 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Laplace HypoPINN: Physics-Informed Neural Network for hypocenter localization and its predictive uncertainty
May 28, 2022
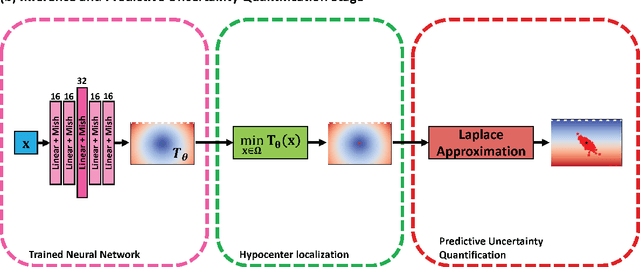
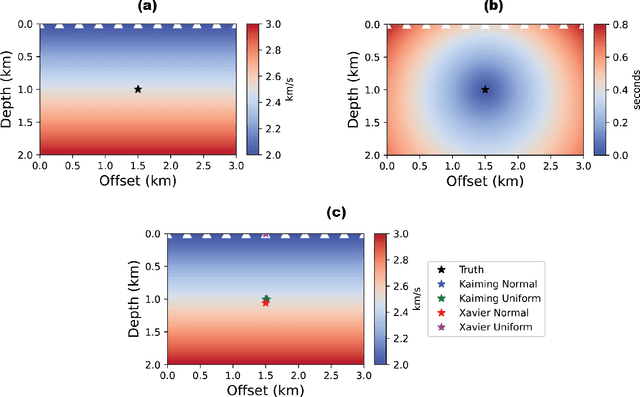
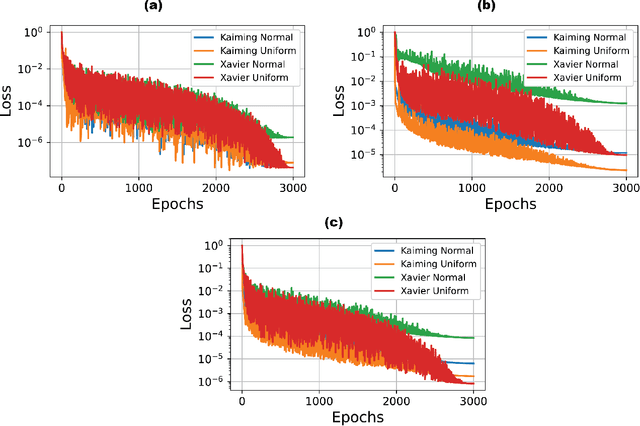
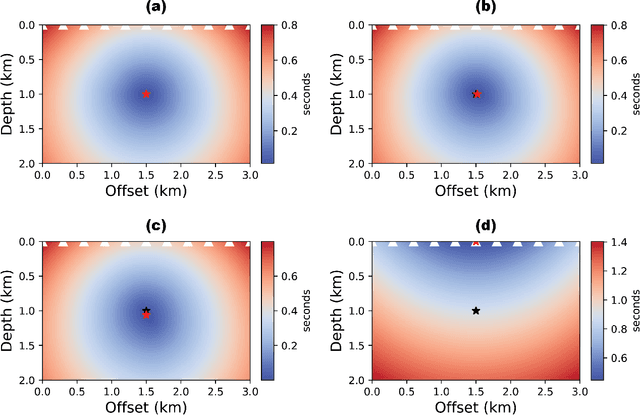
Several techniques have been proposed over the years for automatic hypocenter localization. While those techniques have pros and cons that trade-off computational efficiency and the susceptibility of getting trapped in local minima, an alternate approach is needed that allows robust localization performance and holds the potential to make the elusive goal of real-time microseismic monitoring possible. Physics-informed neural networks (PINNs) have appeared on the scene as a flexible and versatile framework for solving partial differential equations (PDEs) along with the associated initial or boundary conditions. We develop HypoPINN -- a PINN-based inversion framework for hypocenter localization and introduce an approximate Bayesian framework for estimating its predictive uncertainties. This work focuses on predicting the hypocenter locations using HypoPINN and investigates the propagation of uncertainties from the random realizations of HypoPINN's weights and biases using the Laplace approximation. We train HypoPINN to obtain the optimized weights for predicting hypocenter location. Next, we approximate the covariance matrix at the optimized HypoPINN's weights for posterior sampling with the Laplace approximation. The posterior samples represent various realizations of HypoPINN's weights. Finally, we predict the locations of the hypocenter associated with those weights' realizations to investigate the uncertainty propagation that comes from those realisations. We demonstrate the features of this methodology through several numerical examples, including using the Otway velocity model based on the Otway project in Australia.
