 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UnseenNet: Fast Training Detector for Any Unseen Concept
Mar 26, 2022
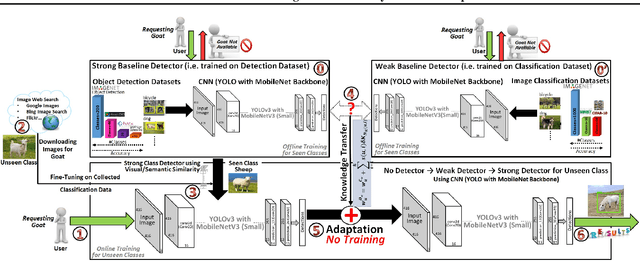
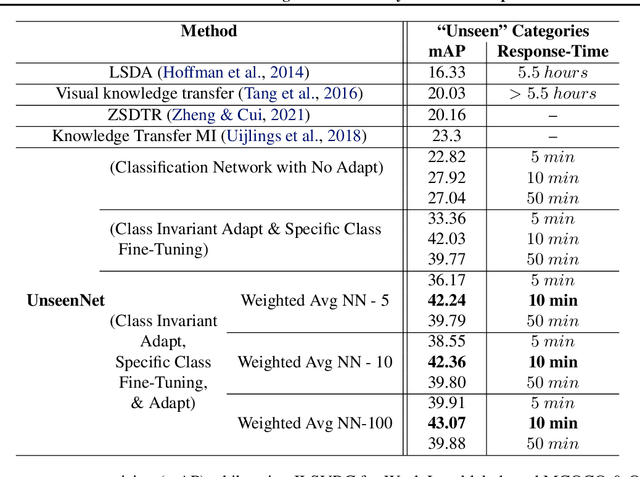
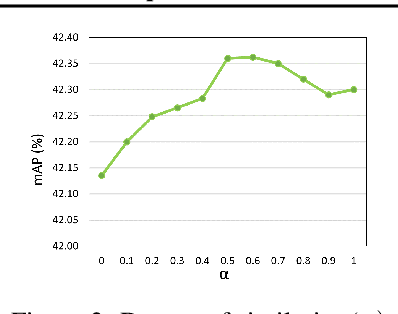
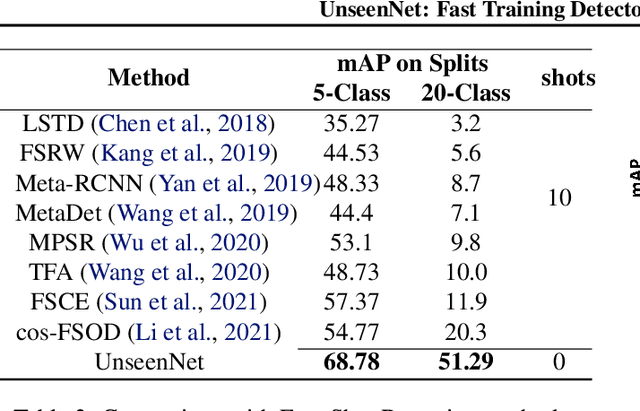
Training of object detection models using less data is currently the focus of existing N-shot learning models in computer vision. Such methods use object-level labels and takes hours to train on unseen classes. There are many cases where we have large amount of image-level labels available for training but cannot be utilized by few shot object detection models for training. There is a need for a machine learning framework that can be used for training any unseen class and can become useful in real-time situations. In this paper, we proposed an "Unseen Class Detector" that can be trained within a very short time for any possible unseen class without bounding boxes with competitive accuracy. We build our approach on "Strong" and "Weak" baseline detectors, which we trained on existing object detection and image classification datasets, respectively. Unseen concepts are fine-tuned on the strong baseline detector using only image-level labels and further adapted by transferring the classifier-detector knowledge between baselines. We use semantic as well as visual similarities to identify the source class (i.e. Sheep) for the fine-tuning and adaptation of unseen class (i.e. Goat). Our model (UnseenNet) is trained on the ImageNet classification dataset for unseen classes and tested on an object detection dataset (OpenImages). UnseenNet improves the mean average precision (mAP) by 10% to 30% over existing baselines (semi-supervised and few-shot) of object detection on different unseen class splits. Moreover, training time of our model is <10 min for each unseen class. Qualitative results demonstrate that UnseenNet is suitable not only for few classes of Pascal VOC but for unseen classes of any dataset or web. Code is available at https://github.com/Asra-Aslam/UnseenNet.
