 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Practical Conditional Neural Processes Via Tractable Dependent Predictions
Mar 16, 2022

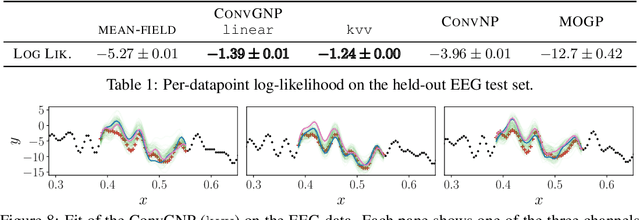
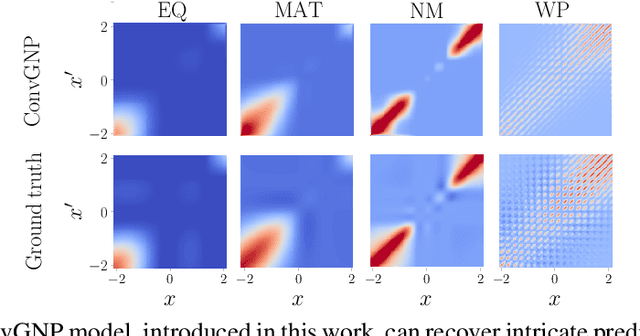

Conditional Neural Processes (CNPs; Garnelo et al., 2018a) are meta-learning models which leverage the flexibility of deep learning to produce well-calibrated predictions and naturally handle off-the-grid and missing data. CNPs scale to large datasets and train with ease. Due to these features, CNPs appear well-suited to tasks from environmental sciences or healthcare. Unfortunately, CNPs do not produce correlated predictions, making them fundamentally inappropriate for many estimation and decision making tasks. Predicting heat waves or floods, for example, requires modelling dependencies in temperature or precipitation over time and space. Existing approaches which model output dependencies, such as Neural Processes (NPs; Garnelo et al., 2018b) or the FullConvGNP (Bruinsma et al., 2021), are either complicated to train or prohibitively expensive. What is needed is an approach which provides dependent predictions, but is simple to train and computationally tractable. In this work, we present a new class of Neural Process models that make correlated predictions and support exact maximum likelihood training that is simple and scalable. We extend the proposed models by using invertible output transformations, to capture non-Gaussian output distributions. Our models can be used in downstream estimation tasks which require dependent function samples. By accounting for output dependencies, our models show improved predictive performance on a range of experiments with synthetic and real data.
Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation
Mar 04, 2022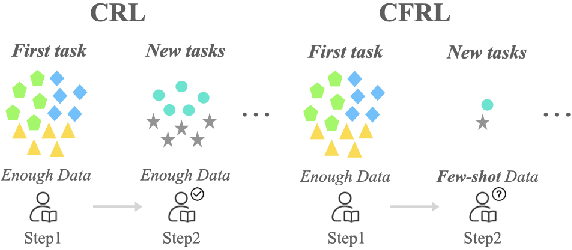
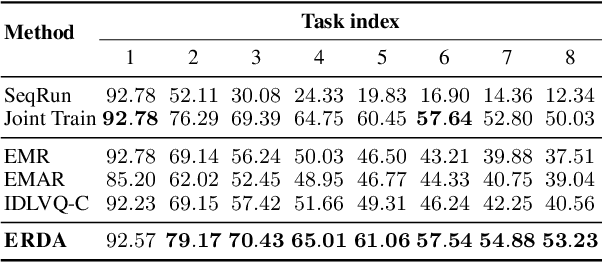
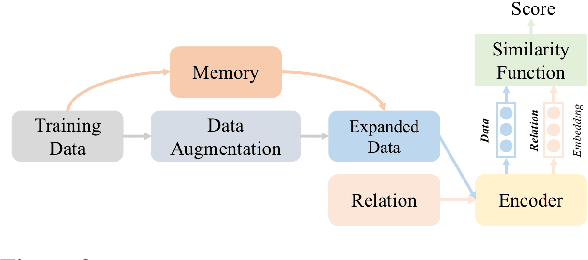

Existing continual relation learning (CRL) methods rely on plenty of labeled training data for learning a new task, which can be hard to acquire in real scenario as getting large and representative labeled data is often expensive and time-consuming. It is therefore necessary for the model to learn novel relational patterns with very few labeled data while avoiding catastrophic forgetting of previous task knowledge. In this paper, we formulate this challenging yet practical problem as continual few-shot relation learning (CFRL). Based on the finding that learning for new emerging few-shot tasks often results in feature distributions that are incompatible with previous tasks' learned distributions, we propose a novel method based on embedding space regularization and data augmentation. Our method generalizes to new few-shot tasks and avoids catastrophic forgetting of previous tasks by enforcing extra constraints on the relational embeddings and by adding extra {relevant} data in a self-supervised manner. With extensive experiments we demonstrate that our method can significantly outperform previous state-of-the-art methods in CFRL task settings.