Explainability Tools Enabling Deep Learning in Future In-Situ Real-Time Planetary Explorations
Jan 15, 2022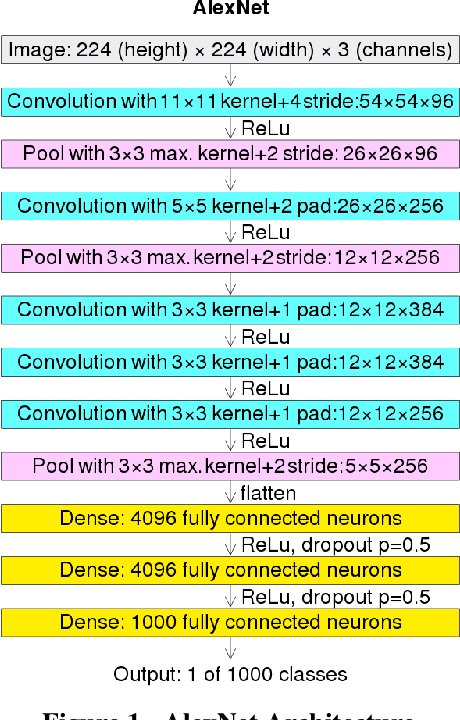


Deep learning (DL) has proven to be an effective machine learning and computer vision technique. DL-based image segmentation, object recognition and classification will aid many in-situ Mars rover tasks such as path planning and artifact recognition/extraction. However, most of the Deep Neural Network (DNN) architectures are so complex that they are considered a 'black box'. In this paper, we used integrated gradients to describe the attributions of each neuron to the output classes. It provides a set of explainability tools (ET) that opens the black box of a DNN so that the individual contribution of neurons to category classification can be ranked and visualized. The neurons in each dense layer are mapped and ranked by measuring expected contribution of a neuron to a class vote given a true image label. The importance of neurons is prioritized according to their correct or incorrect contribution to the output classes and suppression or bolstering of incorrect classes, weighted by the size of each class. ET provides an interface to prune the network to enhance high-rank neurons and remove low-performing neurons. ET technology will make DNNs smaller and more efficient for implementation in small embedded systems. It also leads to more explainable and testable DNNs that can make systems easier for Validation \& Verification. The goal of ET technology is to enable the adoption of DL in future in-situ planetary exploration missions.
SMARAGD: Synthesized sMatch for Accurate and Rapid AMR Graph Distance
