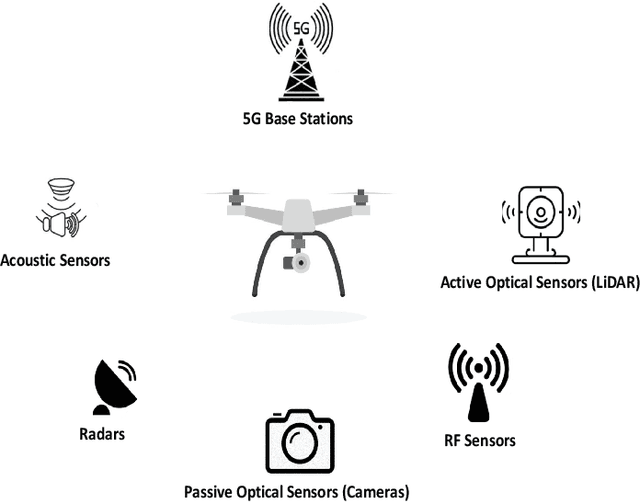
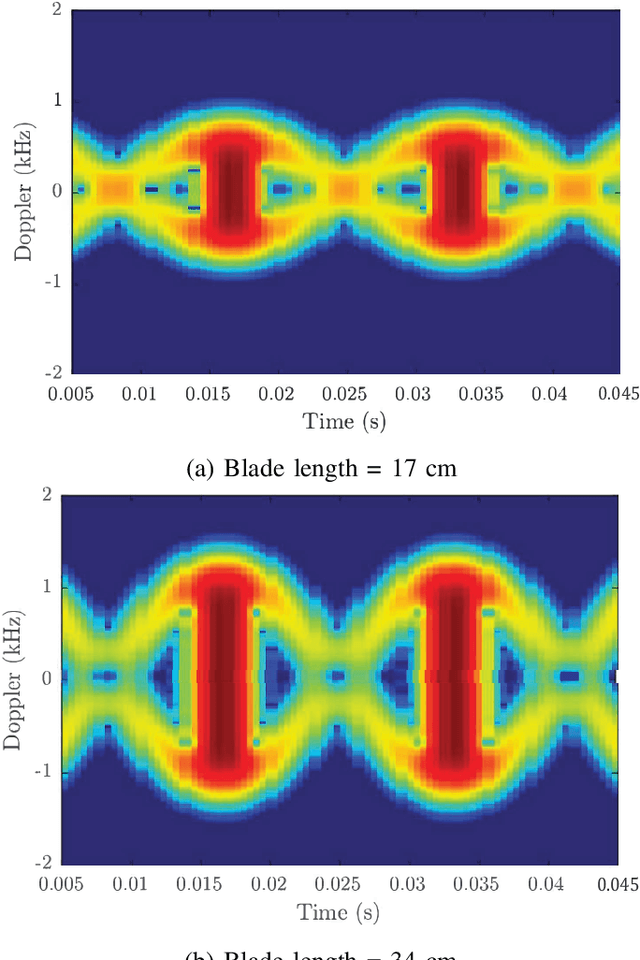
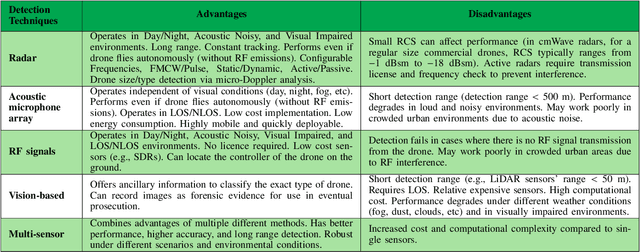
There has been a rapid growth in the deployment of Unmanned Aerial Vehicles (UAVs) in various applications ranging from vital safety-of-life such as surveillance and reconnaissance at nuclear power plants to entertainment and hobby applications. While popular, drones can pose serious security threats that can be unintentional or intentional. Thus, there is an urgent need for real-time accurate detection and classification of drones. In this article, we perform a survey of drone detection approaches presenting their advantages and limitations. We analyze detection techniques that employ radars, acoustic and optical sensors, and emitted radio frequency (RF) signals. We compare their performance, accuracy, and cost, concluding that combining multiple sensing modalities might be the path forward.