Adaptive Sign Algorithm for Graph Signal Processing
Jan 15, 2022
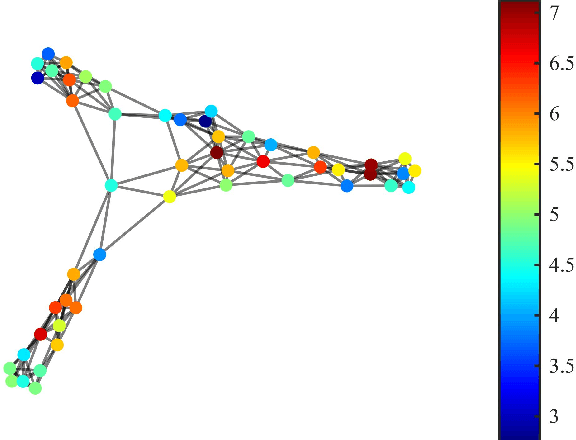
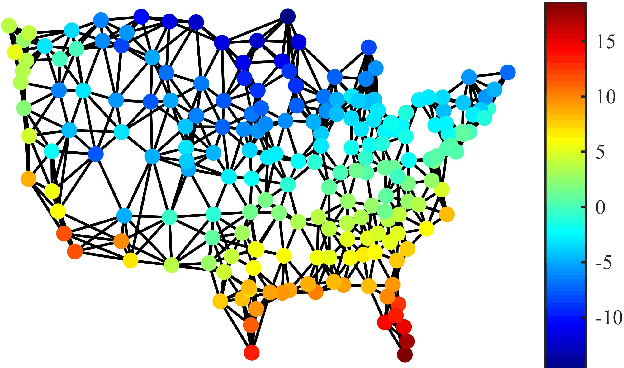
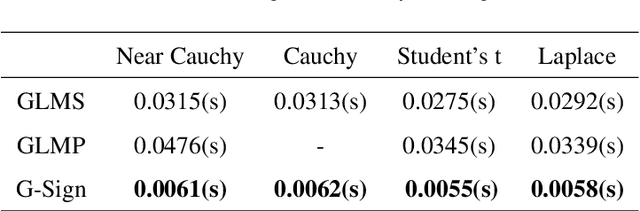
Efficient and robust online processing technique of irregularly structured data is crucial in the current era of data abundance. In this paper, we propose a graph/network version of the classical adaptive Sign algorithm for online graph signal estimation under impulsive noise. Recently introduced graph adaptive least mean squares algorithm is unstable under non-Gaussian impulsive noise and has high computational complexity. The Graph-Sign algorithm proposed in this work is based on the minimum dispersion criterion and therefore impulsive noise does not hinder its estimation quality. Unlike the recently proposed graph adaptive least mean p-th power algorithm, our Graph-Sign algorithm can operate without prior knowledge of the noise distribution. The proposed Graph-Sign algorithm has a faster run time because of its low computational complexity compared to the existing adaptive graph signal processing algorithms. Experimenting on steady-state and time-varying graph signals estimation utilizing spectral properties of bandlimitedness and sampling, the Graph-Sign algorithm demonstrates fast, stable, and robust graph signal estimation performance under impulsive noise modeled by alpha stable, Cauchy, Student's t, or Laplace distributions.