Mar 24, 2022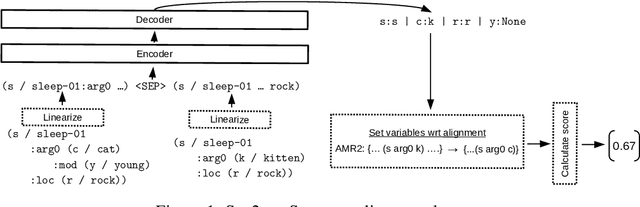
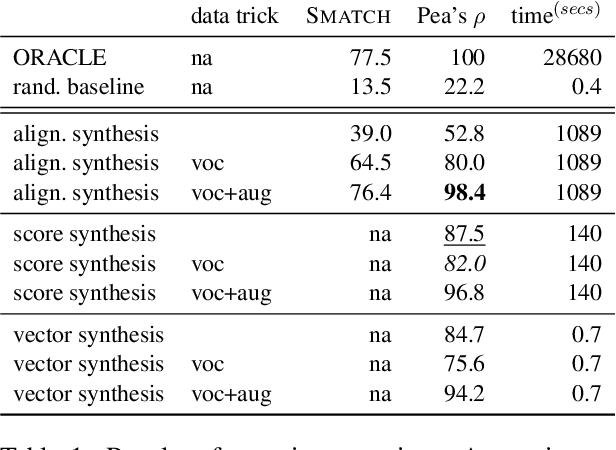
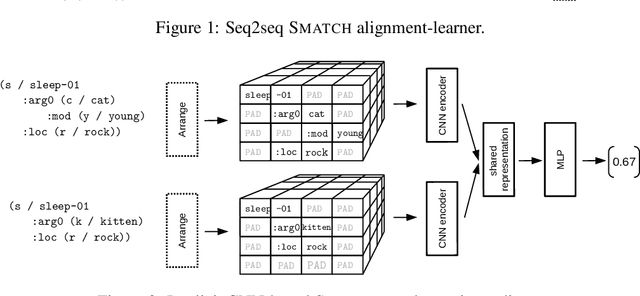
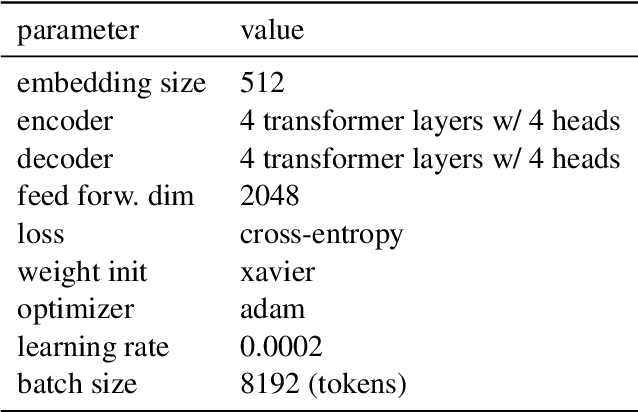
The semantic similarity of graph-based meaning representations, such as Abstract Meaning Representation (AMR), is typically assessed using graph matching algorithms, such as SMATCH (Cai and Knight, 2013). However, SMATCH suffers from NP-completeness, making its large-scale application, e.g., for AMR clustering or semantic search, infeasible. To mitigate this issue, we propose SMARAGD (Synthesized sMatch for accurate and rapid AMR graph distance). We show the potential of neural networks to approximate the SMATCH scores and graph alignments, i) in linear time using a machine translation framework to predict the alignments, or ii) in constant time using a Siamese CNN to directly predict SMATCH scores. We show that the approximation error can be substantially reduced by applying data augmentation and AMR graph anonymization.
Revitalize Region Feature for Democratizing Video-Language Pre-training
Mar 19, 2022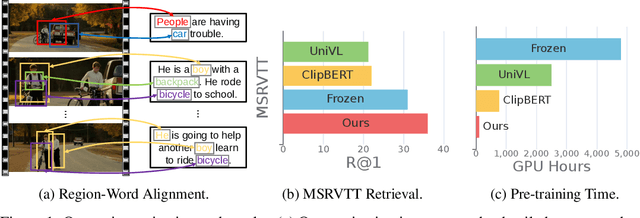
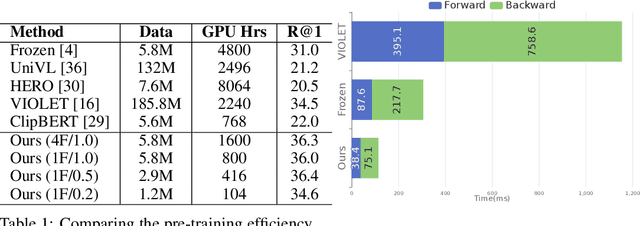
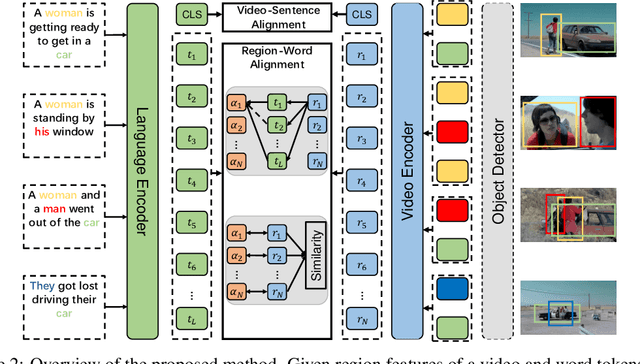

Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language tasks. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream text-to-video retrieval and video question answering tasks on seven datasets demonstrate the superiority of our method on both effectiveness and efficiency, e.g., our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far. The code will be available at \url{https://github.com/showlab/DemoVLP}.
