 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
Jan 30, 2022
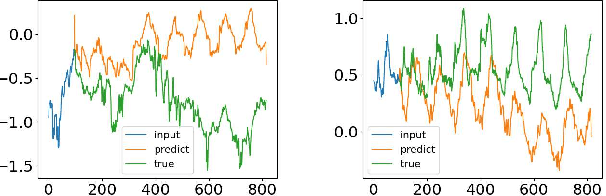
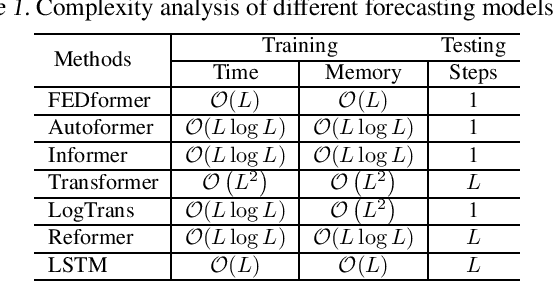
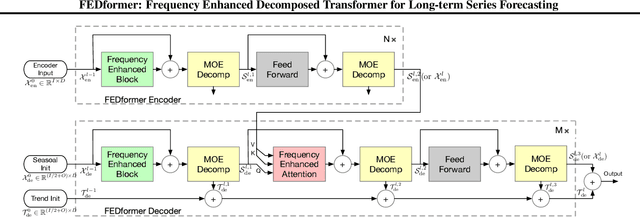
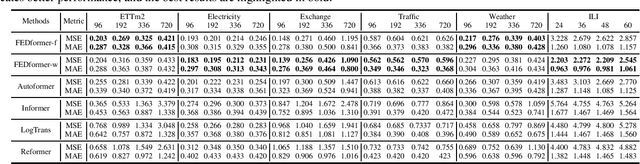
Although Transformer-based methods have significantly improved state-of-the-art results for long-term series forecasting, they are not only computationally expensive but more importantly, are unable to capture the global view of time series (e.g. overall trend). To address these problems, we propose to combine Transformer with the seasonal-trend decomposition method, in which the decomposition method captures the global profile of time series while Transformers capture more detailed structures. To further enhance the performance of Transformer for long-term prediction, we exploit the fact that most time series tend to have a sparse representation in well-known basis such as Fourier transform, and develop a frequency enhanced Transformer. Besides being more effective, the proposed method, termed as Frequency Enhanced Decomposed Transformer ({\bf FEDformer}), is more efficient than standard Transformer with a linear complexity to the sequence length. Our empirical studies with six benchmark datasets show that compared with state-of-the-art methods, FEDformer can reduce prediction error by $14.8\%$ and $22.6\%$ for multivariate and univariate time series, respectively. the code will be released soon.
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 11, 2021
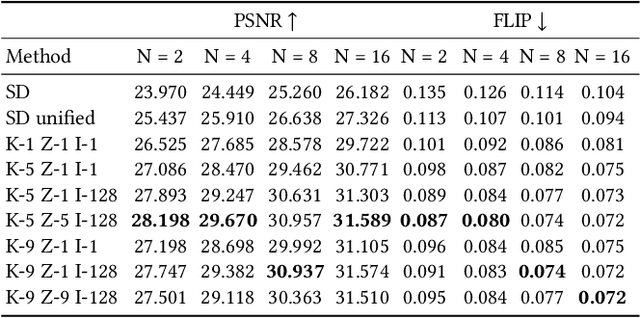
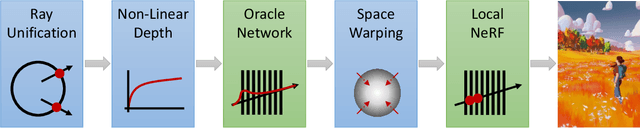
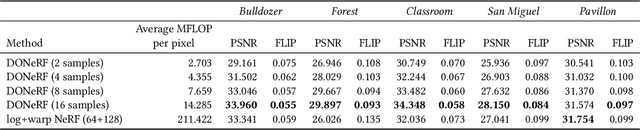
The recent research explosion around implicit neural representations, such as NeRF, shows that there is immense potential for implicitly storing high-quality scene and lighting information in neural networks. However, one major limitation preventing the use of NeRF in interactive and real-time rendering applications is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on consumer hardware. In this work, we take a step towards bringing neural representations closer to practical rendering of synthetic content in interactive and real-time applications, such as games and virtual reality. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF to enable interactive high-quality rendering.
