 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OneLabeler: A Flexible System for Building Data Labeling Tools
Mar 27, 2022
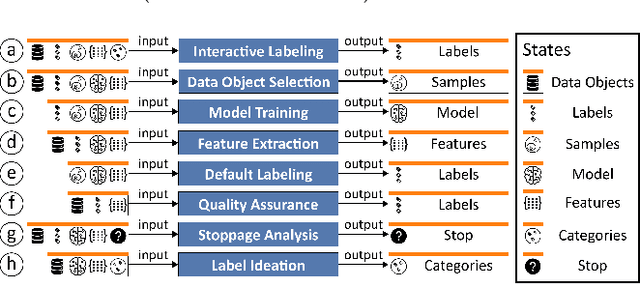

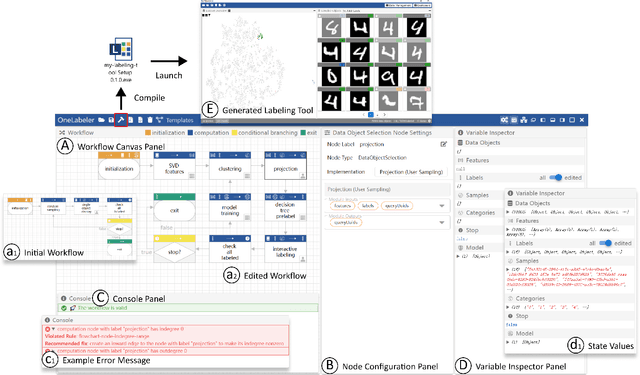
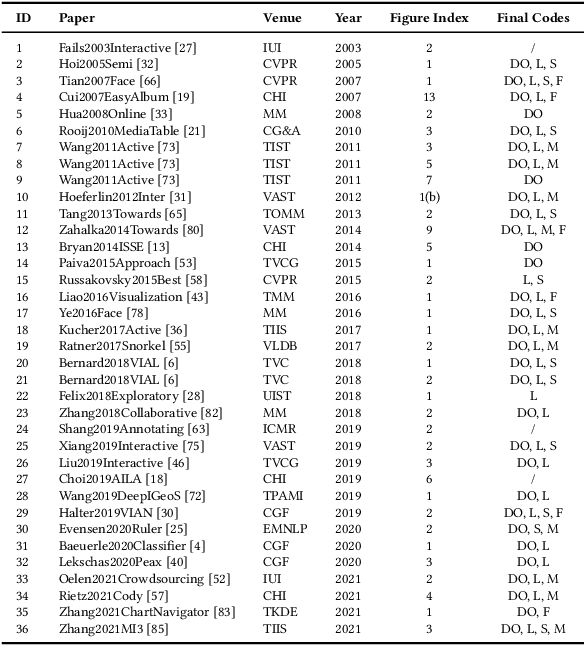
Labeled datasets are essential for supervised machine learning. Various data labeling tools have been built to collect labels in different usage scenarios. However, developing labeling tools is time-consuming, costly, and expertise-demanding on software development. In this paper, we propose a conceptual framework for data labeling and OneLabeler based on the conceptual framework to support easy building of labeling tools for diverse usage scenarios. The framework consists of common modules and states in labeling tools summarized through coding of existing tools. OneLabeler supports configuration and composition of common software modules through visual programming to build data labeling tools. A module can be a human, machine, or mixed computation procedure in data labeling. We demonstrate the expressiveness and utility of the system through ten example labeling tools built with OneLabeler. A user study with developers provides evidence that OneLabeler supports efficient building of diverse data labeling tools.
A Multi-Agent Reinforcement Learning Framework for Off-Policy Evaluation in Two-sided Markets
Feb 21, 2022

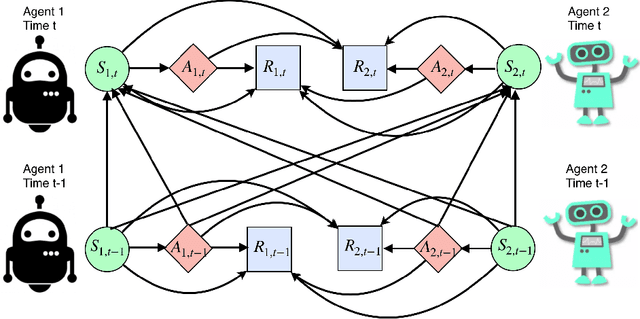
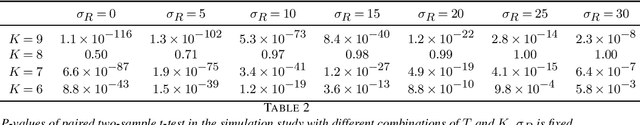
The two-sided markets such as ride-sharing companies often involve a group of subjects who are making sequential decisions across time and/or location. With the rapid development of smart phones and internet of things, they have substantially transformed the transportation landscape of human beings. In this paper we consider large-scale fleet management in ride-sharing companies that involve multiple units in different areas receiving sequences of products (or treatments) over time. Major technical challenges, such as policy evaluation, arise in those studies because (i) spatial and temporal proximities induce interference between locations and times; and (ii) the large number of locations results in the curse of dimensionality. To address both challenges simultaneously, we introduce a multi-agent reinforcement learning (MARL) framework for carrying policy evaluation in these studies. We propose novel estimators for mean outcomes under different products that are consistent despite the high-dimensionality of state-action space. The proposed estimator works favorably in simulation experiments. We further illustrate our method using a real dataset obtained from a two-sided marketplace company to evaluate the effects of applying different subsidizing policies. A Python implementation of the proposed method is available at https://github.com/RunzheStat/CausalMARL.
