 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recipe for Efficient SBIR Models: Combining Relative Triplet Loss with Batch Normalization and Knowledge Distillation
May 30, 2023Sketch-Based Image Retrieval (SBIR) is a crucial task in multimedia retrieval, where the goal is to retrieve a set of images that match a given sketch query. Researchers have already proposed several well-performing solutions for this task, but most focus on enhancing embedding through different approaches such as triplet loss, quadruplet loss, adding data augmentation, and using edge extraction. In this work, we tackle the problem from various angles. We start by examining the training data quality and show some of its limitations. Then, we introduce a Relative Triplet Loss (RTL), an adapted triplet loss to overcome those limitations through loss weighting based on anchors similarity. Through a series of experiments, we demonstrate that replacing a triplet loss with RTL outperforms previous state-of-the-art without the need for any data augmentation. In addition, we demonstrate why batch normalization is more suited for SBIR embeddings than l2-normalization and show that it improves significantly the performance of our models. We further investigate the capacity of models required for the photo and sketch domains and demonstrate that the photo encoder requires a higher capacity than the sketch encoder, which validates the hypothesis formulated in [34]. Then, we propose a straightforward approach to train small models, such as ShuffleNetv2 [22] efficiently with a marginal loss of accuracy through knowledge distillation. The same approach used with larger models enabled us to outperform previous state-of-the-art results and achieve a recall of 62.38% at k = 1 on The Sketchy Database [30].
Induced Feature Selection by Structured Pruning
Mar 20, 2023



The advent of sparsity inducing techniques in neural networks has been of a great help in the last few years. Indeed, those methods allowed to find lighter and faster networks, able to perform more efficiently in resource-constrained environment such as mobile devices or highly requested servers. Such a sparsity is generally imposed on the weights of neural networks, reducing the footprint of the architecture. In this work, we go one step further by imposing sparsity jointly on the weights and on the input data. This can be achieved following a three-step process: 1) impose a certain structured sparsity on the weights of the network; 2) track back input features corresponding to zeroed blocks of