Weakly-supervised Temporal Path Representation Learning with Contrastive Curriculum Learning -- Extended Version
Apr 01, 2022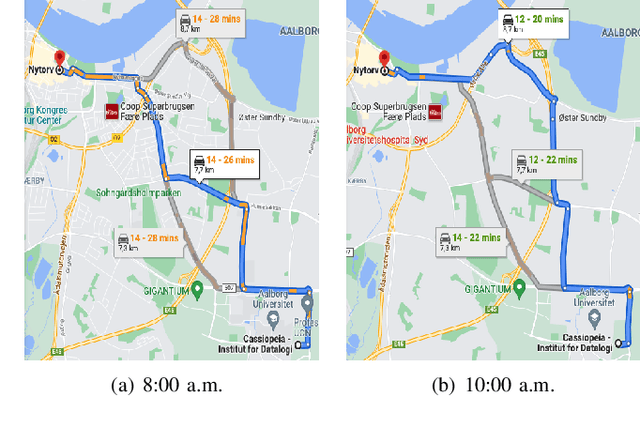
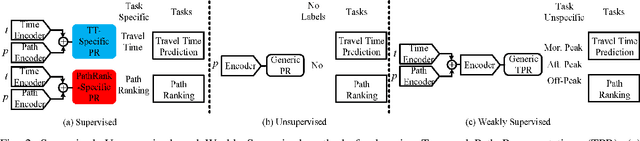
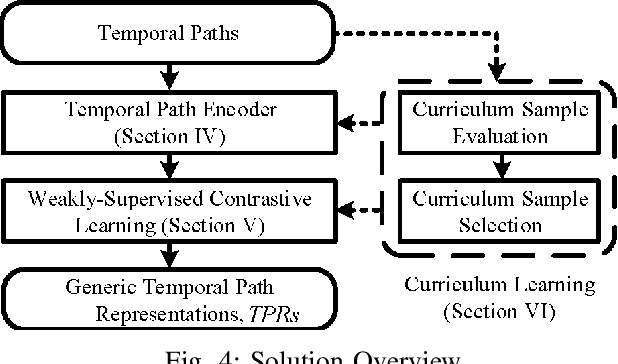
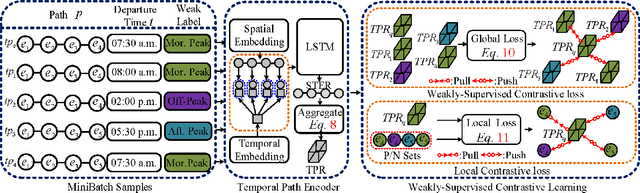
In step with the digitalization of transportation, we are witnessing a growing range of path-based smart-city applications, e.g., travel-time estimation and travel path ranking. A temporal path~(TP) that includes temporal information, e.g., departure time, into the path is of fundamental to enable such applications. In this setting, it is essential to learn generic temporal path representations~(TPRs) that consider spatial and temporal correlations simultaneously and that can be used in different applications, i.e., downstream tasks. Existing methods fail to achieve the goal since (i) supervised methods require large amounts of task-specific labels when training and thus fail to generalize the obtained TPRs to other tasks; (ii) though unsupervised methods can learn generic representations, they disregard the temporal aspect, leading to sub-optimal results. To contend with the limitations of existing solutions, we propose a Weakly-Supervised Contrastive (WSC) learning model. We first propose a temporal path encoder that encodes both the spatial and temporal information of a temporal path into a TPR. To train the encoder, we introduce weak labels that are easy and inexpensive to obtain, and are relevant to different tasks, e.g., temporal labels indicating peak vs. off-peak hour from departure times. Based on the weak labels, we construct meaningful positive and negative temporal path samples by considering both spatial and temporal information, which facilities training the encoder using contrastive learning by pulling closer the positive samples' representations while pushing away the negative samples' representations. To better guide the contrastive learning, we propose a learning strategy based on Curriculum Learning such that the learning performs from easy to hard training instances. Experiments studies verify the effectiveness of the proposed method.
