 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of GANs Training: A Game and Stochastic Control Methodology
Dec 27, 2021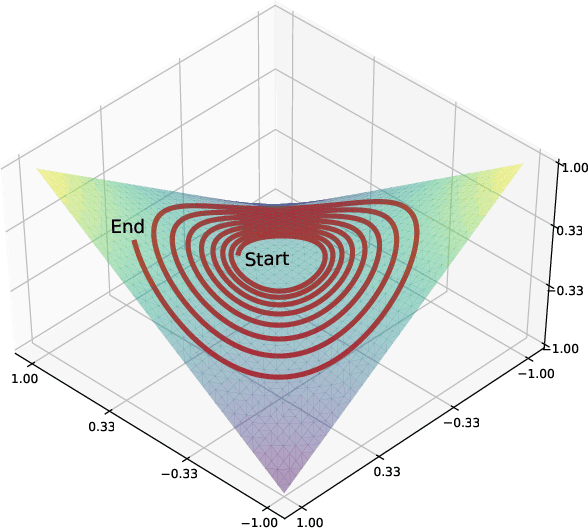
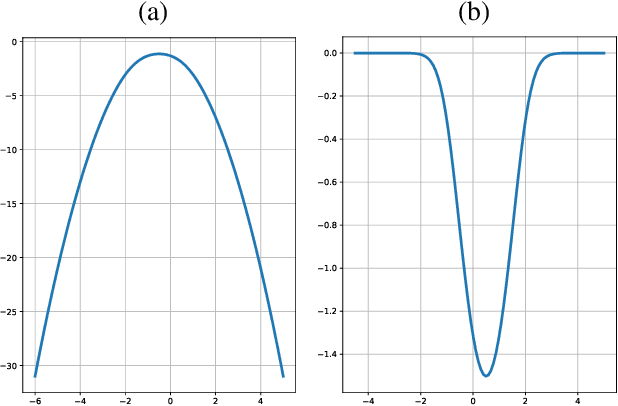
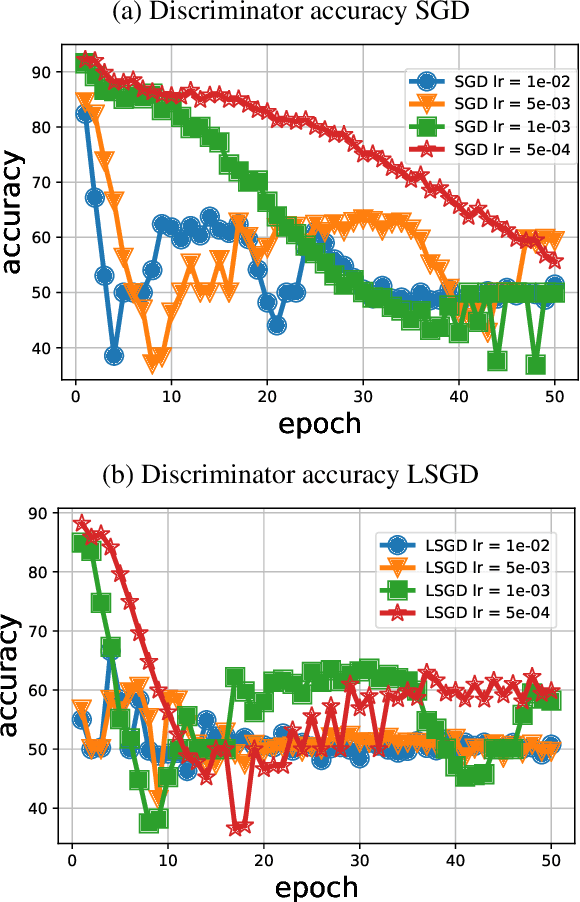
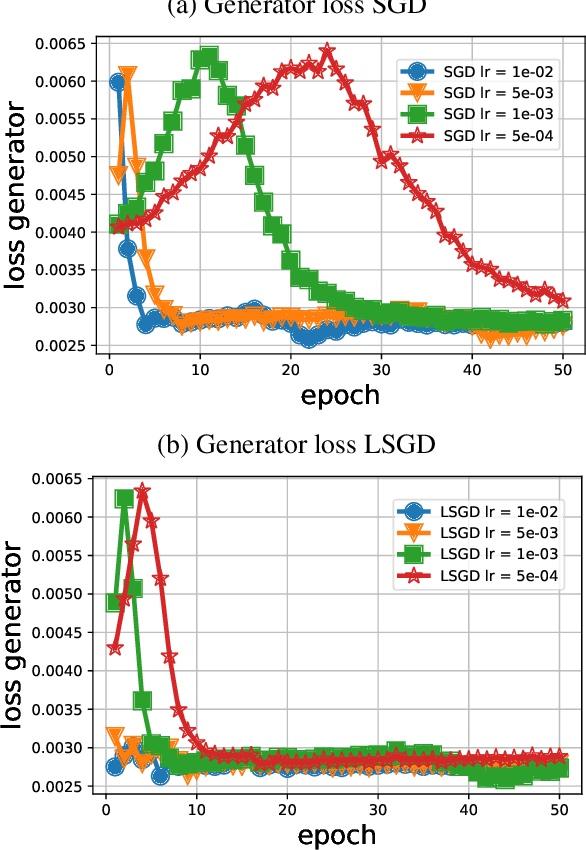
Training generative adversarial networks (GANs) is known to be difficult, especially for financial time series. This paper first analyzes the well-posedness problem in GANs minimax games and the convexity issue in GANs objective functions. It then proposes a stochastic control framework for hyper-parameters tuning in GANs training. The weak form of dynamic programming principle and the uniqueness and the existence of the value function in the viscosity sense for the corresponding minimax game are established. In particular, explicit forms for the optimal adaptive learning rate and batch size are derived and are shown to depend on the convexity of the objective function, revealing a relation between improper choices of learning rate and explosion in GANs training. Finally, empirical studies demonstrate that training algorithms incorporating this adaptive control approach outperform the standard ADAM method in terms of convergence and robustness. From GANs training perspective, the analysis in this paper provides analytical support for the popular practice of ``clipping'', and suggests that the convexity and well-posedness issues in GANs may be tackled through appropriate choices of hyper-parameters.
