 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeCIM: A Hardware-Software Co-Design for CIM-Based Acceleration of Small Language Models
Apr 13, 2026The growing demand for deploying Small Language Models (SLMs) on edge devices, including laptops, smartphones, and embedded platforms, has exposed fundamental inefficiencies in existing accelerators. While GPUs handle prefill workloads efficiently, the autoregressive decoding phase is dominated by GEMV operations that are inherently memory-bound, resulting in poor utilization and prohibitive energy costs at the edge. In this work, we present EdgeCIM, a hardware-software co-design framework that rethinks accelerator design for end-to-end decoder-only inference. At its core is a CIM macro, implemented in 65nm, coupled with a tile-based mapping strategy that balances pipeline stages, maximizing parallelism while alleviating DRAM bandwidth bottlenecks. Our simulator enables design space exploration of SLMs up to 4B parameters, identifying Pareto-optimal configurations in terms of latency and energy. Compared to an NVIDIA Orin Nano, EdgeCIM achieves up to 7.3x higher throughput and 49.59x better energy efficiency on LLaMA3.2-1B, and delivers 9.95x higher throughput than Qualcomm SA8255P on LLaMA3.2-3B. Extensive benchmarks on TinyLLaMA-1.1B, LLaMA3.2 (1B, 3B), Phi-3.5-mini-3.8B, Qwen2.5 (0.5B, 1.5B, 3B), SmolLM2-1.7B, SmolLM3-3B, and Qwen3 (0.6B, 1.7B, 4B) reveal that our accelerator, under INT4 precision, achieves on average 336.42 tokens/s and 173.02 tokens/J. These results establish EdgeCIM as a compelling solution towards real-time, energy-efficient edge-scale SLM inference.
Joint Hardware-Workload Co-Optimization for In-Memory Computing Accelerators
Mar 04, 2026Software-hardware co-design is essential for optimizing in-memory computing (IMC) hardware accelerators for neural networks. However, most existing optimization frameworks target a single workload, leading to highly specialized hardware designs that do not generalize well across models and applications. In contrast, practical deployment scenarios require a single IMC platform that can efficiently support multiple neural network workloads. This work presents a joint hardware-workload co-optimization framework based on an optimized evolutionary algorithm for designing generalized IMC accelerator architectures. By explicitly capturing cross-workload trade-offs rather than optimizing for a single model, the proposed approach significantly reduces the performance gap between workload-specific and generalized IMC designs. The framework is evaluated on both RRAM- and SRAM-based IMC architectures, demonstrating strong robustness and adaptability across diverse design scenarios. Compared to baseline methods, the optimized designs achieve energy-delay-area product (EDAP) reductions of up to 76.2% and 95.5% when optimizing across a small set (4 workloads) and a large set (9 workloads), respectively. The source code of the framework is available at https://github.com/OlgaKrestinskaya/JointHardwareWorkloadOptimizationIMC.
Leveraging Embedding Techniques in Multimodal Machine Learning for Mental Illness Assessment
Apr 02, 2025



The increasing global prevalence of mental disorders, such as depression and PTSD, requires objective and scalable diagnostic tools. Traditional clinical assessments often face limitations in accessibility, objectivity, and consistency. This paper investigates the potential of multimodal machine learning to address these challenges, leveraging the complementary information available in text, audio, and video data. Our approach involves a comprehensive analysis of various data preprocessing techniques, including novel chunking and utterance-based formatting strategies. We systematically evaluate a range of state-of-the-art embedding models for each modality and employ Convolutional Neural Networks (CNNs) and Bidirectional LSTM Networks (BiLSTMs) for feature extraction. We explore data-level, feature-level, and decision-level fusion techniques, including a novel integration of Large Language Model (LLM) predictions. We also investigate the impact of replacing Multilayer Perceptron classifiers with Support Vector Machines. We extend our analysis to severity prediction using PHQ-8 and PCL-C scores and multi-class classification (considering co-occurring conditions). Our results demonstrate that utterance-based chunking significantly improves performance, particularly for text and audio modalities. Decision-level fusion, incorporating LLM predictions, achieves the highest accuracy, with a balanced accuracy of 94.8% for depression and 96.2% for PTSD detection. The combination of CNN-BiLSTM architectures with utterance-level chunking, coupled with the integration of external LLM, provides a powerful and nuanced approach to the detection and assessment of mental health conditions. Our findings highlight the potential of MMML for developing more accurate, accessible, and personalized mental healthcare tools.
Chimera: A Block-Based Neural Architecture Search Framework for Event-Based Object Detection
Dec 27, 2024



