 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Dose Plugin Towards Real-time Monte Carlo Dose Calculation Through a Deep Learning based Denoising Algorithm
Nov 30, 2020
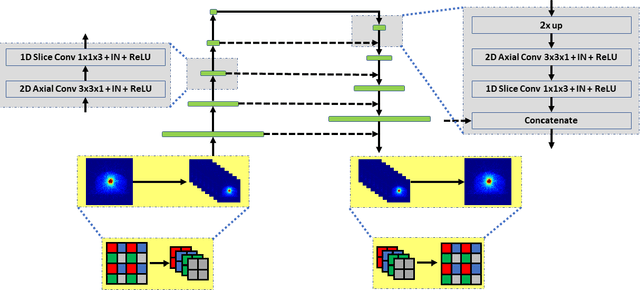

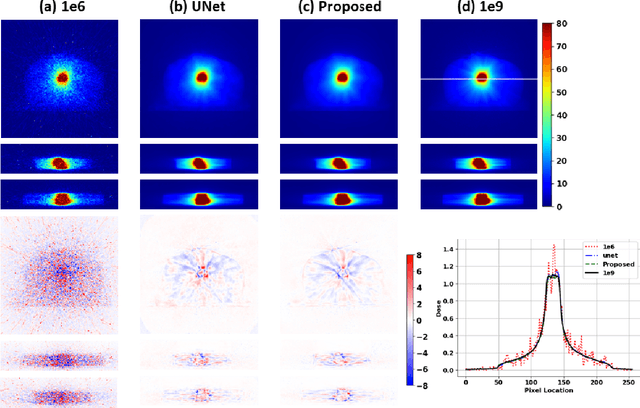
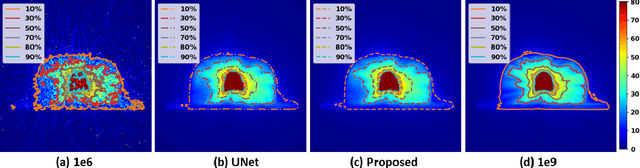
Monte Carlo (MC) simulation is considered the gold standard method for radiotherapy dose calculation. However, achieving high precision requires a large number of simulation histories, which is time consuming. The use of computer graphics processing units (GPUs) has greatly accelerated MC simulation and allows dose calculation within a few minutes for a typical radiotherapy treatment plan. However, some clinical applications demand real time efficiency for MC dose calculation. To tackle this problem, we have developed a real time, deep learning based dose denoiser that can be plugged into a current GPU based MC dose engine to enable real time MC dose calculation. We used two different acceleration strategies to achieve this goal: 1) we applied voxel unshuffle and voxel shuffle operators to decrease the input and output sizes without any information loss, and 2) we decoupled the 3D volumetric convolution into a 2D axial convolution and a 1D slice convolution. In addition, we used a weakly supervised learning framework to train the network, which greatly reduces the size of the required training dataset and thus enables fast fine tuning based adaptation of the trained model to different radiation beams. Experimental results show that the proposed denoiser can run in as little as 39 ms, which is around 11.6 times faster than the baseline model. As a result, the whole MC dose calculation pipeline can be finished within 0.15 seconds, including both GPU MC dose calculation and deep learning based denoising, achieving the real time efficiency needed for some radiotherapy applications, such as online adaptive radiotherapy.
Sparse Graph Learning with Eigen-gap for Spectral Filter Training in Graph Convolutional Networks