Conditional Inference and Activation of Knowledge Entities in ACT-R
Oct 28, 2021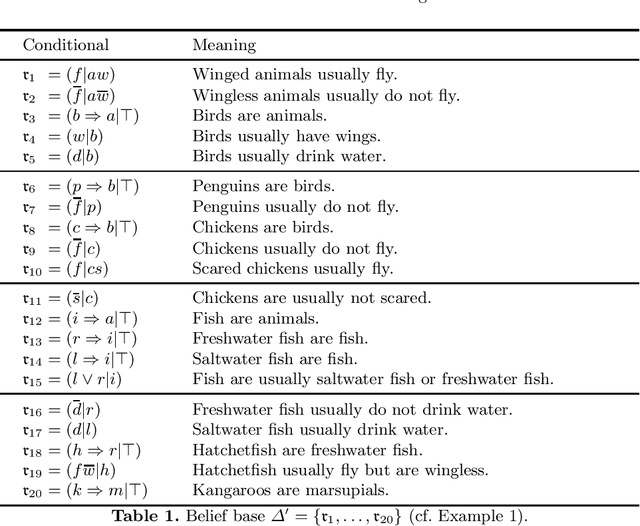
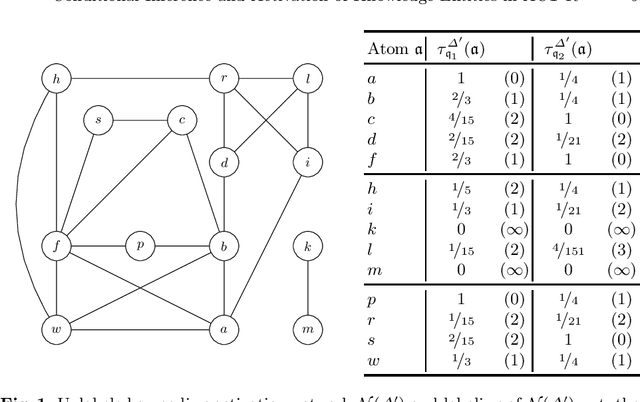
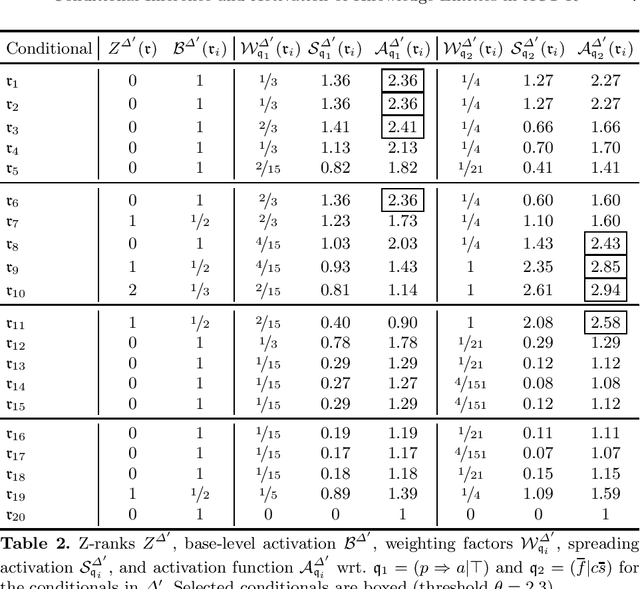

Activation-based conditional inference applies conditional reasoning to ACT-R, a cognitive architecture developed to formalize human reasoning. The idea of activation-based conditional inference is to determine a reasonable subset of a conditional belief base in order to draw inductive inferences in time. Central to activation-based conditional inference is the activation function which assigns to the conditionals in the belief base a degree of activation mainly based on the conditional's relevance for the current query and its usage history. Therewith, our approach integrates several aspects of human reasoning into expert systems such as focusing, forgetting, and remembering.