Quadrotor Formation Flying Resilient to Abrupt Vehicle Failures via a Fluid Flow Navigation Function
Mar 03, 2022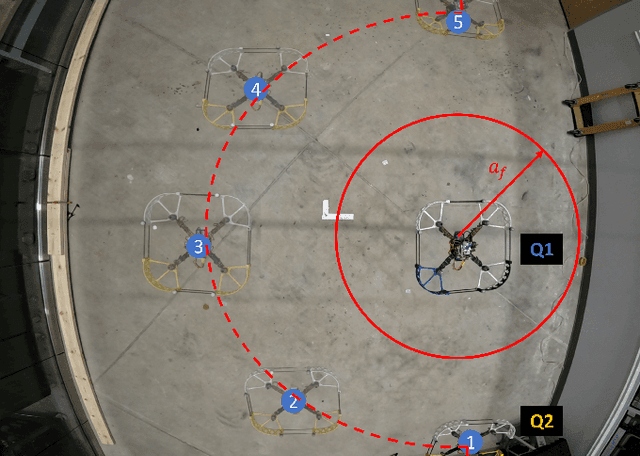
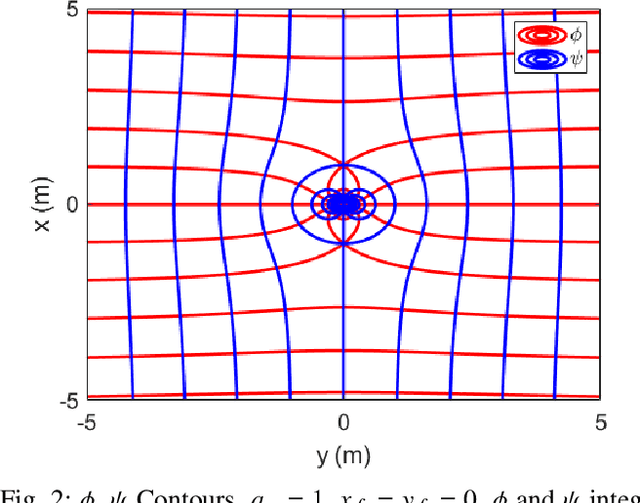
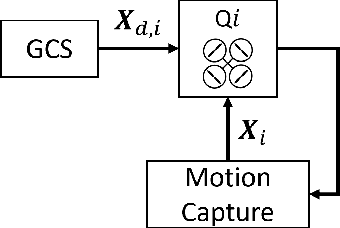
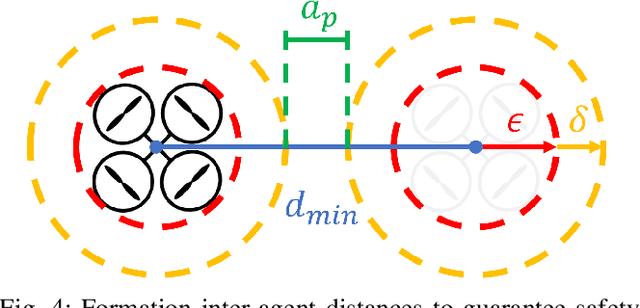
This paper develops and experimentally evaluates a navigation function for quadrotor formation flight that is resilient to abrupt quadrotor failures and other obstacles. The navigation function is based on modeling healthy quadrotors as particles in an ideal fluid flow. We provide three key contributions: (i) A Containment Exclusion Mode (CEM) safety theorem and proof which guarantees safety and formally specifies a minimum safe distance between quadrotors in formation, (ii) A real-time, computationally efficient CEM navigation algorithm, (iii) Simulation and experimental algorithm validation. Simulations were first performed with a team of six virtual quadrotors to demonstrate velocity tracking via dynamic slide speed, maintaining sufficient inter-agent distances, and operating in real-time. Flight tests with a team of two custom quadrotors were performed in an indoor motion capture flight facility, successfully validating that the navigation algorithm can handle non-trivial bounded tracking errors while guaranteeing safety.
