 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Simplifying Node Classification on Heterophilous Graphs with Compatible Label Propagation
May 19, 2022
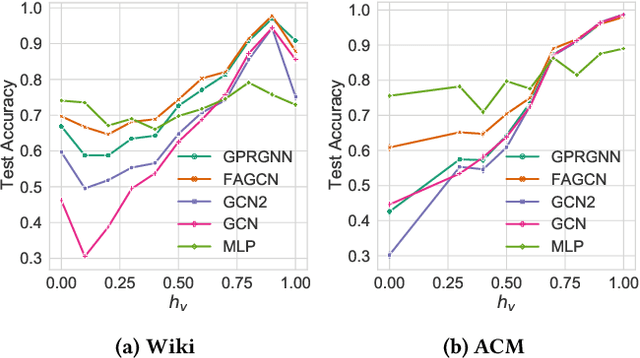

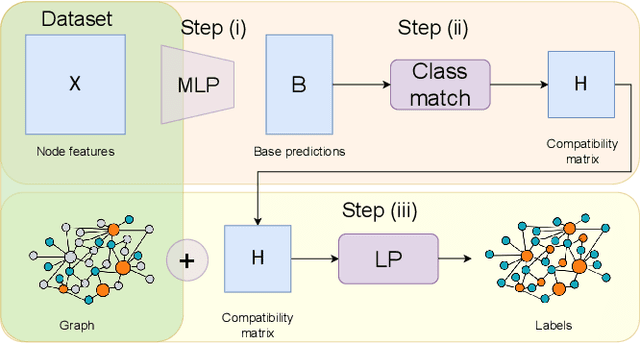
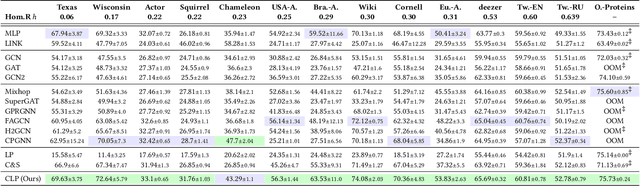
Graph Neural Networks (GNNs) have been predominant for graph learning tasks; however, recent studies showed that a well-known graph algorithm, Label Propagation (LP), combined with a shallow neural network can achieve comparable performance to GNNs in semi-supervised node classification on graphs with high homophily. In this paper, we show that this approach falls short on graphs with low homophily, where nodes often connect to the nodes of the opposite classes. To overcome this, we carefully design a combination of a base predictor with LP algorithm that enjoys a closed-form solution as well as convergence guarantees. Our algorithm first learns the class compatibility matrix and then aggregates label predictions using LP algorithm weighted by class compatibilities. On a wide variety of benchmarks, we show that our approach achieves the leading performance on graphs with various levels of homophily. Meanwhile, it has orders of magnitude fewer parameters and requires less execution time. Empirical evaluations demonstrate that simple adaptations of LP can be competitive in semi-supervised node classification in both homophily and heterophily regimes.
