 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Taylor Swift: Taylor Driven Temporal Modeling for Swift Future Frame Prediction
Oct 27, 2021
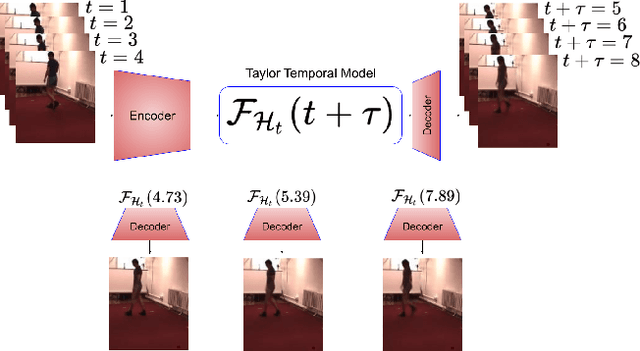
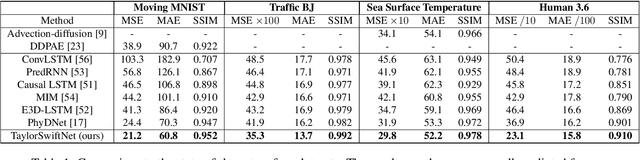
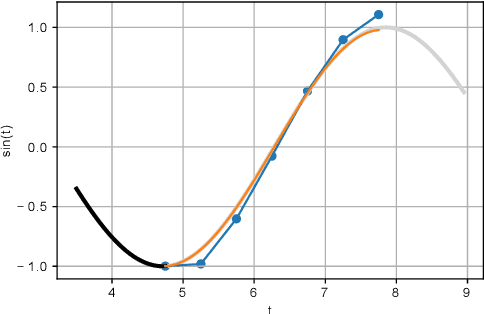

While recurrent neural networks (RNNs) demonstrate outstanding capabilities in future video frame prediction, they model dynamics in a discrete time space and sequentially go through all frames until the desired future temporal step is reached. RNNs are therefore prone to accumulate the error as the number of future frames increases. In contrast, partial differential equations (PDEs) model physical phenomena like dynamics in continuous time space, however, current PDE-based approaches discretize the PDEs using e.g., the forward Euler method. In this work, we therefore propose to approximate the motion in a video by a continuous function using the Taylor series. To this end, we introduce TayloSwiftNet, a novel convolutional neural network that learns to estimate the higher order terms of the Taylor series for a given input video. TayloSwiftNet can swiftly predict any desired future frame in just one forward pass and change the temporal resolution on-the-fly. The experimental results on various datasets demonstrate the superiority of our model.
Modeling and Predicting Blood Flow Characteristics through Double Stenosed Artery from CFD simulation using Deep Learning Models
Dec 04, 2021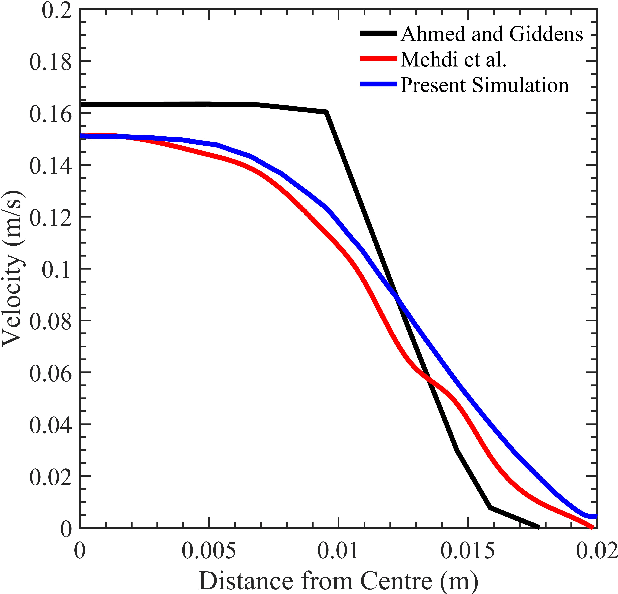
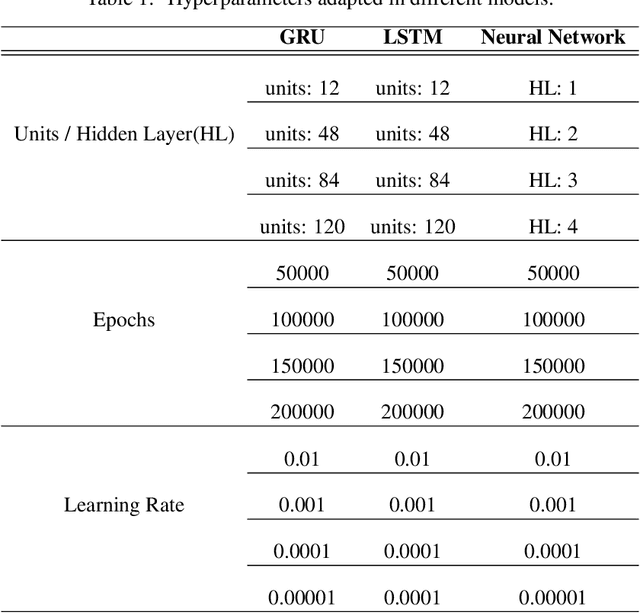
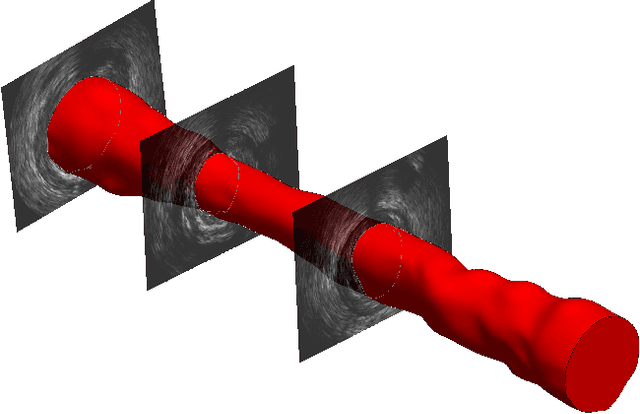
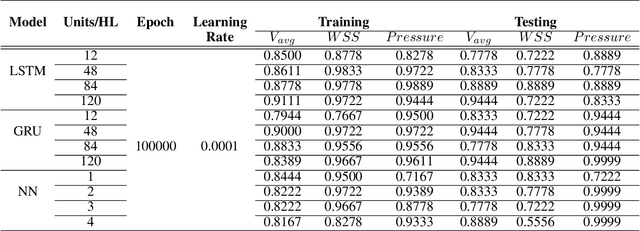
Establishing patient-specific finite element analysis (FEA) models for computational fluid dynamics (CFD) of double stenosed artery models involves time and effort, restricting physicians' ability to respond quickly in time-critical medical applications. Such issues might be addressed by training deep learning (DL) models to learn and predict blood flow characteristics using a dataset generated by CFD simulations of simplified