 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Training for Kolmogorov Arnold Networks
Mar 05, 2026Algorithmic speedup of training common neural architectures is made difficult by the lack of structure guaranteed by the function compositions inherent to such networks. In contrast to multilayer perceptrons (MLPs), Kolmogorov-Arnold networks (KANs) provide more structure by expanding learned activations in a specified basis. This paper exploits this structure to develop practical algorithms and theoretical insights, yielding training speedup via multilevel training for KANs. To do so, we first establish an equivalence between KANs with spline basis functions and multichannel MLPs with power ReLU activations through a linear change of basis. We then analyze how this change of basis affects the geometry of gradient-based optimization with respect to spline knots. The KANs change-of-basis motivates a multilevel training approach, where we train a sequence of KANs naturally defined through a uniform refinement of spline knots with analytic geometric interpolation operators between models. The interpolation scheme enables a ``properly nested hierarchy'' of architectures, ensuring that interpolation to a fine model preserves the progress made on coarse models, while the compact support of spline basis functions ensures complementary optimization on subsequent levels. Numerical experiments demonstrate that our multilevel training approach can achieve orders of magnitude improvement in accuracy over conventional methods to train comparable KANs or MLPs, particularly for physics informed neural networks. Finally, this work demonstrates how principled design of neural networks can lead to exploitable structure, and in this case, multilevel algorithms that can dramatically improve training performance.
Layer-Parallel Training for Transformers
Jan 13, 2026We present a new training methodology for transformers using a multilevel, layer-parallel approach. Through a neural ODE formulation of transformers, our application of a multilevel parallel-in-time algorithm for the forward and backpropagation phases of training achieves parallel acceleration over the layer dimension. This dramatically enhances parallel scalability as the network depth increases, which is particularly useful for increasingly large foundational models. However, achieving this introduces errors that cause systematic bias in the gradients, which in turn reduces convergence when closer to the minima. We develop an algorithm to detect this critical transition and either switch to serial training or systematically increase the accuracy of layer-parallel training. Results, including BERT, GPT2, ViT, and machine translation architectures, demonstrate parallel-acceleration as well as accuracy commensurate with serial pre-training while fine-tuning is unaffected.
Interpreting Transformer Architectures as Implicit Multinomial Regression
Sep 04, 2025Mechanistic interpretability aims to understand how internal components of modern machine learning models, such as weights, activations, and layers, give rise to the model's overall behavior. One particularly opaque mechanism is attention: despite its central role in transformer models, its mathematical underpinnings and relationship to concepts like feature polysemanticity, superposition, and model performance remain poorly understood. This paper establishes a novel connection between attention mechanisms and multinomial regression. Specifically, we show that in a fixed multinomial regression setting, optimizing over latent features yields optimal solutions that align with the dynamics induced by attention blocks. In other words, the evolution of representations through a transformer can be interpreted as a trajectory that recovers the optimal features for classification.
Leveraging KANs for Expedient Training of Multichannel MLPs via Preconditioning and Geometric Refinement
May 23, 2025Multilayer perceptrons (MLPs) are a workhorse machine learning architecture, used in a variety of modern deep learning frameworks. However, recently Kolmogorov-Arnold Networks (KANs) have become increasingly popular due to their success on a range of problems, particularly for scientific machine learning tasks. In this paper, we exploit the relationship between KANs and multichannel MLPs to gain structural insight into how to train MLPs faster. We demonstrate the KAN basis (1) provides geometric localized support, and (2) acts as a preconditioned descent in the ReLU basis, overall resulting in expedited training and improved accuracy. Our results show the equivalence between free-knot spline KAN architectures, and a class of MLPs that are refined geometrically along the channel dimension of each weight tensor. We exploit this structural equivalence to define a hierarchical refinement scheme that dramatically accelerates training of the multi-channel MLP architecture. We show further accuracy improvements can be had by allowing the $1$D locations of the spline knots to be trained simultaneously with the weights. These advances are demonstrated on a range of benchmark examples for regression and scientific machine learning.