TRACER: Extreme Attention Guided Salient Object Tracing Network
Dec 14, 2021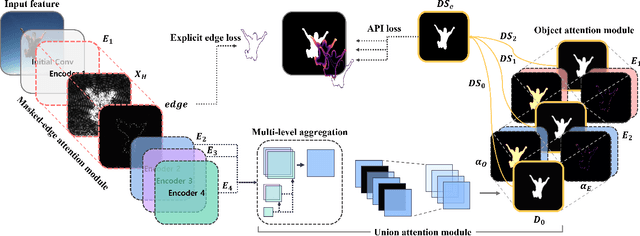
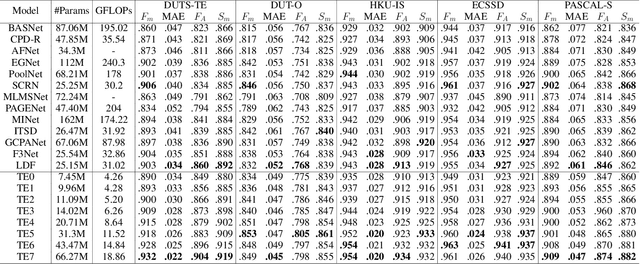


Existing studies on salient object detection (SOD) focus on extracting distinct objects with edge information and aggregating multi-level features to improve SOD performance. To achieve satisfactory performance, the methods employ refined edge information and low multi-level discrepancy. However, both performance gain and computational efficiency cannot be attained, which has motivated us to study the inefficiencies in existing encoder-decoder structures to avoid this trade-off. We propose TRACER, which detects salient objects with explicit edges by incorporating attention guided tracing modules. We employ a masked edge attention module at the end of the first encoder using a fast Fourier transform to propagate the refined edge information to the downstream feature extraction. In the multi-level aggregation phase, the union attention module identifies the complementary channel and important spatial information. To improve the decoder performance and computational efficiency, we minimize the decoder block usage with object attention module. This module extracts undetected objects and edge information from refined channels and spatial representations. Subsequently, we propose an adaptive pixel intensity loss function to deal with the relatively important pixels unlike conventional loss functions which treat all pixels equally. A comparison with 13 existing methods reveals that TRACER achieves state-of-the-art performance on five benchmark datasets. In particular, TRACER-Efficient3 (TE3) outperforms LDF, an existing method while requiring 1.8x fewer learning parameters and less time; TE3 is 5x faster.
Novel Dual-Channel Long Short-Term Memory Compressed Capsule Networks for Emotion Recognition
Dec 26, 2021
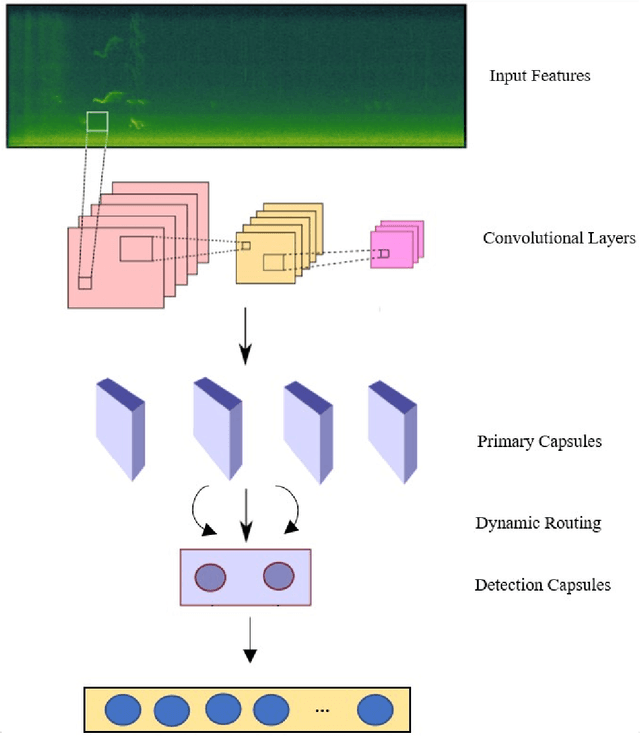
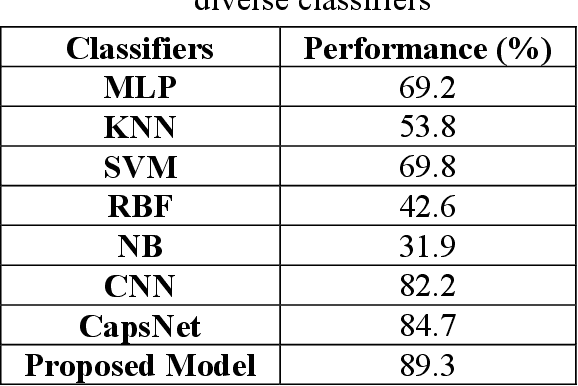