double stenosed artery models with different configurations. When blood flow patterns are compared through an actual double stenosed artery model, derived from IVUS imaging, it is revealed that the sinusoidal approximation of stenosed neck geometry, which has been widely used in previous research works, fails to effectively represent the effects of a real constriction. As a result, a novel geometric representation of the constricted neck is proposed which, in terms of a generalized simplified model, outperforms the former assumption. The sequential change in artery lumen diameter and flow parameters along the length of the vessel presented opportunities for the use of LSTM and GRU DL models. However, with the small dataset of short lengths of doubly constricted blood arteries, the basic neural network model outperforms the specialized RNNs for most flow properties. LSTM, on the other hand, performs better for predicting flow properties with large fluctuations, such as varying blood pressure over the length of the vessels. Despite having good overall accuracies in training and testing across all the properties for the vessels in the dataset, the GRU model underperforms for an individual vessel flow prediction in all cases. The results also point to the need of individually optimized hyperparameters for each property in any model rather than aiming to achieve overall good performance across all outputs with a single set of hyperparameters.
Memetic Search for Vehicle Routing with Simultaneous Pickup-Delivery and Time Windows
Nov 16, 2020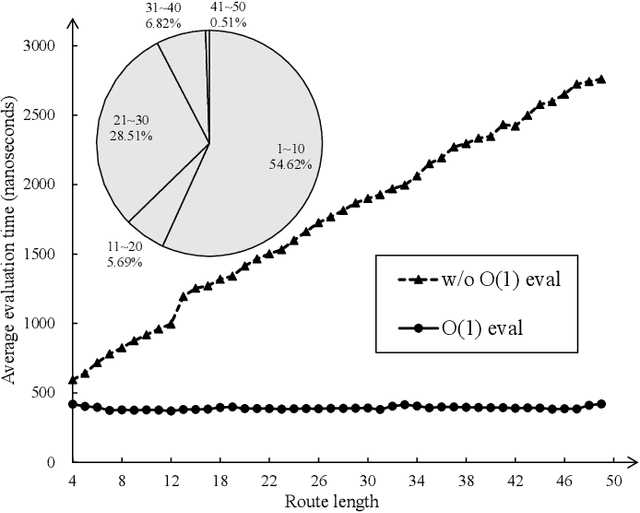
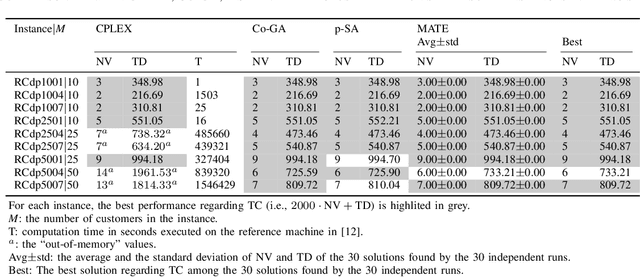
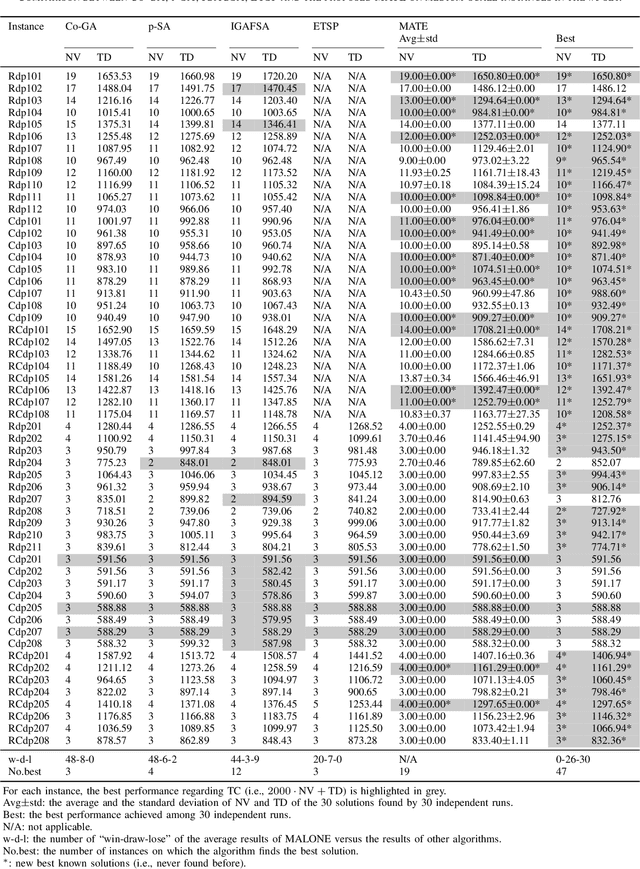
The vehicle routing problem with simultaneous pickup-delivery and time windows (VRPSPDTW) has attracted much attention in the last decade, due to its wide application in modern logistics involving bi-directional flow of goods. In this paper, we propose a memetic algorithm with efficient local search and extended neighborhood, dubbed MATE, for solving this problem. The novelty