Optimized Potential Initialization for Low-latency Spiking Neural Networks
Feb 03, 2022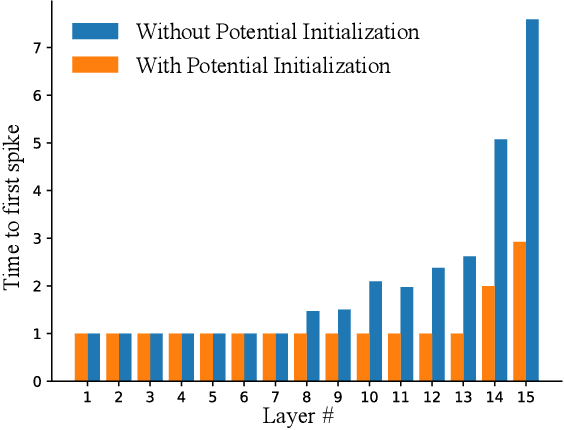
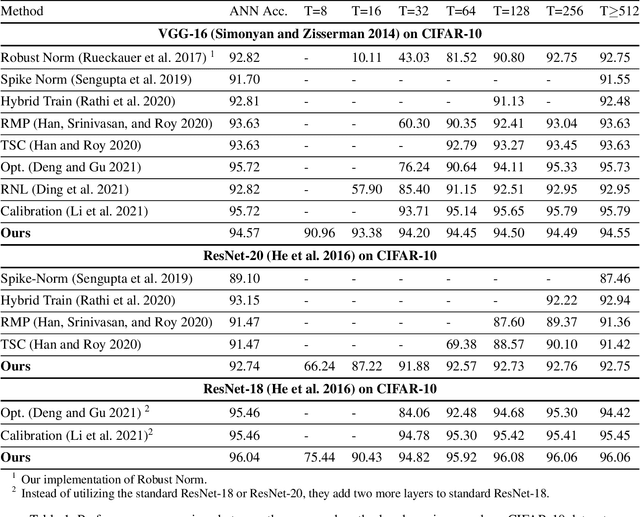
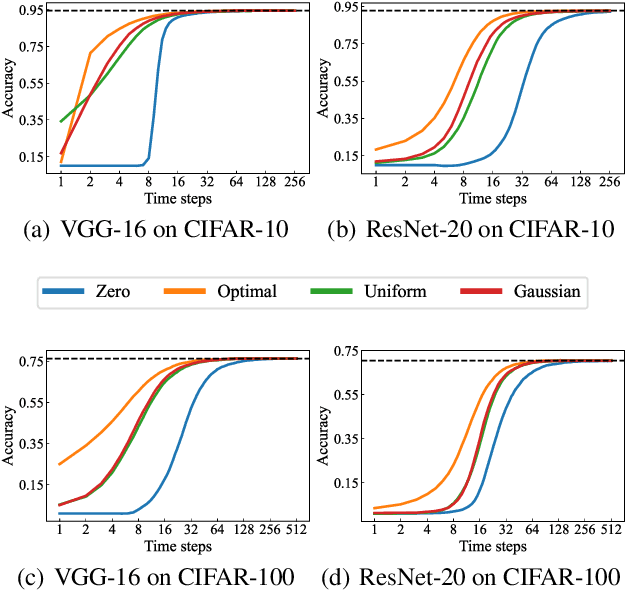
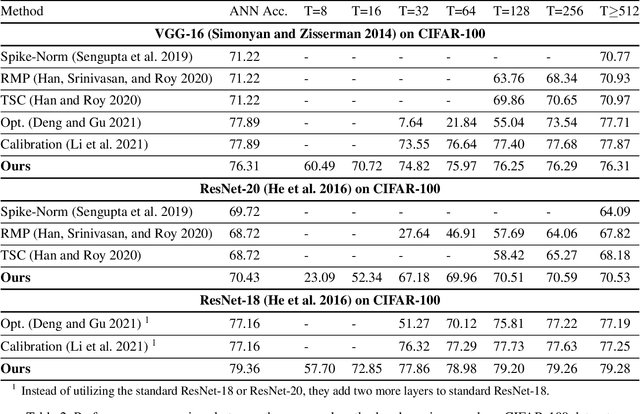
Spiking Neural Networks (SNNs) have been attached great importance due to the distinctive properties of low power consumption, biological plausibility, and adversarial robustness. The most effective way to train deep SNNs is through ANN-to-SNN conversion, which have yielded the best performance in deep network structure and large-scale datasets. However, there is a trade-off between accuracy and latency. In order to achieve high precision as original ANNs, a long simulation time is needed to match the firing rate of a spiking neuron with the activation value of an analog neuron, which impedes the practical application of SNN. In this paper, we aim to achieve high-performance converted SNNs with extremely low latency (fewer than 32 time-steps). We start by theoretically analyzing ANN-to-SNN conversion and show that scaling the thresholds does play a similar role as weight normalization. Instead of introducing constraints that facilitate ANN-to-SNN conversion at the cost of model capacity, we applied a more direct way by optimizing the initial membrane potential to reduce the conversion loss in each layer. Besides, we demonstrate that optimal initialization of membrane potentials can implement expected error-free ANN-to-SNN conversion. We evaluate our algorithm on the CIFAR-10, CIFAR-100 and ImageNet datasets and achieve state-of-the-art accuracy, using fewer time-steps. For example, we reach top-1 accuracy of 93.38\% on CIFAR-10 with 16 time-steps. Moreover, our method can be applied to other ANN-SNN conversion methodologies and remarkably promote performance when the time-steps is small.