Feb 28, 2022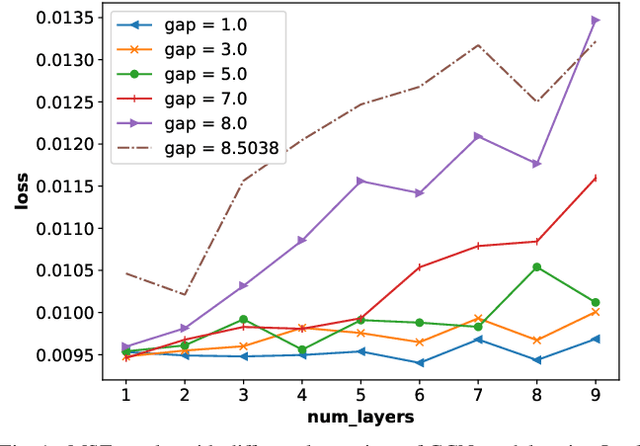
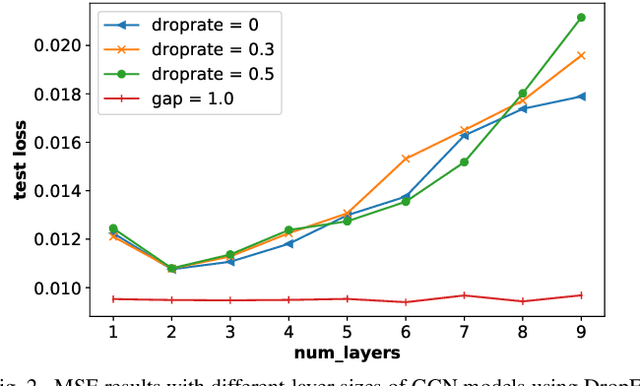
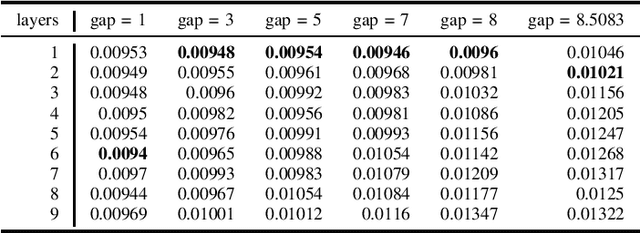
It is now known that the expressive power of graph convolutional neural nets (GCN) does not grow infinitely with the number of layers. Instead, the GCN output approaches a subspace spanned by the first eigenvector of the normalized graph Laplacian matrix with the convergence rate characterized by the "eigen-gap": the difference between the Laplacian's first two distinct eigenvalues. To promote a deeper GCN architecture with sufficient expressiveness, in this paper, given an empirical covariance matrix $\bar{C}$ computed from observable data, we learn a sparse graph Laplacian matrix $L$ closest to $\bar{C}^{-1}$ while maintaining a desirable eigen-gap that slows down convergence. Specifically, we first define a sparse graph learning problem with constraints on the first eigenvector (the most common signal) and the eigen-gap. We solve the corresponding dual problem greedily, where a locally optimal eigen-pair is computed one at a time via a fast approximation of a semi-definite programming (SDP) formulation. The computed $L$ with the desired eigen-gap is normalized spectrally and used for supervised training of GCN for a targeted task. Experiments show that our proposal produced deeper GCNs and smaller errors compared to a competing scheme without explicit eigen-gap optimization.
An Evolutionary Game for Mobile User Access Mode Selection in sub-$6$ GHz/mmWave Cellular Networks
Jan 10, 2022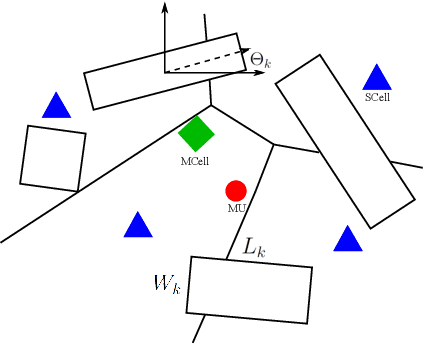
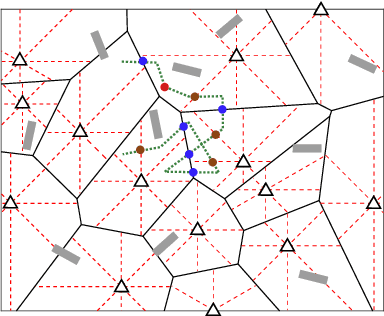
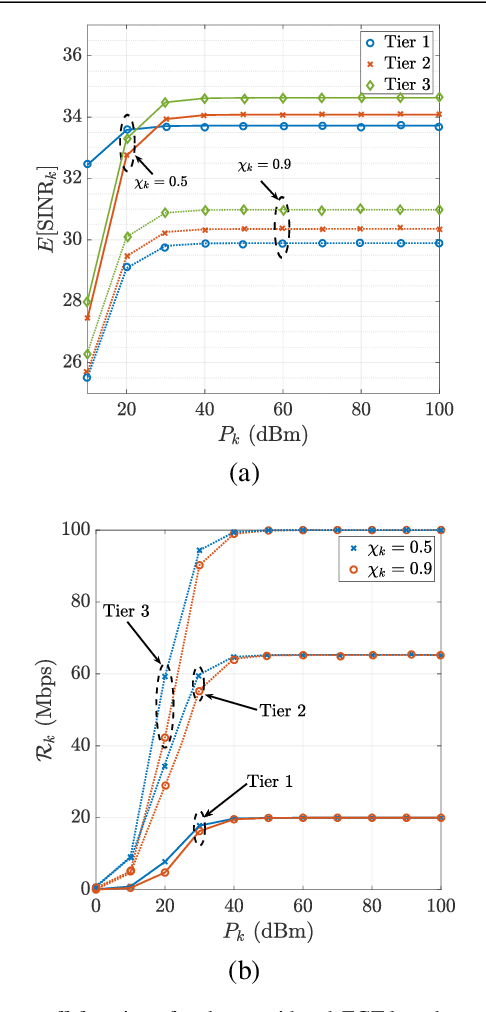
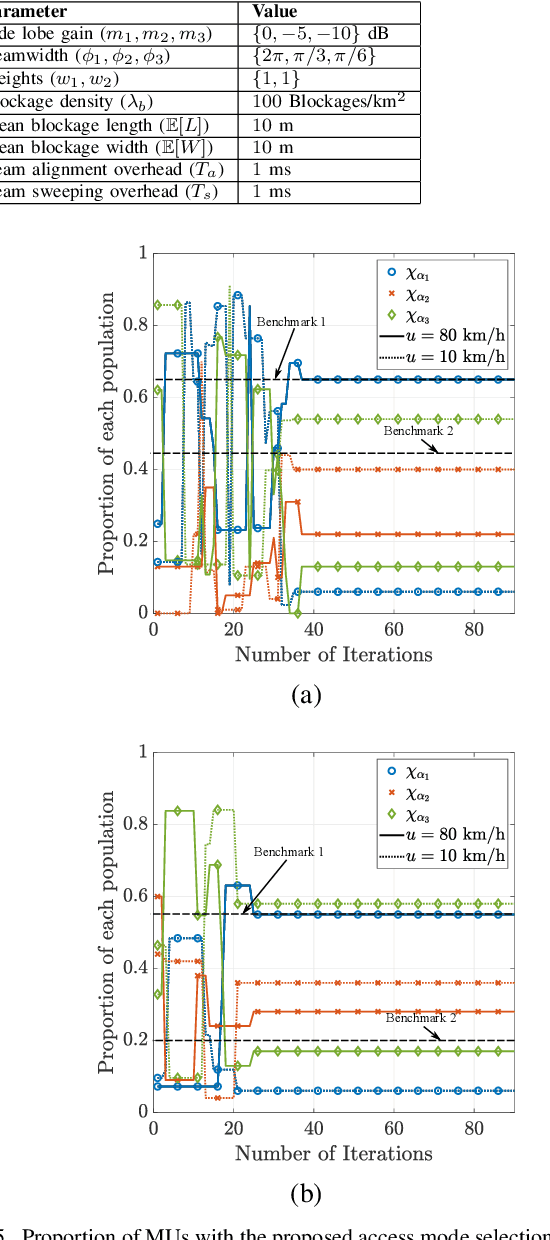