Hybrid Manufacturing Process Planning for Arbitrary Part and Tool Shapes
May 24, 2022
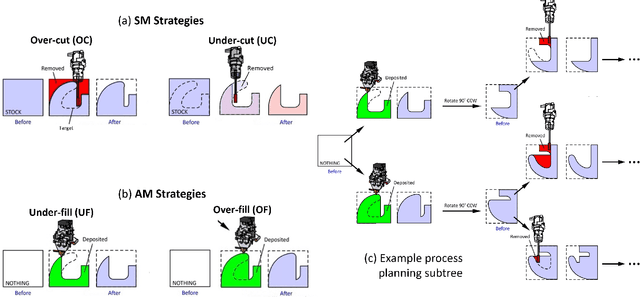
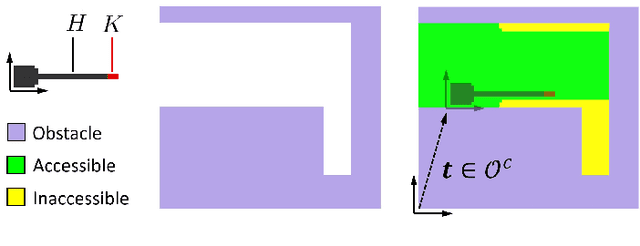
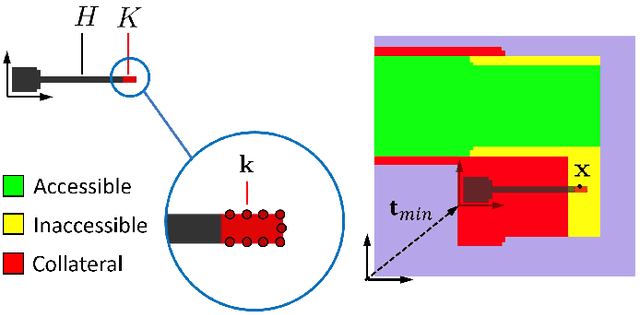
Hybrid manufacturing (HM) technologies combine additive and subtractive manufacturing (AM/SM) capabilities in multi-modal process plans that leverage the strengths of each. Despite the growing interest in HM technologies, software tools for process planning have not caught up with advances in hardware and typically impose restrictions that limit the design and manufacturing engineers' ability to systematically explore the full design and process planning spaces. We present a general framework for identifying AM/SM actions that make up an HM process plan based on accessibility and support requirements, using morphological operations that allow for arbitrary part and tool geometries to be considered. To take advantage of multi-modality, we define the actions to allow for temporary excessive material deposition or removal, with an understanding that subsequent actions can correct for them, unlike the case in unimodal (AM-only or SM-only) process plans that are monotonic. We use this framework to generate a combinatorial space of valid, potentially non-monotonic, process plans for a given part of arbitrary shape, a collection of AM/SM tools of arbitrary shapes, and a set of relative rotations (fixed for each action) between them, representing build/fixturing directions on $3-$axis machines. Finally, we use define a simple objective function quantifying the cost of materials and operating time in terms of deposition/removal volumes and use a search algorithm to explore the exponentially large space of valid process plans to find "cost-optimal" solutions. We demonstrate the effectiveness of our method on 3D examples.