Gaussian Variational Schemes on Bounded and Unbounded Domains
Oct 08, 2024



A machine-learnable variational scheme using Gaussian radial basis functions (GRBFs) is presented and used to approximate linear problems on bounded and unbounded domains. In contrast to standard mesh-free methods, which use GRBFs to discretize strong-form differential equations, this work exploits the relationship between integrals of GRBFs, their derivatives, and polynomial moments to produce exact quadrature formulae which enable weak-form expressions. Combined with trainable GRBF means and covariances, this leads to a flexible, generalized Galerkin variational framework which is applied in the infinite-domain setting where the scheme is conforming, as well as the bounded-domain setting where it is not. Error rates for the proposed GRBF scheme are derived in each case, and examples are presented demonstrating utility of this approach as a surrogate modeling technique.
DDU-Net: A Domain Decomposition-based CNN for High-Resolution Image Segmentation on Multiple GPUs
Aug 01, 2024The segmentation of ultra-high resolution images poses challenges such as loss of spatial information or computational inefficiency. In this work, a novel approach that combines encoder-decoder architectures with domain decomposition strategies to address these challenges is proposed. Specifically, a domain decomposition-based U-Net (DDU-Net) architecture is introduced, which partitions input images into non-overlapping patches that can be processed independently on separate devices. A communication network is added to facilitate inter-patch information exchange to enhance the understanding of spatial context. Experimental validation is performed on a synthetic dataset that is designed to measure the effectiveness of the communication network. Then, the performance is tested on the DeepGlobe land cover classification dataset as a real-world benchmark data set. The results demonstrate that the approach, which includes inter-patch communication for images divided into $16\times16$ non-overlapping subimages, achieves a $2-3\,\%$ higher intersection over union (IoU) score compared to the same network without inter-patch communication. The performance of the network which includes communication is equivalent to that of a baseline U-Net trained on the full image, showing that our model provides an effective solution for segmenting ultra-high-resolution images while preserving spatial context. The code is available at https://github.com/corne00/HiRes-Seg-CNN.
Graph Neural Networks and Applied Linear Algebra
Oct 21, 2023Sparse matrix computations are ubiquitous in scientific computing. With the recent interest in scientific machine learning, it is natural to ask how sparse matrix computations can leverage neural networks (NN). Unfortunately, multi-layer perceptron (MLP) neural networks are typically not natural for either graph or sparse matrix computations. The issue lies with the fact that MLPs require fixed-sized inputs while scientific applications generally generate sparse matrices with arbitrary dimensions and a wide range of nonzero patterns (or matrix graph vertex interconnections). While convolutional NNs could possibly address matrix graphs where all vertices have the same number of nearest neighbors, a more general approach is needed for arbitrary sparse matrices, e.g. arising from discretized partial differential equations on unstructured meshes. Graph neural networks (GNNs) are one approach suitable to sparse matrices. GNNs define aggregation functions (e.g., summations) that operate on variable size input data to produce data of a fixed output size so that MLPs can be applied. The goal of this paper is to provide an introduction to GNNs for a numerical linear algebra audience. Concrete examples are provided to illustrate how many common linear algebra tasks can be accomplished using GNNs. We focus on iterative methods that employ computational kernels such as matrix-vector products, interpolation, relaxation methods, and strength-of-connection measures. Our GNN examples include cases where parameters are determined a-priori as well as cases where parameters must be learned. The intent with this article is to help computational scientists understand how GNNs can be used to adapt machine learning concepts to computational tasks associated with sparse matrices. It is hoped that this understanding will stimulate data-driven extensions of classical sparse linear algebra tasks.
Parallel Training of GRU Networks with a Multi-Grid Solver for Long Sequences
Mar 07, 2022

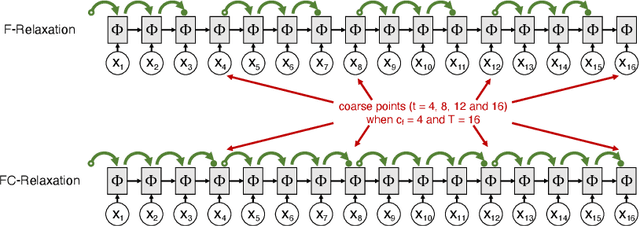

Parallelizing Gated Recurrent Unit (GRU) networks is a challenging task, as the training procedure of GRU is inherently sequential. Prior efforts to parallelize GRU have largely focused on conventional parallelization strategies such as data-parallel and model-parallel training algorithms. However, when the given sequences are very long, existing approaches are still inevitably performance limited in terms of training time. In this paper, we present a novel parallel training scheme (called parallel-in-time) for GRU based on a multigrid reduction in time (MGRIT) solver. MGRIT partitions a sequence into multiple shorter sub-sequences and trains the sub-sequences on different processors in parallel. The key to achieving speedup is a hierarchical correction of the hidden state to accelerate end-to-end communication in both the forward and backward propagation phases of gradient descent. Experimental results on the HMDB51 dataset, where each video is an image sequence, demonstrate that the new parallel training scheme achieves up to 6.5$\times$ speedup over a serial approach. As efficiency of our new parallelization strategy is associated with the sequence length, our parallel GRU algorithm achieves significant performance improvement as the sequence length increases.