End-to-end LPCNet: A Neural Vocoder With Fully-Differentiable LPC Estimation
Mar 29, 2022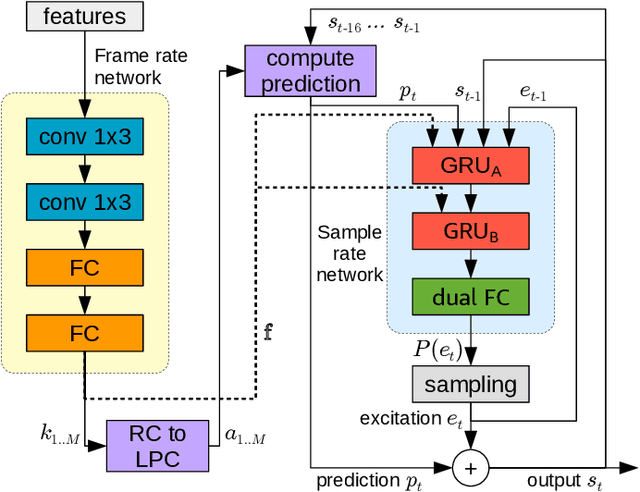
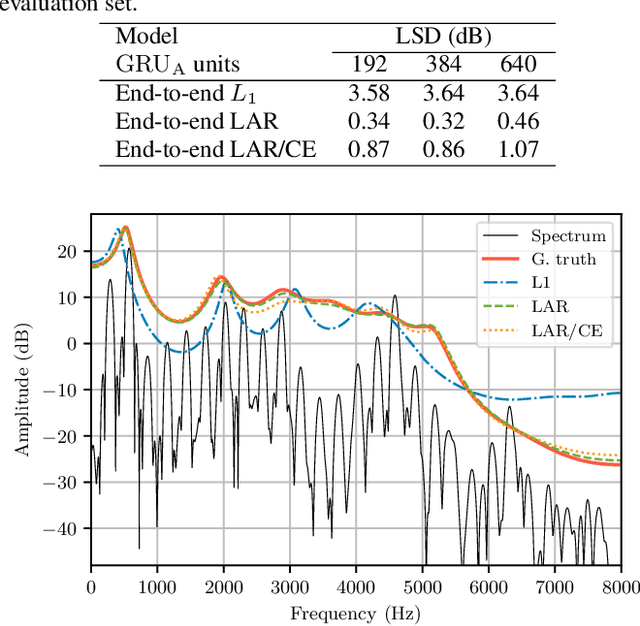
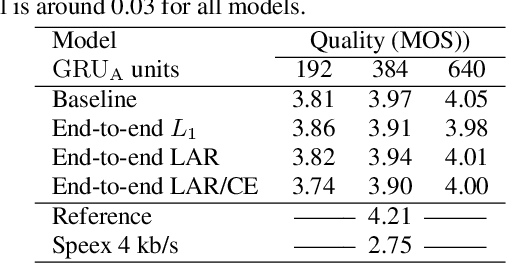
Neural vocoders have recently demonstrated high quality speech synthesis, but typically require a high computational complexity. LPCNet was proposed as a way to reduce the complexity of neural synthesis by using linear prediction (LP) to assist an autoregressive model. At inference time, LPCNet relies on the LP coefficients being explicitly computed from the input acoustic features. That makes the design of LPCNet-based systems more complicated, while adding the constraint that the input features must represent a clean speech spectrum. We propose an end-to-end version of LPCNet that lifts these limitations by learning to infer the LP coefficients from the input features in the frame rate network. Results show that the proposed end-to-end approach equals or exceeds the quality of the original LPCNet model, but without explicit LP analysis. Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features.
