 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Instantaneous Physiological Estimation using Video Transformers
Feb 24, 2022
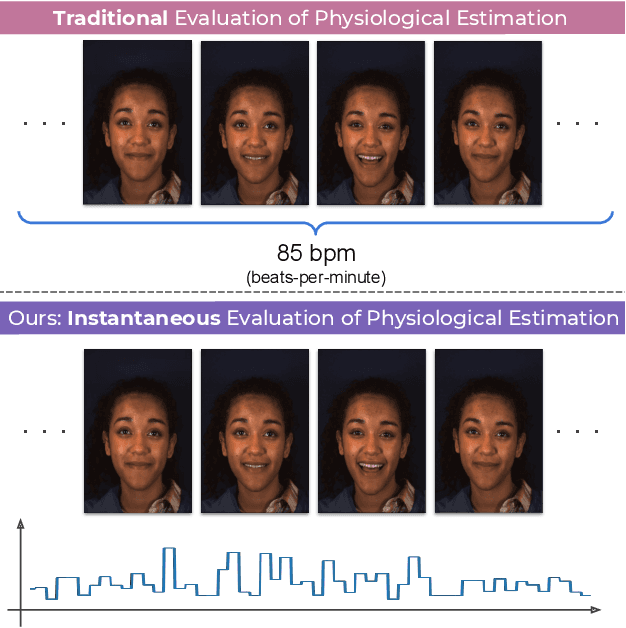
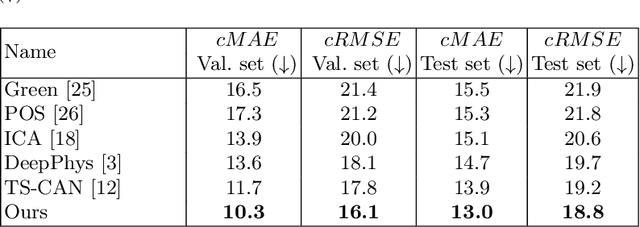
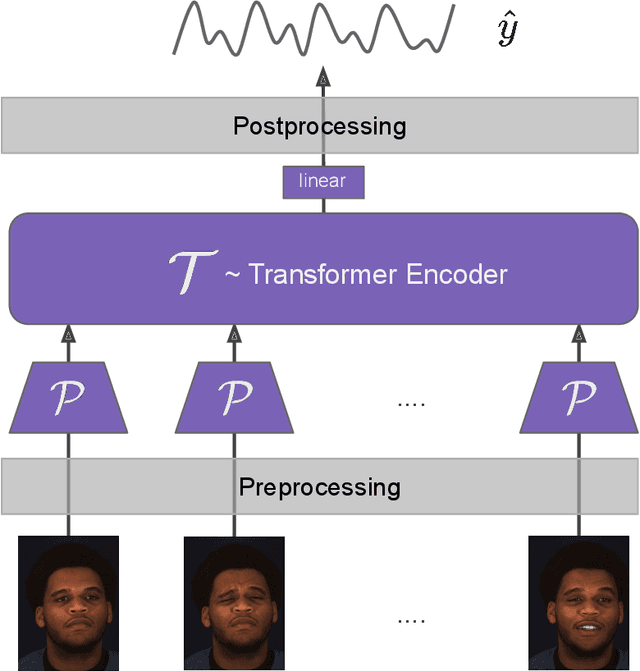
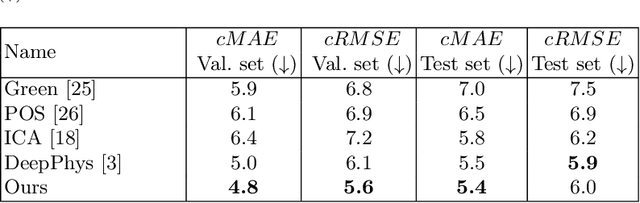
Video-based physiological signal estimation has been limited primarily to predicting episodic scores in windowed intervals. While these intermittent values are useful, they provide an incomplete picture of patients' physiological status and may lead to late detection of critical conditions. We propose a video Transformer for estimating instantaneous heart rate and respiration rate from face videos. Physiological signals are typically confounded by alignment errors in space and time. To overcome this, we formulated the loss in the frequency domain. We evaluated the method on the large scale Vision-for-Vitals (V4V) benchmark. It outperformed both shallow and deep learning based methods for instantaneous respiration rate estimation. In the case of heart-rate estimation, it achieved an instantaneous-MAE of 13.0 beats-per-minute.