* Special Issue on symposium on Solid and Physical Modeling (SPM'2022)
Simple Contrastive Graph Clustering
May 11, 2022

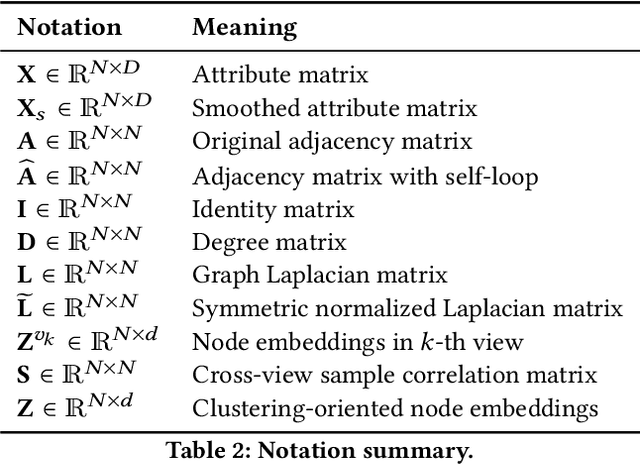
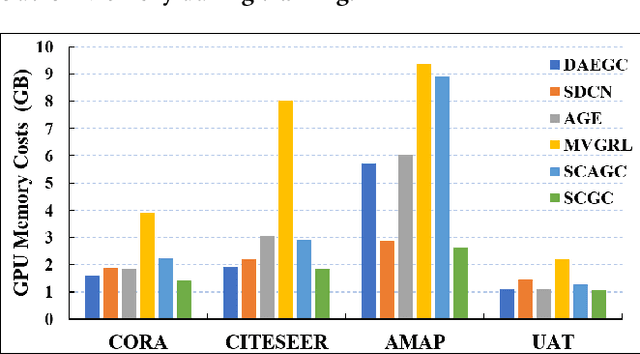
Contrastive learning has recently attracted plenty of attention in deep graph clustering for its promising performance. However, complicated data augmentations and time-consuming graph convolutional operation undermine the efficiency of these methods. To solve this problem, we propose a Simple Contrastive Graph Clustering (SCGC) algorithm to improve the existing methods from the perspectives of network architecture, data augmentation, and objective function. As to the architecture, our network includes two main parts, i.e., pre-processing and network backbone. A simple low-pass denoising operation conducts neighbor information aggregation as an independent pre-processing, and only two multilayer perceptrons (MLPs) are included as the backbone. For data augmentation, instead of introducing complex operations over graphs, we construct two augmented views of the same vertex by designing parameter un-shared siamese encoders and corrupting the node embeddings directly. Finally, as to the objective function, to further improve the clustering performance, a novel cross-view structural consistency objective function is designed to enhance the discriminative capability of the learned network. Extensive experimental results on seven benchmark datasets validate our proposed algorithm's effectiveness and superiority. Significantly, our algorithm outperforms the recent contrastive deep clustering competitors with at least seven times speedup on average.
Parallel Training of GRU Networks with a Multi-Grid Solver for Long Sequences
Mar 07, 2022

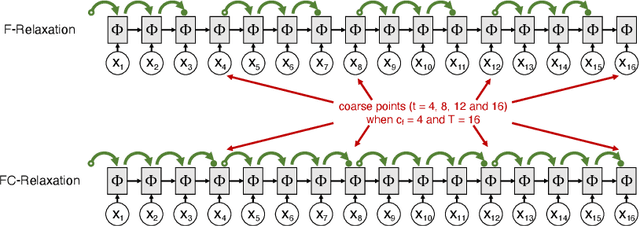

Parallelizing Gated Recurrent Unit (GRU) networks is a challenging task, as the training procedure of GRU is inherently sequential. Prior efforts to parallelize GRU have largely focused on conventional parallelization strategies such as data-parallel and model-parallel training algorithms. However, when the given sequences are very long, existing approaches are still inevitably performance limited in terms of training time. In this paper, we present a novel parallel training scheme (called parallel-in-time) for GRU based on a multigrid reduction in time (MGRIT) solver. MGRIT partitions a sequence into multiple shorter sub-sequences and trains the sub-sequences on different processors in parallel. The key to achieving speedup is a hierarchical correction of the hidden state to accelerate end-to-end communication in both the forward and backward propagation phases of gradient descent. Experimental results on the HMDB51 dataset, where each video is an image sequence, demonstrate that the new parallel training scheme achieves up to 6.5$\times$ speedup over a serial approach. As efficiency of our new parallelization strategy is associated with the sequence length, our parallel GRU algorithm achieves significant performance improvement as the sequence length increases.