By utilizing the combination of two powerful tools i.e., stochastic geometry (SG) and evolutionary game theory (EGT), in this paper, we study the problem of mobile user (MU) mode selection in heterogeneous sub-$6$ GHz/millimeter wave (mmWave) cellular networks. Particularly, by using SG tools, we first propose an analytical framework to assess the performance of the considered networks in terms of average signal-to-interference-plus-noise (SINR) ratio, average rate, and mobility-induced time overhead, for scenarios with user mobility{.} According to the SG-based framework, an EGT-based approach is presented to solve the problem of access mode selection. Specifically, two EGT-based models are considered, where for each MU its utility function depends on the average SINR and the average rate, respectively, while the time overhead is considered as a penalty term. A distributed algorithm is proposed to reach the evolutionary equilibrium, where the existence and stability of the equilibrium is theoretically analyzed and proved. Moreover, we extend the formulation by considering information delay exchange and evaluate its impact on the convergence of the proposed algorithm. Our results reveal that the proposed technique can offer better spectral efficiency and connectivity in heterogeneous sub-$6$ GHz/mmWave cellular networks with mobility, compared with the conventional access mode selection techniques.
Set Functions for Time Series
Sep 26, 2019
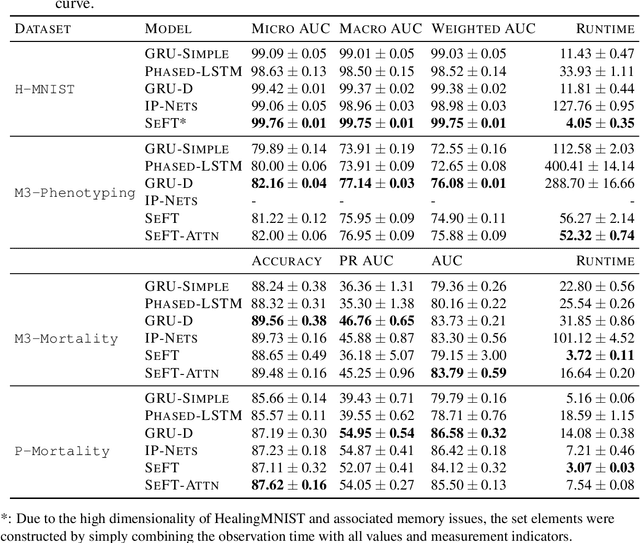
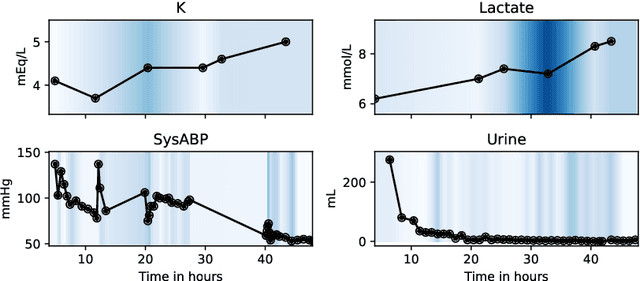
Despite the eminent successes of deep neural networks, many architectures are often hard to transfer to irregularly-sampled and asynchronous time series that occur in many real-world datasets, such as healthcare applications. This paper proposes a novel framework for classifying irregularly sampled time series with unaligned measurements, focusing on high scalability and data efficiency. Our method SEFT (Set Functions for Time Series) is based on recent advances in differentiable set function learning, extremely parallelizable, and scales well to very large datasets and online monitoring scenarios. We extensively compare our method to competitors on multiple healthcare time series datasets and show that it performs competitively whilst significantly reducing runtime.