Many-to-many Splatting for Efficient Video Frame Interpolation
Apr 07, 2022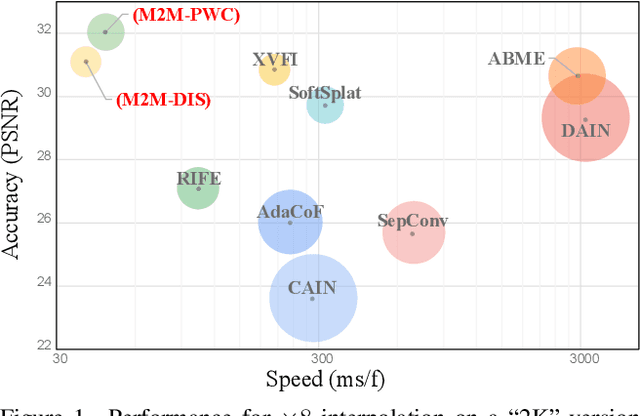
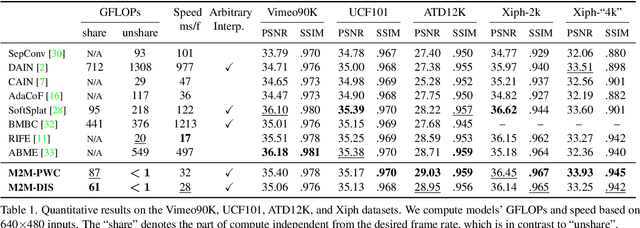
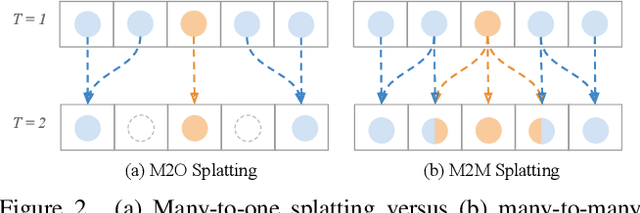
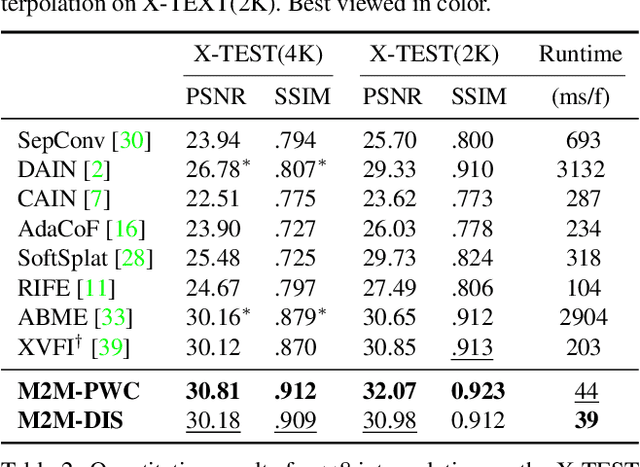
Motion-based video frame interpolation commonly relies on optical flow to warp pixels from the inputs to the desired interpolation instant. Yet due to the inherent challenges of motion estimation (e.g. occlusions and discontinuities), most state-of-the-art interpolation approaches require subsequent refinement of the warped result to generate satisfying outputs, which drastically decreases the efficiency for multi-frame interpolation. In this work, we propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Specifically, given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step, and then fuse any overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context. This establishes a many-to-many splatting scheme with robustness to artifacts like holes. Moreover, for each input frame pair, M2M only performs motion estimation once and has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. We conducted extensive experiments to analyze M2M, and found that it significantly improves efficiency while maintaining high effectiveness.
Online Learning in Fisher Markets with Unknown Agent Preferences
Apr 27, 2022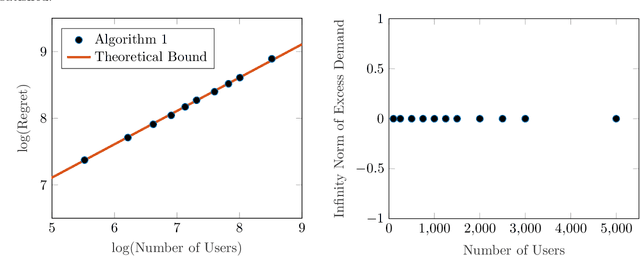
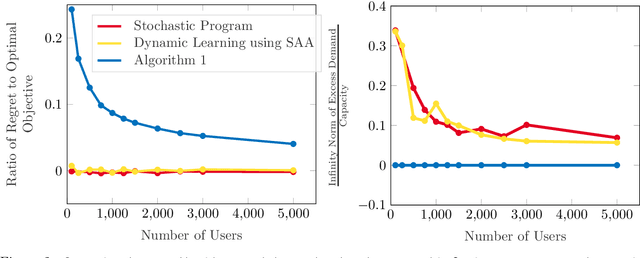
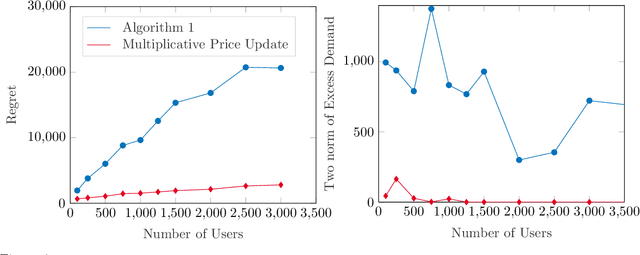
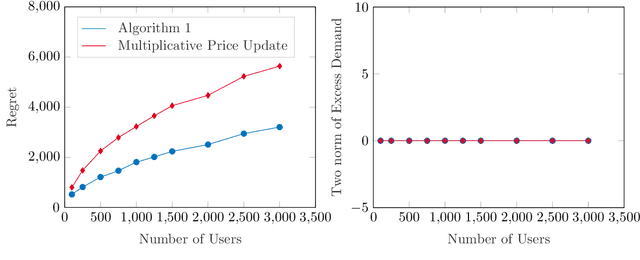
In a Fisher market, agents (users) spend a budget of (artificial) currency to buy goods that maximize their utilities, and producers set prices on capacity-constrained goods such that the market clears. The equilibrium prices in such a market are typically computed through the solution of a convex program, e.g., the Eisenberg-Gale program, that aggregates users' preferences into a centralized social welfare objective. However, the computation of equilibrium prices using convex programs assumes that all transactions happen in a static market wherein all users are present simultaneously and relies on complete information on each user's budget and utility function. Since, in practice, information on users' utilities and budgets is unknown and users tend to arrive over time in the market, we study an online variant of Fisher markets, wherein users enter the market sequentially. We focus on the setting where users have linear utilities with privately known utility and budget parameters drawn i.i.d. from a distribution $\mathcal{D}$. In this setting, we develop a simple yet effective algorithm to set prices that preserves user privacy while achieving a regret and capacity violation of $O(\sqrt{n})$, where $n$ is the number of arriving users and the capacities of the goods scale as $O(n)$. Here, our regret measure represents the optimality gap in the objective of the Eisenberg-Gale program between the online allocation policy and that of an offline oracle with complete information on users' budgets and utilities. To establish the efficacy of our approach, we show that even an algorithm that sets expected equilibrium prices with perfect information on the distribution $\mathcal{D}$ cannot achieve both a regret and constraint violation of better than $\Omega(\sqrt{n})$. Finally, we present numerical experiments to demonstrate the performance of our approach relative to several benchmarks.