Event-based cameras are sensors that simulate the human eye, offering advantages such as high-speed robustness and low power consumption. Established Deep Learning techniques have shown effectiveness in processing event data. Chimera is a Block-Based Neural Architecture Search (NAS) framework specifically designed for Event-Based Object Detection, aiming to create a systematic approach for adapting RGB-domain processing methods to the event domain. The Chimera design space is constructed from various macroblocks, including Attention blocks, Convolutions, State Space Models, and MLP-mixer-based architectures, which provide a valuable trade-off between local and global processing capabilities, as well as varying levels of complexity. The results on the PErson Detection in Robotics (PEDRo) dataset demonstrated performance levels comparable to leading state-of-the-art models, alongside an average parameter reduction of 1.6 times.
Leveraging Audio and Text Modalities in Mental Health: A Study of LLMs Performance
Dec 09, 2024



Mental health disorders are increasingly prevalent worldwide, creating an urgent need for innovative tools to support early diagnosis and intervention. This study explores the potential of Large Language Models (LLMs) in multimodal mental health diagnostics, specifically for detecting depression and Post Traumatic Stress Disorder through text and audio modalities. Using the E-DAIC dataset, we compare text and audio modalities to investigate whether LLMs can perform equally well or better with audio inputs. We further examine the integration of both modalities to determine if this can enhance diagnostic accuracy, which generally results in improved performance metrics. Our analysis specifically utilizes custom-formulated metrics; Modal Superiority Score and Disagreement Resolvement Score to evaluate how combined modalities influence model performance. The Gemini 1.5 Pro model achieves the highest scores in binary depression classification when using the combined modality, with an F1 score of 0.67 and a Balanced Accuracy (BA) of 77.4%, assessed across the full dataset. These results represent an increase of 3.1% over its performance with the text modality and 2.7% over the audio modality, highlighting the effectiveness of integrating modalities to enhance diagnostic accuracy. Notably, all results are obtained in zero-shot inferring, highlighting the robustness of the models without requiring task-specific fine-tuning. To explore the impact of different configurations on model performance, we conduct binary, severity, and multiclass tasks using both zero-shot and few-shot prompts, examining the effects of prompt variations on performance. The results reveal that models such as Gemini 1.5 Pro in text and audio modalities, and GPT-4o mini in the text modality, often surpass other models in balanced accuracy and F1 scores across multiple tasks.
Automated Multi-Label Annotation for Mental Health Illnesses Using Large Language Models
Dec 05, 2024