Towards Scale Consistent Monocular Visual Odometry by Learning from the Virtual World
Mar 11, 2022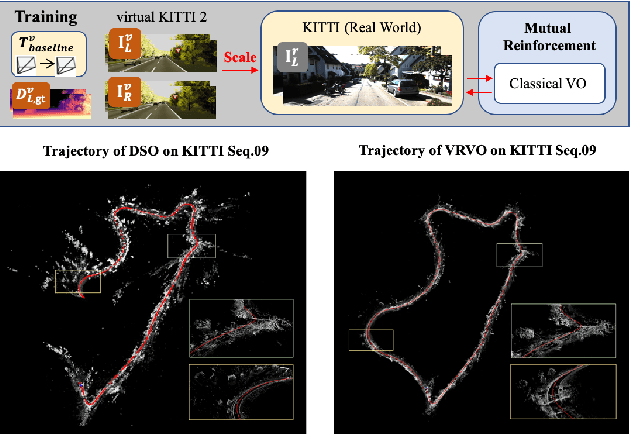
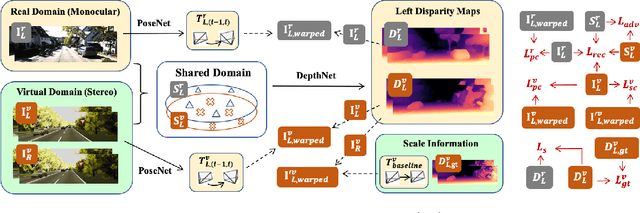
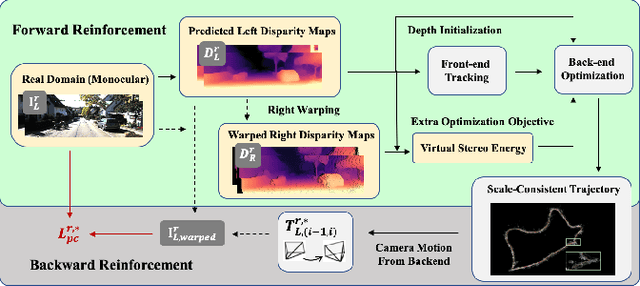
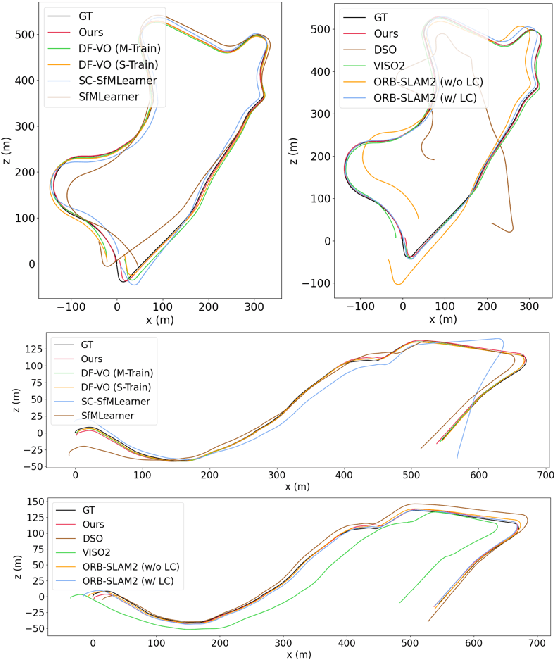
Monocular visual odometry (VO) has attracted extensive research attention by providing real-time vehicle motion from cost-effective camera images. However, state-of-the-art optimization-based monocular VO methods suffer from the scale inconsistency problem for long-term predictions. Deep learning has recently been introduced to address this issue by leveraging stereo sequences or ground-truth motions in the training dataset. However, it comes at an additional cost for data collection, and such training data may not be available in all datasets. In this work, we propose VRVO, a novel framework for retrieving the absolute scale from virtual data that can be easily obtained from modern simulation environments, whereas in the real domain no stereo or ground-truth data are required in either the training or inference phases. Specifically, we first train a scale-aware disparity network using both monocular real images and stereo virtual data. The virtual-to-real domain gap is bridged by using an adversarial training strategy to map images from both domains into a shared feature space. The resulting scale-consistent disparities are then integrated with a direct VO system by constructing a virtual stereo objective that ensures the scale consistency over long trajectories. Additionally, to address the suboptimality issue caused by the separate optimization backend and the learning process, we further propose a mutual reinforcement pipeline that allows bidirectional information flow between learning and optimization, which boosts the robustness and accuracy of each other. We demonstrate the effectiveness of our framework on the KITTI and vKITTI2 datasets.