Nash Neural Networks : Inferring Utilities from Optimal Behaviour
Mar 25, 2022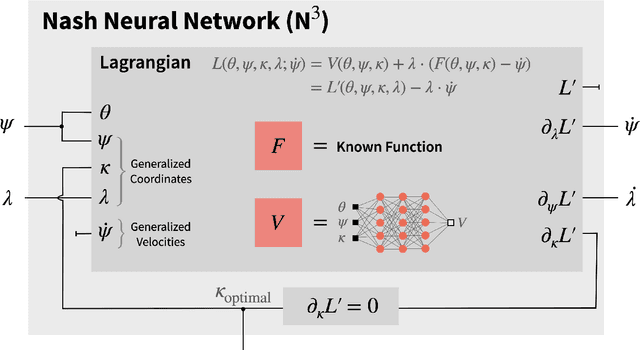
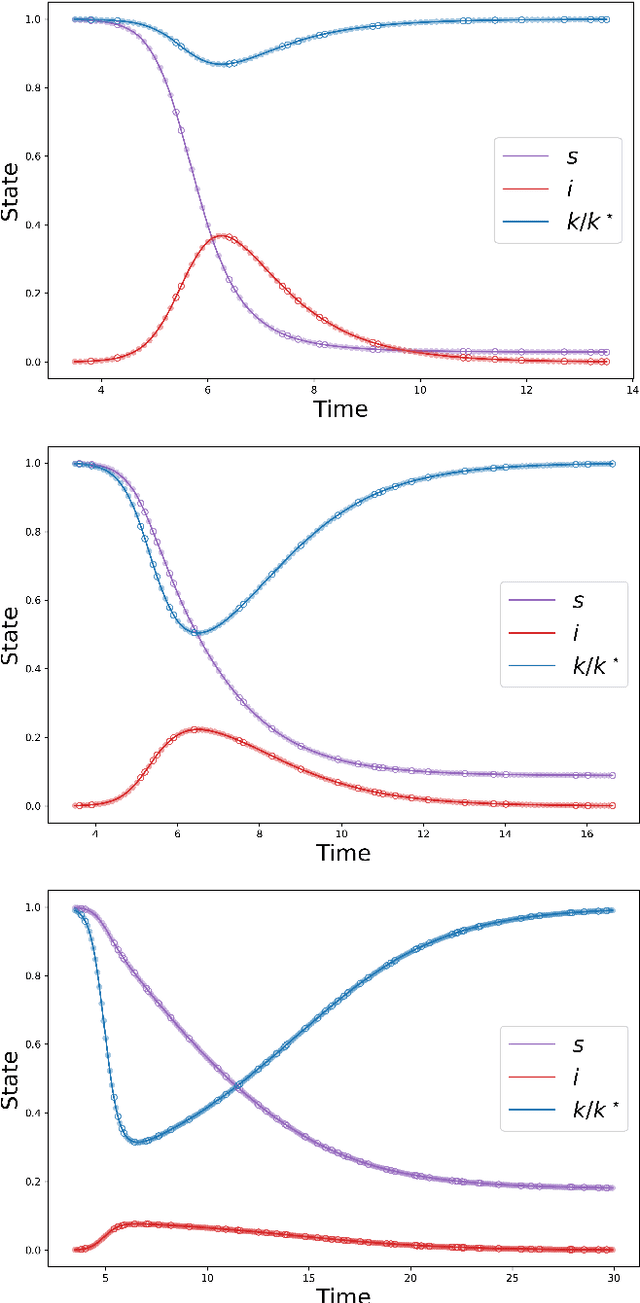
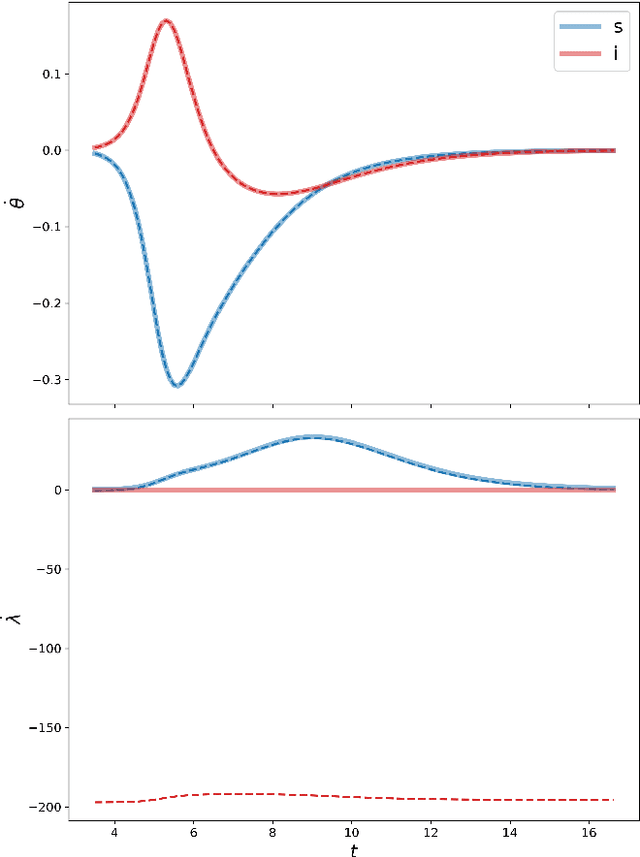
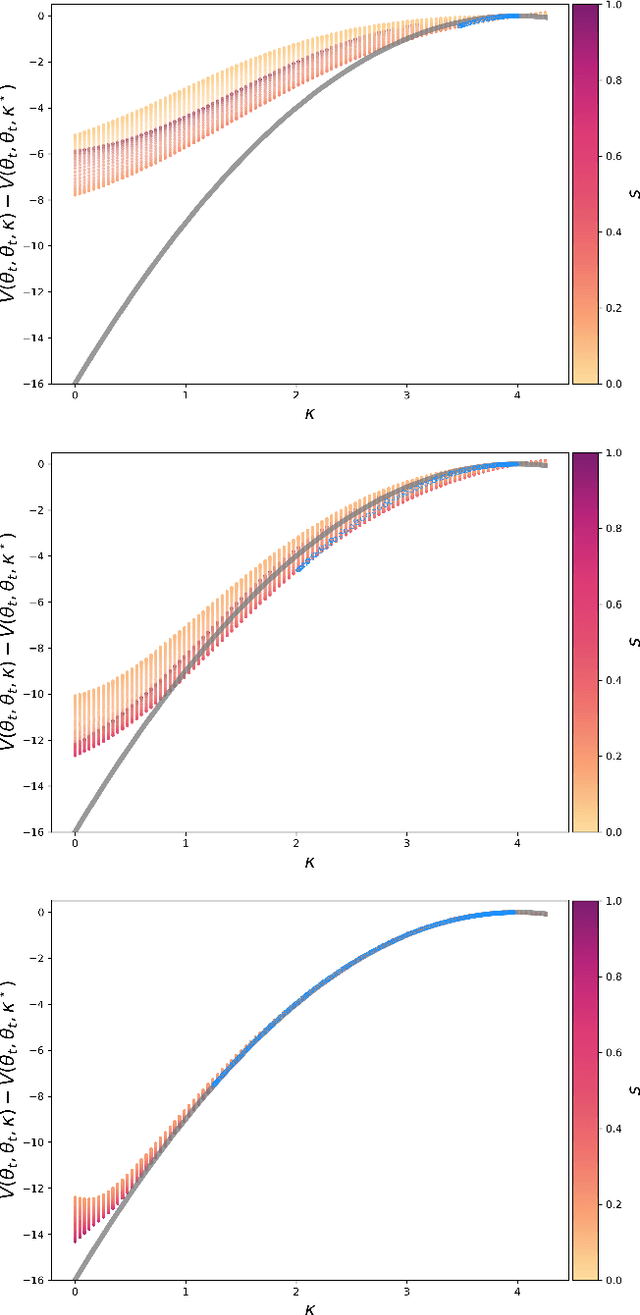
We propose Nash Neural Networks ($N^3$) as a new type of Physics Informed Neural Network that is able to infer the underlying utility from observations of how rational individuals behave in a differential game with a Nash equilibrium. We assume that the dynamics for both the population and the individual are known, but not the payoff function, which specifies the cost per unit time of being in any particular state. We construct our network in such a way that the Euler-Lagrange equations of the corresponding optimal control problem are satisfied and the optimal control is self-consistently determined. In this way, we are able to learn the unknown payoff function in an unsupervised manner. We have applied the $N^3$ to study the optimal behaviour during epidemics, in which individuals can choose to socially distance depending on the state of the pandemic and the cost of being infected. Training our network against synthetic data for a simple SIR model, we showed that it is possible to accurately reproduce the hidden payoff function, in such a way that the game dynamics are respected. Our approach will have far-reaching applications, as it allows one to infer utilities from behavioural data, and can thus be applied to study a wide array of problems in science, engineering, economics and government planning.