of MATE lies in three aspects: 1) an initialization procedure which integrates an existing heuristic into the population-based search framework, in an intelligent way; 2) a new crossover involving route inheritance and regret-based node reinsertion; 3) a highly-effective local search procedure which could flexibly search in a large neighborhood by switching between move operators with different step sizes, while keeping low computational complexity. Experimental results on public benchmark show that MATE consistently outperforms all the state-of-the-art algorithms, and notably, finds new best-known solutions on 44 instances (65 instances in total). A new benchmark of large-scale instances, derived from a real-world application of the JD logistics, is also introduced, which could serve as a new and more practical test set for future research.
DEFER: Distributed Edge Inference for Deep Neural Networks
Jan 18, 2022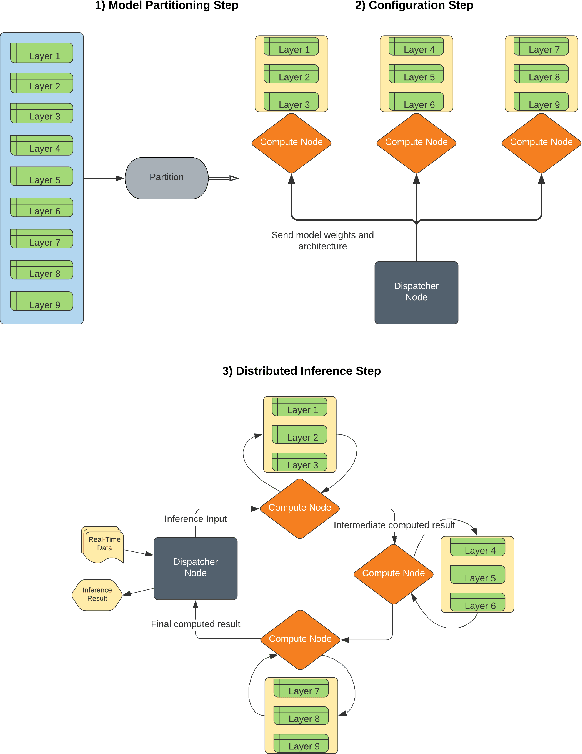
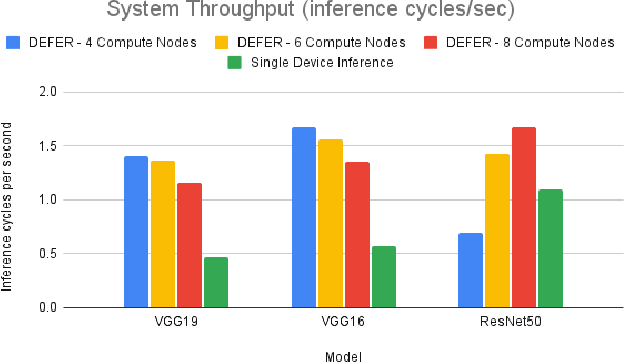
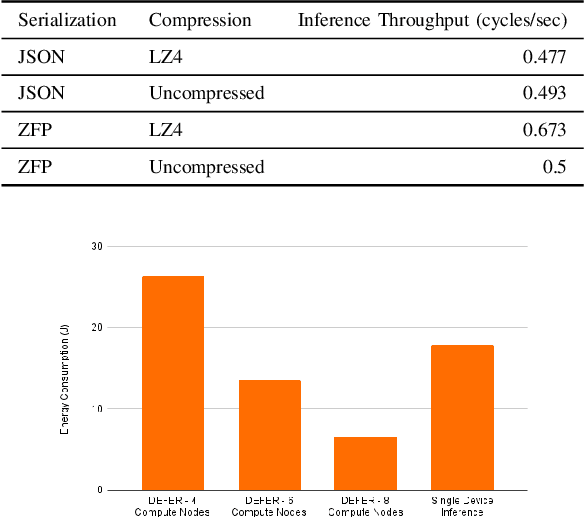
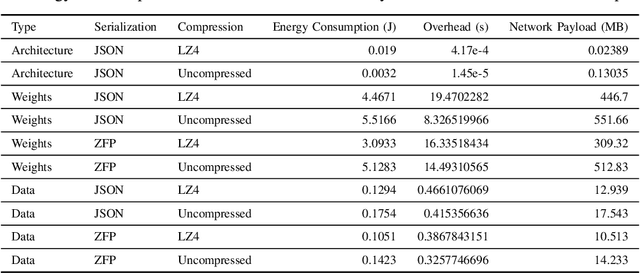
Modern machine learning tools such as deep neural networks (DNNs) are playing a revolutionary role in many fields such as natural language processing, computer vision, and the internet of things. Once they are trained, deep learning models can be deployed on edge computers to perform classification and prediction on real-time data for these applications. Particularly for large models, the limited computational and memory resources on a single edge device can become the throughput bottleneck for an inference pipeline. To increase throughput and decrease per-device compute load, we present DEFER (Distributed Edge inFERence), a framework for distributed edge inference, which partitions deep neural networks into layers that can be spread across multiple compute nodes. The architecture consists of a single "dispatcher" node to distribute DNN partitions and inference data to respective compute nodes. The compute nodes are connected in a series pattern where each node's