weight; 3) remove useless weights and input features and retrain the network. Performing pruning both on the network and on input data not only allows for extreme reduction in terms of parameters and operations but can also serve as an interpretation process. Indeed, with the help of data pruning, we now have information about which input feature is useful for the network to keep its performance. Experiments conducted on a variety of architectures and datasets: MLP validated on MNIST, CIFAR10/100 and ConvNets (VGG16 and ResNet18), validated on CIFAR10/100 and CALTECH101 respectively, show that it is possible to achieve additional gains in terms of total parameters and in FLOPs by performing pruning on input data, while also increasing accuracy.
FasterAI: A Lightweight Library for Creating Sparse Neural Networks
Jul 03, 2022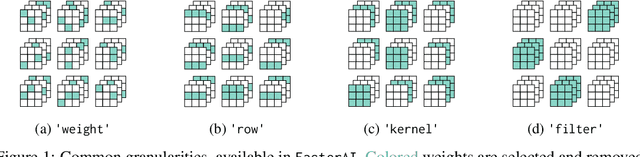
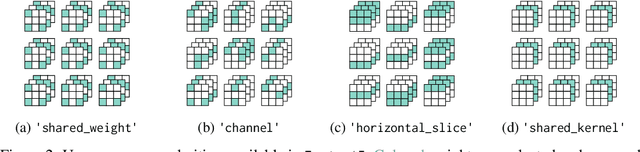
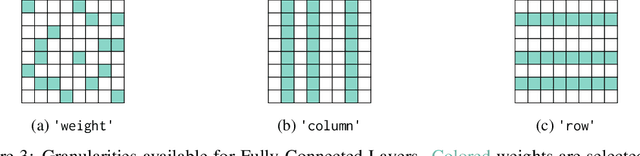
FasterAI is a PyTorch-based library, aiming to facilitate the utilization of deep neural networks compression techniques such as sparsification, pruning, knowledge distillation, or regularization. The library is built with the purpose of enabling quick implementation and experimentation. More particularly, compression techniques are leveraging Callback systems of libraries such as fastai and Pytorch Lightning to bring a user-friendly and high-level API. The main asset of FasterAI is its lightweight, yet powerful, simplicity of use. Indeed, because it was developed in a very granular way, users can create thousands of unique experiments by using different combinations of parameters. In this paper, we focus on the sparsifying capabilities of FasterAI, which represents the core of the library. Performing sparsification of a neural network in FasterAI only requires a single additional line of code in the traditional training loop, yet allows to perform state-of-the-art techniques such as Lottery Ticket Hypothesis experiments
Improve Convolutional Neural Network Pruning by Maximizing Filter Variety
Mar 11, 2022
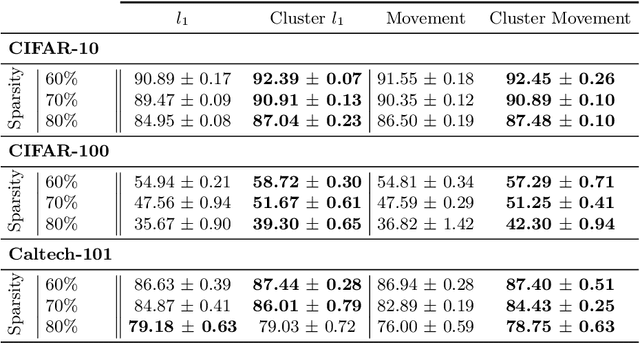

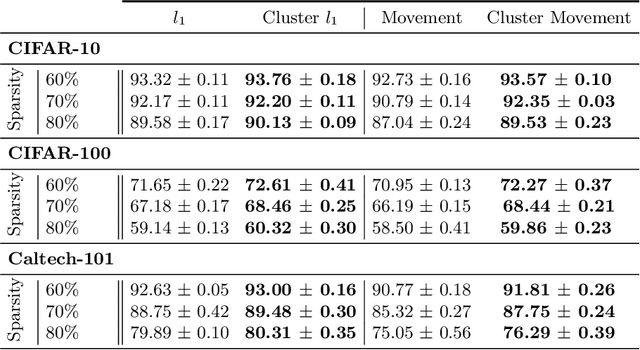
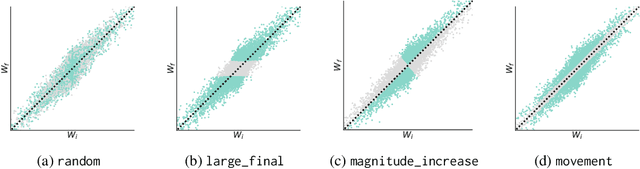