Time-Supervised Primary Object Segmentation
Aug 16, 2020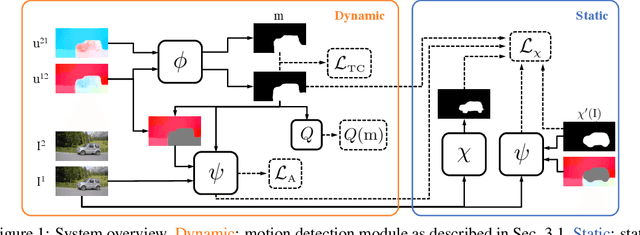



We describe an unsupervised method to detect and segment portions of live scenes that, at some point in time, are seen moving as a coherent whole, which we refer to as primary objects. Our method first segments motions by minimizing the mutual information between partitions of the image domain, which bootstraps a static object detection model that takes a single image as input. The two models are mutually reinforced within a feedback loop, enabling extrapolation to previously unseen classes of objects. Our method requires video for training, but can be used on either static images or videos at inference time. As the volume of our training sets grows, more and more objects are seen moving, thus turning our method into unsupervised (or time-supervised) training to segment primary objects. The resulting system outperforms the state-of-the-art in both video object segmentation and salient object detection benchmarks, even when compared to methods that use explicit manual annotation.
Differentiable Zooming for Multiple Instance Learning on Whole-Slide Images
Apr 30, 2022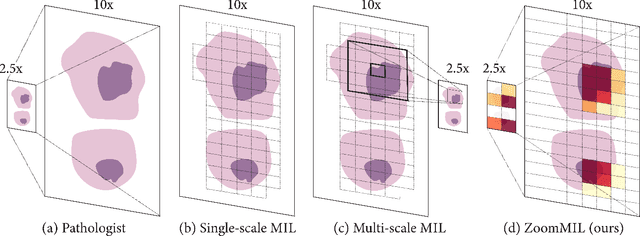
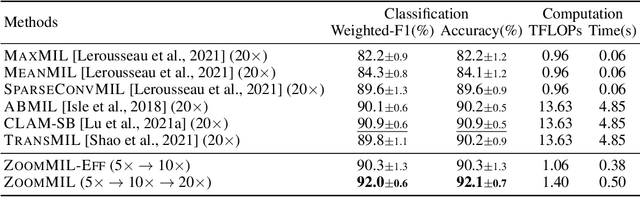
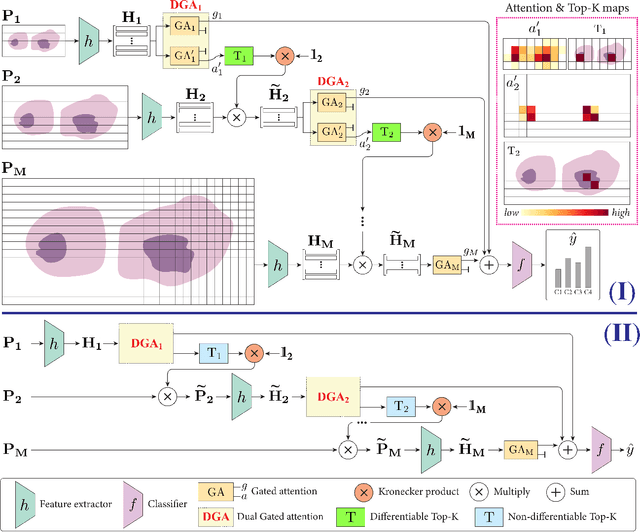
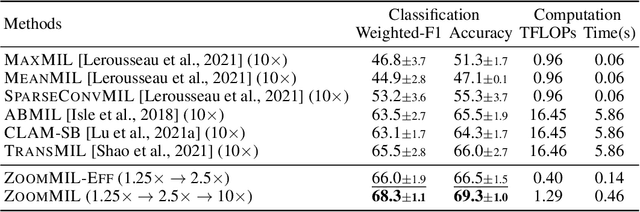
Multiple Instance Learning (MIL) methods have become increasingly popular for classifying giga-pixel sized Whole-Slide Images (WSIs) in digital pathology. Most MIL methods operate at a single WSI magnification, by processing all the tissue patches. Such a formulation induces high computational requirements, and constrains the contextualization of the WSI-level representation to a single scale. A few MIL methods extend to multiple scales, but are computationally more demanding. In this paper, inspired by the pathological diagnostic process, we propose