Tuning-free multi-coil compressed sensing MRI with Parallel Variable Density Approximate Message Passing (P-VDAMP)
Mar 08, 2022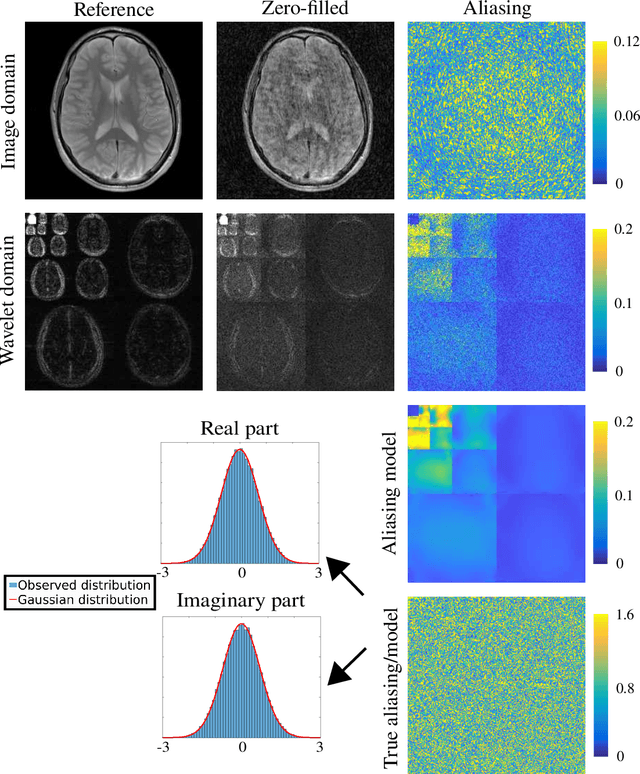


Purpose: To develop a tuning-free method for multi-coil compressed sensing MRI that performs competitively with algorithms with an optimally tuned sparse parameter. Theory: The Parallel Variable Density Approximate Message Passing (P-VDAMP) algorithm is proposed. For Bernoulli random variable density sampling, P-VDAMP obeys a "state evolution", where the intermediate per-iteration image estimate is distributed according to the ground truth corrupted by a Gaussian vector with approximately known covariance. State evolution is leveraged to automatically tune sparse parameters on-the-fly with Stein's Unbiased Risk Estimate (SURE). Methods: P-VDAMP is evaluated on brain, knee and angiogram datasets at acceleration factors 5 and 10 and compared with four variants of the Fast Iterative Shrinkage-Thresholding algorithm (FISTA), including two tuning-free variants from the literature. Results: The proposed method is found to have a similar reconstruction quality and time to convergence as FISTA with an optimally tuned sparse weighting. Conclusions: P-VDAMP is an efficient, robust and principled method for on-the-fly parameter tuning that is competitive with optimally tuned FISTA and offers substantial robustness and reconstruction quality improvements over competing tuning-free methods.
