 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaIA: Graphical Information Gain based Attention Network for Weakly Supervised Point Cloud Semantic Segmentation
Oct 02, 2022
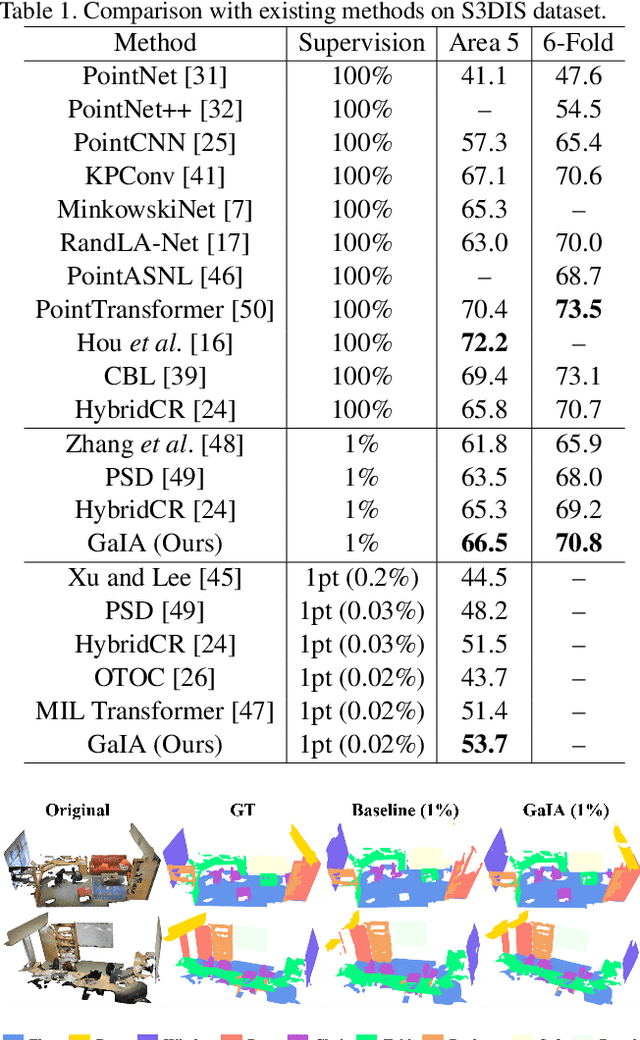
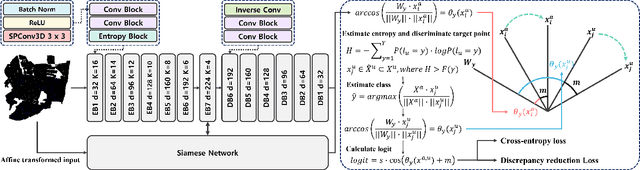
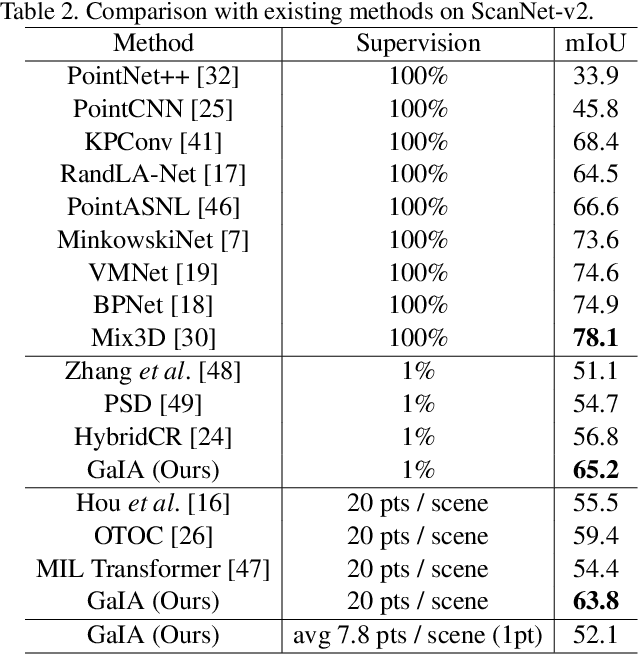
While point cloud semantic segmentation is a significant task in 3D scene understanding, this task demands a time-consuming process of fully annotating labels. To address this problem, recent studies adopt a weakly supervised learning approach under the sparse annotation. Different from the existing studies, this study aims to reduce the epistemic uncertainty measured by the entropy for a precise semantic segmentation. We propose the graphical information gain based attention network called GaIA, which alleviates the entropy of each point based on the reliable information. The graphical information gain discriminates the reliable point by employing relative entropy between target point and its neighborhoods. We further introduce anchor-based additive angular margin loss, ArcPoint. The ArcPoint optimizes the unlabeled points containing high entropy towards semantically similar classes of the labeled points on hypersphere space. Experimental results on S3DIS and ScanNet-v2 datasets demonstrate our framework outperforms the existing weakly supervised methods. We have released GaIA at https://github.com/Karel911/GaIA.
TRACER: Extreme Attention Guided Salient Object Tracing Network
Dec 14, 2021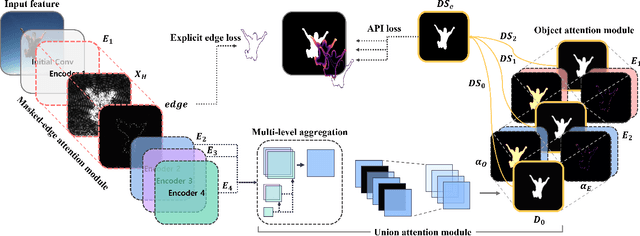
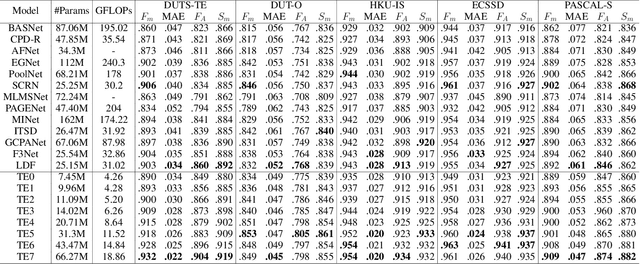


Existing studies on salient object detection (SOD) focus on extracting distinct objects with edge information and aggregating multi-level features to improve SOD performance. To achieve satisfactory performance, the methods employ refined edge information and low multi-level discrepancy. However, both performance gain and computational efficiency cannot be attained, which has motivated us to study the inefficiencies in existing encoder-decoder structures to avoid this trade-off. We propose TRACER, which detects salient objects with explicit edges by incorporating attention guided tracing modules. We employ a masked edge attention module at the end of the first encoder using a fast Fourier transform to propagate the refined edge information to the downstream feature extraction. In the multi-level aggregation phase, the union attention module identifies the complementary channel and important spatial information. To improve the decoder performance and computational efficiency, we minimize the decoder block usage with object attention module. This module extracts undetected objects and edge information from refined channels and spatial representations. Subsequently, we propose an adaptive pixel intensity loss function to deal with the relatively important pixels unlike conventional loss functions which treat all pixels equally. A comparison with 13 existing methods reveals that TRACER achieves state-of-the-art performance on five benchmark datasets. In particular, TRACER-Efficient3 (TE3) outperforms LDF, an existing method while requiring 1.8x fewer learning parameters and less time; TE3 is 5x faster.