Fully Adaptive Composition in Differential Privacy
Mar 10, 2022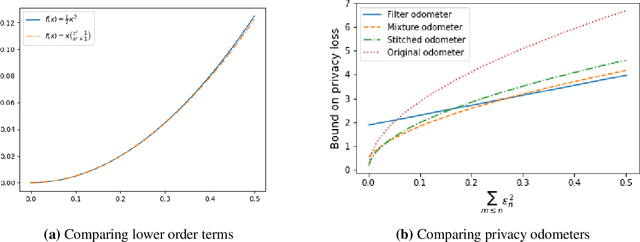
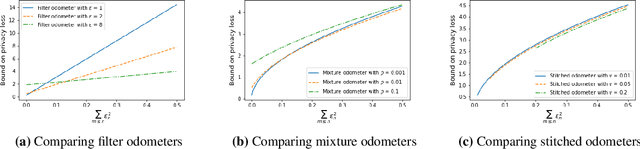
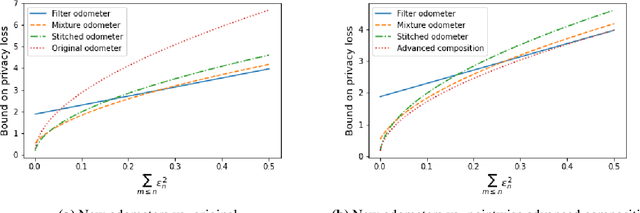
Composition is a key feature of differential privacy. Well-known advanced composition theorems allow one to query a private database quadratically more times than basic privacy composition would permit. However, these results require that the privacy parameters of all algorithms be fixed before interacting with the data. To address this, Rogers et al. introduced fully adaptive composition, wherein both algorithms and their privacy parameters can be selected adaptively. The authors introduce two probabilistic objects to measure privacy in adaptive composition: privacy filters, which provide differential privacy guarantees for composed interactions, and privacy odometers, time-uniform bounds on privacy loss. There are substantial gaps between advanced composition and existing filters and odometers. First, existing filters place stronger assumptions on the algorithms being composed. Second, these odometers and filters suffer from large constants, making them impractical. We construct filters that match the tightness of advanced composition, including constants, despite allowing for adaptively chosen privacy parameters. We also construct several general families of odometers. These odometers can match the tightness of advanced composition at an arbitrary, preselected point in time, or at all points in time simultaneously, up to a doubly-logarithmic factor. We obtain our results by leveraging recent advances in time-uniform martingale concentration. In sum, we show that fully adaptive privacy is obtainable at almost no loss, and conjecture that our results are essentially unimprovable (even in constants) in general.
