 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Back to Reality for Imitation Learning
Nov 25, 2021

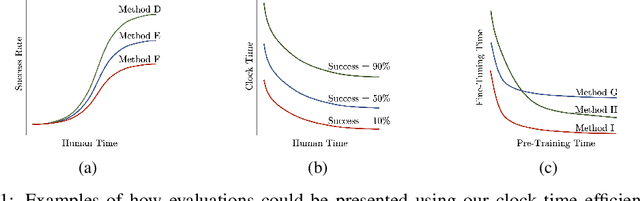

Imitation learning, and robot learning in general, emerged due to breakthroughs in machine learning, rather than breakthroughs in robotics. As such, evaluation metrics for robot learning are deeply rooted in those for machine learning, and focus primarily on data efficiency. We believe that a better metric for real-world robot learning is time efficiency, which better models the true cost to humans. This is a call to arms to the robot learning community to develop our own evaluation metrics, tailored towards the long-term goals of real-world robotics.
Self-directed Machine Learning
Jan 08, 2022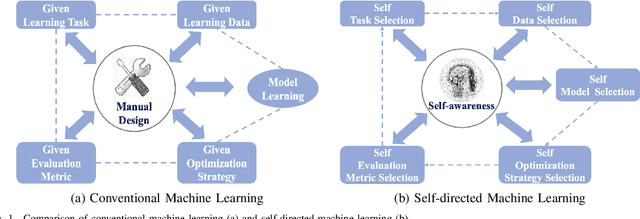
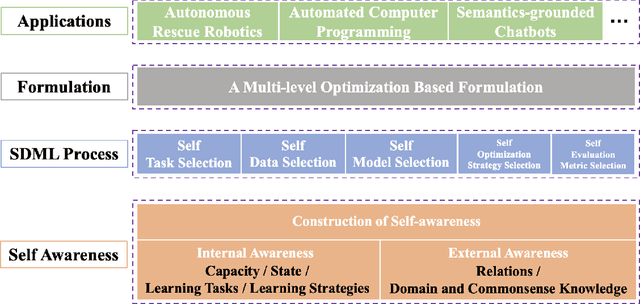
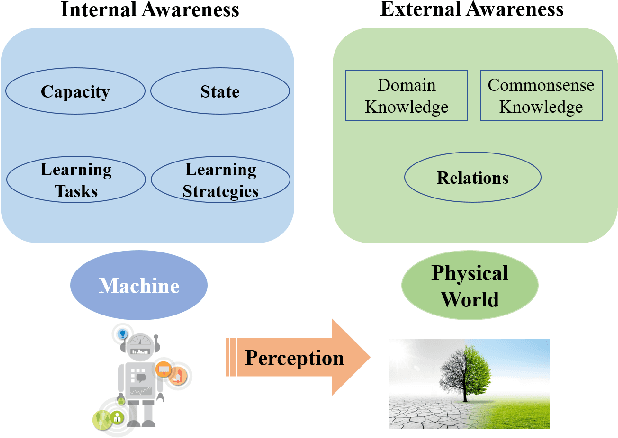
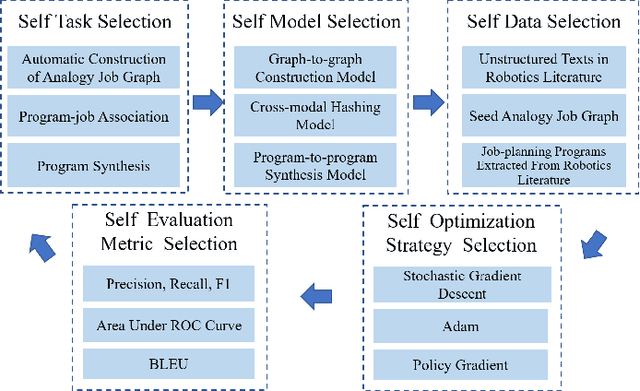
Conventional machine learning (ML) relies heavily on manual design from machine learning experts to decide learning tasks, data, models, optimization algorithms, and evaluation metrics, which is labor-intensive, time-consuming, and cannot learn autonomously like humans. In education science, self-directed learning, where human learners select learning tasks and materials on their own without requiring hands-on guidance, has been shown to be more effective than passive teacher-guided learning. Inspired by the concept of self-directed human learning, we introduce the principal concept of Self-directed Machine Learning (SDML) and propose a framework for SDML. Specifically, we design SDML as a self-directed learning process guided by self-awareness, including internal awareness and external awareness. Our proposed SDML process benefits from self task selection, self data selection, self model selection, self optimization strategy selection and self evaluation metric selection through self-awareness without human guidance. Meanwhile, the learning performance of the SDML process serves as feedback to further improve self-awareness. We propose a mathematical formulation for SDML based on multi-level optimization. Furthermore, we present case studies together with potential applications of SDML, followed by discussing future research directions. We expect that SDML could enable machines to conduct human-like self-directed learning and provide a new perspective towards artificial general intelligence.