Dynamic physical activity recommendation on personalised mobile health information service: A deep reinforcement learning approach
Apr 03, 2022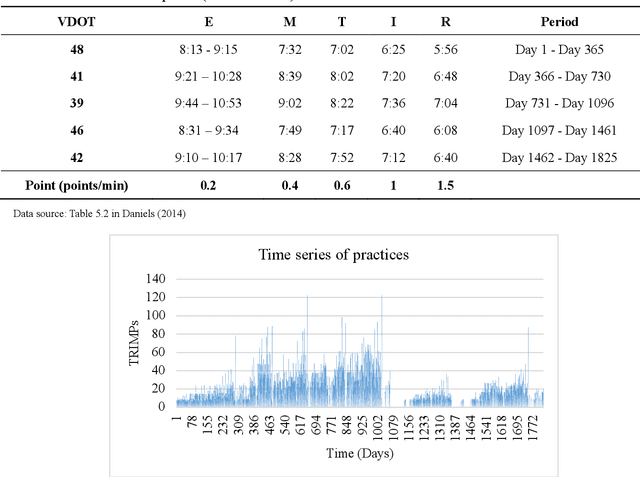


Mobile health (mHealth) information service makes healthcare management easier for users, who want to increase physical activity and improve health. However, the differences in activity preference among the individual, adherence problems, and uncertainty of future health outcomes may reduce the effect of the mHealth information service. The current health service system usually provides recommendations based on fixed exercise plans that do not satisfy the user specific needs. This paper seeks an efficient way to make physical activity recommendation decisions on physical activity promotion in personalised mHealth information service by establishing data-driven model. In this study, we propose a real-time interaction model to select the optimal exercise plan for the individual considering the time-varying characteristics in maximising the long-term health utility of the user. We construct a framework for mHealth information service system comprising a personalised AI module, which is based on the scientific knowledge about physical activity to evaluate the individual exercise performance, which may increase the awareness of the mHealth artificial intelligence system. The proposed deep reinforcement learning (DRL) methodology combining two classes of approaches to improve the learning capability for the mHealth information service system. A deep learning method is introduced to construct the hybrid neural network combing long-short term memory (LSTM) network and deep neural network (DNN) techniques to infer the individual exercise behavior from the time series data. A reinforcement learning method is applied based on the asynchronous advantage actor-critic algorithm to find the optimal policy through exploration and exploitation.
Identical Image Retrieval using Deep Learning
May 10, 2022
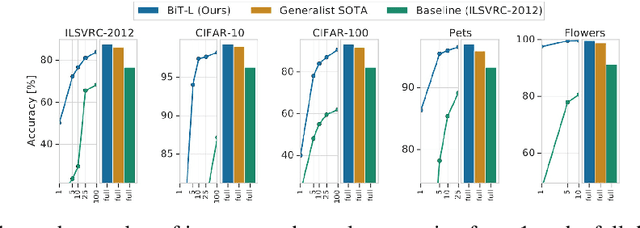
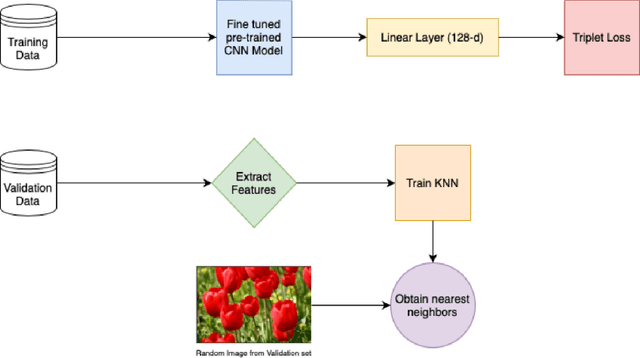

In recent years, we know that the interaction with images has increased. Image similarity involves fetching similar-looking images abiding by a given reference image. The target is to find out whether the image searched as a query can result in similar pictures. We are using the BigTransfer Model, which is a state-of-art model itself. BigTransfer(BiT) is essentially a ResNet but pre-trained on a larger dataset like ImageNet and ImageNet-21k with additional modifications. Using the fine-tuned pre-trained Convolution Neural Network Model, we extract the key features and train on the K-Nearest Neighbor model to obtain the nearest neighbor. The application of our model is to find similar images, which are hard to achieve through text queries within a low inference time. We analyse the benchmark of our model based on this application.