Architectures and Synchronization Techniques for Distributed Satellite Systems: A Survey
Mar 16, 2022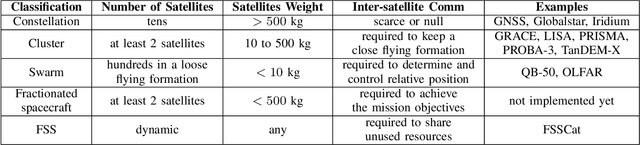
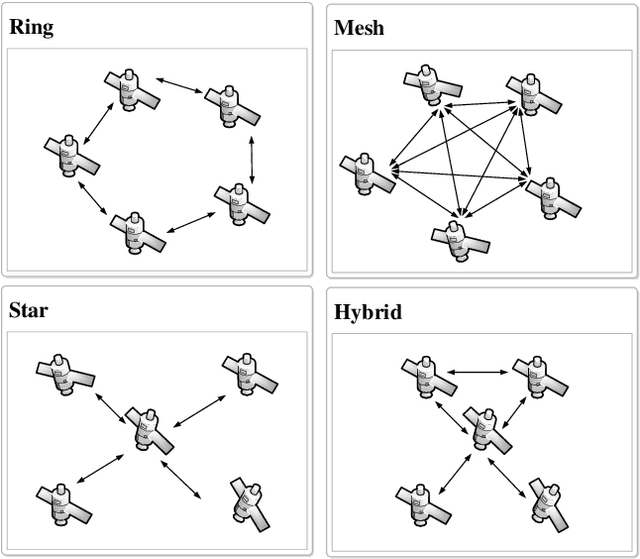
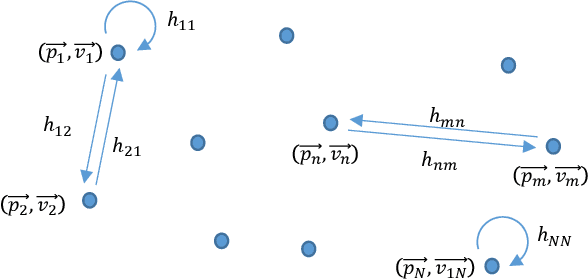
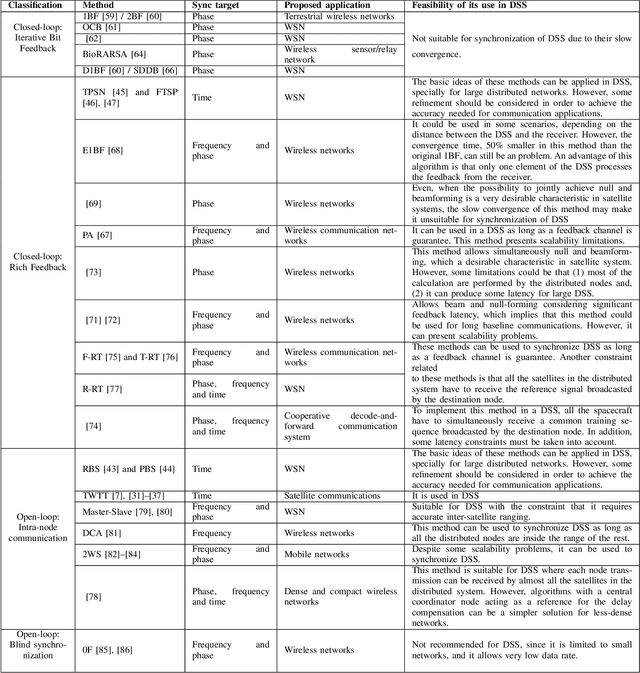
Cohesive Distributed Satellite Systems (CDSS) is a key enabling technology for the future of remote sensing and communication missions. However, they have to meet strict synchronization requirements before their use is generalized. When clock or local oscillator signals are generated locally at each of the distributed nodes, achieving exact synchronization in absolute phase, frequency, and time is a complex problem. In addition, satellite systems have significant resource constraints, especially for small satellites, which are envisioned to be part of the future CDSS. Thus, the development of precise, robust, and resource-efficient synchronization techniques is essential for the advancement of future CDSS. In this context, this survey aims to summarize and categorize the most relevant results on synchronization techniques for DSS. First, some important architecture and system concepts are defined. Then, the synchronization methods reported in the literature are reviewed and categorized. This article also provides an extensive list of applications and examples of synchronization techniques for DSS in addition to the most significant advances in other operations closely related to synchronization, such as inter-satellite ranging and relative position. The survey also provides a discussion on emerging data-driven synchronization techniques based on ML. Finally, a compilation of current research activities and potential research topics is proposed, identifying problems and open challenges that can be useful for researchers in the field.