computed result is relayed to the subsequent node. The result is then returned to the Dispatcher. We quantify the throughput, energy consumption, network payload, and overhead for our framework under realistic network conditions using the CORE network emulator. We find that for the ResNet50 model, the inference throughput of DEFER with 8 compute nodes is 53% higher and per node energy consumption is 63% lower than single device inference. We further reduce network communication demands and energy consumption using the ZFP serialization and LZ4 compression algorithms. We have implemented DEFER in Python using the TensorFlow and Keras ML libraries, and have released DEFER as an open-source framework to benefit the research community.
* Received the Best Paper Award at the COMSNETS 2022 MINDS Workshop
Convergence of GANs Training: A Game and Stochastic Control Methodology
Dec 27, 2021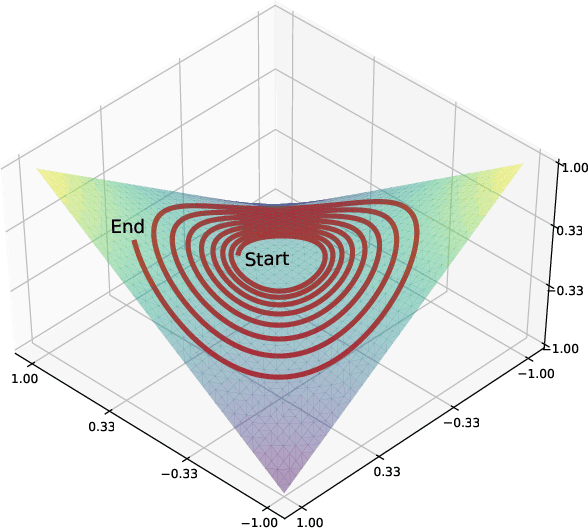
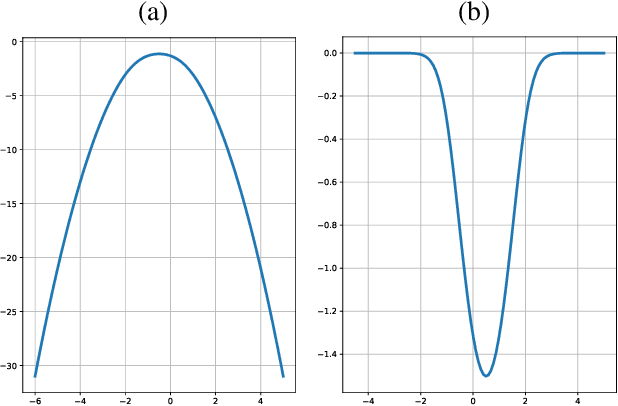
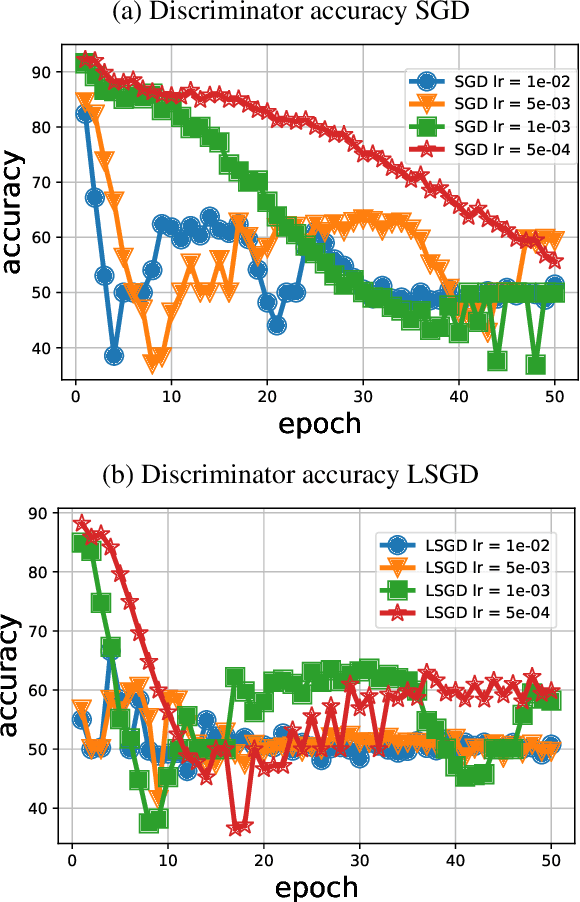
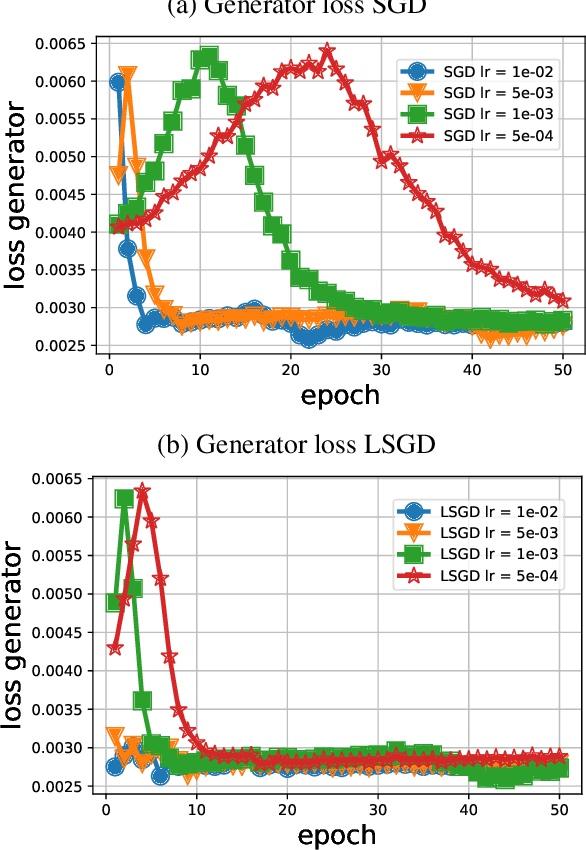
Training generative adversarial networks (GANs) is known to be difficult, especially for financial time series. This paper first analyzes the well-posedness problem in GANs minimax games and the convexity issue in GANs objective functions. It then proposes a stochastic control framework for hyper-parameters tuning in GANs training. The weak form of dynamic programming principle and the uniqueness and the existence of the value function in the viscosity sense for the corresponding minimax game are established. In particular, explicit forms for the optimal adaptive learning rate and batch size are derived and are shown to depend on the convexity of the objective function, revealing a relation between improper choices of learning rate and explosion in GANs training. Finally, empirical studies demonstrate that training algorithms incorporating this adaptive control approach outperform the standard ADAM method in terms of convergence and robustness. From GANs training perspective, the analysis in this paper provides analytical support for the popular practice of ``clipping'', and suggests that the convexity and well-posedness issues in GANs may be tackled through appropriate choices of hyper-parameters.