Evaluation of Time Series Forecasting Models for Estimation of PM2.5 Levels in Air
Apr 07, 2021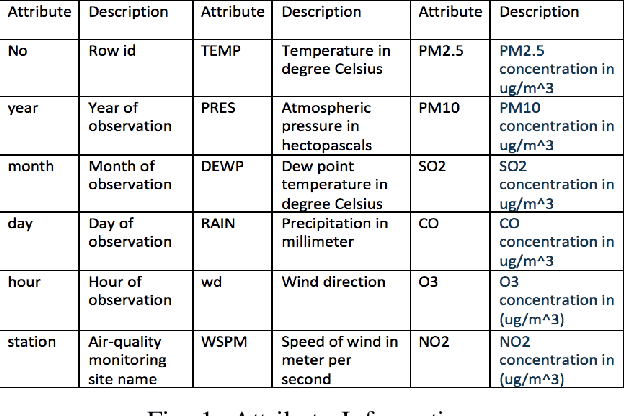
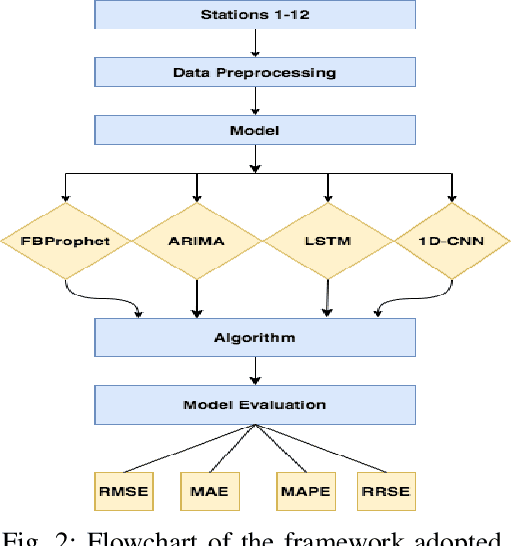
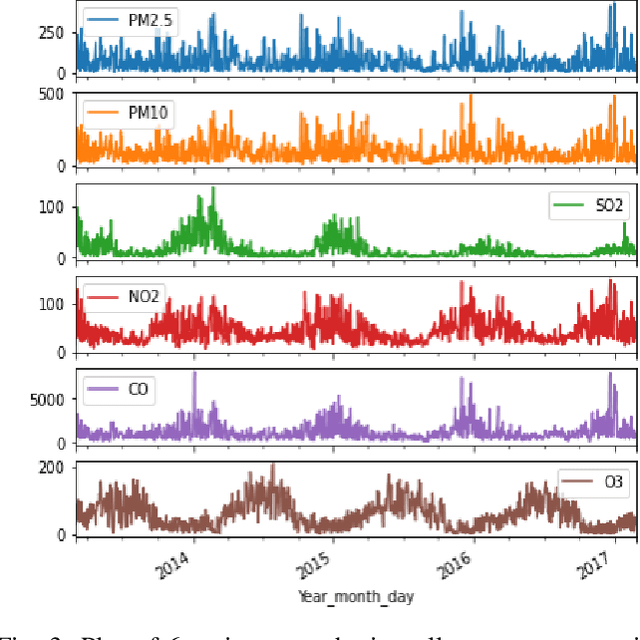
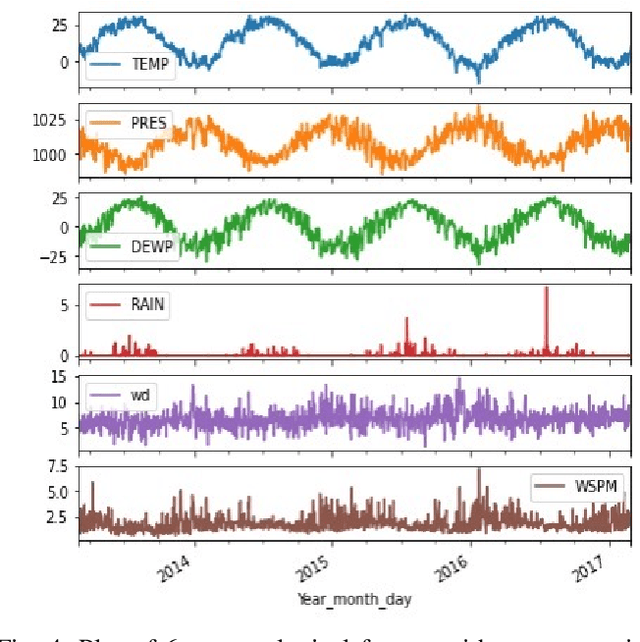
Air contamination in urban areas has risen consistently over the past few years. Due to expanding industrialization and increasing concentration of toxic gases in the climate, the air is getting more poisonous step by step at an alarming rate. Since the arrival of the Coronavirus pandemic, it is getting more critical to lessen air contamination to reduce its impact. The specialists and environmentalists are making a valiant effort to gauge air contamination levels. However, its genuinely unpredictable to mimic subatomic communication in the air, which brings about off base outcomes. There has been an ascent in using machine learning and deep learning models to foresee the results on time series data. This study adopts ARIMA, FBProphet, and deep learning models such as LSTM, 1D CNN, to estimate the concentration of PM2.5 in the environment. Our predicted results convey that all adopted methods give comparative outcomes in terms of average root mean squared error. However, the LSTM outperforms all other models with reference to mean absolute percentage error.