ZOOMER: Boosting Retrieval on Web-scale Graphs by Regions of Interest
Mar 20, 2022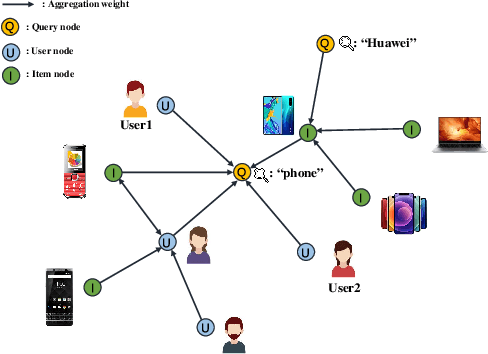
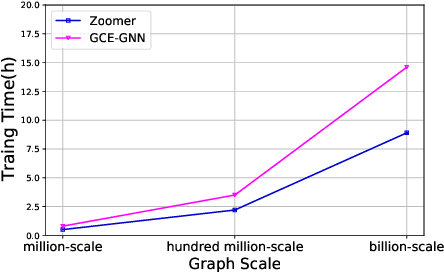
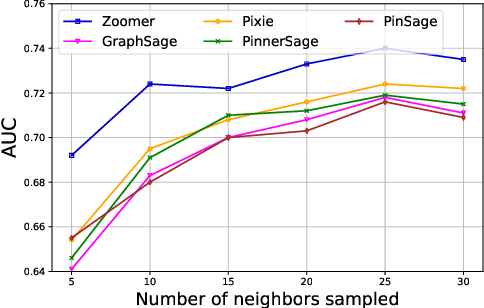
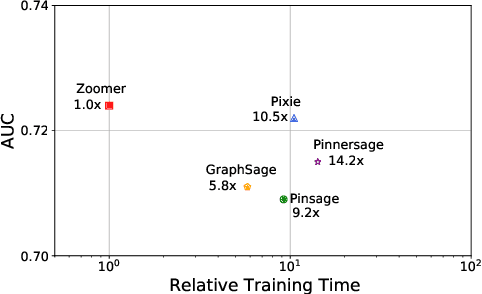
We introduce ZOOMER, a system deployed at Taobao, the largest e-commerce platform in China, for training and serving GNN-based recommendations over web-scale graphs. ZOOMER is designed for tackling two challenges presented by the massive user data at Taobao: low training/serving efficiency due to the huge scale of the graphs, and low recommendation quality due to the information overload which distracts the recommendation model from specific user intentions. ZOOMER achieves this by introducing a key concept, Region of Interests (ROI) in GNNs for recommendations, i.e., a neighborhood region in the graph with significant relevance to a strong user intention. ZOOMER narrows the focus from the whole graph and "zooms in" on the more relevant ROIs, thereby reducing the training/serving cost and mitigating the information overload at the same time. With carefully designed mechanisms, ZOOMER identifies the interest expressed by each recommendation request, constructs an ROI subgraph by sampling with respect to the interest, and guides the GNN to reweigh different parts of the ROI towards the interest by a multi-level attention module. Deployed as a large-scale distributed system, ZOOMER supports graphs with billions of nodes for training and thousands of requests per second for serving. ZOOMER achieves up to 14x speedup when downsizing sampling scales with comparable (even better) AUC performance than baseline methods. Besides, both the offline evaluation and online A/B test demonstrate the effectiveness of ZOOMER.