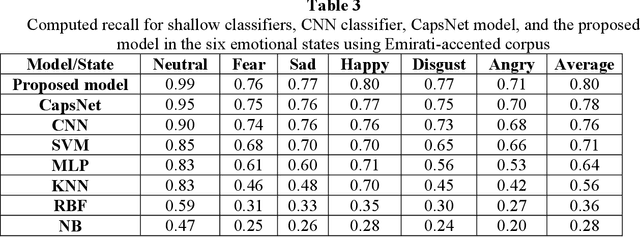
Recent analysis on speech emotion recognition has made considerable advances with the use of MFCCs spectrogram features and the implementation of neural network approaches such as convolutional neural networks (CNNs). Capsule networks (CapsNet) have gained gratitude as alternatives to CNNs with their larger capacities for hierarchical representation. To address these issues, this research introduces a text-independent and speaker-independent SER novel architecture, where a dual-channel long short-term memory compressed-CapsNet (DC-LSTM COMP-CapsNet) algorithm is proposed based on the structural features of CapsNet. Our proposed novel classifier can ensure the energy efficiency of the model and adequate compression method in speech emotion recognition, which is not delivered through the original structure of a CapsNet. Moreover, the grid search approach is used to attain optimal solutions. Results witnessed an improved performance and reduction in the training and testing running time. The speech datasets used to evaluate our algorithm are: Arabic Emirati-accented corpus, English speech under simulated and actual stress corpus, English Ryerson audio-visual database of emotional speech and song corpus, and crowd-sourced emotional multimodal actors dataset. This work reveals that the optimum feature extraction method compared to other known methods is MFCCs delta-delta. Using the four datasets and the MFCCs delta-delta, DC-LSTM COMP-CapsNet surpasses all the state-of-the-art systems, classical classifiers, CNN, and the original CapsNet. Using the Arabic Emirati-accented corpus, our results demonstrate that the proposed work yields average emotion recognition accuracy of 89.3% compared to 84.7%, 82.2%, 69.8%, 69.2%, 53.8%, 42.6%, and 31.9% based on CapsNet, CNN, support vector machine, multi-layer perceptron, k-nearest neighbor, radial basis function, and naive Bayes, respectively.