Multi-Objective System-by-Design for mm-Wave Automotive Radar Antennas
Mar 02, 2022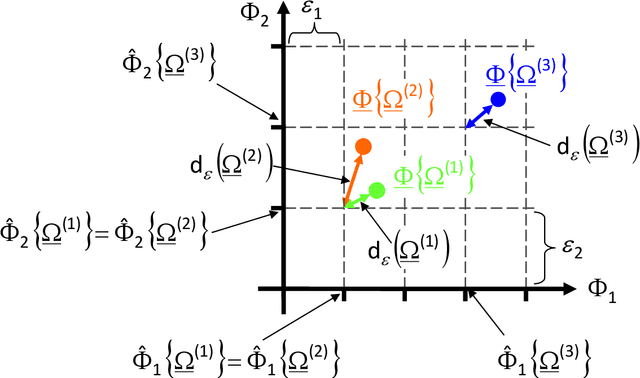
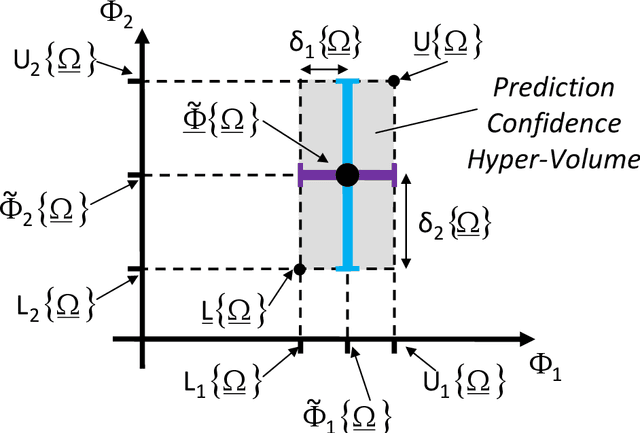
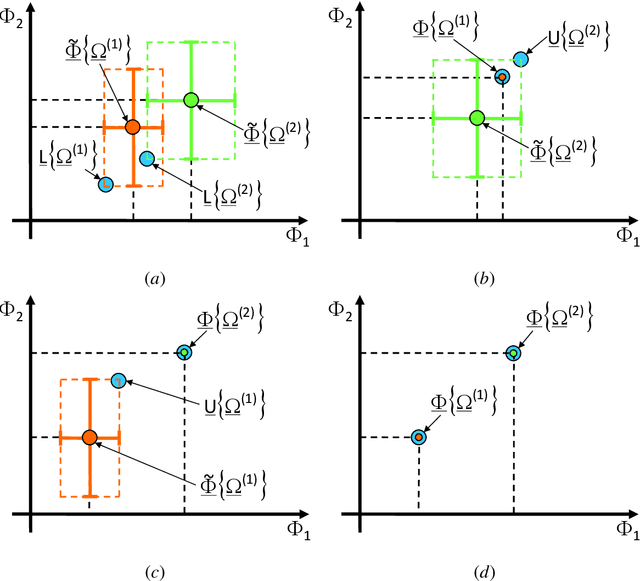
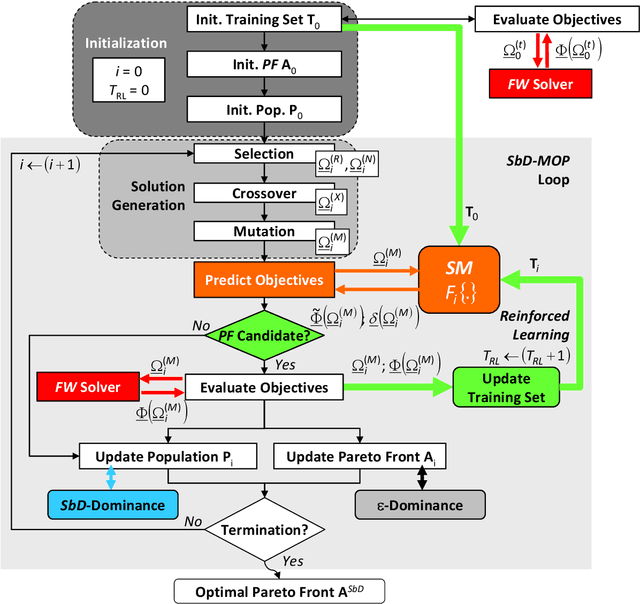
The computationally-efficient solution of multi-objective optimization problems (MOPs) arising in the design of modern electromagnetic (EM) microwave devices is addressed. Towards this end, a novel System-by-Design (SbD) method is developed to effectively explore the solution space and to provide the decision maker with a set of optimal trade-off solutions minimizing multiple and (generally) contrasting objectives. The proposed MO-SbD method proves a high computational efficiency, with a remarkable time saving with respect to a competitive state-of-the-art MOP solution strategy, thanks to the "smart" integration of evolutionary-inspired concepts and operators with artificial intelligence (AI) and machine learning (ML) techniques. Representative numerical results are reported to provide the interested users with useful insights and guidelines on the proposed optimization method as well as to assess its effectiveness in designing mm-wave automotive radar antennas.
Classifications of Skull Fractures using CT Scan Images via CNN with Lazy Learning Approach
Mar 21, 2022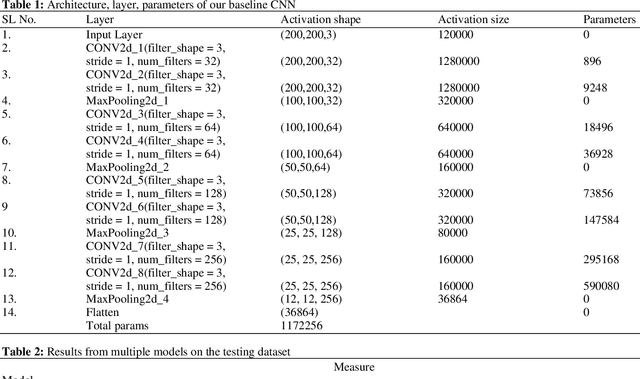