It Is Different When Items Are Older: Debiasing Recommendations When Selection Bias and User Preferences Are Dynamic
Nov 24, 2021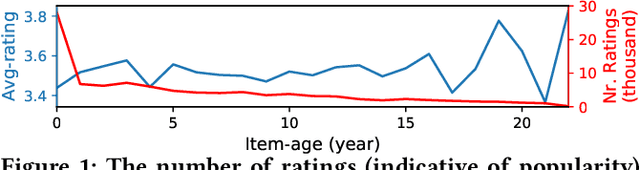
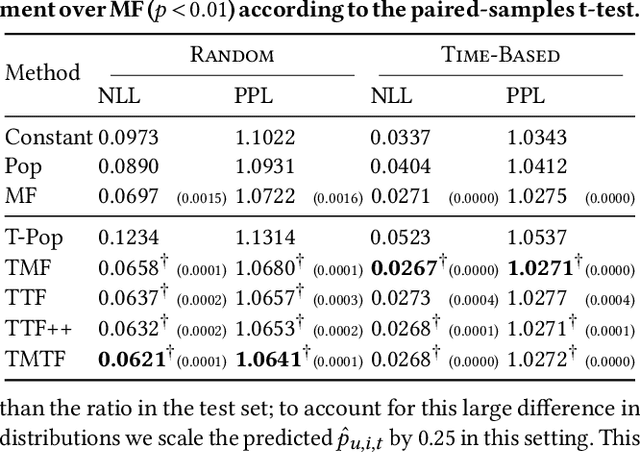
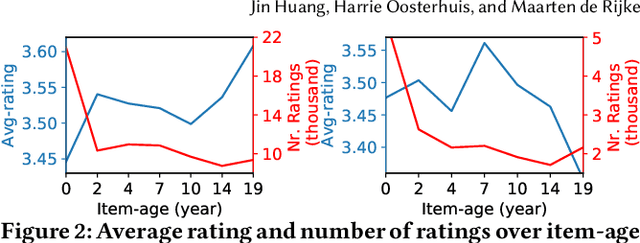
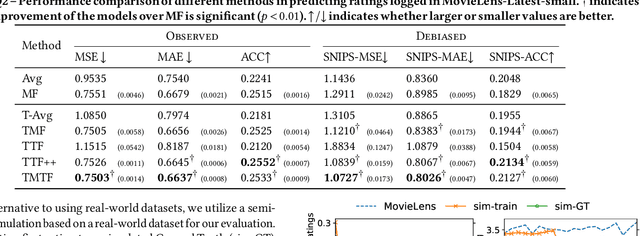
User interactions with recommender systems (RSs) are affected by user selection bias, e.g., users are more likely to rate popular items (popularity bias) or items that they expect to enjoy beforehand (positivity bias). Methods exist for mitigating the effects of selection bias in user ratings on the evaluation and optimization of RSs. However, these methods treat selection bias as static, despite the fact that the popularity of an item may change drastically over time and the fact that user preferences may also change over time. We focus on the age of an item and its effect on selection bias and user preferences. Our experimental analysis reveals that the rating behavior of users on the MovieLens dataset is better captured by methods that consider effects from the age of item on bias and preferences. We theoretically show that in a dynamic scenario in which both the selection bias and user preferences are dynamic, existing debiasing methods are no longer unbiased. To address this limitation, we introduce DebiAsing in the dyNamiC scEnaRio (DANCER), a novel debiasing method that extends the inverse propensity scoring debiasing method to account for dynamic selection bias and user preferences. Our experimental results indicate that DANCER improves rating prediction performance compared to debiasing methods that incorrectly assume that selection bias is static in a dynamic scenario. To the best of our knowledge, DANCER is the first debiasing method that accounts for dynamic selection bias and user preferences in RSs.