$β$-DARTS: Beta-Decay Regularization for Differentiable Architecture Search
Mar 04, 2022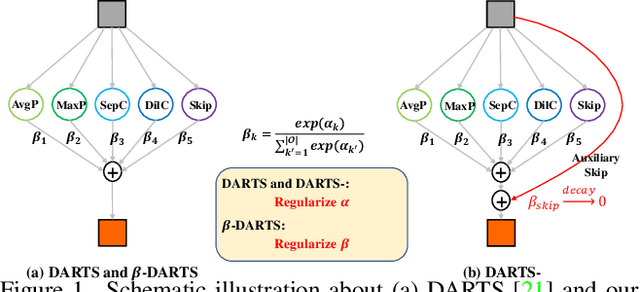
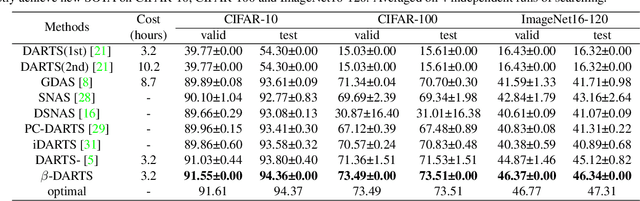
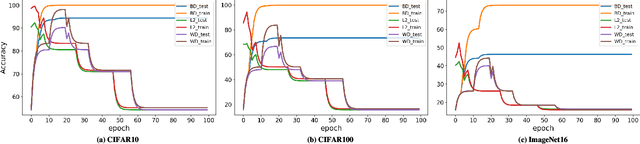
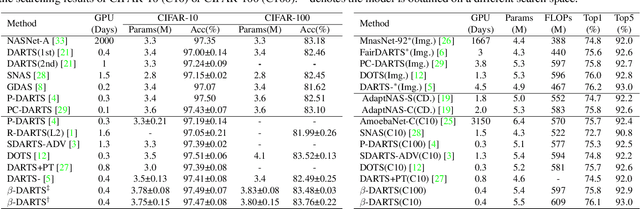
Neural Architecture Search~(NAS) has attracted increasingly more attention in recent years because of its capability to design deep neural networks automatically. Among them, differential NAS approaches such as DARTS, have gained popularity for the search efficiency. However, they suffer from two main issues, the weak robustness to the performance collapse and the poor generalization ability of the searched architectures. To solve these two problems, a simple-but-efficient regularization method, termed as Beta-Decay, is proposed to regularize the DARTS-based NAS searching process. Specifically, Beta-Decay regularization can impose constraints to keep the value and variance of activated architecture parameters from too large. Furthermore, we provide in-depth theoretical analysis on how it works and why it works. Experimental results on NAS-Bench-201 show that our proposed method can help to stabilize the searching process and makes the searched network more transferable across different datasets. In addition, our search scheme shows an outstanding property of being less dependent on training time and data. Comprehensive experiments on a variety of search spaces and datasets validate the effectiveness of the proposed method.