Integration of Explainable Artificial Intelligence to Identify Significant Landslide Causal Factors for Extreme Gradient Boosting based Landslide Susceptibility Mapping with Improved Feature Selection
Jan 10, 2022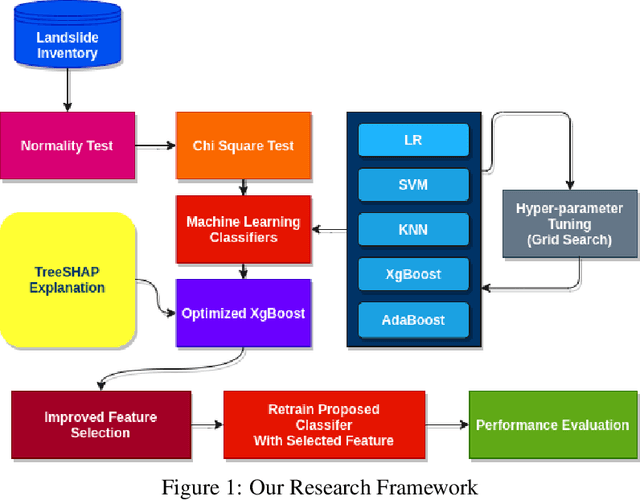
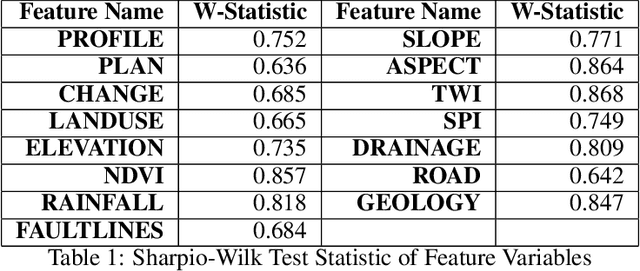
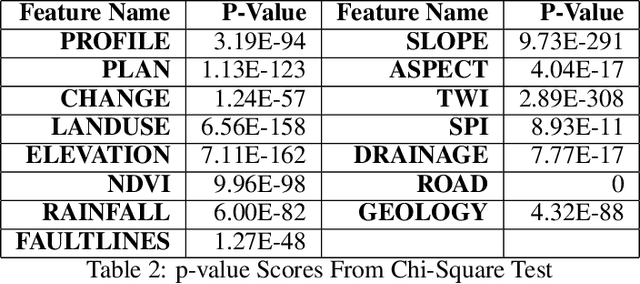
Landslides have been a regular occurrence and an alarming threat to human life and property in the era of anthropogenic global warming. An early prediction of landslide susceptibility using a data-driven approach is a demand of time. In this study, we explored the eloquent features that best describe landslide susceptibility with state-of-the-art machine learning methods. In our study, we employed state-of-the-art machine learning algorithms including XgBoost, LR, KNN, SVM, Adaboost for landslide susceptibility prediction. To find the best hyperparameters of each individual classifier for optimized performance, we have incorporated the Grid Search method, with 10 Fold Cross-Validation. In this context, the optimized version of XgBoost outperformed all other classifiers with a Cross-validation Weighted F1 score of 94.62%. Followed by this empirical evidence, we explored the XgBoost classifier by incorporating TreeSHAP and identified eloquent features such as SLOPE, ELEVATION, TWI that complement the performance of the XGBoost classifier mostly and features such as LANDUSE, NDVI, SPI which has less effect on models performance. According to the TreeSHAP explanation of features, we selected the 9 most significant landslide causal factors out of 15. Evidently, an optimized version of XgBoost along with feature reduction by 40%, has outperformed all other classifiers in terms of popular evaluation metrics with a Cross-Validation Weighted F1 score of 95.01% on the training and AUC score of 97%.