Swift and Sure: Hardness-aware Contrastive Learning for Low-dimensional Knowledge Graph Embeddings
Jan 03, 2022
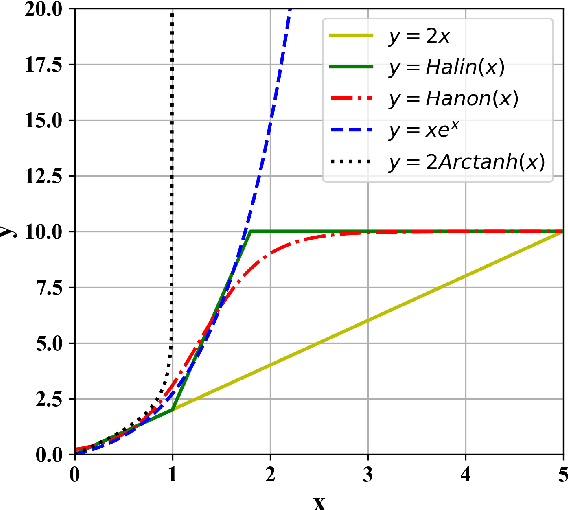
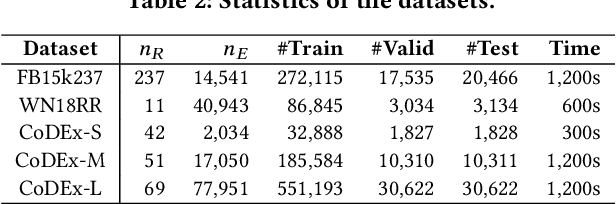
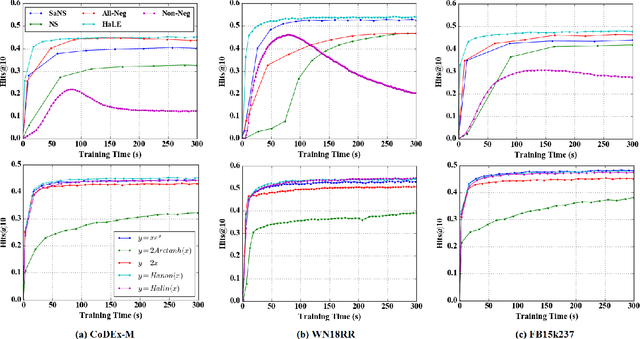
Knowledge graph embedding (KGE) has drawn great attention due to its potential in automatic knowledge graph (KG) completion and knowledge-driven tasks. However, recent KGE models suffer from high training cost and large storage space, thus limiting their practicality in real-world applications. To address this challenge, based on the latest findings in the field of Contrastive Learning, we propose a novel KGE training framework called Hardness-aware Low-dimensional Embedding (HaLE). Instead of the traditional Negative Sampling, we design a new loss function based on query sampling that can balance two important training targets, Alignment and Uniformity. Furthermore, we analyze the hardness-aware ability of recent low-dimensional hyperbolic models and propose a lightweight hardness-aware activation mechanism, which can help the KGE models focus on hard instances and speed up convergence. The experimental results show that in the limited training time, HaLE can effectively improve the performance and training speed of KGE models on five commonly-used datasets. The HaLE-trained models can obtain a high prediction accuracy after training few minutes and are competitive compared to the state-of-the-art models in both low- and high-dimensional conditions.
