 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Leveraging Pre-Trained Multi-Layer Representations for Speaker Verification
Dec 15, 2025Recent speaker verification studies have achieved notable success by leveraging layer-wise output from pre-trained Transformer models. However, few have explored the advancements in aggregating these multi-level features beyond the static weighted average. We present Layer Attentive Pooling (LAP), a novel strategy for aggregating inter-layer representations from pre-trained speech models for speaker verification. LAP assesses the significance of each layer from multiple perspectives time-dynamically, and employs max pooling instead of averaging. Additionally, we propose a lightweight backend speaker model comprising LAP and Attentive Statistical Temporal Pooling (ASTP) to extract speaker embeddings from pre-trained model output. Experiments on the VoxCeleb benchmark reveal that our compact architecture achieves state-of-the-art performance while greatly reducing the training time. We further analyzed LAP design and its dynamic weighting mechanism for capturing speaker characteristics.
* Accepted to Interspeech 2025
WAY: Estimation of Vessel Destination in Worldwide AIS Trajectory
Dec 15, 2025



The Automatic Identification System (AIS) enables data-driven maritime surveillance but suffers from reliability issues and irregular intervals. We address vessel destination estimation using global-scope AIS data by proposing a differentiated approach that recasts long port-to-port trajectories as a nested sequence structure. Using spatial grids, this method mitigates spatio-temporal bias while preserving detailed resolution. We introduce a novel deep learning architecture, WAY, designed to process these reformulated trajectories for long-term destination estimation days to weeks in advance. WAY comprises a trajectory representation layer and Channel-Aggregative Sequential Processing (CASP) blocks. The representation layer generates multi-channel vector sequences from kinematic and non-kinematic features. CASP blocks utilize multi-headed channel- and self-attention for aggregation and sequential information delivery. Additionally, we propose a task-specialized Gradient Dropout (GD) technique to enable many-to-many training on single labels, preventing biased feedback surges by stochastically blocking gradient flow based on sample length. Experiments on 5-year AIS data demonstrate WAY's superiority over conventional spatial grid-based approaches regardless of trajectory progression. Results further confirm that adopting GD leads to performance gains. Finally, we explore WAY's potential for real-world application through multitask learning for ETA estimation.
* Accepted to IEEE Transactions on Aerospace and Electronic Systems (TAES)
Universal Pooling Method of Multi-layer Features from Pretrained Models for Speaker Verification
Sep 12, 2024Recent advancements in automatic speaker verification (ASV) studies have been achieved by leveraging large-scale pretrained networks. In this study, we analyze the approaches toward such a paradigm and underline the significance of interlayer information processing as a result. Accordingly, we present a novel approach for exploiting the multilayered nature of pretrained models for ASV, which comprises a layer/frame-level network and two steps of pooling architectures for each layer and frame axis. Specifically, we let convolutional architecture directly processes a stack of layer outputs.Then, we present a channel attention-based scheme of gauging layer significance and squeeze the layer level with the most representative value. Finally, attentive statistics over frame-level representations yield a single vector speaker embedding. Comparative experiments are designed using versatile data environments and diverse pretraining models to validate the proposed approach. The experimental results demonstrate the stability of the approach using multi-layer outputs in leveraging pretrained architectures. Then, we verify the superiority of the proposed ASV backend structure, which involves layer-wise operations, in terms of performance improvement along with cost efficiency compared to the conventional method. The ablation study shows how the proposed interlayer processing aids in maximizing the advantage of utilizing pretrained models.
DEX-TTS: Diffusion-based EXpressive Text-to-Speech with Style Modeling on Time Variability
Jun 27, 2024Expressive Text-to-Speech (TTS) using reference speech has been studied extensively to synthesize natural speech, but there are limitations to obtaining well-represented styles and improving model generalization ability. In this study, we present Diffusion-based EXpressive TTS (DEX-TTS), an acoustic model designed for reference-based speech synthesis with enhanced style representations. Based on a general diffusion TTS framework, DEX-TTS includes encoders and adapters to handle styles extracted from reference speech. Key innovations contain the differentiation of styles into time-invariant and time-variant categories for effective style extraction, as well as the design of encoders and adapters with high generalization ability. In addition, we introduce overlapping patchify and convolution-frequency patch embedding strategies to improve DiT-based diffusion networks for TTS. DEX-TTS yields outstanding performance in terms of objective and subjective evaluation in English multi-speaker and emotional multi-speaker datasets, without relying on pre-training strategies. Lastly, the comparison results for the general TTS on a single-speaker dataset verify the effectiveness of our enhanced diffusion backbone. Demos are available here.