Multibit Tries Packet Classification with Deep Reinforcement Learning
May 17, 2022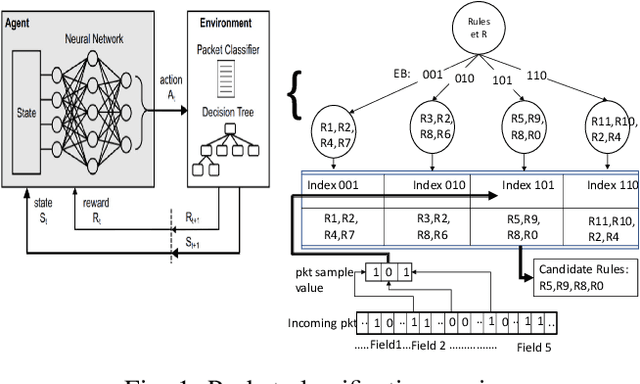
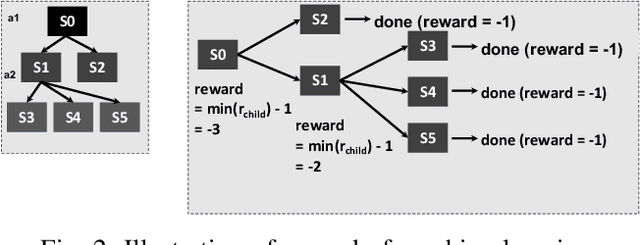
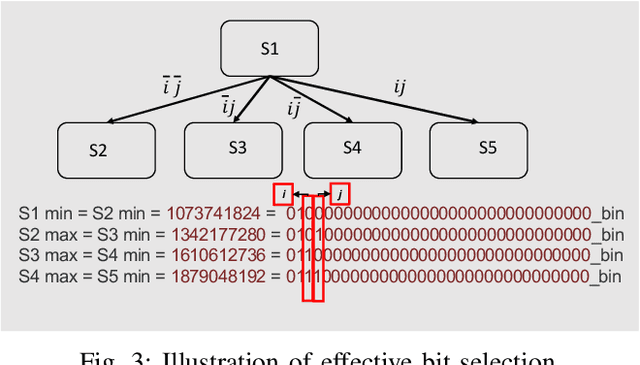
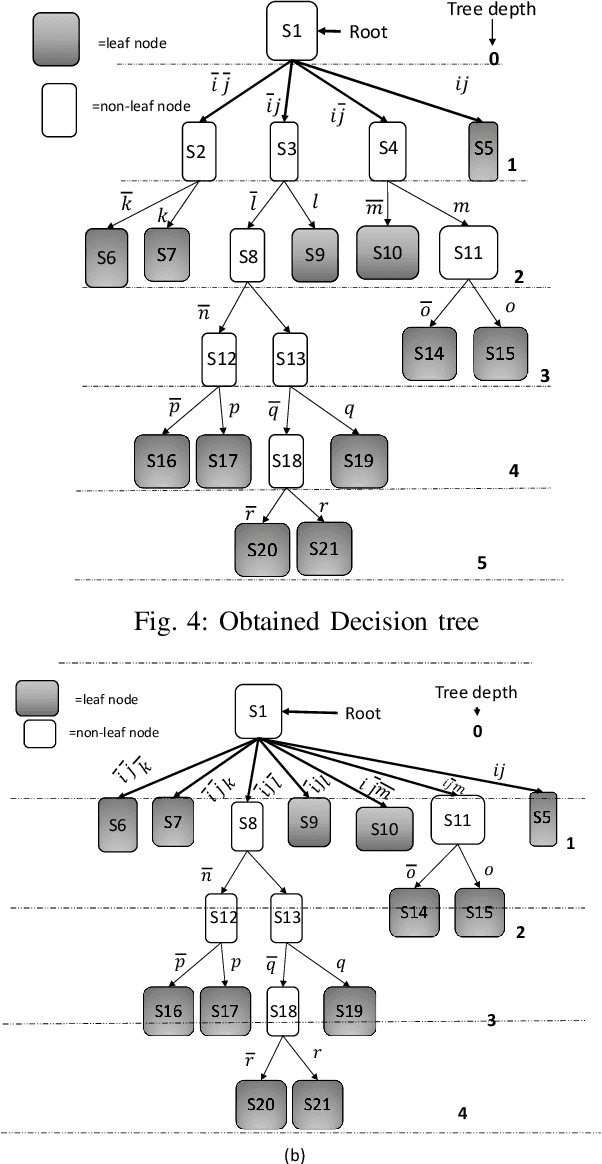
High performance packet classification is a key component to support scalable network applications like firewalls, intrusion detection, and differentiated services. With ever increasing in the line-rate in core networks, it becomes a great challenge to design a scalable and high performance packet classification solution using hand-tuned heuristics approaches. In this paper, we present a scalable learning-based packet classification engine and its performance evaluation. By exploiting the sparsity of ruleset, our algorithm uses a few effective bits (EBs) to extract a large number of candidate rules with just a few of memory access. These effective bits are learned with deep reinforcement learning and they are used to create a bitmap to filter out the majority of rules which do not need to be full-matched to improve the online system performance. Moreover, our EBs learning-based selection method is independent of the ruleset, which can be applied to varying rulesets. Our multibit tries classification engine outperforms lookup time both in worst and average case by 55% and reduce memory footprint, compared to traditional decision tree without EBs.