High-Throughput and Configurable Preprocessor for ICA-based Self-interference Cancellation
Jan 10, 2022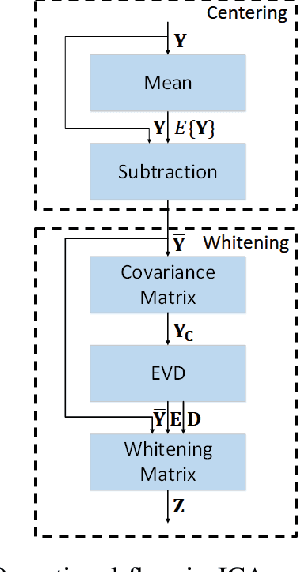

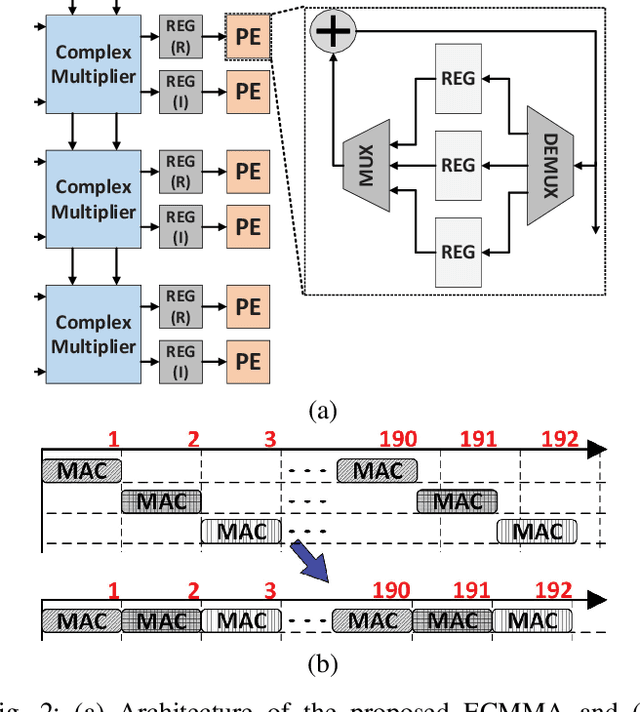

Independent component analysis (ICA) has been used in many applications, including self-interference cancellation in in-band full-duplex wireless communication systems. This paper presents a high-throughput and highly efficient configurable preprocessor for the ICA algorithm. The proposed ICA preprocessor has three major components for centering, for computing the covariance matrix, and for eigenvalue decomposition (EVD). The circuit structures and operational flows for these components are designed both in individual and in joint sense. Specifically, the proposed preprocessor is based on a high-performance matrix multiplication array (MMA) that is presented in this paper. The proposed MMA architecture uses time-multiplexed processing so that the efficiency of hardware utilization is greatly enhanced. Furthermore, the novel processing flow of the proposed preprocessor is highly optimized, so that the centering, the calculation of the covariance matrix, and EVD are conducted in parallel and are pipelined. Thus, the processing throughput is maximized while the required number of hardware elements can be minimized. The proposed ICA preprocessor is designed and implemented with a circuit design flow, and performance estimates based on the post-layout evaluations are presented in this paper. This paper shows that the proposed preprocessor achieves a throughput of 40.7~kMatrices per second for a complexity of 73.3~kGE. Compared with prior work, the proposed preprocessor achieves the highest processing throughput and best efficiency.