Towards Bi-directional Skip Connections in Encoder-Decoder Architectures and Beyond
Mar 11, 2022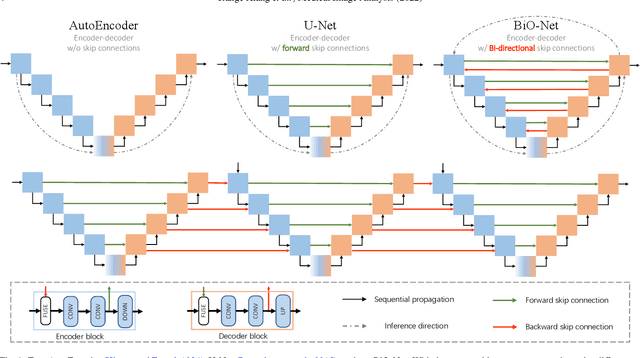
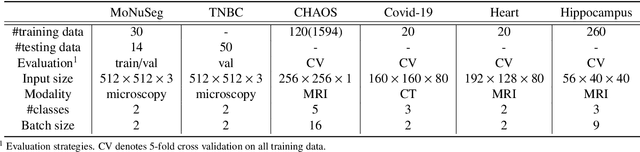
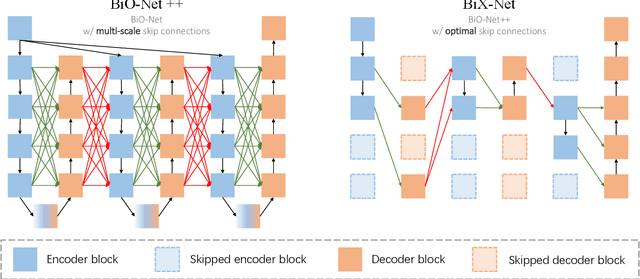
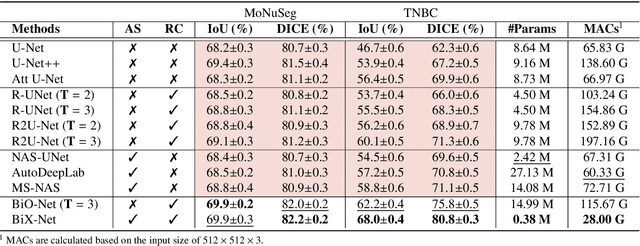
U-Net, as an encoder-decoder architecture with forward skip connections, has achieved promising results in various medical image analysis tasks. Many recent approaches have also extended U-Net with more complex building blocks, which typically increase the number of network parameters considerably. Such complexity makes the inference stage highly inefficient for clinical applications. Towards an effective yet economic segmentation network design, in this work, we propose backward skip connections that bring decoded features back to the encoder. Our design can be jointly adopted with forward skip connections in any encoder-decoder architecture forming a recurrence structure without introducing extra parameters. With the backward skip connections, we propose a U-Net based network family, namely Bi-directional O-shape networks, which set new benchmarks on multiple public medical imaging segmentation datasets. On the other hand, with the most plain architecture (BiO-Net), network computations inevitably increase along with the pre-set recurrence time. We have thus studied the deficiency bottleneck of such recurrent design and propose a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS, to search for the best multi-scale bi-directional skip connections. The ineffective skip connections are then discarded to reduce computational costs and speed up network inference. The finally searched BiX-Net yields the least network complexity and outperforms other state-of-the-art counterparts by large margins. We evaluate our methods on both 2D and 3D segmentation tasks in a total of six datasets. Extensive ablation studies have also been conducted to provide a comprehensive analysis for our proposed methods.
System-reliability based multi-ensemble of GAN and one-class joint Gaussian distributions for unsupervised real-time structural health monitoring
Feb 01, 2021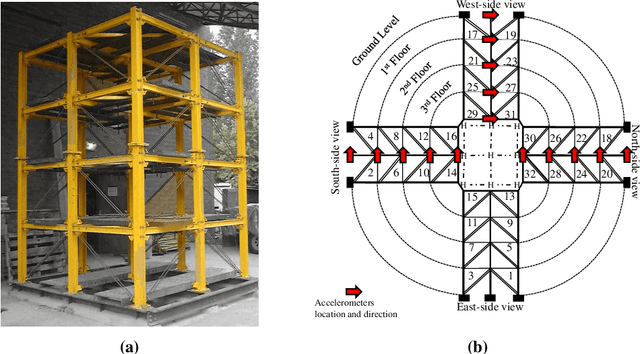
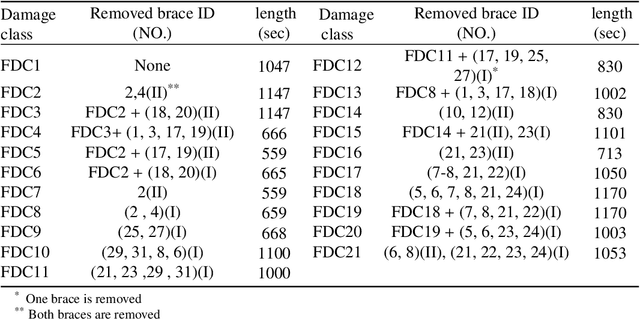
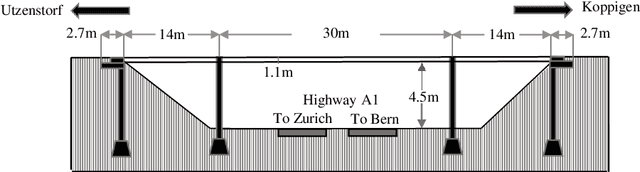
Unsupervised health monitoring has gained much attention in the last decade as the most practical real-time structural health monitoring (SHM) approach. Among the proposed unsupervised techniques in the literature, there are still obstacles to robust and real-time health monitoring. These barriers include loss of information from dimensionality reduction in feature extraction steps, case-dependency of those steps, lack of a dynamic clustering, and detection results' sensitivity to user-defined parameters. This study introduces an unsupervised real-time SHM method with a mixture of low- and high-dimensional features without a case-dependent extraction scheme. Both features are used to train multi-ensembles of Generative Adversarial Networks (GAN) and one-class joint Gaussian distribution models (1-CG). A novelty detection system of limit-state functions based on GAN and 1-CG models' detection scores is constructed. The Resistance of those limit-state functions (detection thresholds) is tuned to user-defined parameters with the GAN-generated data objects by employing the Monte Carlo histogram sampling through a reliability-based analysis. The tuning makes the method robust to user-defined parameters, which is crucial as there is no rule for selecting those parameters in a real-time SHM. The proposed novelty detection framework is applied to two standard SHM datasets to illustrate its generalizability: Yellow Frame (twenty damage classes) and Z24 Bridge (fifteen damage classes). All different damage categories are identified with low sensitivity to the initial choice of user-defined parameters with both introduced dynamic and static baseline approaches with few or no false alarms.