* 6 pages. arXiv admin note: text overlap with arXiv:2205.07973
Let's Agree to Agree: Targeting Consensus for Incomplete Preferences through Majority Dynamics
Apr 28, 2022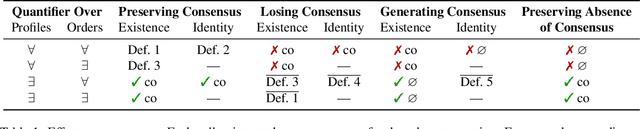
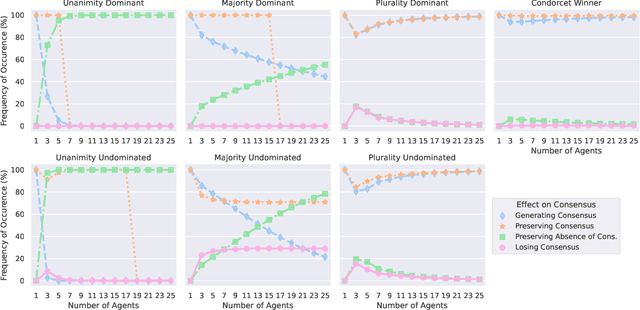

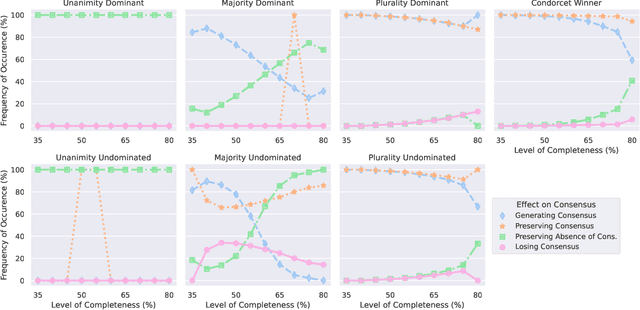
We study settings in which agents with incomplete preferences need to make a collective decision. We focus on a process of majority dynamics where issues are addressed one at a time and undecided agents follow the opinion of the majority. We assess the effects of this process on various consensus notions -- such as the Condorcet winner -- and show that in the worst case, myopic adherence to the majority damages existing consensus; yet, simulation experiments indicate that the damage is often mild. We also examine scenarios where the chair of the decision process can control the existence (or the identity) of consensus, by determining the order in which the issues are discussed.
Machine Learning-Based User Scheduling in Integrated Satellite-HAPS-Ground Networks
May 31, 2022



Integrated space-air-ground networks promise to offer a valuable solution space for empowering the sixth generation of communication networks (6G), particularly in the context of connecting the unconnected and ultraconnecting the connected. Such digital inclusion thrive makes resource management problems, especially those accounting for load-balancing considerations, of particular interest. The conventional model-based optimization methods, however, often fail to meet the real-time processing and quality-of-service needs, due to the high heterogeneity of the space-air-ground networks, and the typical complexity of the classical algorithms. Given the premises of artificial intelligence at automating wireless networks design, this paper focuses on showcasing the prospects of machine learning in the context of user scheduling in integrated space-air-ground communications. The paper first overviews the most relevant state-of-the art in the context of machine learning applications to the resource allocation problems, with a dedicated attention to space-air-ground networks. The paper then proposes, and shows the benefit of, one specific application that uses ensembling deep neural networks for optimizing the user scheduling policies in integrated space-high altitude platform station (HAPS)-ground networks. Finally, the paper sheds light on the challenges and open issues that promise to spur the integration of machine learning in space-air-ground networks, namely, online HAPS power adaptation, learning-based channel sensing, data-driven multi-HAPSs resource management, and intelligent flying taxis-empowered systems.