ZoomMIL, a method that learns to perform multi-level zooming in an end-to-end manner. ZoomMIL builds WSI representations by aggregating tissue-context information from multiple magnifications. The proposed method outperforms the state-of-the-art MIL methods in WSI classification on two large datasets, while significantly reducing the computational demands with regard to Floating-Point Operations (FLOPs) and processing time by up to 40x.
FullSubNet+: Channel Attention FullSubNet with Complex Spectrograms for Speech Enhancement
Mar 26, 2022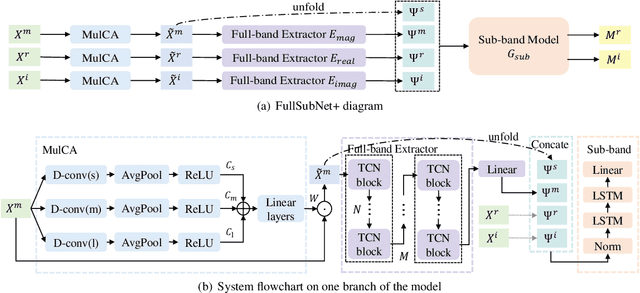
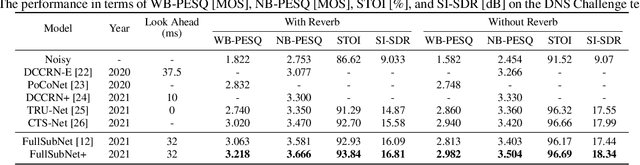
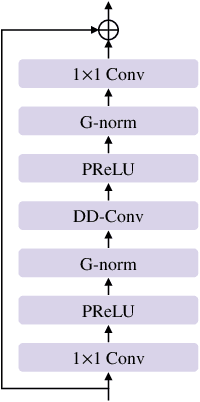

Previously proposed FullSubNet has achieved outstanding performance in Deep Noise Suppression (DNS) Challenge and attracted much attention. However, it still encounters issues such as input-output mismatch and coarse processing for frequency bands. In this paper, we propose an extended single-channel real-time speech enhancement framework called FullSubNet+ with following significant improvements. First, we design a lightweight multi-scale time sensitive channel attention (MulCA) module which adopts multi-scale convolution and channel attention mechanism to help the network focus on more discriminative frequency bands for noise reduction. Then, to make full use of the phase information in noisy speech, our model takes all the magnitude, real and imaginary spectrograms as inputs. Moreover, by replacing the long short-term memory (LSTM) layers in original full-band model with stacked temporal convolutional network (TCN) blocks, we design a more efficient full-band module called full-band extractor. The experimental results in DNS Challenge dataset show the superior performance of our FullSubNet+, which reaches the state-of-the-art (SOTA) performance and outperforms other existing speech enhancement approaches.