The growing prevalence and complexity of mental health disorders present significant challenges for accurate diagnosis and treatment, particularly in understanding the interplay between co-occurring conditions. Mental health disorders, such as depression and Anxiety, often co-occur, yet current datasets derived from social media posts typically focus on single-disorder labels, limiting their utility in comprehensive diagnostic analyses. This paper addresses this critical gap by proposing a novel methodology for cleaning, sampling, labeling, and combining data to create versatile multi-label datasets. Our approach introduces a synthetic labeling technique to transform single-label datasets into multi-label annotations, capturing the complexity of overlapping mental health conditions. To achieve this, two single-label datasets are first merged into a foundational multi-label dataset, enabling realistic analyses of co-occurring diagnoses. We then design and evaluate various prompting strategies for large language models (LLMs), ranging from single-label predictions to unrestricted prompts capable of detecting any present disorders. After rigorously assessing multiple LLMs and prompt configurations, the optimal combinations are identified and applied to label six additional single-disorder datasets from RMHD. The result is SPAADE-DR, a robust, multi-label dataset encompassing diverse mental health conditions. This research demonstrates the transformative potential of LLM-driven synthetic labeling in advancing mental health diagnostics from social media data, paving the way for more nuanced, data-driven insights into mental health care.
SoftmAP: Software-Hardware Co-design for Integer-Only Softmax on Associative Processors
Nov 26, 2024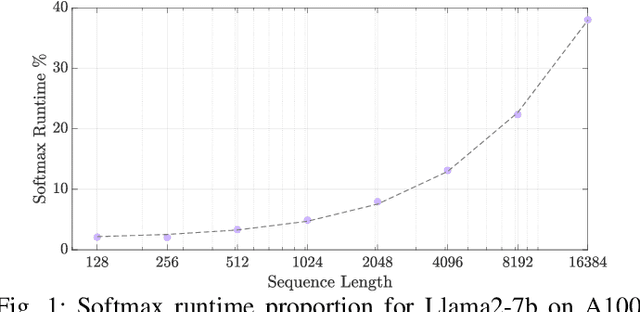
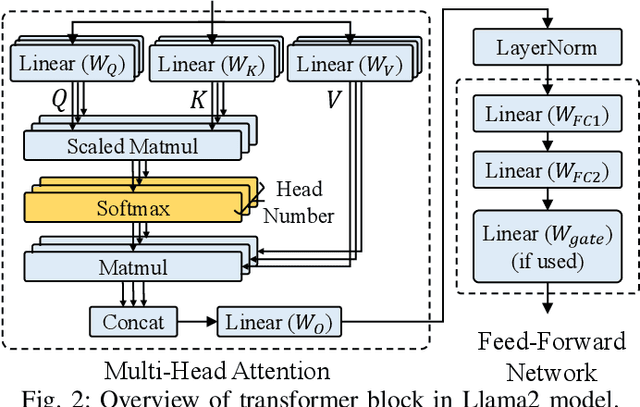
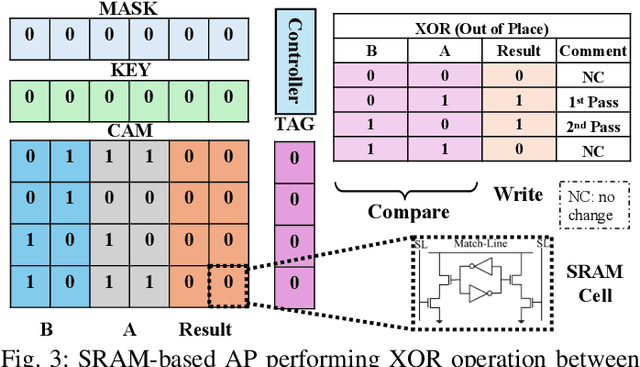
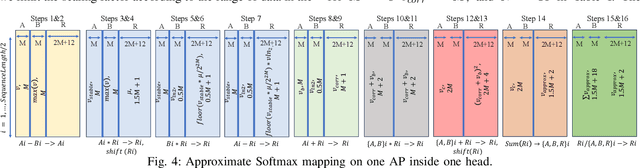
Recent research efforts focus on reducing the computational and memory overheads of Large Language Models (LLMs) to make them feasible on resource-constrained devices. Despite advancements in compression techniques, non-linear operators like Softmax and Layernorm remain bottlenecks due to their sensitivity to quantization. We propose SoftmAP, a software-hardware co-design methodology that implements an integer-only low-precision Softmax using In-Memory Compute (IMC) hardware. Our method achieves up to three orders of magnitude improvement in the energy-delay product compared to A100 and RTX3090 GPUs, making LLMs more deployable without compromising performance.
BF-IMNA: A Bit Fluid In-Memory Neural Architecture for Neural Network Acceleration
Nov 03, 2024