Deep Depth Completion: A Survey
May 11, 2022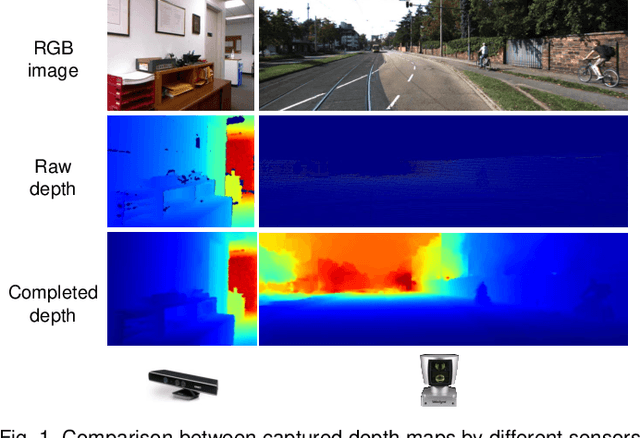
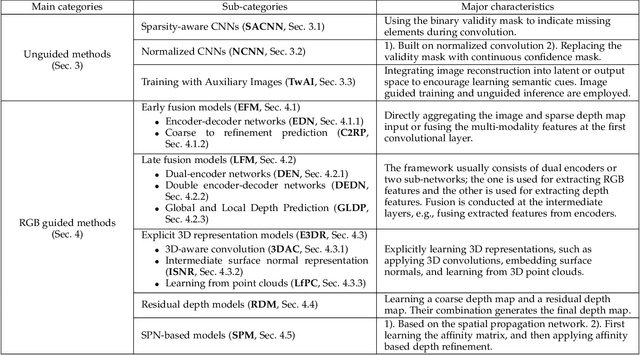
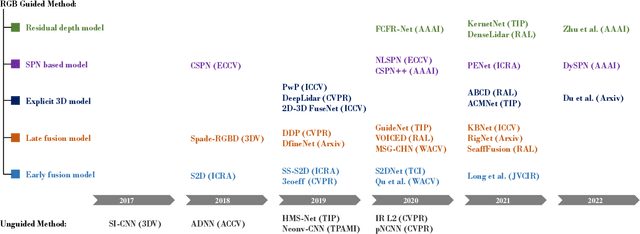
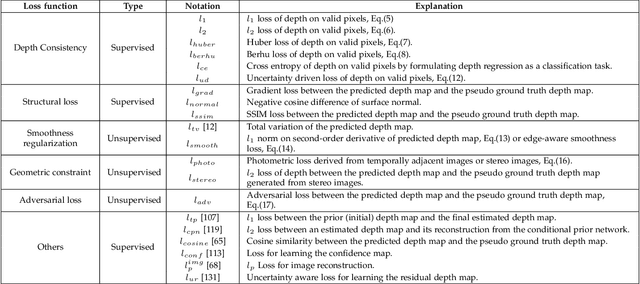
Depth completion aims at predicting dense pixel-wise depth from a sparse map captured from a depth sensor. It plays an essential role in various applications such as autonomous driving, 3D reconstruction, augmented reality, and robot navigation. Recent successes on the task have been demonstrated and dominated by deep learning based solutions. In this article, for the first time, we provide a comprehensive literature review that helps readers better grasp the research trends and clearly understand the current advances. We investigate the related studies from the design aspects of network architectures, loss functions, benchmark datasets, and learning strategies with a proposal of a novel taxonomy that categorizes existing methods. Besides, we present a quantitative comparison of model performance on two widely used benchmark datasets, including an indoor and an outdoor dataset. Finally, we discuss the challenges of prior works and provide readers with some insights for future research directions.
FastSTMF: Efficient tropical matrix factorization algorithm for sparse data
May 13, 2022
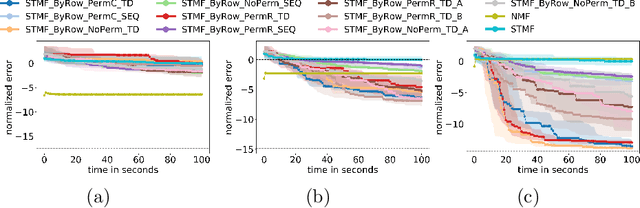
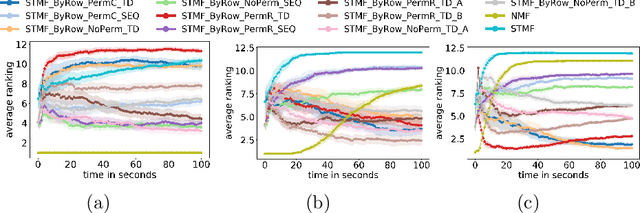

Matrix factorization, one of the most popular methods in machine learning, has recently benefited from introducing non-linearity in prediction tasks using tropical semiring. The non-linearity enables a better fit to extreme values and distributions, thus discovering high-variance patterns that differ from those found by standard linear algebra. However, the optimization process of various tropical matrix factorization methods is slow. In our work, we propose a new method FastSTMF based on Sparse Tropical Matrix Factorization (STMF), which introduces a novel strategy for updating factor matrices that results in efficient computational performance. We evaluated the efficiency of FastSTMF on synthetic and real gene expression data from the TCGA database, and the results show that FastSTMF outperforms STMF in both accuracy and running time. Compared to NMF, we show that FastSTMF performs better on some datasets and is not prone to overfitting as NMF. This work sets the basis for developing other matrix factorization techniques based on many other semirings using a new proposed optimization process.