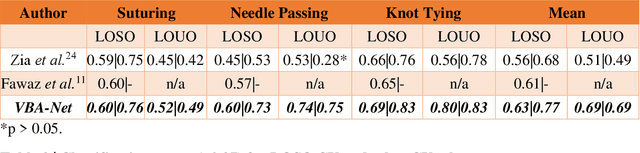
Video-based Formative and Summative Assessment of Surgical Tasks using Deep Learning
Mar 17, 2022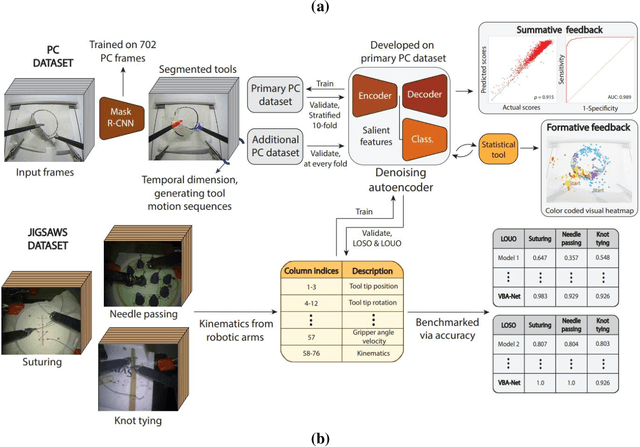
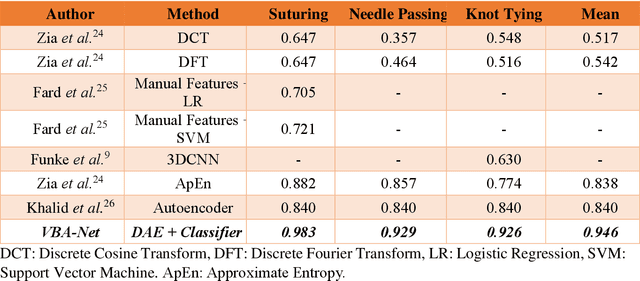
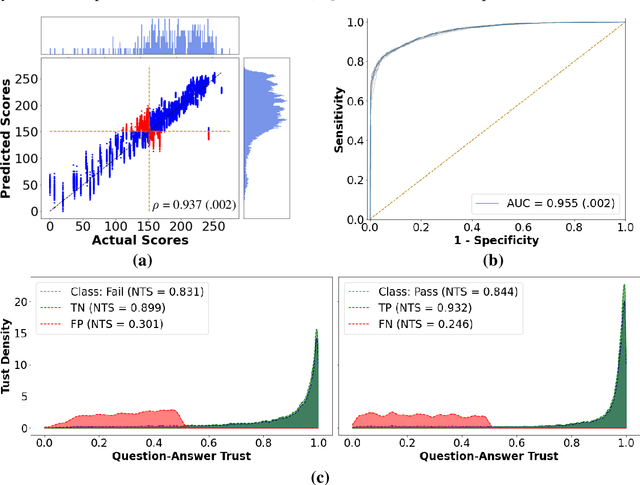
To ensure satisfactory clinical outcomes, surgical skill assessment must be objective, time-efficient, and preferentially automated - none of which is currently achievable. Video-based assessment (VBA) is being deployed in intraoperative and simulation settings to evaluate technical skill execution. However, VBA remains manually- and time-intensive and prone to subjective interpretation and poor inter-rater reliability. Herein, we propose a deep learning (DL) model that can automatically and objectively provide a high-stakes summative assessment of surgical skill execution based on video feeds and low-stakes formative assessment to guide surgical skill acquisition. Formative assessment is generated using heatmaps of visual features that correlate with surgical performance. Hence, the DL model paves the way to the quantitative and reproducible evaluation of surgical tasks from videos with the potential for broad dissemination in surgical training, certification, and credentialing.