Few-shot Structured Radiology Report Generation Using Natural Language Prompts
Mar 29, 2022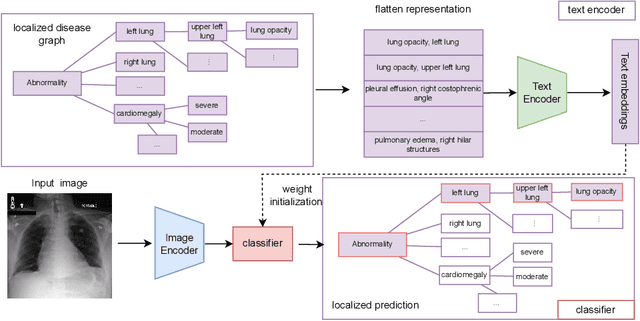
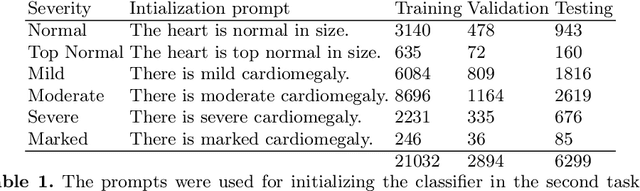
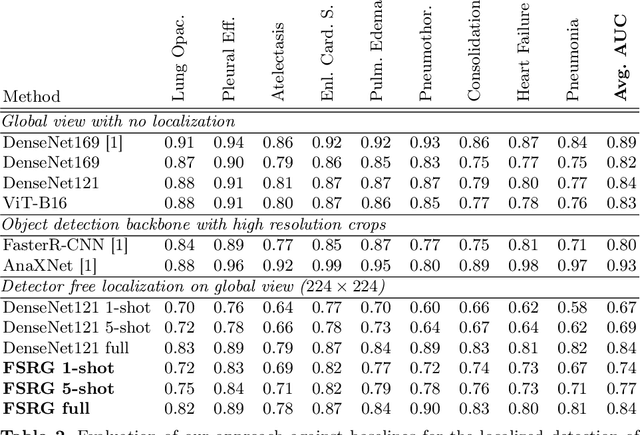
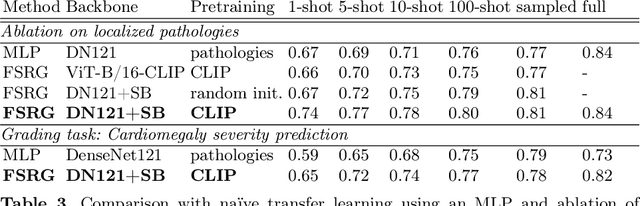
Chest radiograph reporting is time-consuming, and numerous solutions to automate this process have been proposed. Due to the complexity of medical information, the variety of writing styles, and free text being prone to typos and inconsistencies, the efficacy of quantifying the clinical accuracy of free-text reports using natural language processing measures is challenging. On the other hand, structured reports ensure consistency and can more easily be used as a quality assurance tool. To accomplish this, we present a strategy for predicting clinical observations and their anatomical location that is easily extensible to other structured findings. First, we train a contrastive language-image model using related chest radiographs and free-text radiological reports. Then, we create textual prompts for each structured finding and optimize a classifier for predicting clinical findings and their associations within the medical image. The results indicate that even when only a few image-level annotations are used for training, the method can localize pathologies in chest radiographs and generate structured reports.