Neural network pruning is a widely used strategy for reducing model storage and computing requirements. It allows to lower the complexity of the network by introducing sparsity in the weights. Because taking advantage of sparse matrices is still challenging, pruning is often performed in a structured way, i.e. removing entire convolution filters in the case of ConvNets, according to a chosen pruning criteria. Common pruning criteria, such as l1-norm or movement, usually do not consider the individual utility of filters, which may lead to: (1) the removal of filters exhibiting rare, thus important and discriminative behaviour, and (2) the retaining of filters with redundant information. In this paper, we present a technique solving those two issues, and which can be appended to any pruning criteria. This technique ensures that the criteria of selection focuses on redundant filters, while retaining the rare ones, thus maximizing the variety of remaining filters. The experimental results, carried out on different datasets (CIFAR-10, CIFAR-100 and CALTECH-101) and using different architectures (VGG-16 and ResNet-18) demonstrate that it is possible to achieve similar sparsity levels while maintaining a higher performance when appending our filter selection technique to pruning criteria. Moreover, we assess the quality of the found sparse sub-networks by applying the Lottery Ticket Hypothesis and find that the addition of our method allows to discover better performing tickets in most cases
Towards Lightweight Neural Animation : Exploration of Neural Network Pruning in Mixture of Experts-based Animation Models
Jan 24, 2022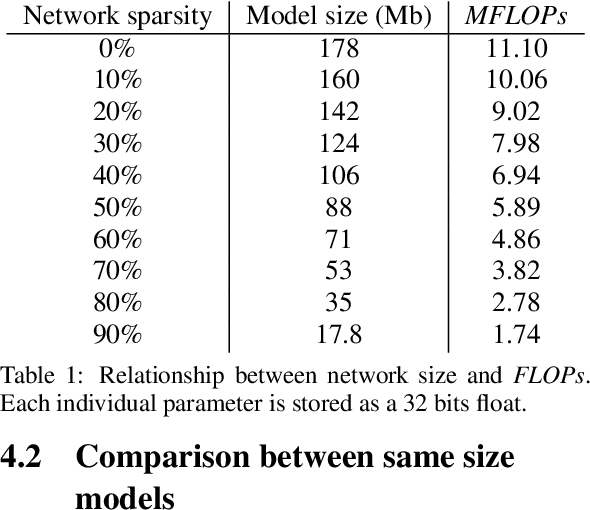
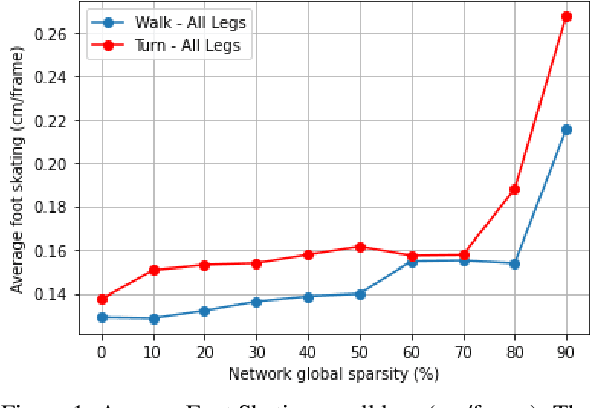


In the past few years, neural character animation has emerged and offered an automatic method for animating virtual characters. Their motion is synthesized by a neural network. Controlling this movement in real time with a user-defined control signal is also an important task in video games for example. Solutions based on fully-connected layers (MLPs) and Mixture-of-Experts (MoE) have given impressive results in generating and controlling various movements with close-range interactions between the environment and the virtual character. However, a major shortcoming of fully-connected layers is their computational and memory cost which may lead to sub-optimized solution. In this work, we apply pruning algorithms to compress an MLP- MoE neural network in the context of interactive character animation, which reduces its number of parameters and accelerates its computation time with a trade-off between this acceleration and the synthesized motion quality. This work demonstrates that, with the same number of experts and parameters, the pruned model produces less motion artifacts than the dense model and the learned high-level motion features are similar for both