* 19 pages, 11 figures
DeepAoANet: Learning Angle of Arrival from Software Defined Radios with Deep Neural Networks
Dec 09, 2021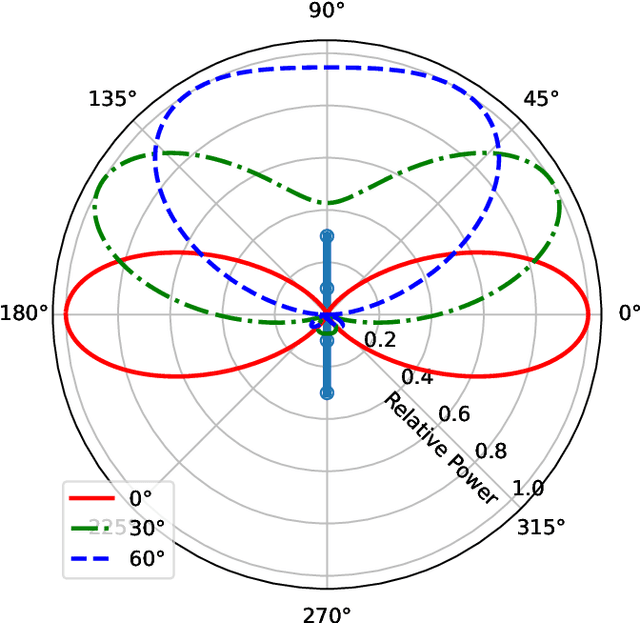
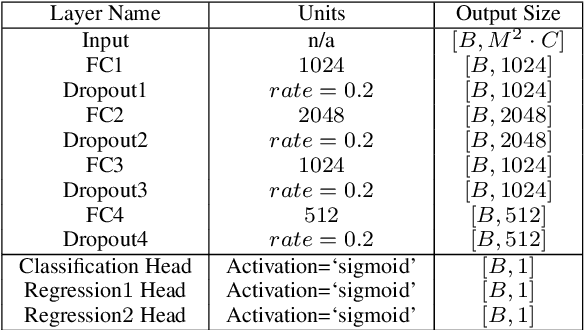
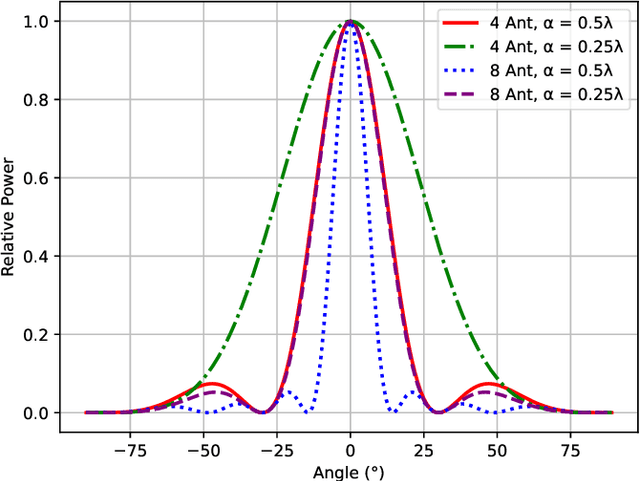
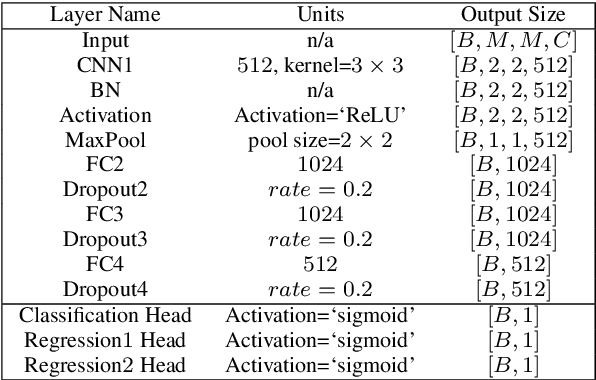
Direction finding and positioning systems based on RF signals are significantly impacted by multipath propagation, particularly in indoor environments. Existing algorithms (e.g MUSIC) perform poorly in resolving Angle of Arrival (AoA) in the presence of multipath or when operating in a weak signal regime. We note that digitally sampled RF frontends allow for the easy analysis of signals, and their delayed components. Low-cost Software-Defined Radio (SDR) modules enable Channel State Information (CSI) extraction across a wide spectrum, motivating the design of an enhanced Angle-of-Arrival (AoA) solution. We propose a Deep Learning approach to deriving AoA from a single snapshot of the SDR multichannel data. We compare and contrast deep-learning based angle classification and regression models, to estimate up to two AoAs accurately. We have implemented the inference engines on different platforms to extract AoAs in real-time, demonstrating the computational tractability of our approach. To demonstrate the utility of our approach we have collected IQ (In-phase and Quadrature components) samples from a four-element Universal Linear Array (ULA) in various Light-of-Sight (LOS) and Non-Line-of-Sight (NLOS) environments, and published the dataset. Our proposed method demonstrates excellent reliability in determining number of impinging signals and realized mean absolute AoA errors less than $2^{\circ}$.