Toeplitz Least Squares Problems, Fast Algorithms and Big Data
Dec 24, 2021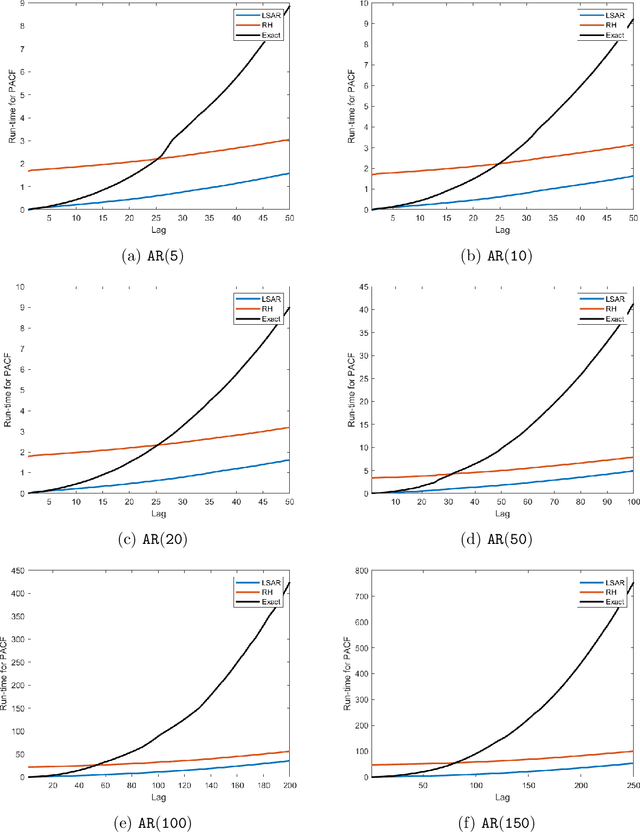
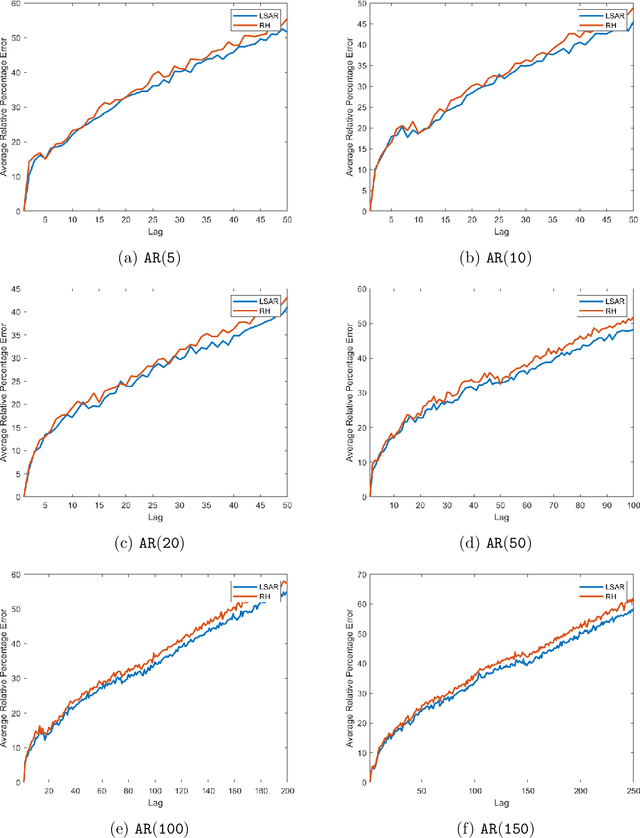
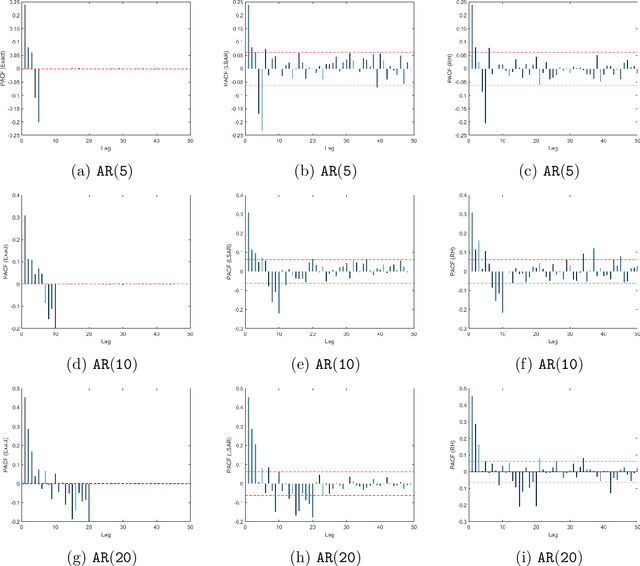
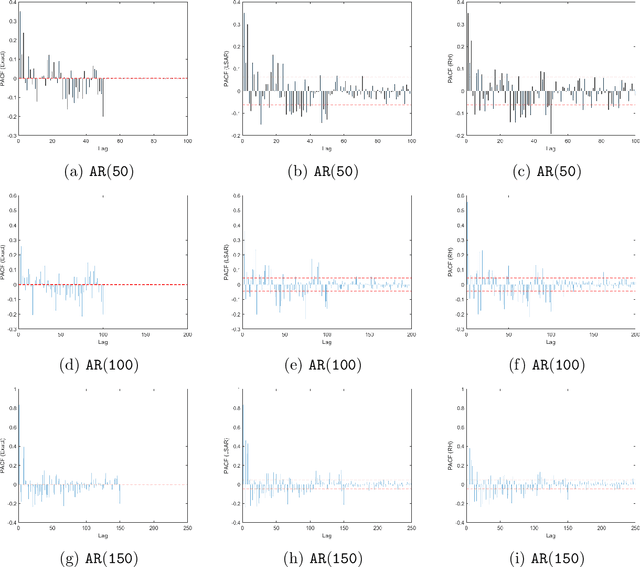
In time series analysis, when fitting an autoregressive model, one must solve a Toeplitz ordinary least squares problem numerous times to find an appropriate model, which can severely affect computational times with large data sets. Two recent algorithms (LSAR and Repeated Halving) have applied randomized numerical linear algebra (RandNLA) techniques to fitting an autoregressive model to big time-series data. We investigate and compare the quality of these two approximation algorithms on large-scale synthetic and real-world data. While both algorithms display comparable results for synthetic datasets, the LSAR algorithm appears to be more robust when applied to real-world time series data. We conclude that RandNLA is effective in the context of big-data time series.