Where Is My Mind ? Predicting Visual Attention from Brain Activity
Jan 11, 2022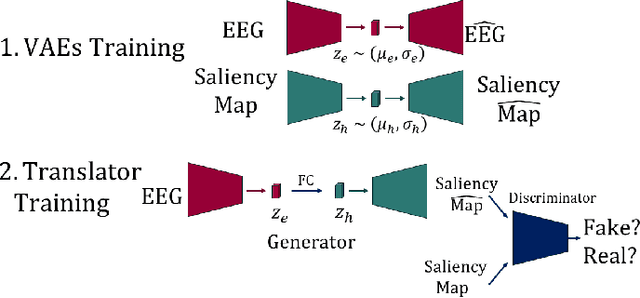
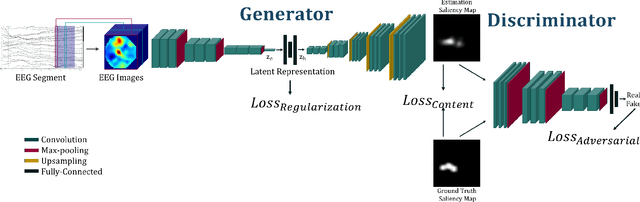

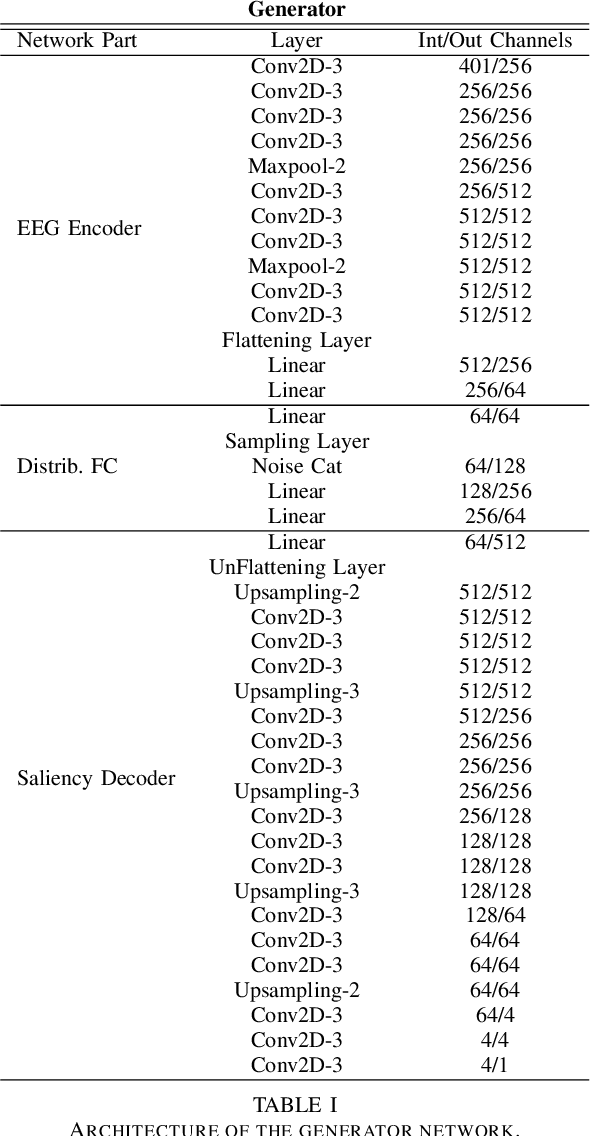
Visual attention estimation is an active field of research at the crossroads of different disciplines: computer vision, artificial intelligence and medicine. One of the most common approaches to estimate a saliency map representing attention is based on the observed images. In this paper, we show that visual attention can be retrieved from EEG acquisition. The results are comparable to traditional predictions from observed images, which is of great interest. For this purpose, a set of signals has been recorded and different models have been developed to study the relationship between visual attention and brain activity. The results are encouraging and comparable with other approaches estimating attention with other modalities. The codes and dataset considered in this paper have been made available at \url{https://figshare.com/s/3e353bd1c621962888ad} to promote research in the field.
An Experimental Study of the Impact of Pre-training on the Pruning of a Convolutional Neural Network
Dec 15, 2021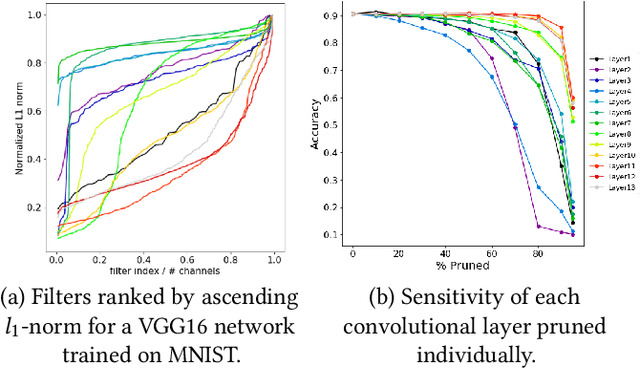
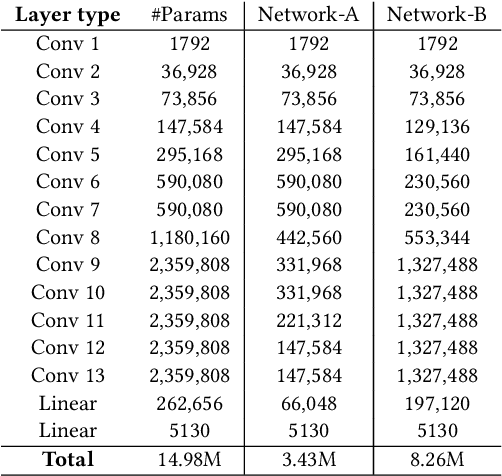
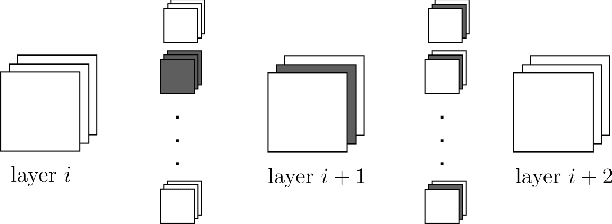
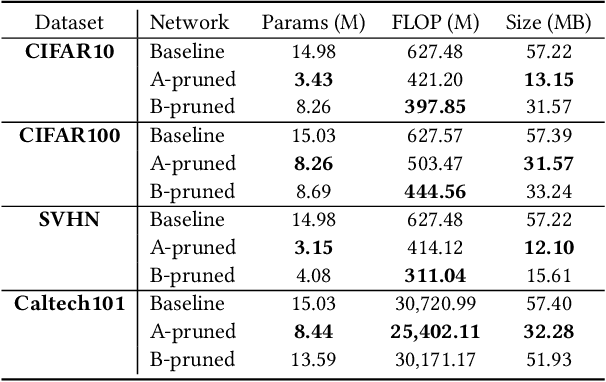
In recent years, deep neural networks have known a wide success in various application domains. However, they require important computational and memory resources, which severely hinders their deployment, notably on mobile devices or for real-time applications. Neural networks usually involve a large number of parameters, which correspond to the weights of the network. Such parameters, obtained with the help of a training process, are determinant for the performance of the network. However, they are also highly redundant. The pruning methods notably attempt to reduce the size of the parameter set, by identifying and removing the irrelevant weights. In this paper, we examine the impact of the training strategy on the pruning efficiency. Two training modalities are considered and compared: (1) fine-tuned and (2) from scratch. The experimental results obtained on four datasets (CIFAR10, CIFAR100, SVHN and Caltech101) and for two different CNNs (VGG16 and MobileNet) demonstrate that a network that has been pre-trained on a large corpus (e.g. ImageNet) and then fine-tuned on a particular dataset can be pruned much more efficiently (up to 80% of parameter reduction) than the same network trained from scratch.