Mixed-precision quantization works Neural Networks (NNs) are gaining traction for their efficient realization on the hardware leading to higher throughput and lower energy. In-Memory Computing (IMC) accelerator architectures are offered as alternatives to traditional architectures relying on a data-centric computational paradigm, diminishing the memory wall problem, and scoring high throughput and energy efficiency. These accelerators can support static fixed-precision but are not flexible to support mixed-precision NNs. In this paper, we present BF-IMNA, a bit fluid IMC accelerator for end-to-end Convolutional NN (CNN) inference that is capable of static and dynamic mixed-precision without any hardware reconfiguration overhead at run-time. At the heart of BF-IMNA are Associative Processors (APs), which are bit-serial word-parallel Single Instruction, Multiple Data (SIMD)-like engines. We report the performance of end-to-end inference of ImageNet on AlexNet, VGG16, and ResNet50 on BF-IMNA for different technologies (eNVM and NVM), mixed-precision configurations, and supply voltages. To demonstrate bit fluidity, we implement HAWQ-V3's per-layer mixed-precision configurations for ResNet18 on BF-IMNA using different latency budgets, and results reveal a trade-off between accuracy and Energy-Delay Product (EDP): On one hand, mixed-precision with a high latency constraint achieves the closest accuracy to fixed-precision INT8 and reports a high (worse) EDP compared to fixed-precision INT4. On the other hand, with a low latency constraint, BF-IMNA reports the closest EDP to fixed-precision INT4, with a higher degradation in accuracy compared to fixed-precision INT8. We also show that BF-IMNA with fixed-precision configuration still delivers performance that is comparable to current state-of-the-art accelerators: BF-IMNA achieves $20\%$ higher energy efficiency and $2\%$ higher throughput.
Towards Efficient IMC Accelerator Design Through Joint Hardware-Workload Co-optimization
Oct 22, 2024



Designing generalized in-memory computing (IMC) hardware that efficiently supports a variety of workloads requires extensive design space exploration, which is infeasible to perform manually. Optimizing hardware individually for each workload or solely for the largest workload often fails to yield the most efficient generalized solutions. To address this, we propose a joint hardware-workload optimization framework that identifies optimised IMC chip architecture parameters, enabling more efficient, workload-flexible hardware. We show that joint optimization achieves 36%, 36%, 20%, and 69% better energy-latency-area scores for VGG16, ResNet18, AlexNet, and MobileNetV3, respectively, compared to the separate architecture parameters search optimizing for a single largest workload. Additionally, we quantify the performance trade-offs and losses of the resulting generalized IMC hardware compared to workload-specific IMC designs.
A Recurrent YOLOv8-based framework for Event-Based Object Detection
Aug 09, 2024



Object detection is crucial in various cutting-edge applications, such as autonomous vehicles and advanced robotics systems, primarily relying on data from conventional frame-based RGB sensors. However, these sensors often struggle with issues like motion blur and poor performance in challenging lighting conditions. In response to these challenges, event-based cameras have emerged as an innovative paradigm. These cameras, mimicking the human eye, demonstrate superior performance in environments with fast motion and extreme lighting conditions while consuming less power. This study introduces ReYOLOv8, an advanced object detection framework that enhances a leading frame-based detection system with spatiotemporal modeling capabilities. We implemented a low-latency, memory-efficient method for encoding event data to boost the system's performance. We also developed a novel data augmentation technique tailored to leverage the unique attributes of event data, thus improving detection accuracy. Our models outperformed all comparable approaches in the GEN1 dataset, focusing on automotive applications, achieving mean Average Precision (mAP) improvements of 5%, 2.8%, and 2.5% across nano, small, and medium scales, respectively.These enhancements were achieved while reducing the number of trainable parameters by an average of 4.43% and maintaining real-time processing speeds between 9.2ms and 15.5ms. On the PEDRo dataset, which targets robotics applications, our models showed mAP improvements ranging from 9% to 18%, with 14.5x and 3.8x smaller models and an average speed enhancement of 1.67x.