Intelligent Reflecting Surface Configurations for Smart Radio Using Deep Reinforcement Learning
May 11, 2022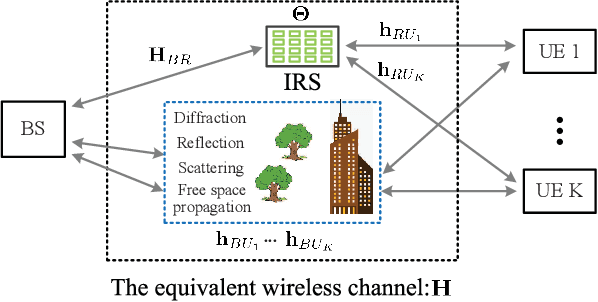
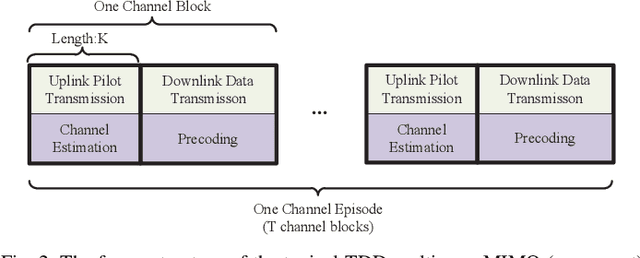

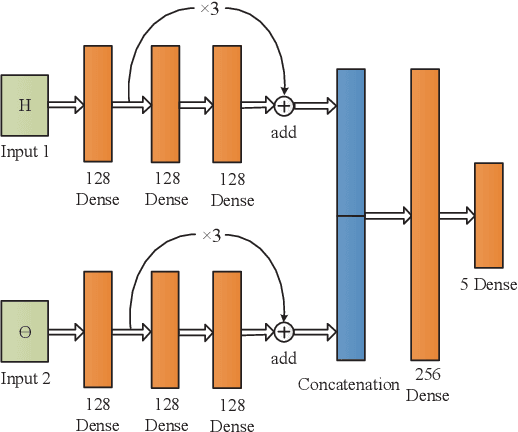
Intelligent reflecting surface (IRS) is envisioned to change the paradigm of wireless communications from "adapting to wireless channels" to "changing wireless channels". However, current IRS configuration schemes, consisting of sub-channel estimation and passive beamforming in sequence, conform to the conventional model-based design philosophies and are difficult to be realized practically in the complex radio environment. To create the smart radio environment, we propose a model-free design of IRS control that is independent of the sub-channel channel state information (CSI) and requires the minimum interaction between IRS and the wireless communication system. We firstly model the control of IRS as a Markov decision process (MDP) and apply deep reinforcement learning (DRL) to perform real-time coarse phase control of IRS. Then, we apply extremum seeking control (ESC) as the fine phase control of IRS. Finally, by updating the frame structure, we integrate DRL and ESC in the model-free control of IRS to improve its adaptivity to different channel dynamics. Numerical results show the superiority of our proposed joint DRL and ESC scheme and verify its effectiveness in model-free IRS control without sub-channel CSI.