3D Skeleton-based Few-shot Action Recognition with JEANIE is not so Naïve
Dec 23, 2021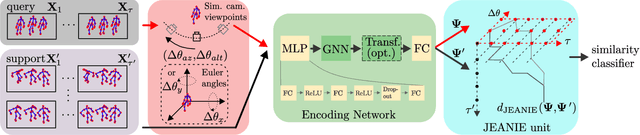
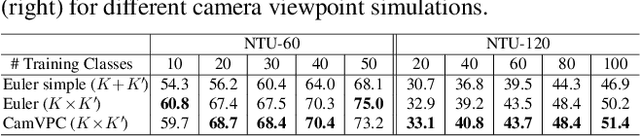
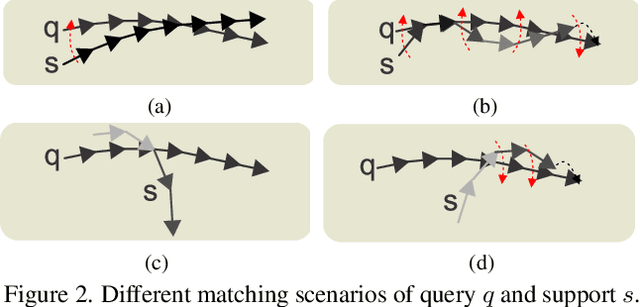
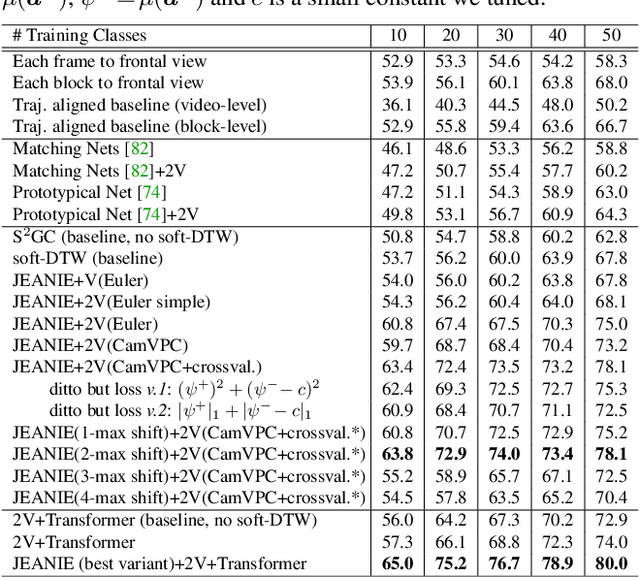
In this paper, we propose a Few-shot Learning pipeline for 3D skeleton-based action recognition by Joint tEmporal and cAmera viewpoiNt alIgnmEnt (JEANIE). To factor out misalignment between query and support sequences of 3D body joints, we propose an advanced variant of Dynamic Time Warping which jointly models each smooth path between the query and support frames to achieve simultaneously the best alignment in the temporal and simulated camera viewpoint spaces for end-to-end learning under the limited few-shot training data. Sequences are encoded with a temporal block encoder based on Simple Spectral Graph Convolution, a lightweight linear Graph Neural Network backbone (we also include a setting with a transformer). Finally, we propose a similarity-based loss which encourages the alignment of sequences of the same class while preventing the alignment of unrelated sequences. We demonstrate state-of-the-art results on NTU-60, NTU-120, Kinetics-skeleton and UWA3D Multiview Activity II.
Image-free multi-character recognition
Dec 20, 2021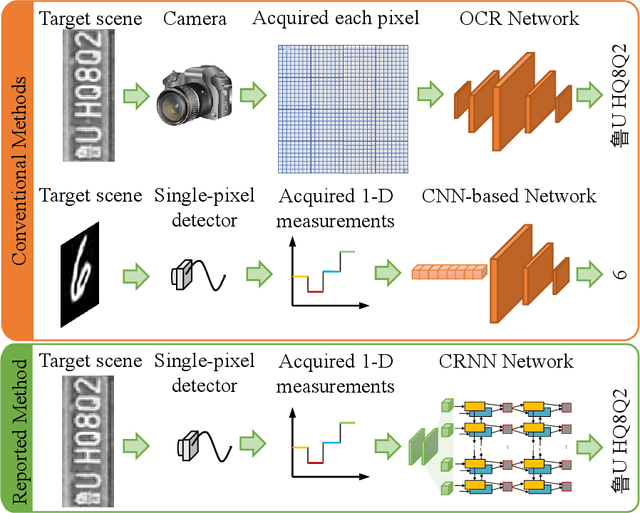
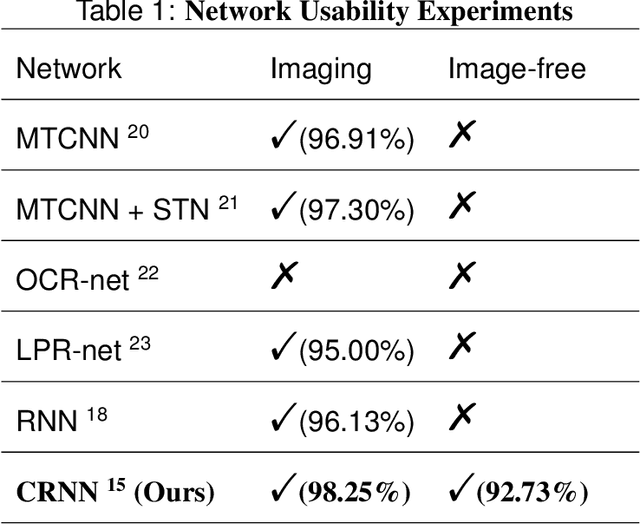
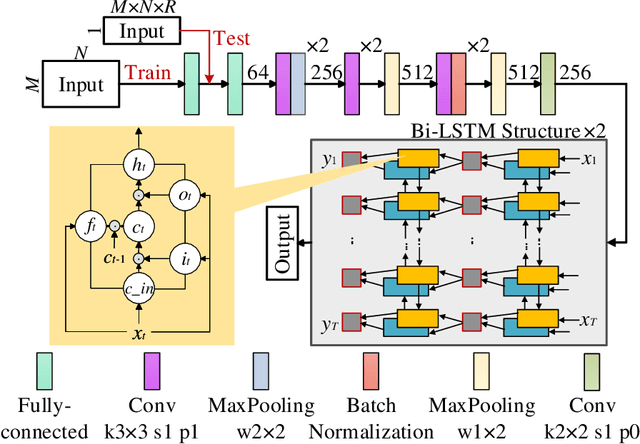
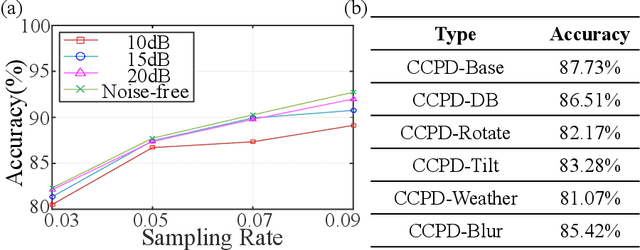
The recently developed image-free sensing technique maintains the advantages of both the light hardware and software, which has been applied in simple target classification and motion tracking. In practical applications, however, there usually exist multiple targets in the field of view, where existing trials fail to produce