Improving reinforcement learning algorithms: towards optimal learning rate policies
Nov 06, 2019
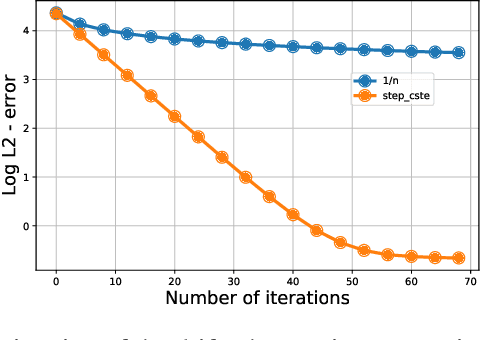

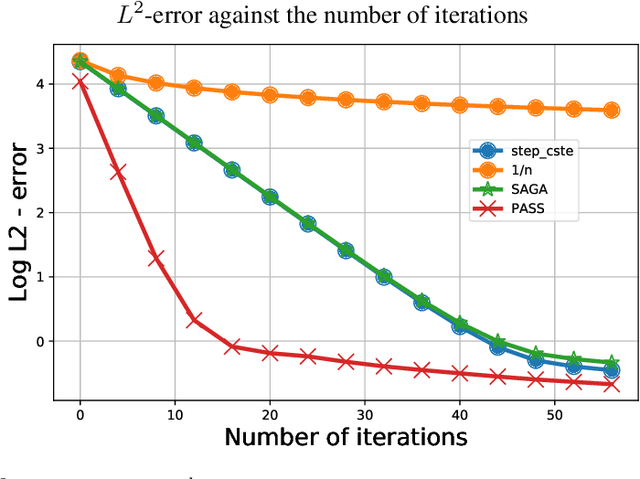
This paper investigates to what extent we can improve reinforcement learning algorithms. Our study is split in three parts. First, our analysis shows that the classical asymptotic convergence rate $O(1/\sqrt{N})$ is pessimistic and can be replaced by $O((\log(N)/N)^{\beta})$ with $\frac{1}{2}\leq \beta \leq 1$ and $N$ the number of iterations. Second, we propose a dynamic optimal policy for the choice of the learning rate $(\gamma_k)_{k\geq 0}$ used in stochastic algorithms. We decompose our policy into two interacting levels: the inner and the outer level. In the inner level, we present the PASS algorithm (for "PAst Sign Search") which, based on a predefined sequence $(\gamma^o_k)_{k\geq 0}$, constructs a new sequence $(\gamma^i_k)_{k\geq 0}$ whose error decreases faster. In the outer level, we propose an optimal methodology for the selection of the predefined sequence $(\gamma^o_k)_{k\geq 0}$. Third, we show empirically that our selection methodology of the learning rate outperforms significantly standard algorithms used in reinforcement learning (RL) in the three following applications: the estimation of a drift, the optimal placement of limit orders and the optimal execution of large number of shares.