Addressing Non-Intervention Challenges via Resilient Robotics utilizing a Digital Twin
Mar 29, 2022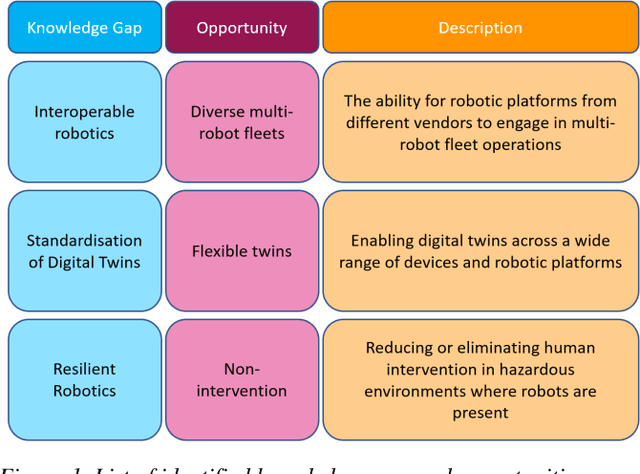
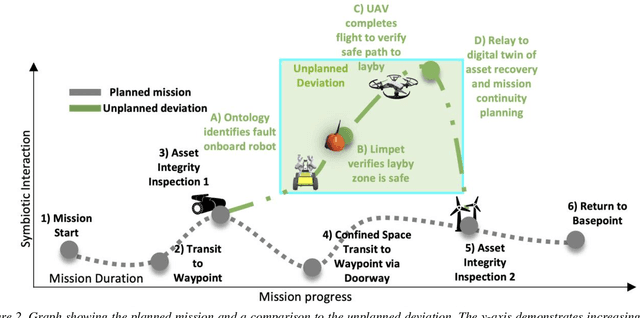
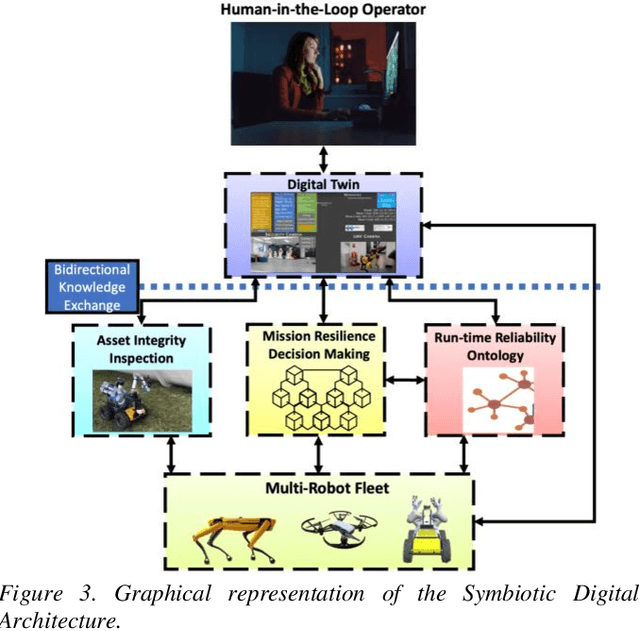
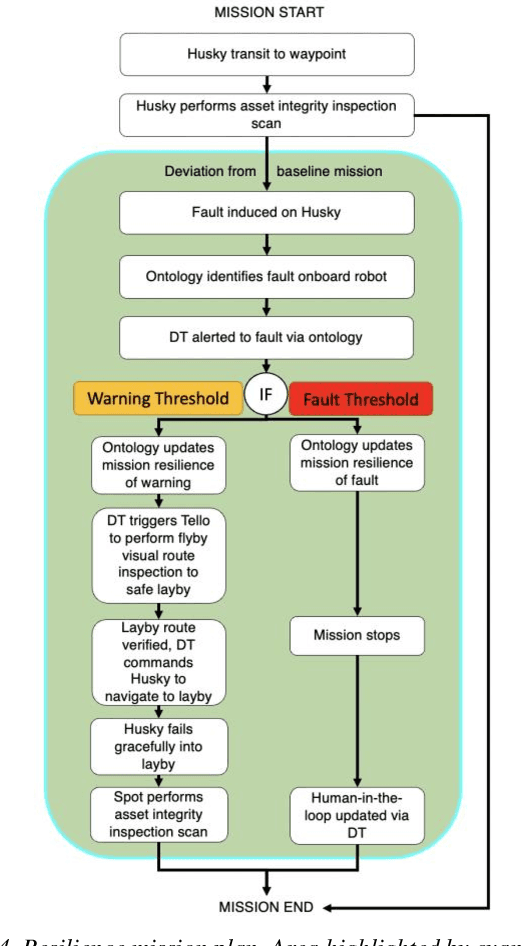
Multi-robot systems face challenges in reducing human interventions as they are often deployed in dangerous environments. It is therefore necessary to include a methodology to assess robot failure rates to reduce the requirement for costly human intervention. A solution to this problem includes robots with the ability to work together to ensure mission resilience. To prevent this intervention, robots should be able to work together to ensure mission resilience. However, robotic platforms generally lack built-in interconnectivity with other platforms from different vendors. This work aims to tackle this issue by enabling the functionality through a bidirectional digital twin. The twin enables the human operator to transmit and receive information to and from the multi-robot fleet. This digital twin considers mission resilience, decision making and a run-time reliability ontology for failure detection to enable the resilience of a multi-robot fleet. This creates the cooperation, corroboration, and collaboration of diverse robots to leverage the capability of robots and support recovery of a failed robot.
CPC: Complementary Progress Constraints for Time-Optimal Quadrotor Trajectories
Jul 13, 2020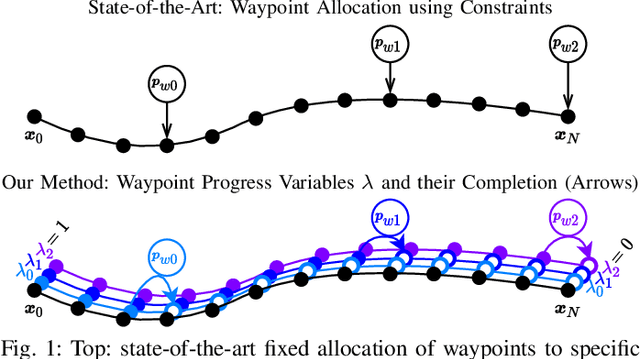
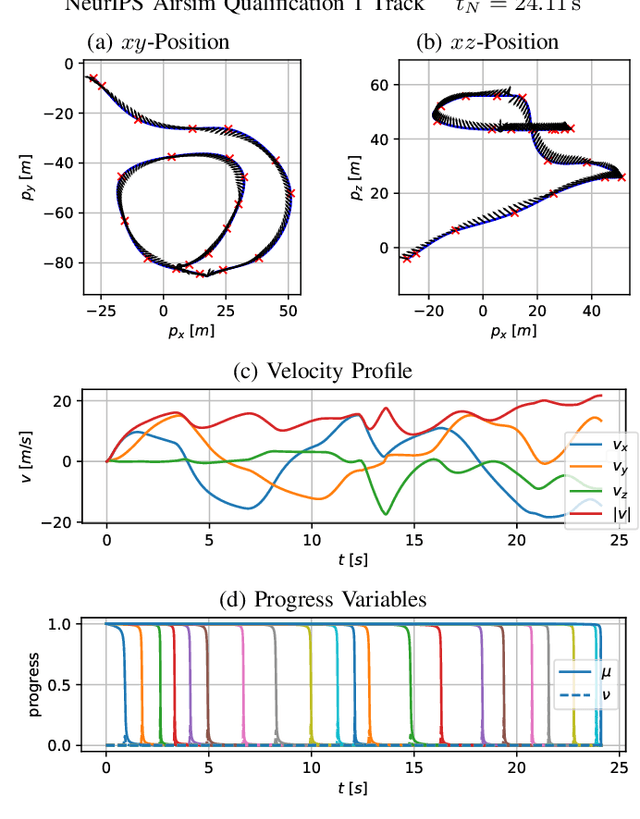