SQuadMDS: a lean Stochastic Quartet MDS improving global structure preservation in neighbor embedding like t-SNE and UMAP
Feb 24, 2022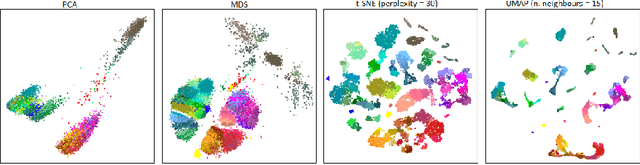
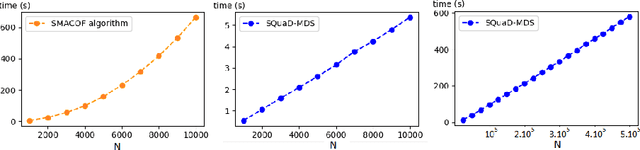
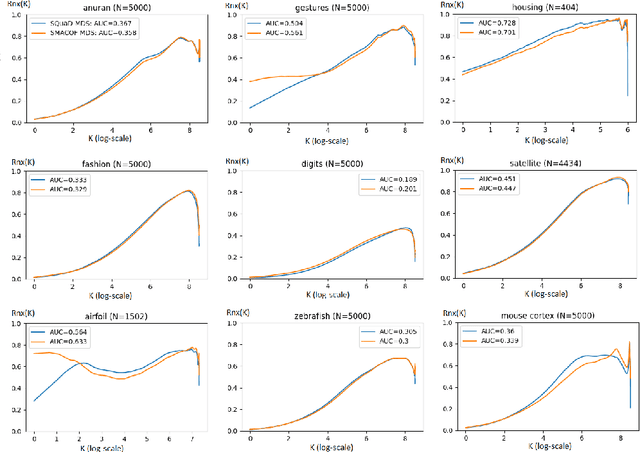
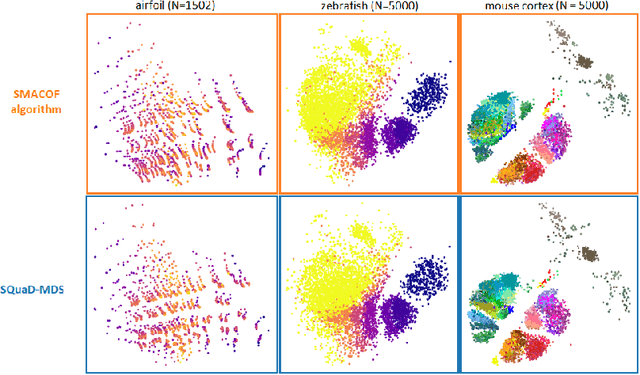
Multidimensional scaling is a statistical process that aims to embed high dimensional data into a lower-dimensional space; this process is often used for the purpose of data visualisation. Common multidimensional scaling algorithms tend to have high computational complexities, making them inapplicable on large data sets. This work introduces a stochastic, force directed approach to multidimensional scaling with a time and space complexity of O(N), with N data points. The method can be combined with force directed layouts of the family of neighbour embedding such as t-SNE, to produce embeddings that preserve both the global and the local structures of the data. Experiments assess the quality of the embeddings produced by the standalone version and its hybrid extension both quantitatively and qualitatively, showing competitive results outperforming state-of-the-art approaches. Codes are available at https://github.com/PierreLambert3/SQuaD-MDS-and-FItSNE-hybrid.
Research on Patch Attentive Neural Process
Jan 29, 2022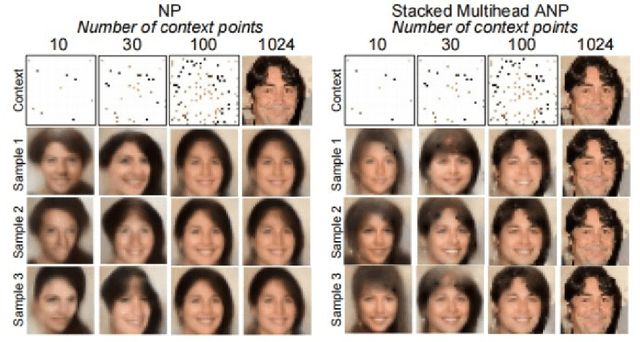
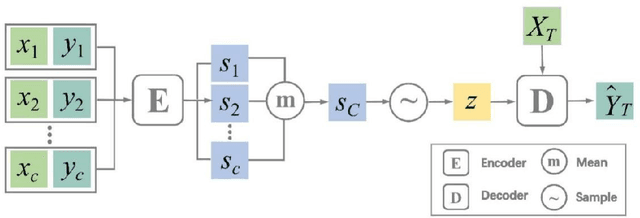
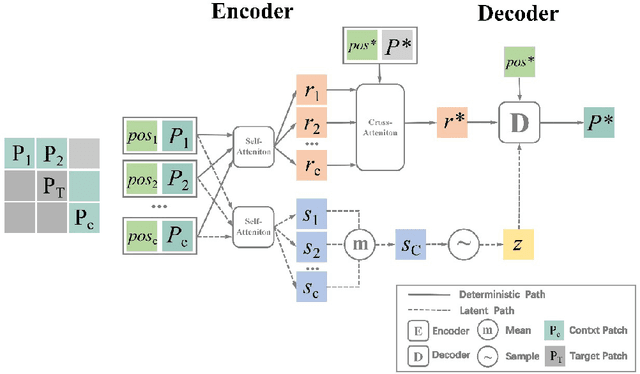
Attentive Neural Process (ANP) improves the fitting ability of Neural Process (NP) and improves its prediction accuracy, but the higher time complexity of the model imposes a limitation on the length of the input sequence. Inspired by models such as Vision Transformer (ViT) and Masked Auto-Encoder (MAE), we propose Patch Attentive Neural Process (PANP) using image patches as input and improve the structure of deterministic paths based on ANP, which allows the model to extract image features more accurately and efficiently reconstruction.