Active Visuo-Tactile Point Cloud Registration for Accurate Pose Estimation of Objects in an Unknown Workspace
Aug 09, 2021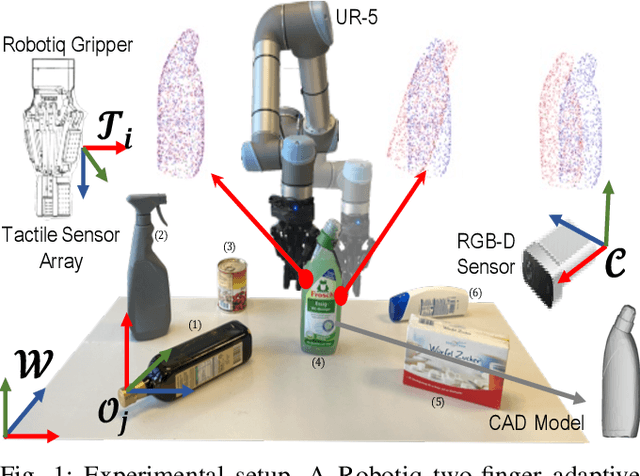
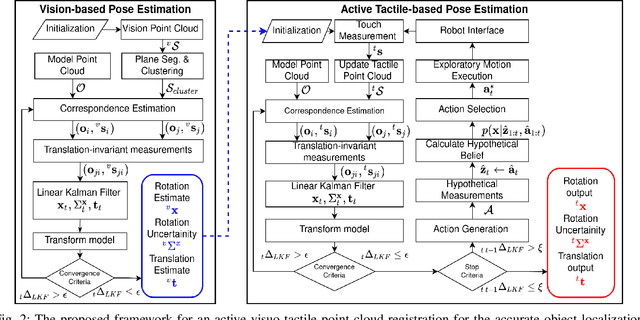
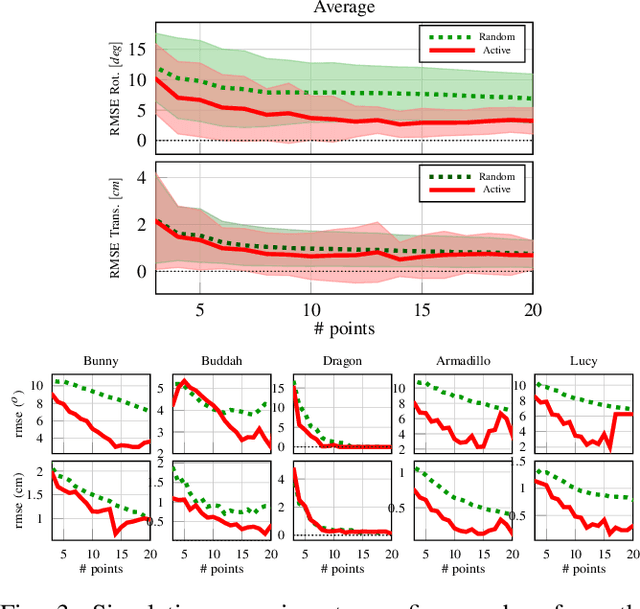
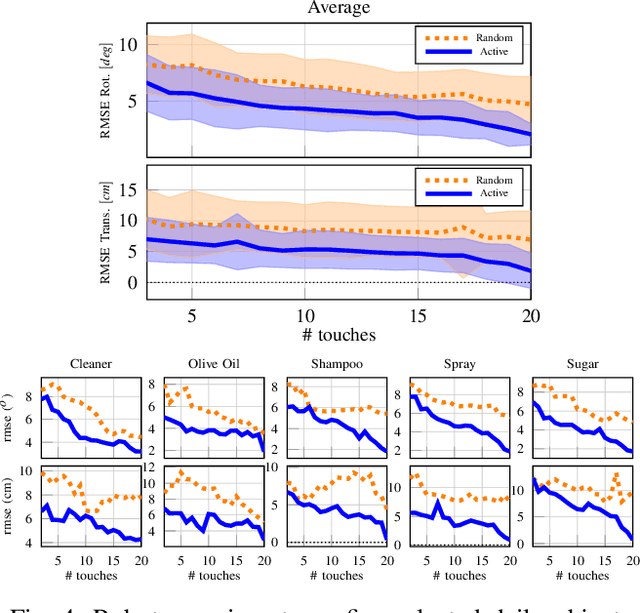
This paper proposes a novel active visuo-tactile based methodology wherein the accurate estimation of the time-invariant SE(3) pose of objects is considered for autonomous robotic manipulators. The robot equipped with tactile sensors on the gripper is guided by a vision estimate to actively explore and localize the objects in the unknown workspace. The robot is capable of reasoning over multiple potential actions, and execute the action to maximize information gain to update the current belief of the object. We formulate the pose estimation process as a linear translation invariant quaternion filter (TIQF) by decoupling the estimation of translation and rotation and formulating the update and measurement model in linear form. We perform pose estimation sequentially on acquired measurements using very sparse point cloud as acquiring each measurement using tactile sensing is time consuming. Furthermore, our proposed method is computationally efficient to perform an exhaustive uncertainty-based active touch selection strategy in real-time without the need for trading information gain with execution time. We evaluated the performance of our approach extensively in simulation and by a robotic system.