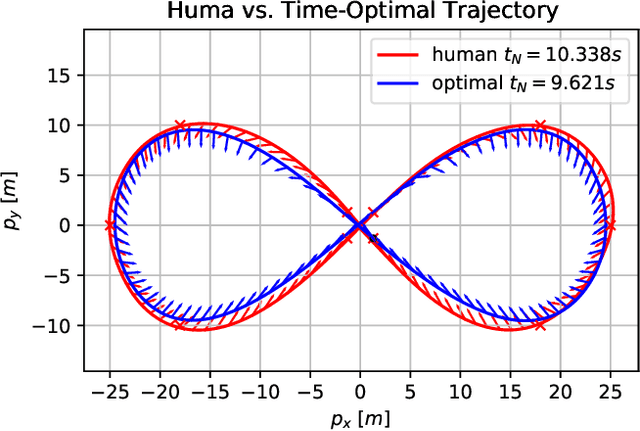
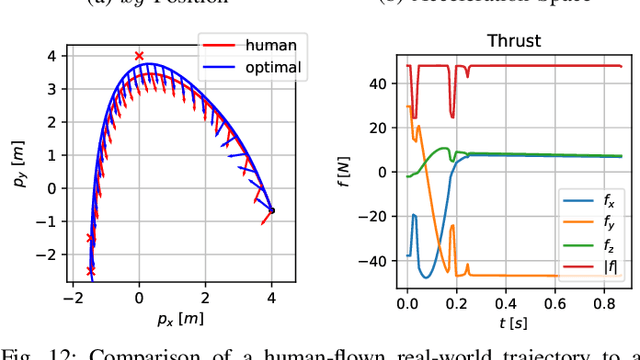
In many mobile robotics scenarios, such as drone racing, the goal is to generate a trajectory that passes through multiple waypoints in minimal time. This problem is referred to as time-optimal planning. State-of-the-art approaches either use polynomial trajectory formulations, which are suboptimal due to their smoothness, or numerical optimization, which requires waypoints to be allocated as costs or constraints to specific discrete-time nodes. For time-optimal planning, this time-allocation is a priori unknown and renders traditional approaches incapable of producing truly time-optimal trajectories. We introduce a novel formulation of progress bound to waypoints by a complementarity constraint. While the progress variables indicate the completion of a waypoint, change of this progress is only allowed in local proximity to the waypoint via complementarity constraints. This enables the simultaneous optimization of the trajectory and the time-allocation of the waypoints. To the best of our knowledge, this is the first approach allowing for truly time-optimal trajectory planning for quadrotors and other systems. We perform and discuss evaluations on optimality and convexity, compare to other related approaches, and qualitatively to an expert-human baseline.
Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives
Apr 18, 2022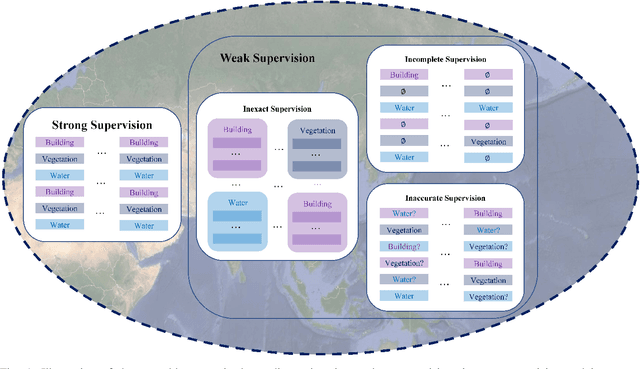
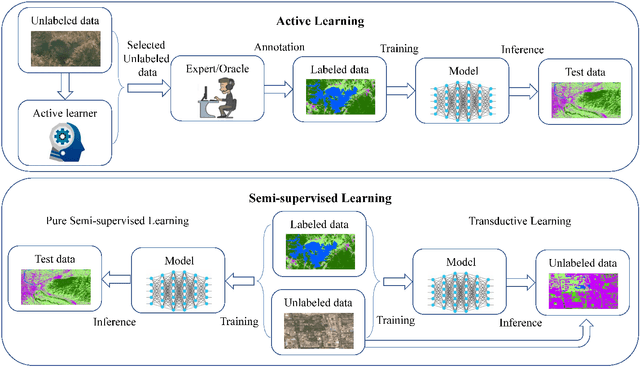
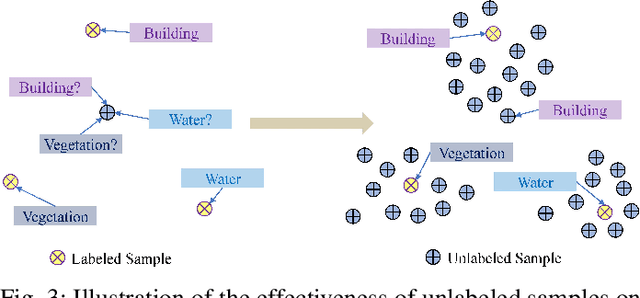

In recent years, supervised learning has been widely used in various tasks of optical remote sensing image understanding, including remote sensing image classification, pixel-wise segmentation, change detection, and object detection. The methods based on supervised learning need a large amount of high-quality training data and their performance highly depends on the quality of the labels. However, in practical remote sensing applications, it is often expensive and time-consuming to obtain large-scale data sets with high-quality labels, which leads to a lack of sufficient supervised information. In some cases, only coarse-grained labels can be obtained, resulting in the lack of exact supervision. In addition, the supervised information obtained manually may be wrong, resulting in a lack of accurate supervision. Therefore, remote sensing image understanding often faces the problems of incomplete, inexact, and inaccurate supervised information, which will affect the breadth and depth of remote sensing applications. In order to solve the above-mentioned problems, researchers have explored various tasks in remote sensing image understanding under weak supervision. This paper summarizes the research progress of weakly supervised learning in the field of remote sensing, including three typical weakly supervised paradigms: 1) Incomplete supervision, where only a subset of training data is labeled; 2) Inexact supervision, where only coarse-grained labels of training data are given; 3) Inaccurate supervision, where the labels given are not always true on the ground.