Learning-based Localizability Estimation for Robust LiDAR Localization
Mar 11, 2022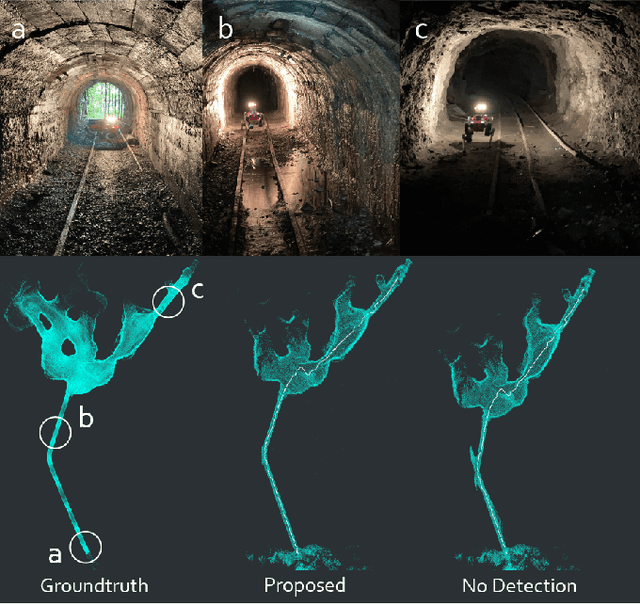
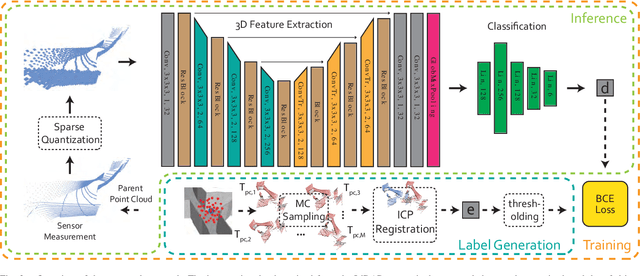
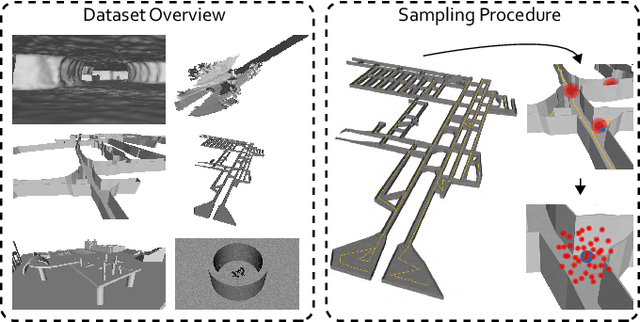
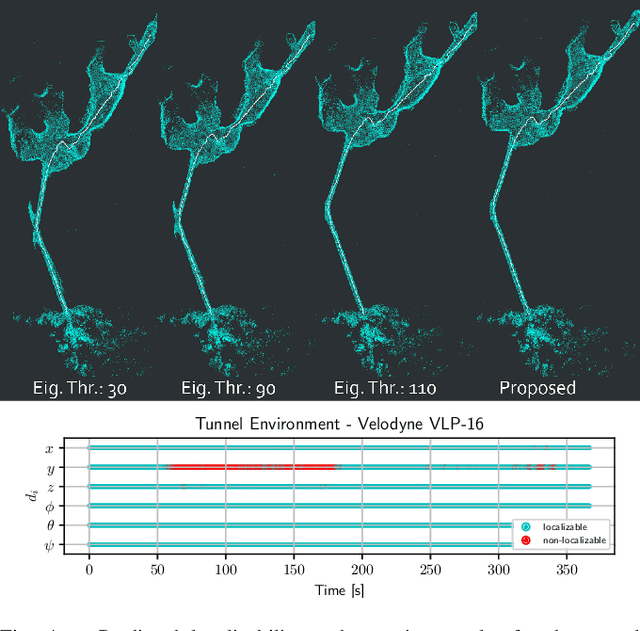
LiDAR-based localization and mapping is one of the core components in many modern robotic systems due to the direct integration of range and geometry, allowing for precise motion estimation and generation of high quality maps in real-time. Yet, as a consequence of insufficient environmental constraints present in the scene, this dependence on geometry can result in localization failure, happening in self-symmetric surroundings such as tunnels. This work addresses precisely this issue by proposing a neural network-based estimation approach for detecting (non-)localizability during robot operation. Special attention is given to the localizability of scan-to-scan registration, as it is a crucial component in many LiDAR odometry estimation pipelines. In contrast to previous, mostly traditional detection approaches, the proposed method enables early detection of failure by estimating the localizability on raw sensor measurements without evaluating the underlying registration optimization. Moreover, previous approaches remain limited in their ability to generalize across environments and sensor types, as heuristic-tuning of degeneracy detection thresholds is required. The proposed approach avoids this problem by learning from a corpus of different environments, allowing the network to function over various scenarios. Furthermore, the network is trained exclusively on simulated data, avoiding arduous data collection in challenging and degenerate, often hard-to-access, environments. The presented method is tested during field experiments conducted across challenging environments and on two different sensor types without any modifications. The observed detection performance is on par with state-of-the-art methods after environment-specific threshold tuning.