TridentNetV2: Lightweight Graphical Global Plan Representations for Dynamic Trajectory Generation
Mar 26, 2022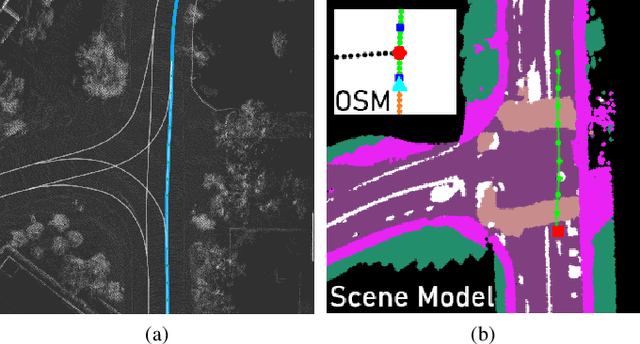
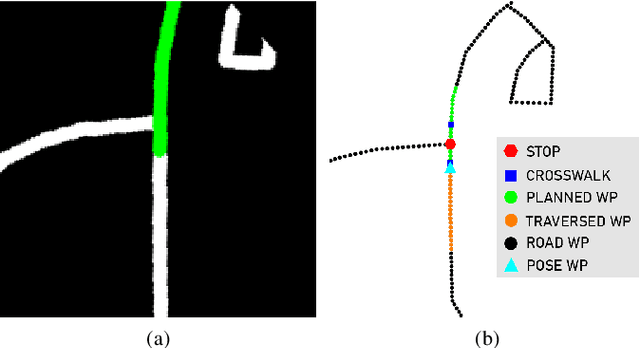
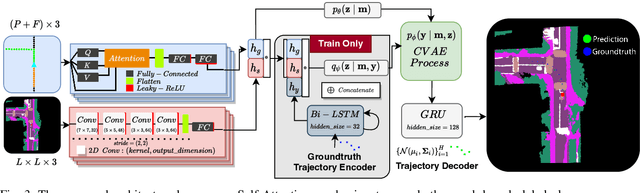
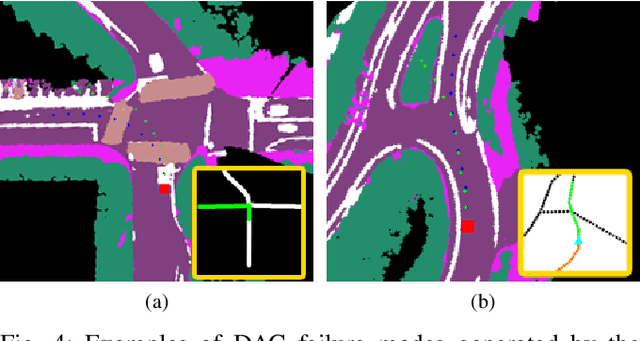
We present a framework for dynamic trajectory generation for autonomous navigation, which does not rely on HD maps as the underlying representation. High Definition (HD) maps have become a key component in most autonomous driving frameworks, which include complete road network information annotated at a centimeter-level that include traversable waypoints, lane information, and traffic signals. Instead, the presented approach models the distributions of feasible ego-centric trajectories in real-time given a nominal graph-based global plan and a lightweight scene representation. By embedding contextual information, such as crosswalks, stop signs, and traffic signals, our approach achieves low errors across multiple urban navigation datasets that include diverse intersection maneuvers, while maintaining real-time performance and reducing network complexity. Underlying datasets introduced are available online.
Dataset Pruning: Reducing Training Data by Examining Generalization Influence
May 19, 2022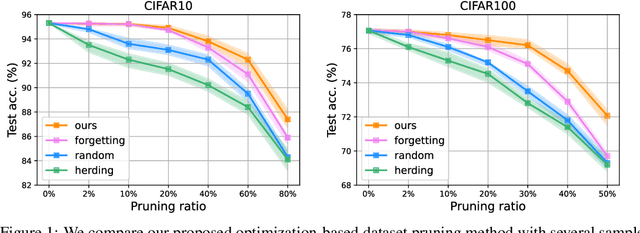

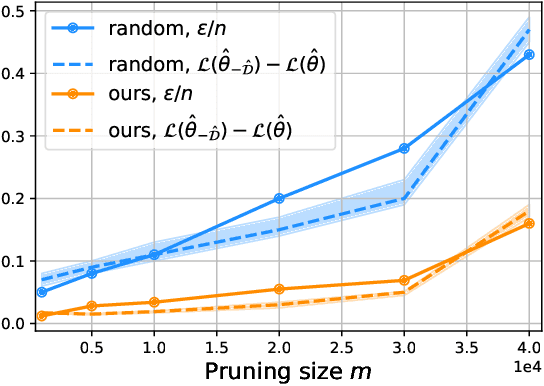
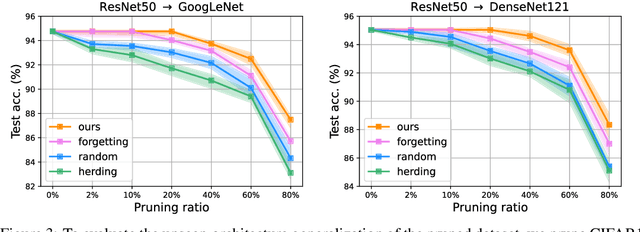
The great success of deep learning heavily relies on increasingly larger training data, which comes at a price of huge computational and infrastructural costs. This poses crucial questions that, do all training data contribute to model's performance? How much does each individual training sample or a sub-training-set affect the model's generalization, and how to construct a smallest subset from the entire training data as a proxy training set without significantly sacrificing the model's performance? To answer these, we propose dataset pruning, an optimization-based sample selection method that can (1) examine the influence of removing a particular set of training samples on model's generalization