Regulations Aware Motion Planning for Autonomous Surface Vessels in Urban Canals
Feb 24, 2022
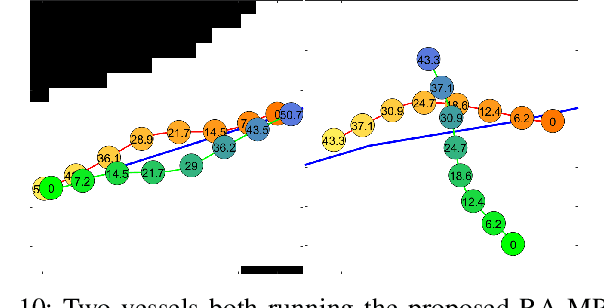
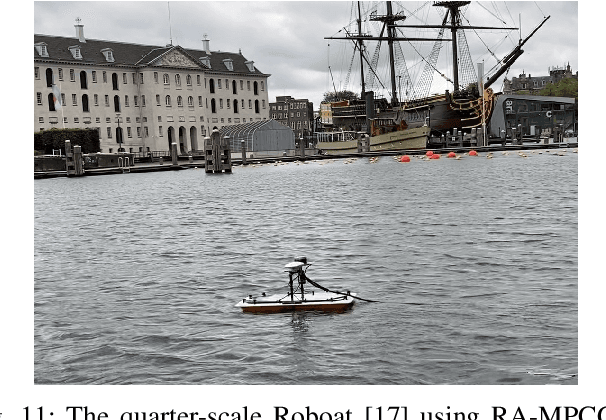
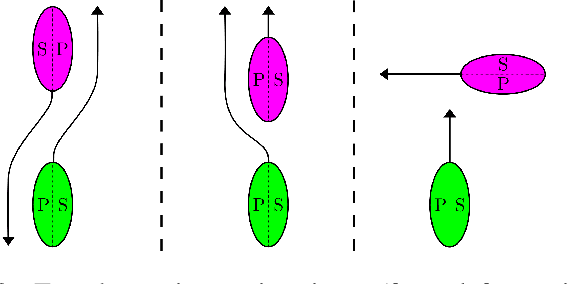
In unstructured urban canals, regulation-aware interactions with other vessels are essential for collision avoidance and social compliance. In this paper, we propose a regulations aware motion planning framework for Autonomous Surface Vessels (ASVs) that accounts for dynamic and static obstacles. Our method builds upon local model predictive contouring control (LMPCC) to generate motion plans satisfying kino-dynamic and collision constraints in real-time while including regulation awareness. To incorporate regulations in the planning stage, we propose a cost function encouraging compliance with rules describing interactions with other vessels similar to COLlision avoidance REGulations at sea (COLREGs). These regulations are essential to make an ASV behave in a predictable and socially compliant manner with regard to other vessels. We compare the framework against baseline methods and show more effective regulation-compliance avoidance of moving obstacles with our motion planner. Additionally, we present experimental results in an outdoor environment