Spatio-temporal Relation Modeling for Few-shot Action Recognition
Dec 09, 2021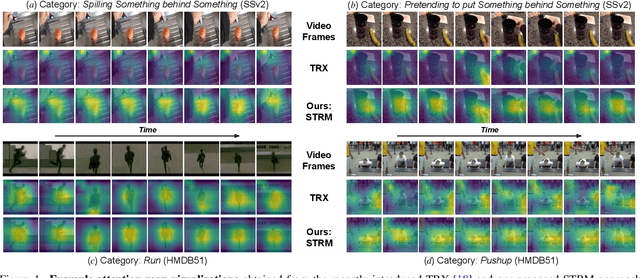
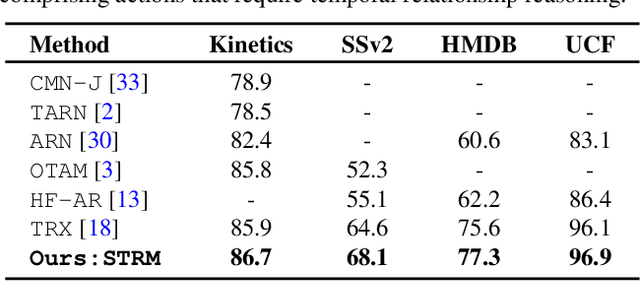
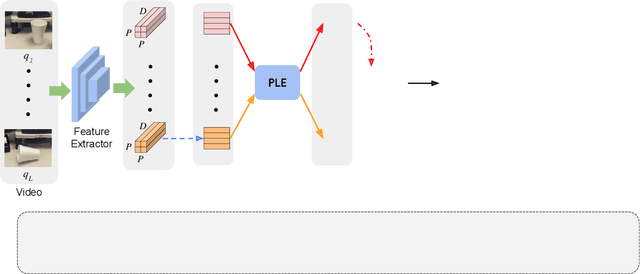
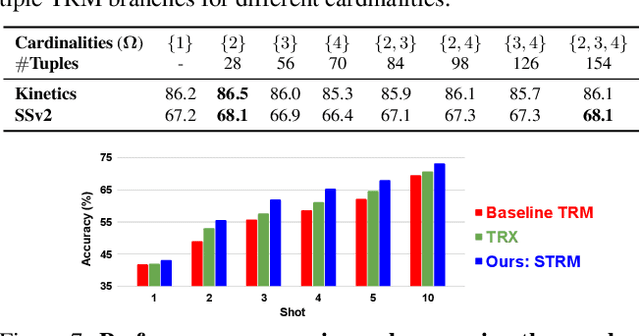
We propose a novel few-shot action recognition framework, STRM, which enhances class-specific feature discriminability while simultaneously learning higher-order temporal representations. The focus of our approach is a novel spatio-temporal enrichment module that aggregates spatial and temporal contexts with dedicated local patch-level and global frame-level feature enrichment sub-modules. Local patch-level enrichment captures the appearance-based characteristics of actions. On the other hand, global frame-level enrichment explicitly encodes the broad temporal context, thereby capturing the relevant object features over time. The resulting spatio-temporally enriched representations are then utilized to learn the relational matching between query and support action sub-sequences. We further introduce a query-class similarity classifier on the patch-level enriched features to enhance class-specific feature discriminability by reinforcing the feature learning at different stages in the proposed framework. Experiments are performed on four few-shot action recognition benchmarks: Kinetics, SSv2, HMDB51 and UCF101. Our extensive ablation study reveals the benefits of the proposed contributions. Furthermore, our approach sets a new state-of-the-art on all four benchmarks. On the challenging SSv2 benchmark, our approach achieves an absolute gain of 3.5% in classification accuracy, as compared to the best existing method in the literature. Our code and models will be publicly released.