ability with theoretical guarantee, and (2) construct a smallest subset of training data that yields strictly constrained generalization gap. The empirically observed generalization gap of dataset pruning is substantially consistent with our theoretical expectations. Furthermore, the proposed method prunes 40% training examples on the CIFAR-10 dataset, halves the convergence time with only 1.3% test accuracy decrease, which is superior to previous score-based sample selection methods.
6N-DoF Pose Tracking for Tensegrity Robots
May 29, 2022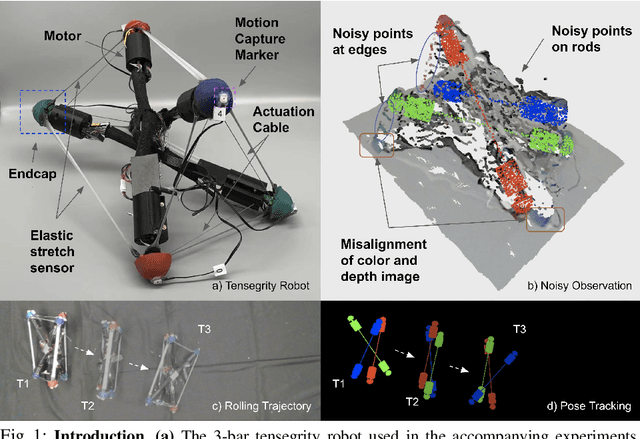
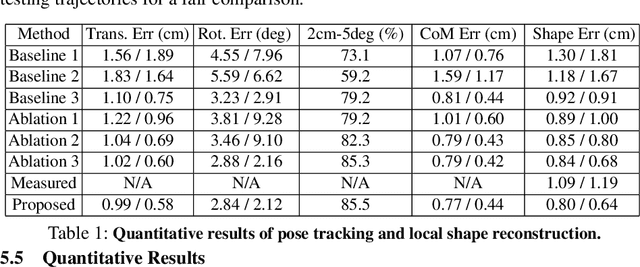

Tensegrity robots, which are composed of rigid compressive elements (rods) and flexible tensile elements (e.g., cables), have a variety of advantages, including flexibility, light weight, and resistance to mechanical impact. Nevertheless, the hybrid soft-rigid nature of these robots also complicates the ability to localize and track their state. This work aims to address what has been recognized as a grand challenge in this domain, i.e., the pose tracking of tensegrity robots through a markerless, vision-based method, as well as novel, onboard sensors that can measure the length of the robot's cables. In particular, an iterative optimization process is proposed to estimate the 6-DoF poses of each rigid element of a tensegrity robot from an RGB-D video as well as endcap distance measurements from the cable sensors. To ensure the pose estimates of rigid elements are physically feasible, i.e., they are not resulting in collisions between rods or with the environment, physical constraints are introduced during the optimization. Real-world experiments are performed with a 3-bar tensegrity robot, which performs locomotion gaits. Given ground truth data from a motion capture system, the proposed method achieves less than 1 cm translation error and 3 degrees rotation error, which significantly outperforms alternatives. At the same time, the approach can provide pose estimates throughout the robot's motion, while motion capture often fails due to occlusions.