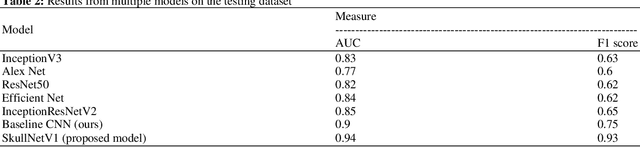
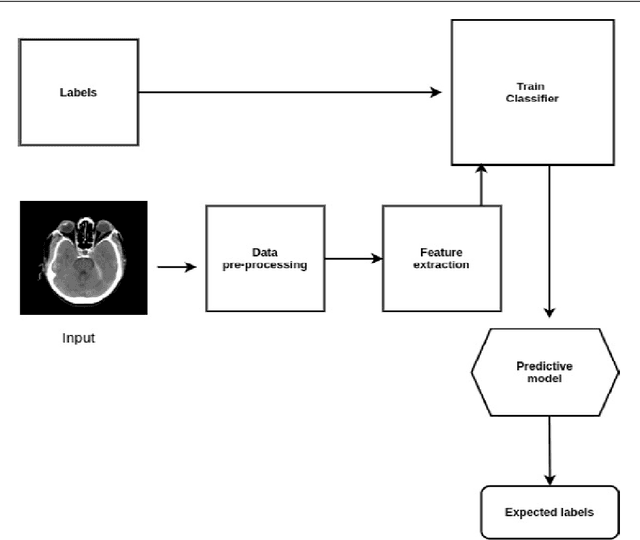
Classification of skull fracture is a challenging task for both radiologists and researchers. Skull fractures result in broken pieces of bone, which can cut into the brain and cause bleeding and other injury types. So it is vital to detect and classify the fracture very early. In real world, often fractures occur at multiple sites. This makes it harder to detect the fracture type where many fracture types might summarize a skull fracture. Unfortunately, manual detection of skull fracture and the classification process is time-consuming, threatening a patient's life. Because of the emergence of deep learning, this process could be automated. Convolutional Neural Networks (CNNs) are the most widely used deep learning models for image categorization because they deliver high accuracy and outstanding outcomes compared to other models. We propose a new model called SkullNetV1 comprising a novel CNN by taking advantage of CNN for feature extraction and lazy learning approach which acts as a classifier for classification of skull fractures from brain CT images to classify five fracture types. Our suggested model achieved a subset accuracy of 88%, an F1 score of 93%, the Area Under the Curve (AUC) of 0.89 to 0.98, a Hamming score of 92% and a Hamming loss of 0.04 for this seven-class multi-labeled classification.