Partition of unity networks: deep hp-approximation
Jan 27, 2021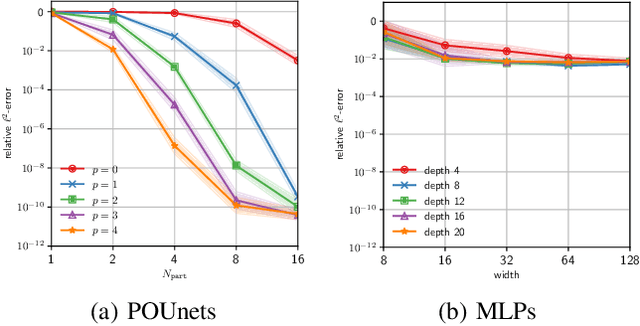
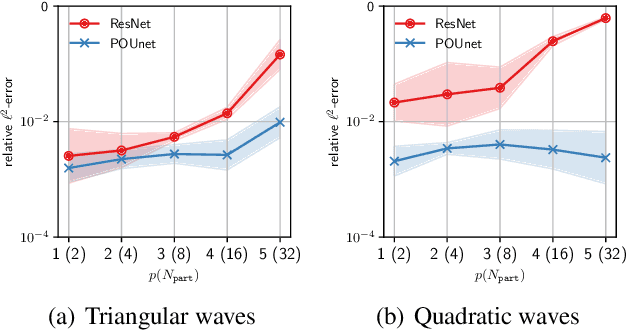
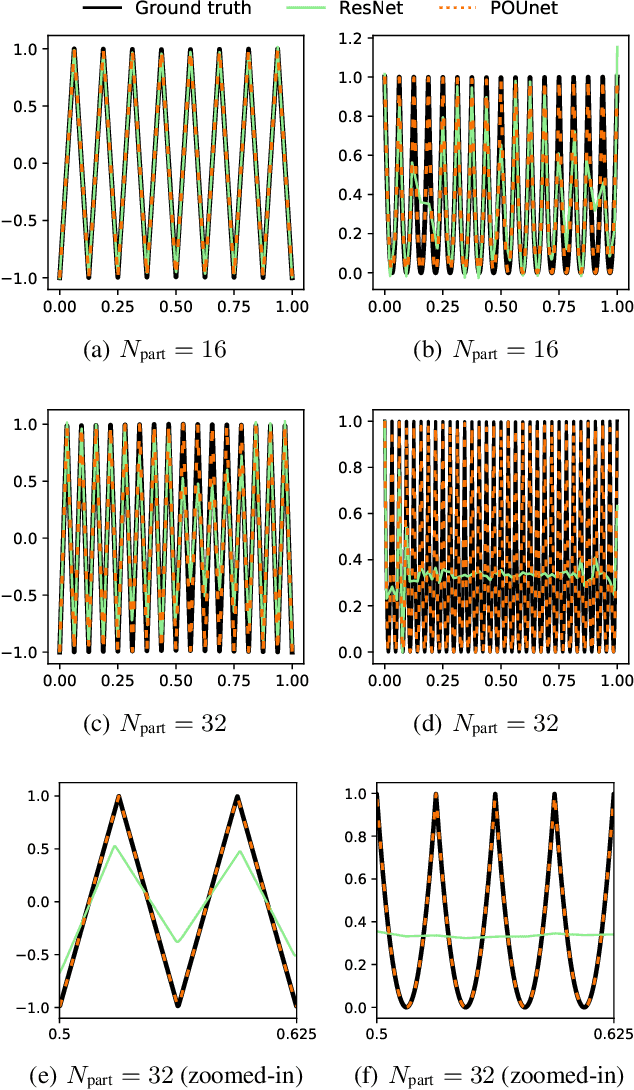
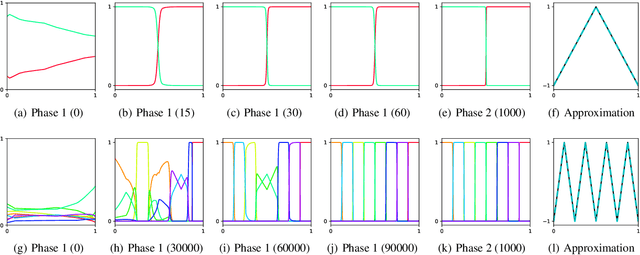
Approximation theorists have established best-in-class optimal approximation rates of deep neural networks by utilizing their ability to simultaneously emulate partitions of unity and monomials. Motivated by this, we propose partition of unity networks (POUnets) which incorporate these elements directly into the architecture. Classification architectures of the type used to learn probability measures are used to build a meshfree partition of space, while polynomial spaces with learnable coefficients are associated to each partition. The resulting hp-element-like approximation allows use of a fast least-squares optimizer, and the resulting architecture size need not scale exponentially with spatial dimension, breaking the curse of dimensionality. An abstract approximation result establishes desirable properties to guide network design. Numerical results for two choices of architecture demonstrate that POUnets yield hp-convergence for smooth functions and consistently outperform MLPs for piecewise polynomial functions with large numbers of discontinuities.