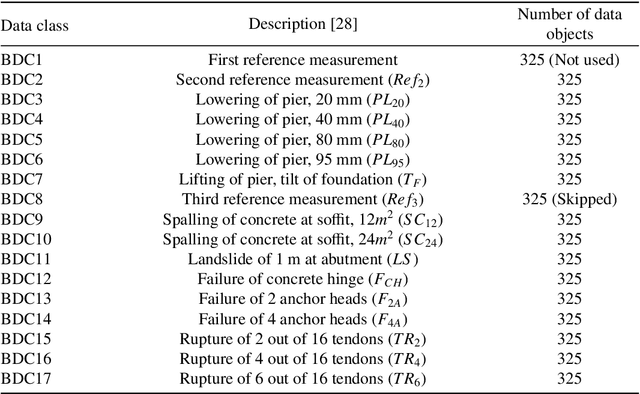
Estimating the electrical power output of industrial devices with end-to-end time-series classification in the presence of label noise
May 01, 2021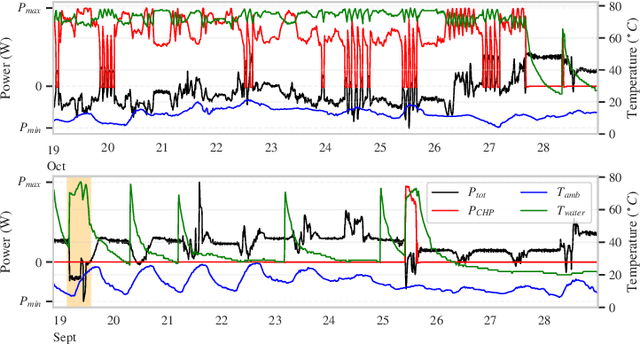
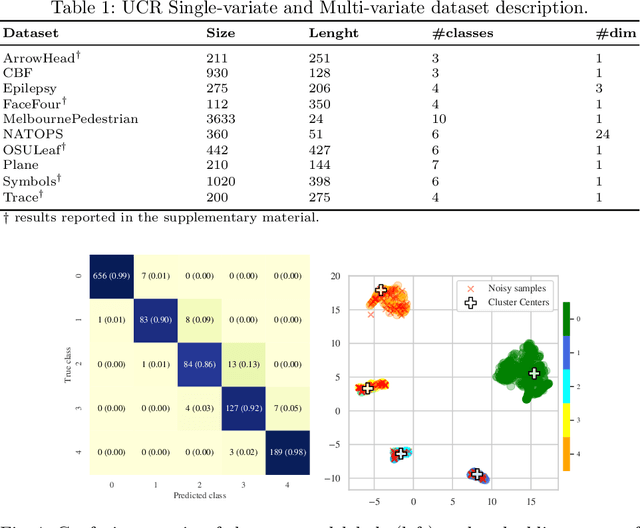
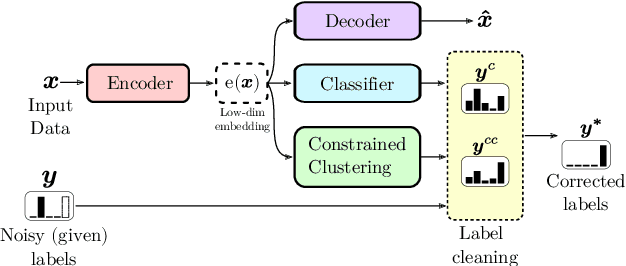
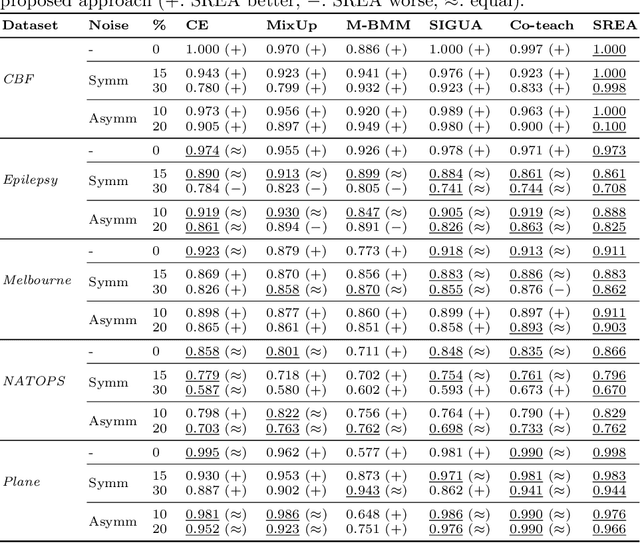
In complex industrial settings, it is common practice to monitor the operation of machines in order to detect undesired states, adjust maintenance schedules, optimize system performance or collect usage statistics of individual machines. In this work, we focus on estimating the power output of a Combined Heat and Power (CHP) machine of a medium-sized company facility by analyzing the total facility power consumption. We formulate the problem as a time-series classification problem where the class label represents the CHP power output. As the facility is fully instrumented and sensor measurements from the CHP are available, we generate the training labels in an automated fashion from the CHP sensor readings. However, sensor failures result in mislabeled training data samples which are hard to detect and remove from the dataset. Therefore, we propose a novel multi-task deep learning approach that jointly trains a classifier and an autoencoder with a shared embedding representation. The proposed approach targets to gradually correct the mislabelled data samples during training in a self-supervised fashion, without any prior assumption on the amount of label noise. We benchmark our approach on several time-series classification datasets and find it to be comparable and sometimes better than state-of-the-art methods. On the real-world use-case of predicting the CHP power output, we thoroughly evaluate the architectural design choices and show that the final architecture considerably increases the robustness of the learning process and consistently beats other recent state-of-the-art algorithms in the presence of unstructured as well as structured label noise.