A globally convergent fast iterative shrinkage-thresholding algorithm with a new momentum factor for single and multi-objective convex optimization
May 11, 2022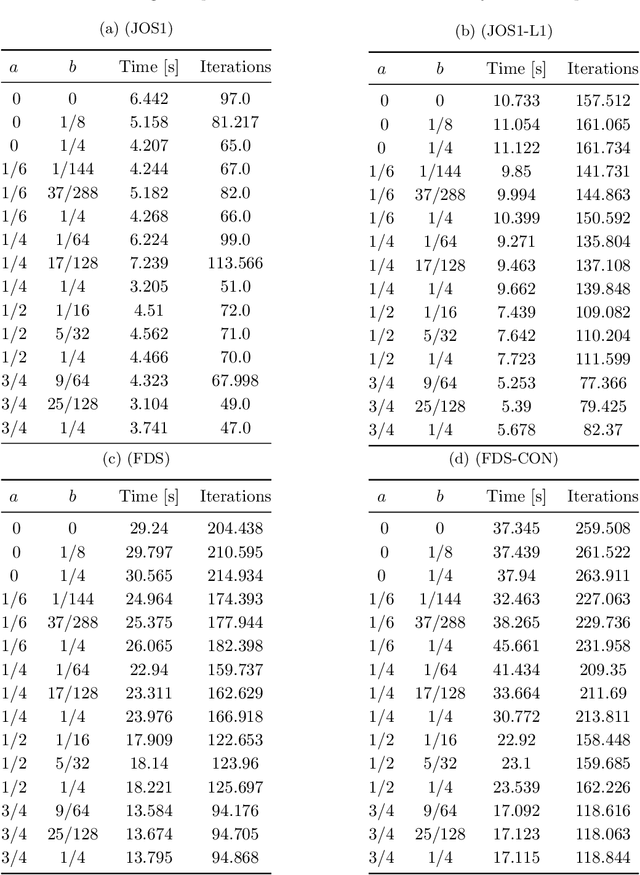
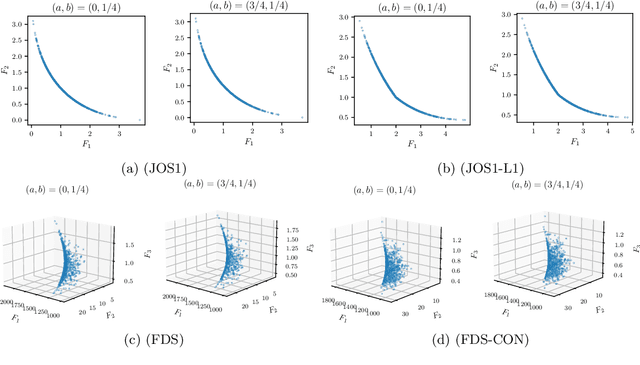

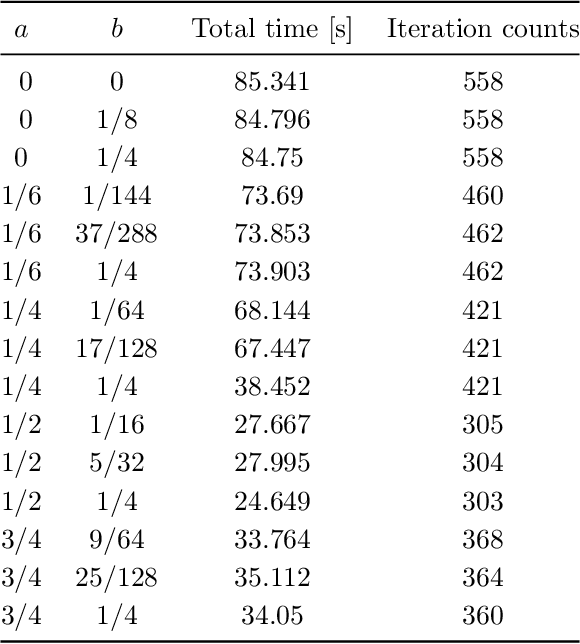
Convex-composite optimization, which minimizes an objective function represented by the sum of a differentiable function and a convex one, is widely used in machine learning and signal/image processing. Fast Iterative Shrinkage Thresholding Algorithm (FISTA) is a typical method for solving this problem and has a global convergence rate of $O(1 / k^2)$. Recently, this has been extended to multi-objective optimization, together with the proof of the $O(1 / k^2)$ global convergence rate. However, its momentum factor is classical, and the convergence of its iterates has not been proven. In this work, introducing some additional hyperparameters $(a, b)$, we propose another accelerated proximal gradient method with a general momentum factor, which is new even for the single-objective cases. We show that our proposed method also has a global convergence rate of $O(1/k^2)$ for any $(a,b)$, and further that the generated sequence of iterates converges to a weak Pareto solution when $a$ is positive, an essential property for the finite-time manifold identification. Moreover, we report numerical results with various $(a,b)$, showing that some of these choices give better results than the classical momentum factors.