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021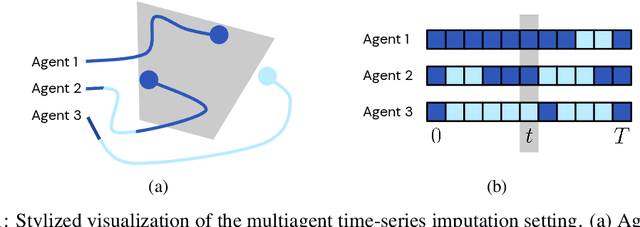
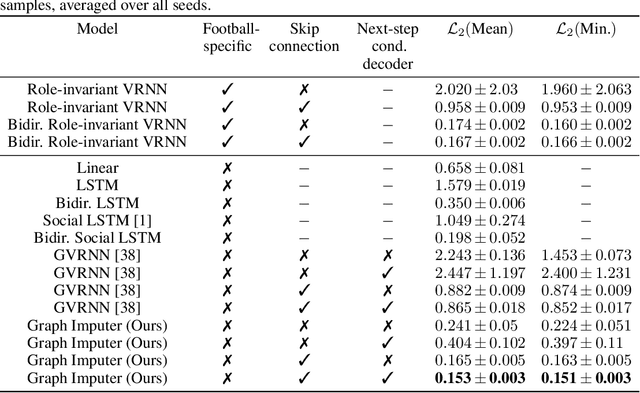
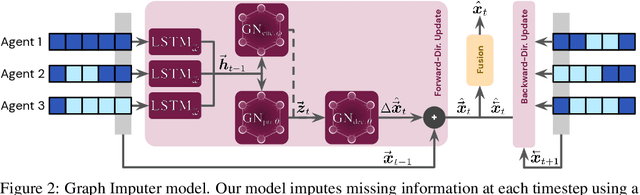
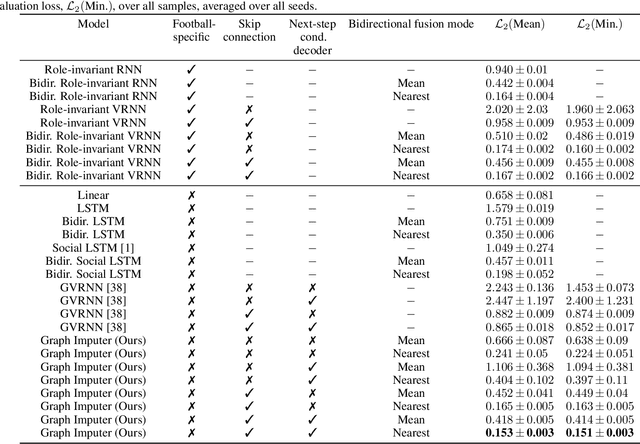
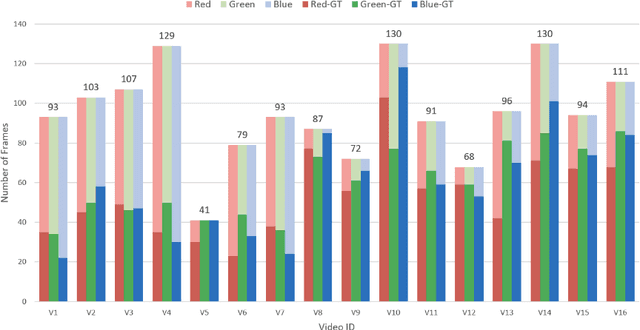
In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.