Physics-informed Evolutionary Strategy based Control for Mitigating Delayed Voltage Recovery
Nov 29, 2021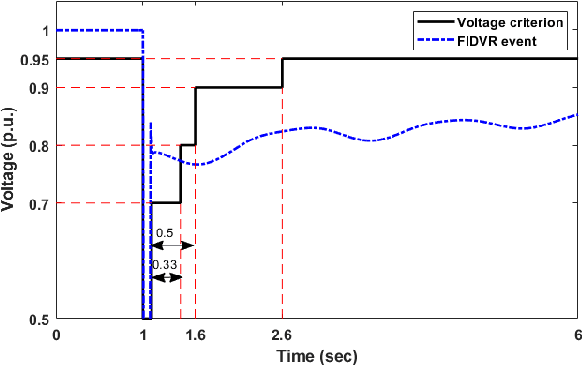
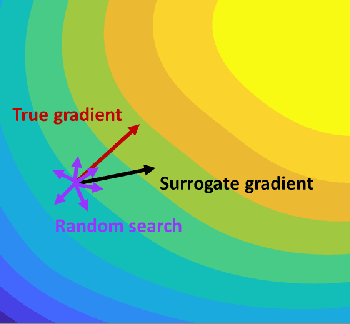
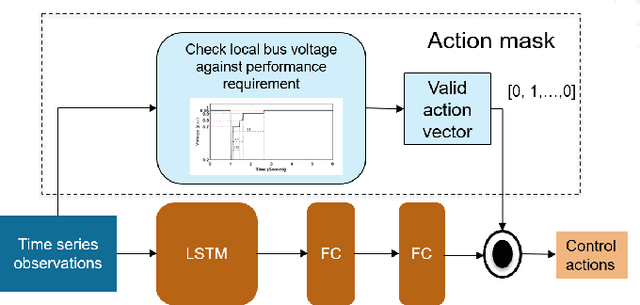
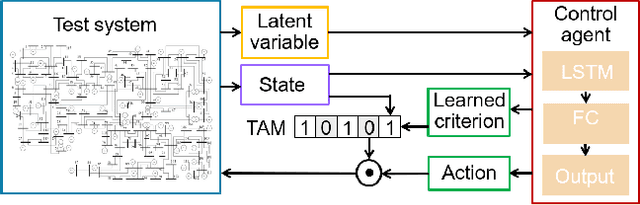
In this work we propose a novel data-driven, real-time power system voltage control method based on the physics-informed guided meta evolutionary strategy (ES). The main objective is to quickly provide an adaptive control strategy to mitigate the fault-induced delayed voltage recovery (FIDVR) problem. Reinforcement learning methods have been developed for the same or similar challenging control problems, but they suffer from training inefficiency and lack of robustness for "corner or unseen" scenarios. On the other hand, extensive physical knowledge has been developed in power systems but little has been leveraged in learning-based approaches. To address these challenges, we introduce the trainable action mask technique for flexibly embedding physical knowledge into RL models to rule out unnecessary or unfavorable actions, and achieve notable improvements in sample efficiency, control performance and robustness. Furthermore, our method leverages past learning experience to derive surrogate gradient to guide and accelerate the exploration process in training. Case studies on the IEEE 300-bus system and comparisons with other state-of-the-art benchmark methods demonstrate effectiveness and advantages of our method.