Towards Lightweight Neural Animation : Exploration of Neural Network Pruning in Mixture of Experts-based Animation Models
Jan 24, 2022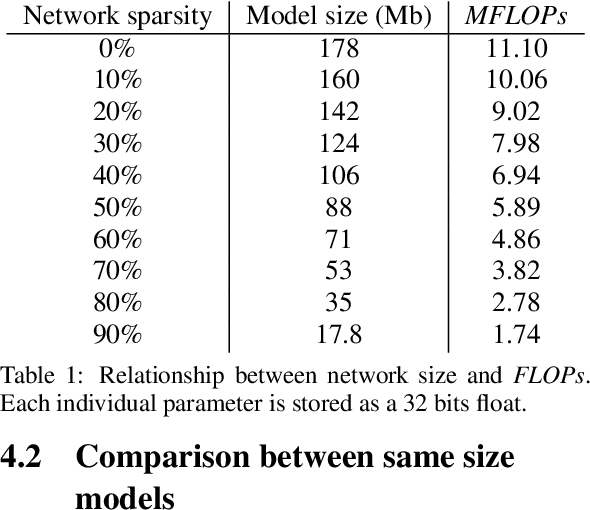
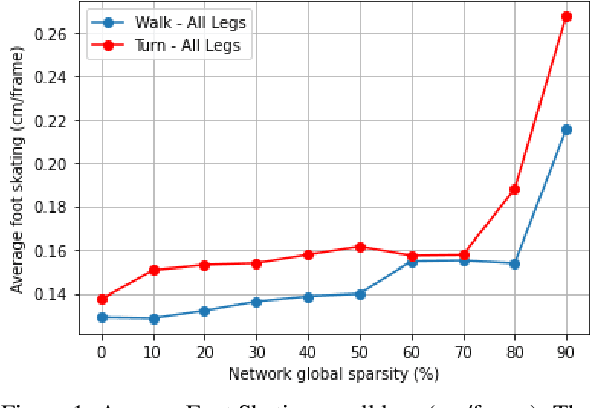


In the past few years, neural character animation has emerged and offered an automatic method for animating virtual characters. Their motion is synthesized by a neural network. Controlling this movement in real time with a user-defined control signal is also an important task in video games for example. Solutions based on fully-connected layers (MLPs) and Mixture-of-Experts (MoE) have given impressive results in generating and controlling various movements with close-range interactions between the environment and the virtual character. However, a major shortcoming of fully-connected layers is their computational and memory cost which may lead to sub-optimized solution. In this work, we apply pruning algorithms to compress an MLP- MoE neural network in the context of interactive character animation, which reduces its number of parameters and accelerates its computation time with a trade-off between this acceleration and the synthesized motion quality. This work demonstrates that, with the same number of experts and parameters, the pruned model produces less motion artifacts than the dense model and the learned high-level motion features are similar for both
t-EVA: Time-Efficient t-SNE Video Annotation
Nov 26, 2020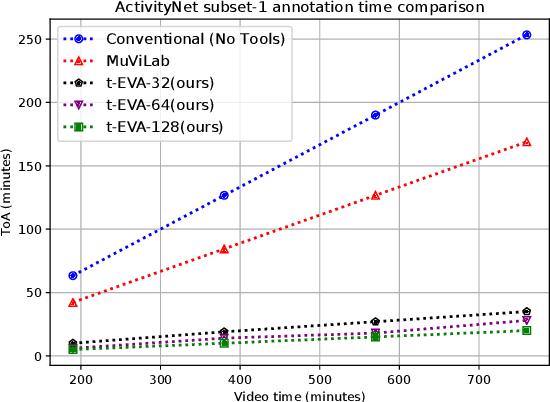
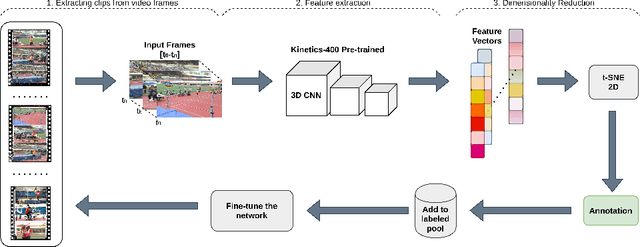

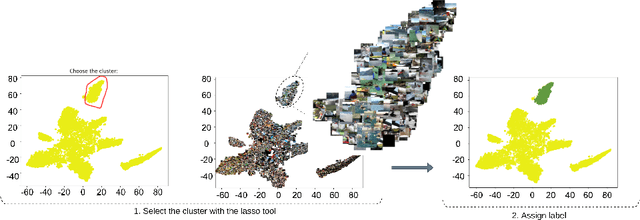
Video understanding has received more attention in the past few years due to the availability of several large-scale video datasets. However, annotating large-scale video datasets are cost-intensive. In this work, we propose a time-efficient video annotation method using spatio-temporal feature similarity and t-SNE dimensionality reduction to speed up the annotation process massively. Placing the same actions from different videos near each other in the two-dimensional space based on feature similarity helps the annotator to group-label video clips. We evaluate our method on two subsets of the ActivityNet (v1.3) and a subset of the Sports-1M dataset. We show that t-EVA can outperform other video annotation tools while maintaining test accuracy on video classification.