Linear-Time WordPiece Tokenization
Dec 31, 2020
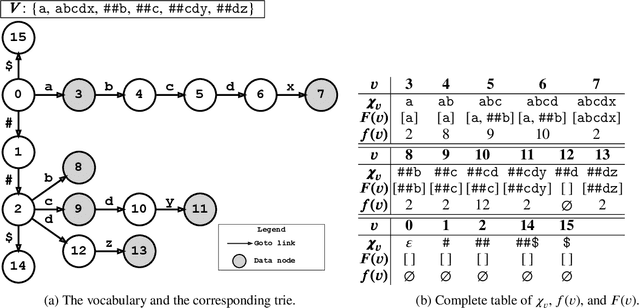

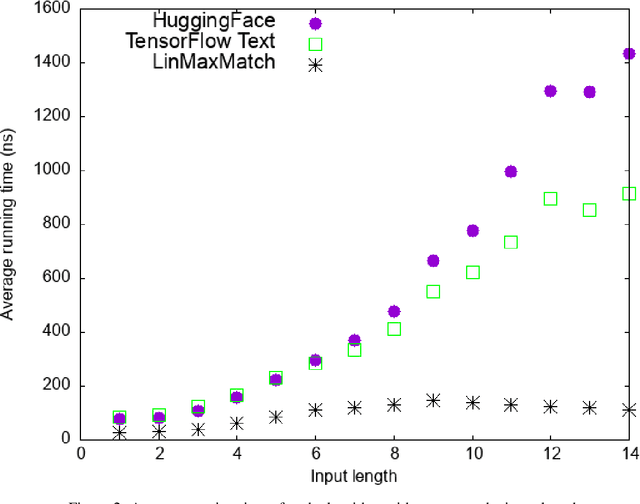
WordPiece tokenization is a subword-based tokenization schema adopted by BERT: it segments the input text via a longest-match-first tokenization strategy, known as Maximum Matching or MaxMatch. To the best of our knowledge, all published MaxMatch algorithms are quadratic (or higher). In this paper, we propose LinMaxMatch, a novel linear-time algorithm for MaxMatch and WordPiece tokenization. Inspired by the Aho-Corasick algorithm, we introduce additional linkages on top of the trie built from the vocabulary, allowing smart transitions when the trie matching cannot continue. Experimental results show that our algorithm is 3x faster on average than two production systems by HuggingFace and TensorFlow Text. Regarding long-tail inputs, our algorithm is 4.5x faster at the 95 percentile. This work has immediate practical value (reducing inference latency, saving compute resources, etc.) and is of theoretical interest by providing an optimal complexity solution to the decades-old MaxMatch problem.
Fast online inference for nonlinear contextual bandit based on Generative Adversarial Network
Feb 17, 2022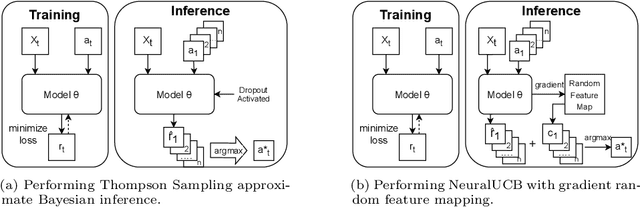
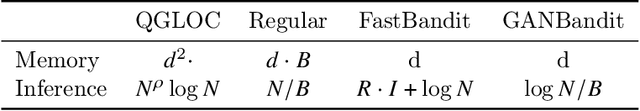
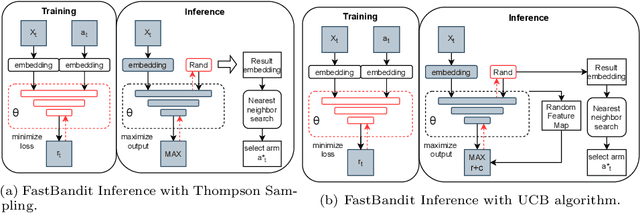

This work addresses the efficiency concern on inferring a nonlinear contextual bandit when the number of arms $n$ is very large. We propose a neural bandit model with an end-to-end training process to efficiently perform bandit algorithms such as Thompson Sampling and UCB during inference. We advance state-of-the-art time complexity to $O(\log n)$ with approximate Bayesian inference, neural random feature mapping, approximate global maxima and approximate nearest neighbor search. We further propose a generative adversarial network to shift the bottleneck of maximizing the objective for selecting optimal arms from inference time to training time, enjoying significant speedup with additional advantage of enabling batch and parallel processing. %The generative model can inference an approximate argmax of the posterior sampling in logarithmic time complexity with the help of approximate nearest neighbor search. Extensive experiments on classification and recommendation tasks demonstrate order-of-magnitude improvement in inference time no significant degradation on the performance.