Revisiting and Maximizing Temporal Knowledge in Semi-supervised Semantic Segmentation
May 31, 2024In semi-supervised semantic segmentation, the Mean Teacher- and co-training-based approaches are employed to mitigate confirmation bias and coupling problems. However, despite their high performance, these approaches frequently involve complex training pipelines and a substantial computational burden, limiting the scalability and compatibility of these methods. In this paper, we propose a PrevMatch framework that effectively mitigates the aforementioned limitations by maximizing the utilization of the temporal knowledge obtained during the training process. The PrevMatch framework relies on two core strategies: (1) we reconsider the use of temporal knowledge and thus directly utilize previous models obtained during training to generate additional pseudo-label guidance, referred to as previous guidance. (2) we design a highly randomized ensemble strategy to maximize the effectiveness of the previous guidance. Experimental results on four benchmark semantic segmentation datasets confirm that the proposed method consistently outperforms existing methods across various evaluation protocols. In particular, with DeepLabV3+ and ResNet-101 network settings, PrevMatch outperforms the existing state-of-the-art method, Diverse Co-training, by +1.6 mIoU on Pascal VOC with only 92 annotated images, while achieving 2.4 times faster training. Furthermore, the results indicate that PrevMatch induces stable optimization, particularly in benefiting classes that exhibit poor performance. Code is available at https://github.com/wooseok-shin/PrevMatch
AD-YOLO: You Look ONly Once in Training Multiple Sound Event Localization and Detection
Mar 28, 2023Sound event localization and detection (SELD) combines the identification of sound events with the corresponding directions of arrival (DOA). Recently, event-oriented track output formats have been adopted to solve this problem; however, they still have limited generalization toward real-world problems in an unknown polyphony environment. To address the issue, we proposed an angular-distance-based multiple SELD (AD-YOLO), which is an adaptation of the "You Look Only Once" algorithm for SELD. The AD-YOLO format allows the model to learn sound occurrences location-sensitively by assigning class responsibility to DOA predictions. Hence, the format enables the model to handle the polyphony problem, regardless of the number of sound overlaps. We evaluated AD-YOLO on DCASE 2020-2022 challenge Task 3 datasets using four SELD objective metrics. The experimental results show that AD-YOLO achieved outstanding performance overall and also accomplished robustness in class-homogeneous polyphony environments.
TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
Mar 16, 2023Voice Conversion (VC) must be achieved while maintaining the content of the source speech and representing the characteristics of the target speaker. The existing methods do not simultaneously satisfy the above two aspects of VC, and their conversion outputs suffer from a trade-off problem between maintaining source contents and target characteristics. In this study, we propose Triple Adaptive Attention Normalization VC (TriAAN-VC), comprising an encoder-decoder and an attention-based adaptive normalization block, that can be applied to non-parallel any-to-any VC. The proposed adaptive normalization block extracts target speaker representations and achieves conversion while minimizing the loss of the source content with siamese loss. We evaluated TriAAN-VC on the VCTK dataset in terms of the maintenance of the source content and target speaker similarity. Experimental results for one-shot VC suggest that TriAAN-VC achieves state-of-the-art performance while mitigating the trade-off problem encountered in the existing VC methods.
GaIA: Graphical Information Gain based Attention Network for Weakly Supervised Point Cloud Semantic Segmentation
Oct 02, 2022
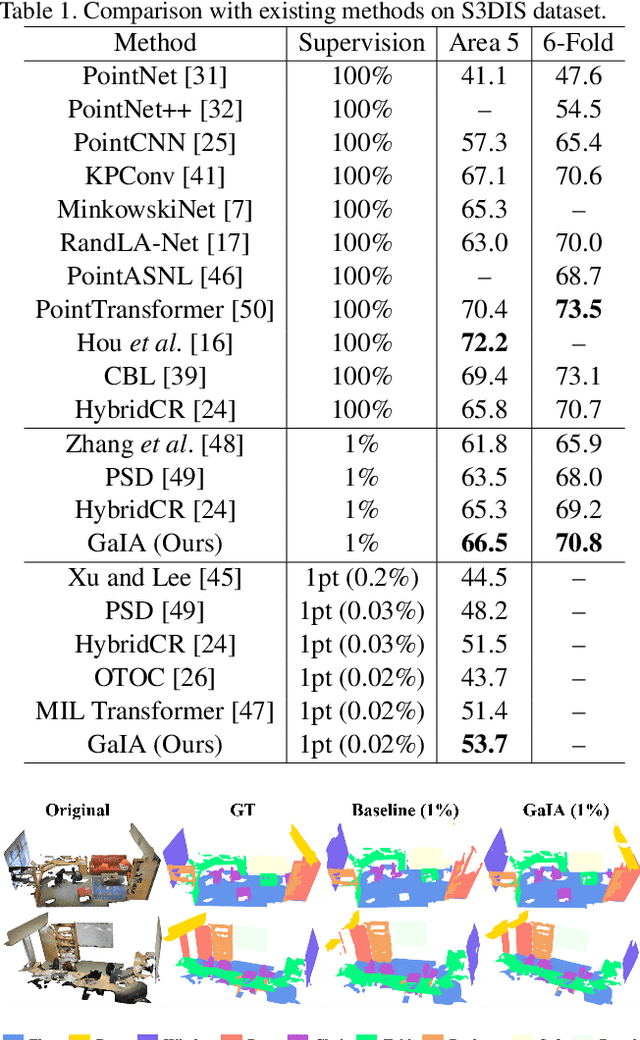
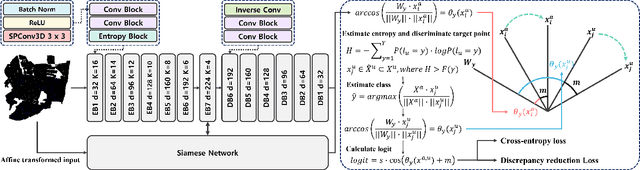
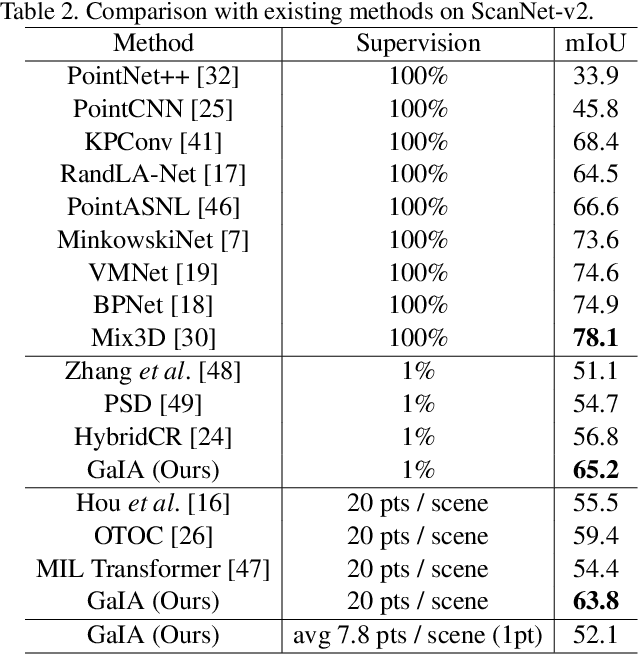
While point cloud semantic segmentation is a significant task in 3D scene understanding, this task demands a time-consuming process of fully annotating labels. To address this problem, recent studies adopt a weakly supervised learning approach under the sparse annotation. Different from the existing studies, this study aims to reduce the epistemic uncertainty measured by the entropy for a precise semantic segmentation. We propose the graphical information gain based attention network called GaIA, which alleviates the entropy of each point based on the reliable information. The graphical information gain discriminates the reliable point by employing relative entropy between target point and its neighborhoods. We further introduce anchor-based additive angular margin loss, ArcPoint. The ArcPoint optimizes the unlabeled points containing high entropy towards semantically similar classes of the labeled points on hypersphere space. Experimental results on S3DIS and ScanNet-v2 datasets demonstrate our framework outperforms the existing weakly supervised methods. We have released GaIA at https://github.com/Karel911/GaIA.