iLabel: Interactive Neural Scene Labelling
Nov 29, 2021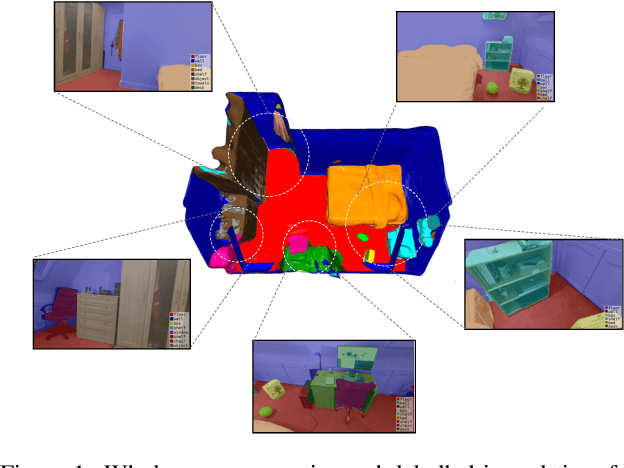
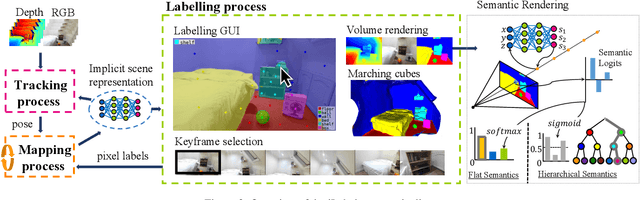
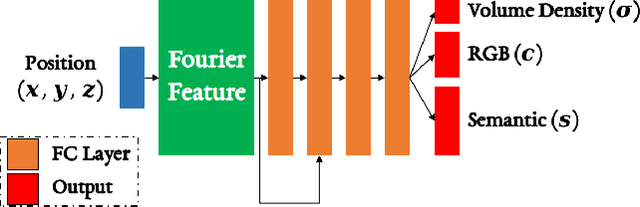
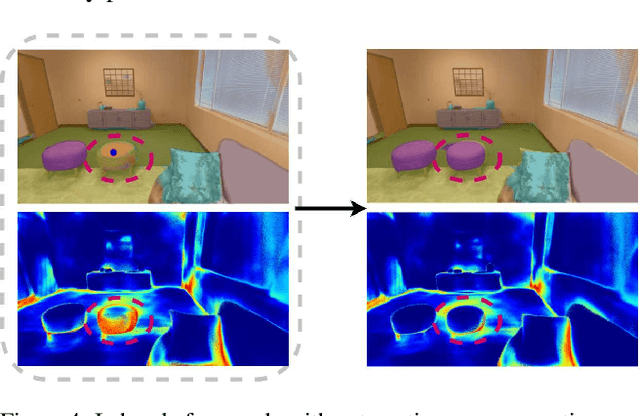
Joint representation of geometry, colour and semantics using a 3D neural field enables accurate dense labelling from ultra-sparse interactions as a user reconstructs a scene in real-time using a handheld RGB-D sensor. Our iLabel system requires no training data, yet can densely label scenes more accurately than standard methods trained on large, expensively labelled image datasets. Furthermore, it works in an 'open set' manner, with semantic classes defined on the fly by the user. iLabel's underlying model is a multilayer perceptron (MLP) trained from scratch in real-time to learn a joint neural scene representation. The scene model is updated and visualised in real-time, allowing the user to focus interactions to achieve efficient labelling. A room or similar scene can be accurately labelled into 10+ semantic categories with only a few tens of clicks. Quantitative labelling accuracy scales powerfully with the number of clicks, and rapidly surpasses standard pre-trained semantic segmentation methods. We also demonstrate a hierarchical labelling variant.