Ask to Understand: Question Generation for Multi-hop Question Answering
Mar 17, 2022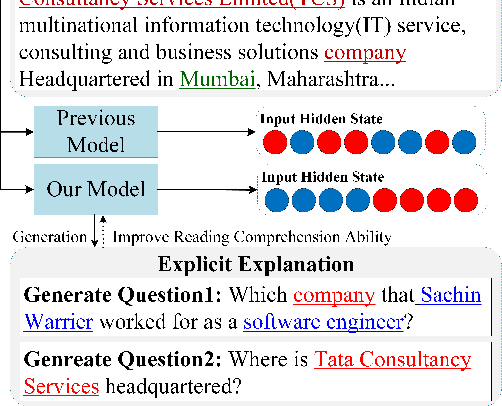
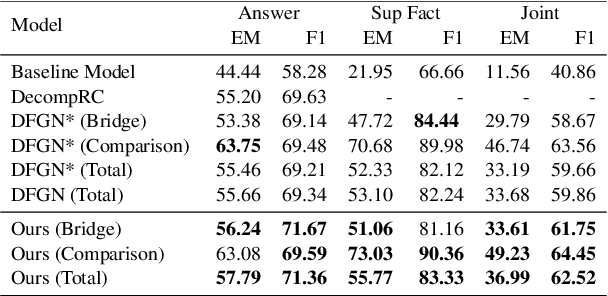
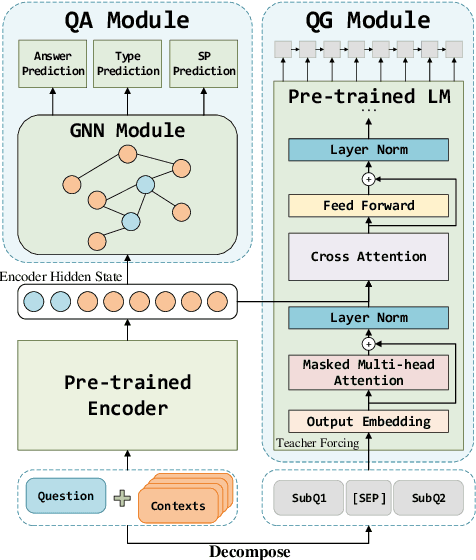
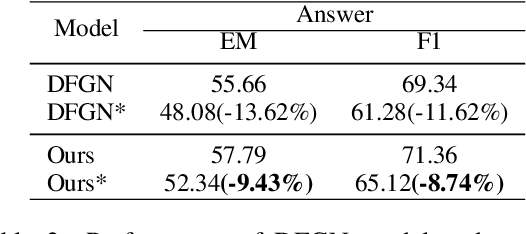
Multi-hop Question Answering (QA) requires the machine to answer complex questions by finding scattering clues and reasoning from multiple documents. Graph Network (GN) and Question Decomposition (QD) are two common approaches at present. The former uses the "black-box" reasoning process to capture the potential relationship between entities and sentences, thus achieving good performance. At the same time, the latter provides a clear reasoning logical route by decomposing multi-hop questions into simple single-hop sub-questions. In this paper, we propose a novel method to complete multi-hop QA from the perspective of Question Generation (QG). Specifically, we carefully design an end-to-end QG module on the basis of a classical QA module, which could help the model understand the context by asking inherently logical sub-questions, thus inheriting interpretability from the QD-based method and showing superior performance. Experiments on the HotpotQA dataset demonstrate that the effectiveness of our proposed QG module, human evaluation further clarifies its interpretability quantitatively, and thorough analysis shows that the QG module could generate better sub-questions than QD methods in terms of fluency, consistency, and diversity.
VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer
Jan 17, 2022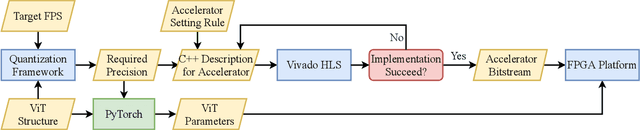
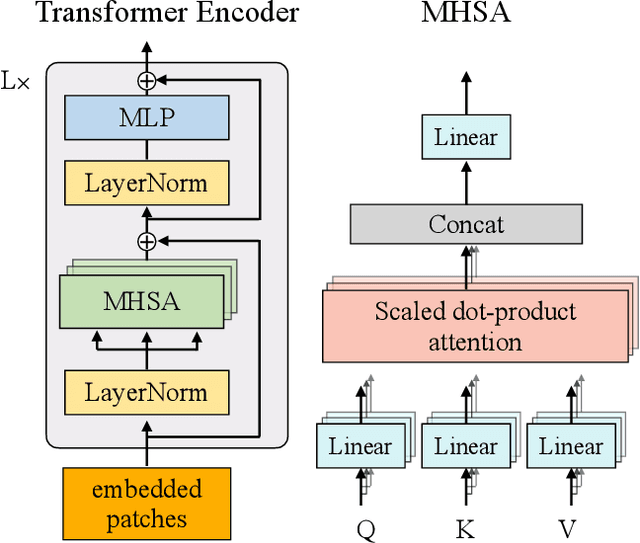
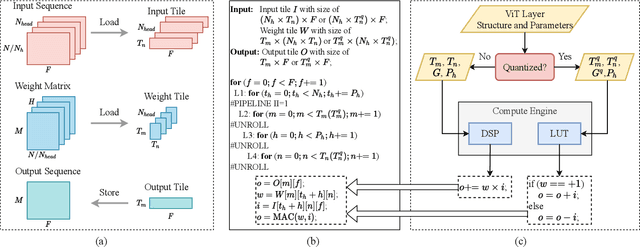
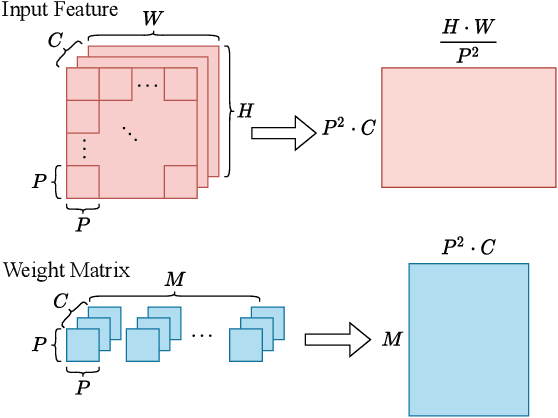
The transformer architectures with attention mechanisms have obtained success in Nature Language Processing (NLP), and Vision Transformers (ViTs) have recently extended the application domains to various vision tasks. While achieving high performance, ViTs suffer from large model size and high computation complexity that hinders the deployment of them on edge devices. To achieve high throughput on hardware and preserve the model accuracy simultaneously, we propose VAQF, a framework that builds inference accelerators on FPGA platforms for quantized ViTs with binary weights and low-precision activations. Given the model structure and the desired frame rate, VAQF will automatically output the required quantization precision for activations as well as the optimized parameter settings of the accelerator that fulfill the hardware requirements. The implementations are developed with Vivado High-Level Synthesis (HLS) on the Xilinx ZCU102 FPGA board, and the evaluation results with the DeiT-base model indicate that a frame rate requirement of 24 frames per second (FPS) is satisfied with 8-bit activation quantization, and a target of 30 FPS is met with 6-bit activation quantization. To the best of our knowledge, this is the first time quantization has been incorporated into ViT acceleration on FPGAs with the help of a fully automatic framework to guide the quantization strategy on the software side and the accelerator implementations on the hardware side given the target frame rate. Very small compilation time cost is incurred compared with quantization training, and the generated accelerators show the capability of achieving real-time execution for state-of-the-art ViT models on FPGAs.