A Derivation of Nesterov's Accelerated Gradient Algorithm from Optimal Control Theory
Mar 29, 2022Nesterov's accelerated gradient algorithm is derived from first principles. The first principles are founded on the recently-developed optimal control theory for optimization. This theory frames an optimization problem as an optimal control problem whose trajectories generate various continuous-time algorithms. The algorithmic trajectories satisfy the necessary conditions for optimal control. The necessary conditions produce a controllable dynamical system for accelerated optimization. Stabilizing this system via a quadratic control Lyapunov function generates an ordinary differential equation. An Euler discretization of the resulting differential equation produces Nesterov's algorithm. In this context, this result solves the purported mystery surrounding the algorithm.
Inverse Online Learning: Understanding Non-Stationary and Reactionary Policies
Mar 14, 2022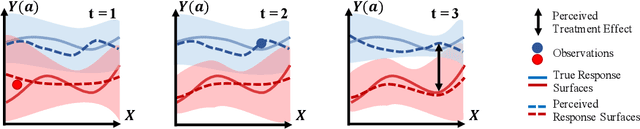
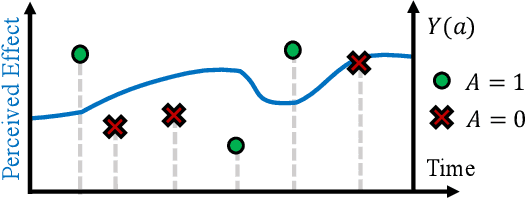
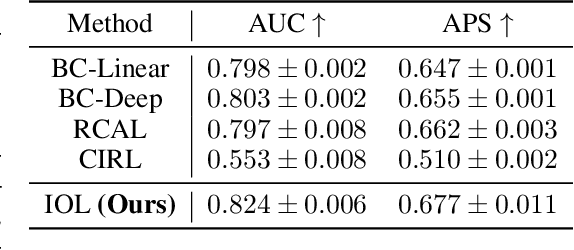
Human decision making is well known to be imperfect and the ability to analyse such processes individually is crucial when attempting to aid or improve a decision-maker's ability to perform a task, e.g. to alert them to potential biases or oversights on their part. To do so, it is necessary to develop interpretable representations of how agents make decisions and how this process changes over time as the agent learns online in reaction to the accrued experience. To then understand the decision-making processes underlying a set of observed trajectories, we cast the policy inference problem as the inverse to this online learning problem. By interpreting actions within a potential outcomes framework, we introduce a meaningful mapping based on agents choosing an action they believe to have the greatest treatment effect. We introduce a practical algorithm for retrospectively estimating such perceived effects, alongside the process through which agents update them, using a novel architecture built upon an expressive family of deep state-space models. Through application to the analysis of UNOS organ donation acceptance decisions, we demonstrate that our approach can bring valuable insights into the factors that govern decision processes and how they change over time.