Multi-View Attention Transfer for Efficient Speech Enhancement
Aug 22, 2022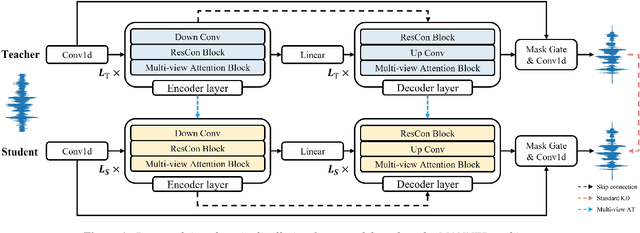
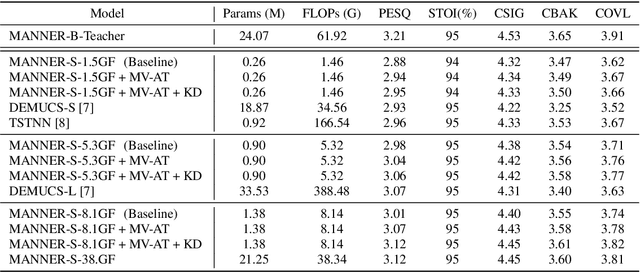
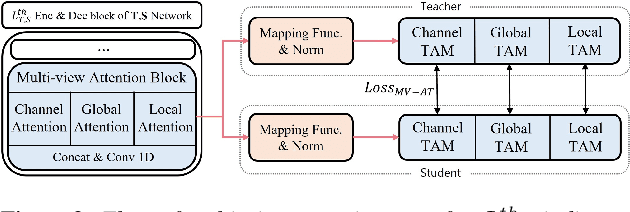
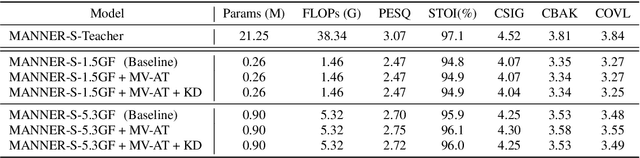
Recent deep learning models have achieved high performance in speech enhancement; however, it is still challenging to obtain a fast and low-complexity model without significant performance degradation. Previous knowledge distillation studies on speech enhancement could not solve this problem because their output distillation methods do not fit the speech enhancement task in some aspects. In this study, we propose multi-view attention transfer (MV-AT), a feature-based distillation, to obtain efficient speech enhancement models in the time domain. Based on the multi-view features extraction model, MV-AT transfers multi-view knowledge of the teacher network to the student network without additional parameters. The experimental results show that the proposed method consistently improved the performance of student models of various sizes on the Valentini and deep noise suppression (DNS) datasets. MANNER-S-8.1GF with our proposed method, a lightweight model for efficient deployment, achieved 15.4x and 4.71x fewer parameters and floating-point operations (FLOPs), respectively, compared to the baseline model with similar performance.
MANNER: Multi-view Attention Network for Noise Erasure
Mar 04, 2022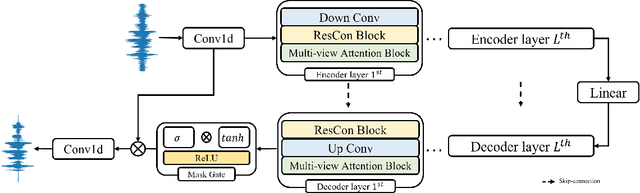
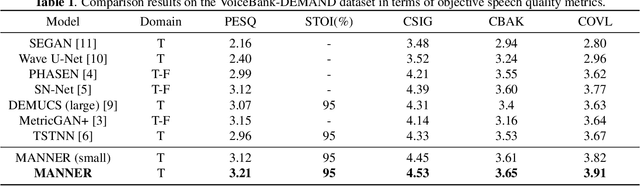
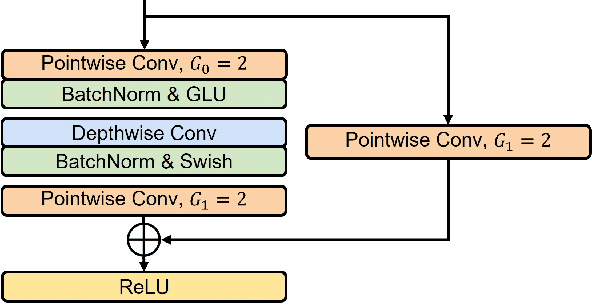
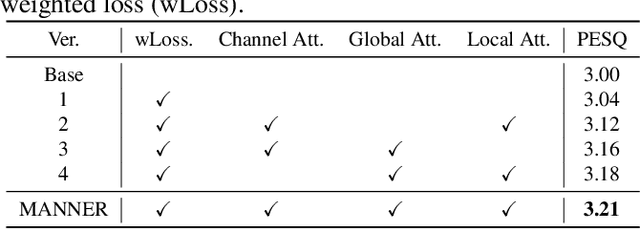
In the field of speech enhancement, time domain methods have difficulties in achieving both high performance and efficiency. Recently, dual-path models have been adopted to represent long sequential features, but they still have limited representations and poor memory efficiency. In this study, we propose Multi-view Attention Network for Noise ERasure (MANNER) consisting of a convolutional encoder-decoder with a multi-view attention block, applied to the time-domain signals. MANNER efficiently extracts three different representations from noisy speech and estimates high-quality clean speech. We evaluated MANNER on the VoiceBank-DEMAND dataset in terms of five objective speech quality metrics. Experimental results show that MANNER achieves state-of-the-art performance while efficiently processing noisy speech.