multi-semantic information. In this letter, we report a novel image-free sensing technique to tackle the multi-target recognition challenge for the first time. Different from the convolutional layer stack of image-free single-pixel networks, the reported CRNN network utilities the bidirectional LSTM architecture to predict the distribution of multiple characters simultaneously. The framework enables to capture the long-range dependencies, providing a high recognition accuracy of multiple characters. We demonstrated the technique's effectiveness in license plate detection, which achieved 87.60% recognition accuracy at a 5% sampling rate with a higher than 100 FPS refresh rate.
Search Strategy Formulation for Systematic Reviews: issues, challenges and opportunities
Dec 17, 2021
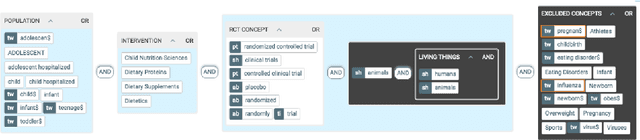
Systematic literature reviews play a vital role in identifying the best available evidence for health and social care policy. The resources required to produce systematic reviews can be significant, and a key to the success of any review is the search strategy used to identify relevant literature. However, the methods used to construct search strategies can be complex, time consuming, resource intensive and error prone. In this review, we examine the state of the art in resolving complex structured information needs, focusing primarily on the healthcare context. We analyse the literature to identify key challenges and issues and explore appropriate solutions and workarounds. From this analysis we propose a way forward to facilitate trust and transparency and to aid explainability, reproducibility and replicability through a set of key design principles for tools to support the development of search strategies in systematic literature reviews.