Nonsmooth convex optimization to estimate the Covid-19 reproduction number space-time evolution with robustness against low quality data
Sep 20, 2021
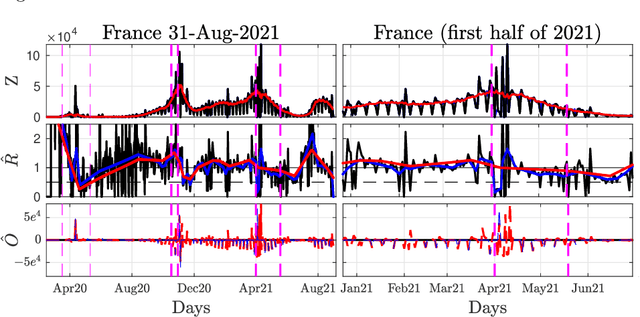
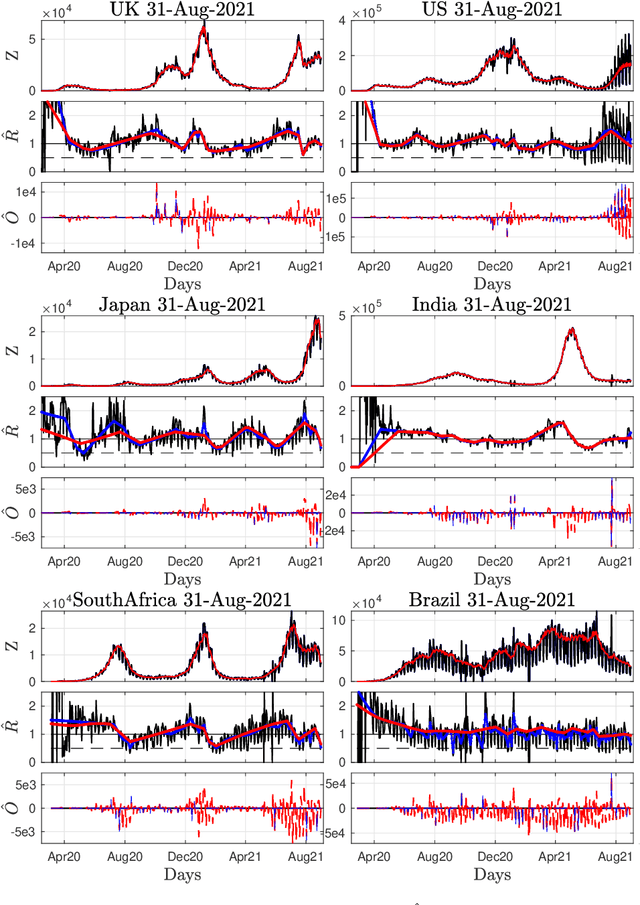
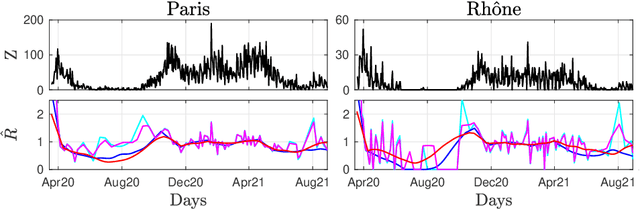
Daily pandemic surveillance, often achieved through the estimation of the reproduction number, constitutes a critical challenge for national health authorities to design countermeasures. In an earlier work, we proposed to formulate the estimation of the reproduction number as an optimization problem, combining data-model fidelity and space-time regularity constraints, solved by nonsmooth convex proximal minimizations. Though promising, that first formulation significantly lacks robustness against the Covid-19 data low quality (irrelevant or missing counts, pseudo-seasonalities,.. .) stemming from the emergency and crisis context, which significantly impairs accurate pandemic evolution assessments. The present work aims to overcome these limitations by carefully crafting a functional permitting to estimate jointly, in a single step, the reproduction number and outliers defined to model low quality data. This functional also enforces epidemiology-driven regularity properties for the reproduction number estimates, while preserving convexity, thus permitting the design of efficient minimization algorithms, based on proximity operators that are derived analytically. The explicit convergence of the proposed algorithm is proven theoretically. Its relevance is quantified on real Covid-19 data, consisting of daily new infection counts for 200+ countries and for the 96 metropolitan France counties, publicly available at Johns Hopkins University and Sant{\'e}-Publique-France. The procedure permits automated daily updates of these estimates, reported via animated and interactive maps. Open-source estimation procedures will be made publicly available.