Towards realistic symmetry-based completion of previously unseen point clouds
Jan 05, 2022
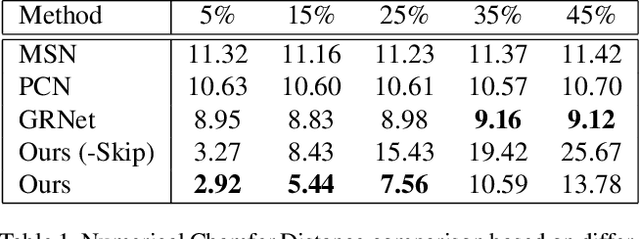
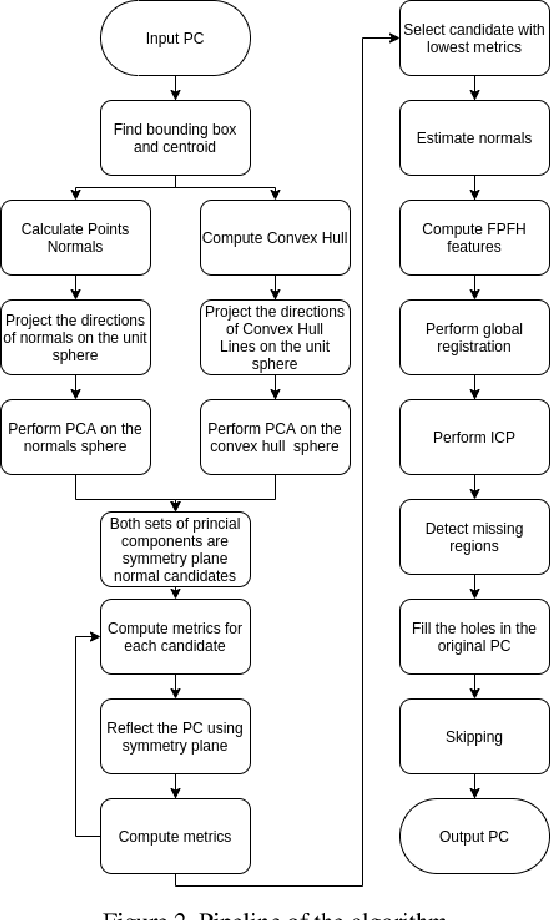

3D scanning is a complex multistage process that generates a point cloud of an object typically containing damaged parts due to occlusions, reflections, shadows, scanner motion, specific properties of the object surface, imperfect reconstruction algorithms, etc. Point cloud completion is specifically designed to fill in the missing parts of the object and obtain its high-quality 3D representation. The existing completion approaches perform well on the academic datasets with a predefined set of object classes and very specific types of defects; however, their performance drops significantly in the real-world settings and degrades even further on previously unseen object classes. We propose a novel framework that performs well on symmetric objects, which are ubiquitous in man-made environments. Unlike learning-based approaches, the proposed framework does not require training data and is capable of completing non-critical damages occurring in customer 3D scanning process using e.g. Kinect, time-of-flight, or structured light scanners. With thorough experiments, we demonstrate that the proposed framework achieves state-of-the-art efficiency in point cloud completion of real-world customer scans. We benchmark the framework performance on two types of datasets: properly augmented existing academic dataset and the actual 3D scans of various objects.
Real-Time Adaptive Velocity Optimization for Autonomous Electric Cars at the Limits of Handling
Dec 25, 2020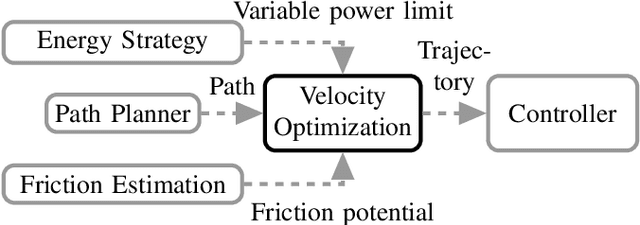
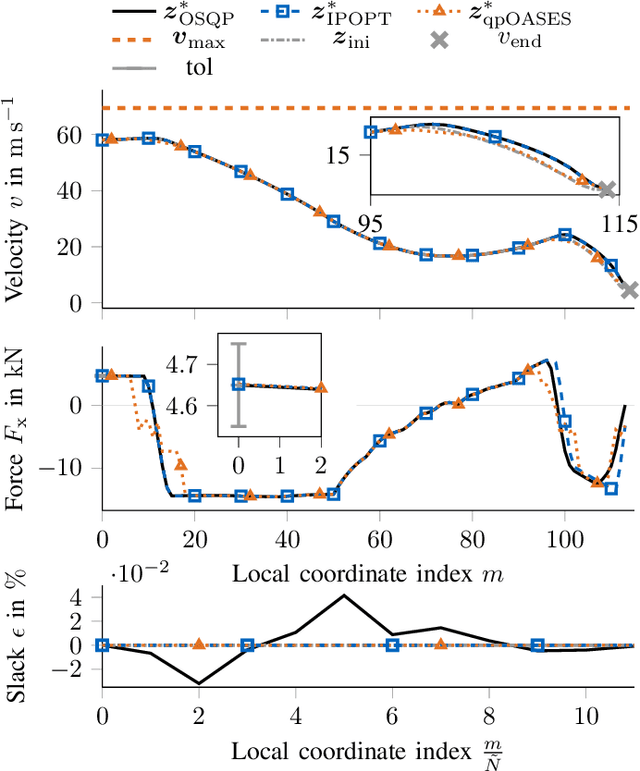
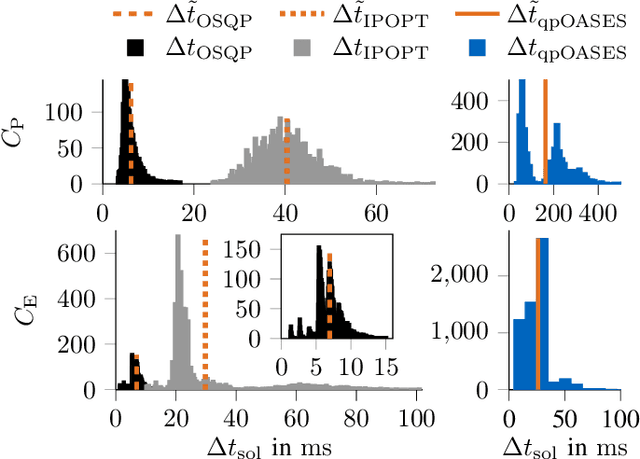

With the evolution of self-driving cars, autonomous racing series like Roborace and the Indy Autonomous Challenge are rapidly attracting growing attention. Researchers participating in these competitions hope to subsequently transfer their developed functionality to passenger vehicles, in order to improve self-driving technology for reasons of safety, and due to environmental and social benefits. The race track has the advantage of being a safe environment where challenging situations for the algorithms are permanently created. To achieve minimum lap times on the race track, it is important to gather and process information about external influences including, e.g., the position of other cars and the friction potential