NetKet 3: Machine Learning Toolbox for Many-Body Quantum Systems
Dec 20, 2021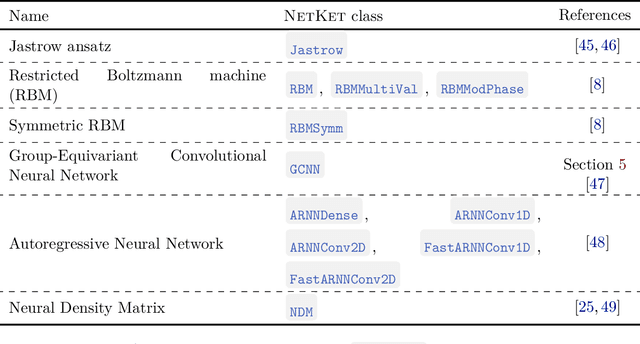
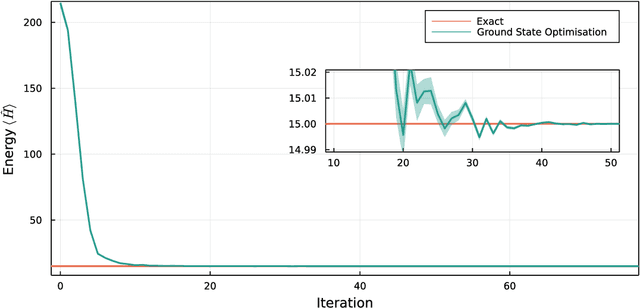
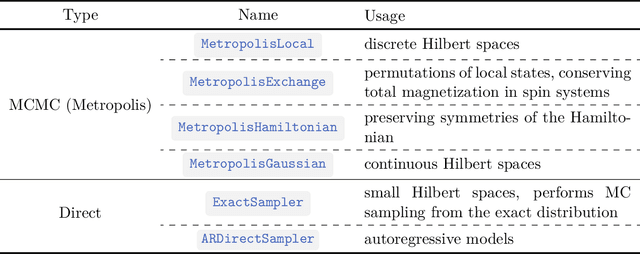
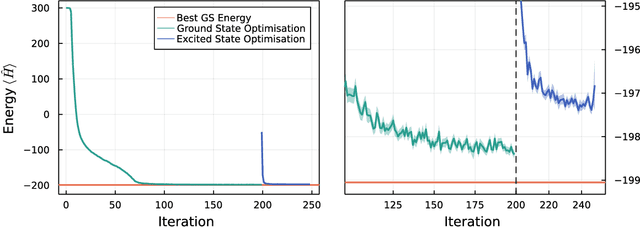
We introduce version 3 of NetKet, the machine learning toolbox for many-body quantum physics. NetKet is built around neural-network quantum states and provides efficient algorithms for their evaluation and optimization. This new version is built on top of JAX, a differentiable programming and accelerated linear algebra framework for the Python programming language. The most significant new feature is the possibility to define arbitrary neural network ans\"atze in pure Python code using the concise notation of machine-learning frameworks, which allows for just-in-time compilation as well as the implicit generation of gradients thanks to automatic differentiation. NetKet 3 also comes with support for GPU and TPU accelerators, advanced support for discrete symmetry groups, chunking to scale up to thousands of degrees of freedom, drivers for quantum dynamics applications, and improved modularity, allowing users to use only parts of the toolbox as a foundation for their own code.
Virtual Replay Cache
Dec 06, 2021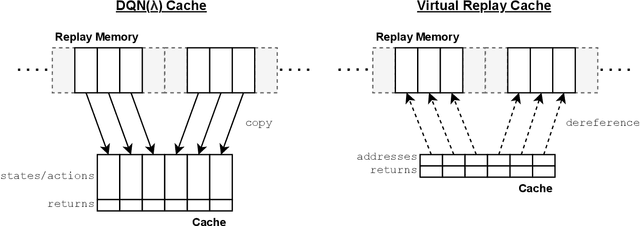
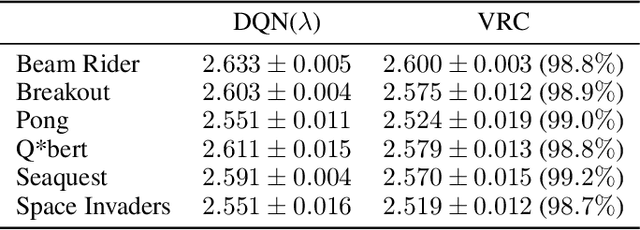

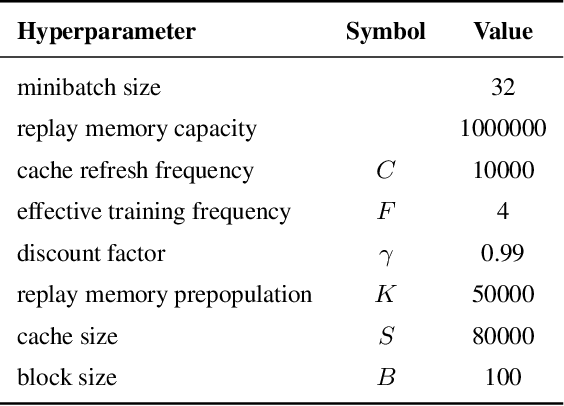
Return caching is a recent strategy that enables efficient minibatch training with multistep estimators (e.g. the {\lambda}-return) for deep reinforcement learning. By precomputing return estimates in sequential batches and then storing the results in an auxiliary data structure for later sampling, the average computation spent per estimate can be greatly reduced. Still, the efficiency of return caching could be improved, particularly with regard to its large memory usage and repetitive data copies. We propose a new data structure, the Virtual Replay Cache (VRC), to address these shortcomings. When learning to play Atari 2600 games, the VRC nearly eliminates DQN({\lambda})'s cache memory footprint and slightly reduces the total training time on our hardware.