One-Cycle Pruning: Pruning ConvNets Under a Tight Training Budget
Jul 05, 2021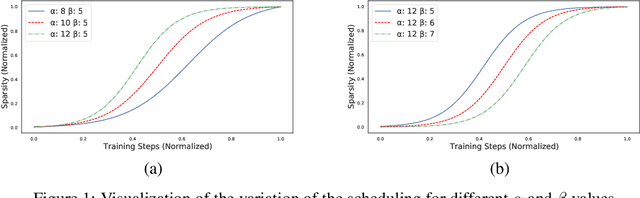
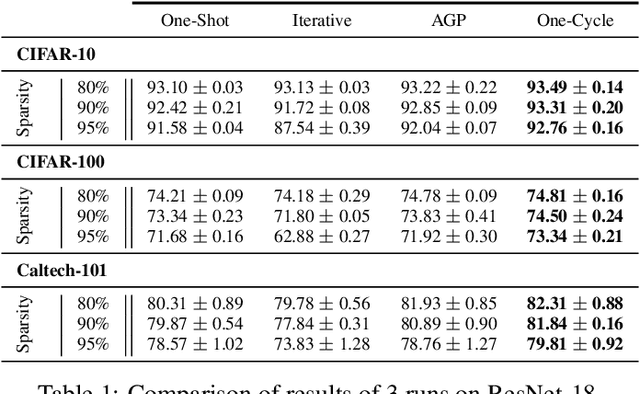
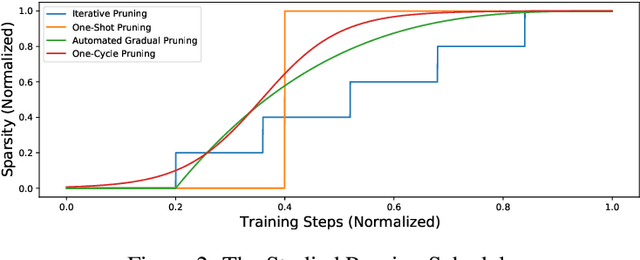

Introducing sparsity in a neural network has been an efficient way to reduce its complexity while keeping its performance almost intact. Most of the time, sparsity is introduced using a three-stage pipeline: 1) train the model to convergence, 2) prune the model according to some criterion, 3) fine-tune the pruned model to recover performance. The last two steps are often performed iteratively, leading to reasonable results but also to a time-consuming and complex process. In our work, we propose to get rid of the first step of the pipeline and to combine the two other steps in a single pruning-training cycle, allowing the model to jointly learn for the optimal weights while being pruned. We do this by introducing a novel pruning schedule, named One-Cycle Pruning, which starts pruning from the beginning of the training, and until its very end. Adopting such a schedule not only leads to better performing pruned models but also drastically reduces the training budget required to prune a model. Experiments are conducted on a variety of architectures (VGG-16 and ResNet-18) and datasets (CIFAR-10, CIFAR-100 and Caltech-101), and for relatively high sparsity values (80%, 90%, 95% of weights removed). Our results show that One-Cycle Pruning consistently outperforms commonly used pruning schedules such as One-Shot Pruning, Iterative Pruning and Automated Gradual Pruning, on a fixed training budget.
Modulated Self-attention Convolutional Network for VQA
Oct 31, 2019

As new data-sets for real-world visual reasoning and compositional question answering are emerging, it might be needed to use the visual feature extraction as a end-to-end process during training. This small contribution aims to suggest new ideas to improve the visual processing of traditional convolutional network for visual question answering (VQA). In this paper, we propose to modulate by a linguistic input a CNN augmented with self-attention. We show encouraging relative improvements for future research in this direction.