Effectiveness of Delivered Information Trade Study
Mar 14, 2022
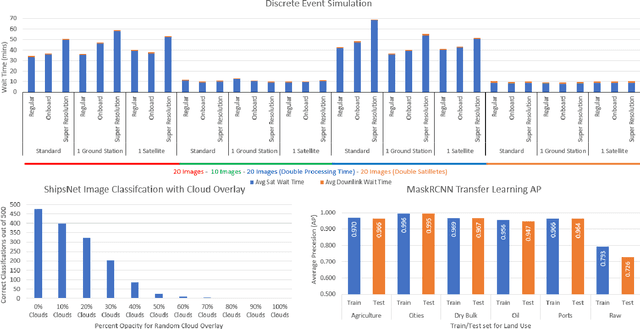

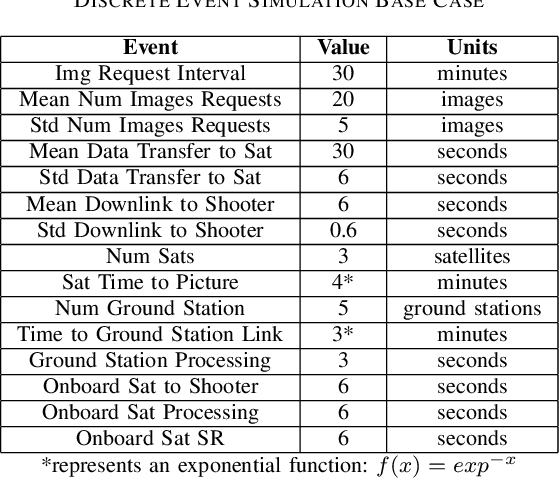
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
Atomic Filter: a Weak Form of Shift Operator for Graph Signals
Apr 01, 2022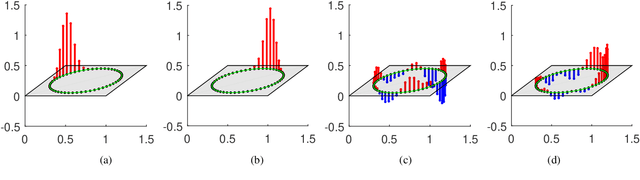
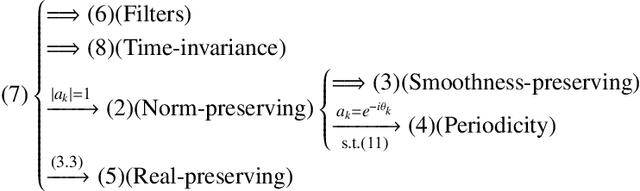
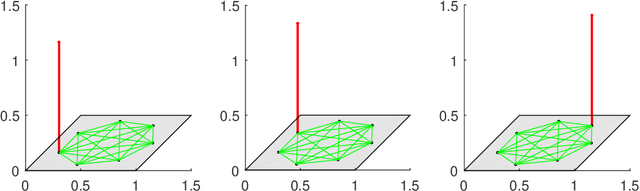
The shift operation plays a crucial role in the classical signal processing. It is the generator of all the filters and the basic operation for time-frequency analysis, such as windowed Fourier transform and wavelet transform. With the rapid development of internet technology and big data science, a large amount of data are expressed as signals defined on graphs. In order to establish the theory of filtering, windowed Fourier transform and wavelet transform in the setting of graph signals, we need to extend the shift operation of classical signals to graph signals. It is a fundamental problem since the vertex set of a graph is usually not a vector space and the addition operation cannot be defined on the vertex set of the graph. In this paper, based on our understanding on the core role of shift operation in classical signal processing we propose the concept of atomic filters, which can be viewed as a weak form of the shift operator for graph signals. Then, we study the conditions such that an atomic filter is norm-preserving, periodic, or real-preserving. The property of real-preserving holds naturally in the classical signal processing, but no the research has been reported on this topic in the graph signal setting. With these conditions we propose the concept of normal atomic filters for graph signals, which degenerates into the classical shift operator under mild conditions if the graph is circulant. Typical examples of graphs that have or have not normal atomic filters are given. Finally, as an application, atomic filters are utilized to construct time-frequency atoms which constitute a frame of the graph signal space.