Dynamic Bayesian Network Modelling of User Affect and Perceptions of a Teleoperated Robot Coach during Longitudinal Mindfulness Training
Dec 06, 2021
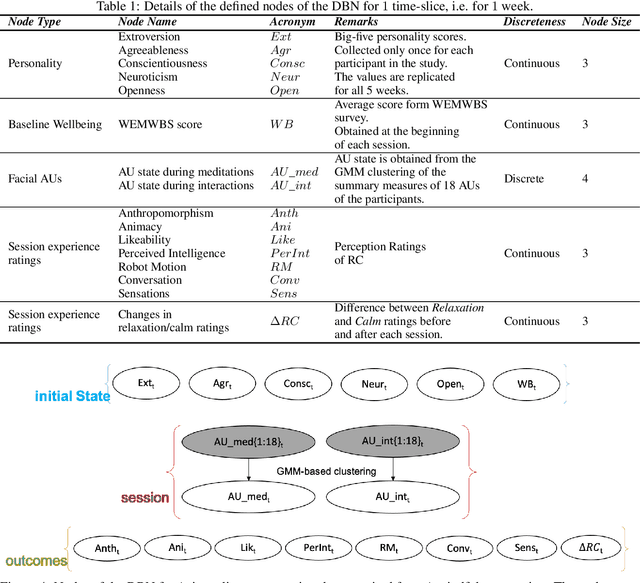

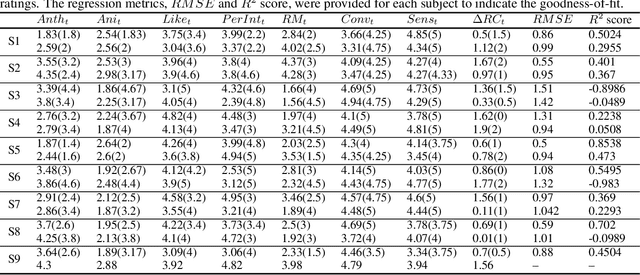
Longitudinal interaction studies with Socially Assistive Robots are crucial to ensure that the robot is relevant for long-term use and its perceptions are not prone to the novelty effect. In this paper, we present a dynamic Bayesian network (DBN) to capture the longitudinal interactions participants had with a teleoperated robot coach (RC) delivering mindfulness sessions. The DBN model is used to study complex, temporal interactions between the participants self-reported personality traits, weekly baseline wellbeing scores, session ratings, and facial AUs elicited during the sessions in a 5-week longitudinal study. DBN modelling involves learning a graphical representation that facilitates intuitive understanding of how multiple components contribute to the longitudinal changes in session ratings corresponding to the perceptions of the RC, and participants relaxation and calm levels. The learnt model captures the following within and between sessions aspects of the longitudinal interaction study: influence of the 5 personality dimensions on the facial AU states and the session ratings, influence of facial AU states on the session ratings, and the influences within the items of the session ratings. The DBN structure is learnt using first 3 time points and the obtained model is used to predict the session ratings of the last 2 time points of the 5-week longitudinal data. The predictions are quantified using subject-wise RMSE and R2 scores. We also demonstrate two applications of the model, namely, imputation of missing values in the dataset and estimation of longitudinal session ratings of a new participant with a given personality profile. The obtained DBN model thus facilitates learning of conditional dependency structure between variables in the longitudinal data and offers inferences and conceptual understanding which are not possible through other regression methodologies.