Intelligent Circuit Design and Implementation with Machine Learning
Jun 07, 2022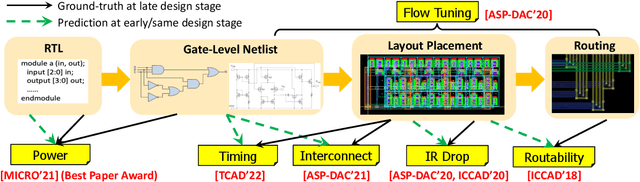
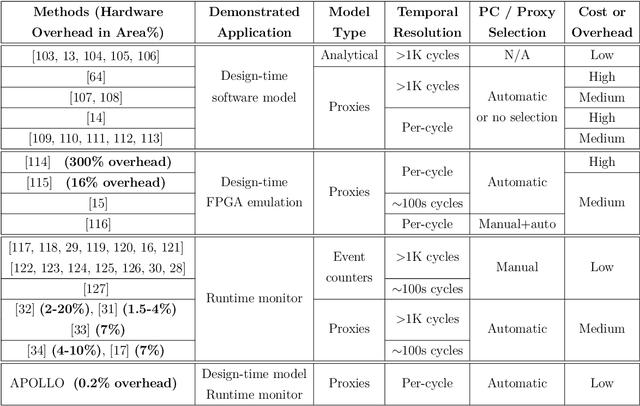
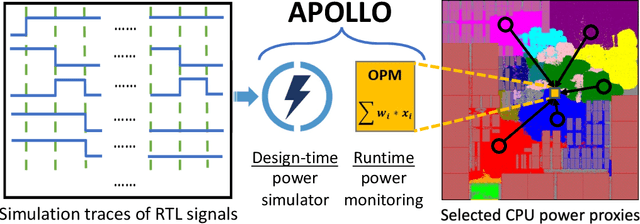
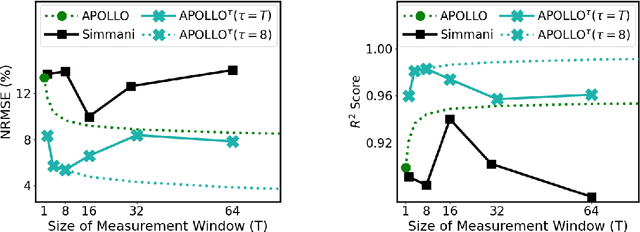
The stagnation of EDA technologies roots from insufficient knowledge reuse. In practice, very similar simulation or optimization results may need to be repeatedly constructed from scratch. This motivates my research on introducing more 'intelligence' to EDA with machine learning (ML), which explores complex correlations in design flows based on prior data. Besides design time, I also propose ML solutions to boost IC performance by assisting the circuit management at runtime. In this dissertation, I present multiple fast yet accurate ML models covering a wide range of chip design stages from the register-transfer level (RTL) to sign-off, solving primary chip-design problems about power, timing, interconnect, IR drop, routability, and design flow tuning. Targeting the RTL stage, I present APOLLO, a fully automated power modeling framework. It constructs an accurate per-cycle power model by extracting the most power-correlated signals. The model can be further implemented on chip for runtime power management with unprecedented low hardware costs. Targeting gate-level netlist, I present Net2 for early estimations on post-placement wirelength. It further enables more accurate timing analysis without actual physical design information. Targeting circuit layout, I present RouteNet for early routability prediction. As the first deep learning-based routability estimator, some feature-extraction and model-design principles proposed in it are widely adopted by later works. I also present PowerNet for fast IR drop estimation. It captures spatial and temporal information about power distribution with a customized CNN architecture. Last, besides targeting a single design step, I present FIST to efficiently tune design flow parameters during both logic synthesis and physical design.