3D High-Quality Magnetic Resonance Image Restoration in Clinics Using Deep Learning
Dec 09, 2021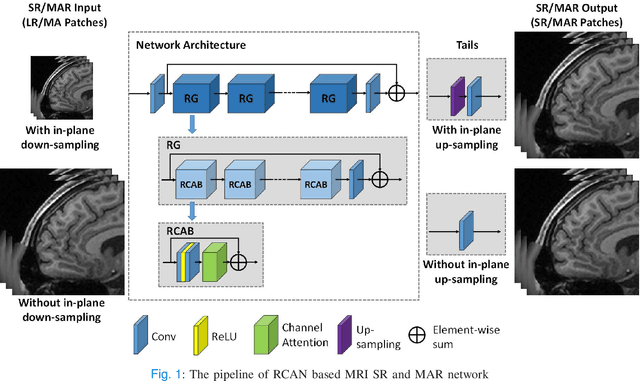
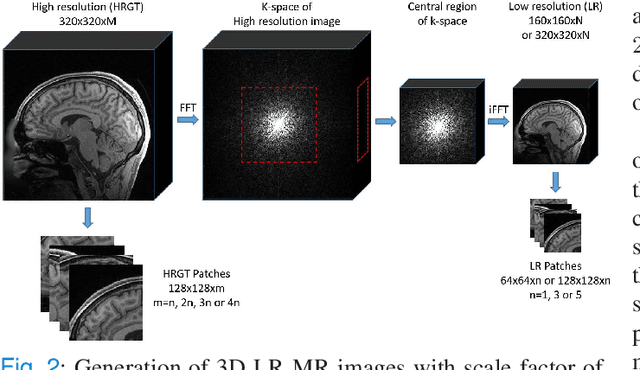
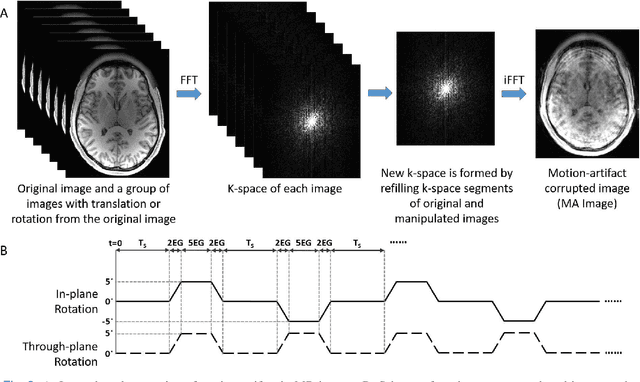

Shortening acquisition time and reducing the motion-artifact are two of the most essential concerns in magnetic resonance imaging. As a promising solution, deep learning-based high quality MR image restoration has been investigated to generate higher resolution and motion artifact-free MR images from lower resolution images acquired with shortened acquisition time, without costing additional acquisition time or modifying the pulse sequences. However, numerous problems still exist to prevent deep learning approaches from becoming practical in the clinic environment. Specifically, most of the prior works focus solely on the network model but ignore the impact of various downsampling strategies on the acquisition time. Besides, the long inference time and high GPU consumption are also the bottle neck to deploy most of the prior works in clinics. Furthermore, prior studies employ random movement in retrospective motion artifact generation, resulting in uncontrollable severity of motion artifact. More importantly, doctors are unsure whether the generated MR images are trustworthy, making diagnosis difficult. To overcome all these problems, we employed a unified 2D deep learning neural network for both 3D MRI super resolution and motion artifact reduction, demonstrating such a framework can achieve better performance in 3D MRI restoration task compared to other states of the art methods and remains the GPU consumption and inference time significantly low, thus easier to deploy. We also analyzed several downsampling strategies based on the acceleration factor, including multiple combinations of in-plane and through-plane downsampling, and developed a controllable and quantifiable motion artifact generation method. At last, the pixel-wise uncertainty was calculated and used to estimate the accuracy of generated image, providing additional information for reliable diagnosis.