between the road and the tires. Furthermore, the predicted behavior of the ego-car's propulsion system is crucial for leveraging the available energy as efficiently as possible. In this paper, we therefore present an optimization-based velocity planner, mathematically formulated as a multi-parametric Sequential Quadratic Problem (mpSQP). This planner can handle a spatially and temporally varying friction coefficient, and transfer a race Energy Strategy (ES) to the road. It further handles the velocity-profile-generation task for performance and emergency trajectories in real time on the vehicle's Electronic Control Unit (ECU).
Poly-time universality and limitations of deep learning
Jan 07, 2020
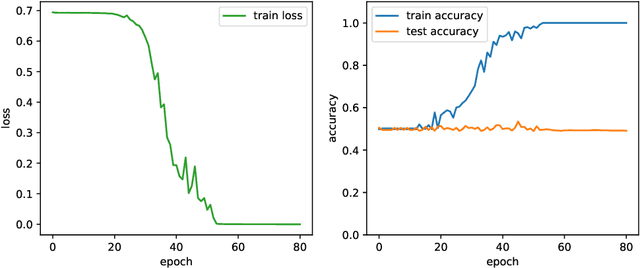
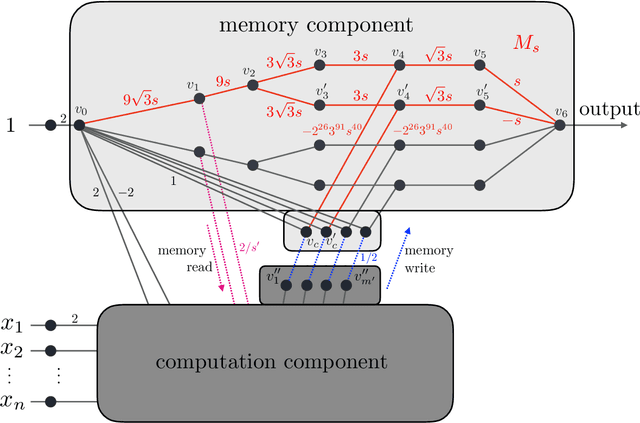
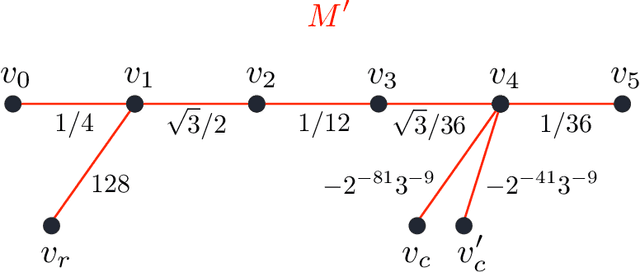
The goal of this paper is to characterize function distributions that deep learning can or cannot learn in poly-time. A universality result is proved for SGD-based deep learning and a non-universality result is proved for GD-based deep learning; this also gives a separation between SGD-based deep learning and statistical query algorithms: (1) {\it Deep learning with SGD is efficiently universal.} Any function distribution that can be learned from samples in poly-time can also be learned by a poly-size neural net trained with SGD on a poly-time initialization with poly-steps, poly-rate and possibly poly-noise. Therefore deep learning provides a universal learning paradigm: it was known that the approximation and estimation errors could be controlled with poly-size neural nets, using ERM that is NP-hard; this new result shows that the optimization error can also be controlled with SGD in poly-time. The picture changes for GD with large enough batches: (2) {\it Result (1) does not hold for GD:} Neural nets of poly-size trained with GD (full gradients or large enough batches) on any initialization with poly-steps, poly-range and at least poly-noise cannot learn any function distribution that has super-polynomial {\it cross-predictability,} where the cross-predictability gives a measure of ``average'' function correlation -- relations and distinctions to the statistical dimension are discussed. In particular, GD with these constraints can learn efficiently monomials of degree $k$ if and only if $k$ is constant. Thus (1) and (2) point to an interesting contrast: SGD is universal even with some poly-noise while full GD or SQ algorithms are not (e.g., parities).