A physics-informed operator regression framework for extracting data-driven continuum models
Sep 25, 2020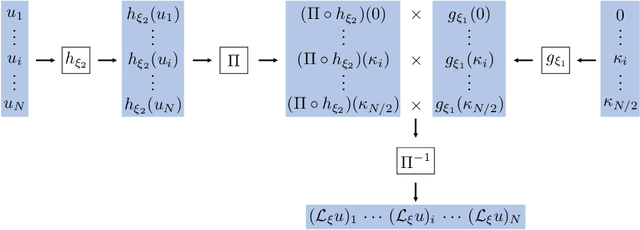
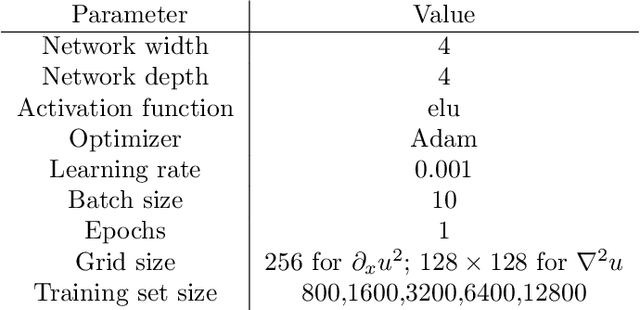
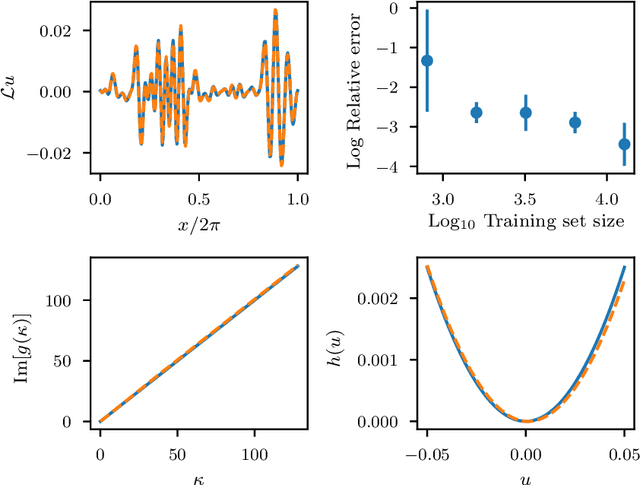

The application of deep learning toward discovery of data-driven models requires careful application of inductive biases to obtain a description of physics which is both accurate and robust. We present here a framework for discovering continuum models from high fidelity molecular simulation data. Our approach applies a neural network parameterization of governing physics in modal space, allowing a characterization of differential operators while providing structure which may be used to impose biases related to symmetry, isotropy, and conservation form. We demonstrate the effectiveness of our framework for a variety of physics, including local and nonlocal diffusion processes and single and multiphase flows. For the flow physics we demonstrate this approach leads to a learned operator that generalizes to system characteristics not included in the training sets, such as variable particle sizes, densities, and concentration.