 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hyperparameter Optimization with Neural Network Pruning
May 18, 2022
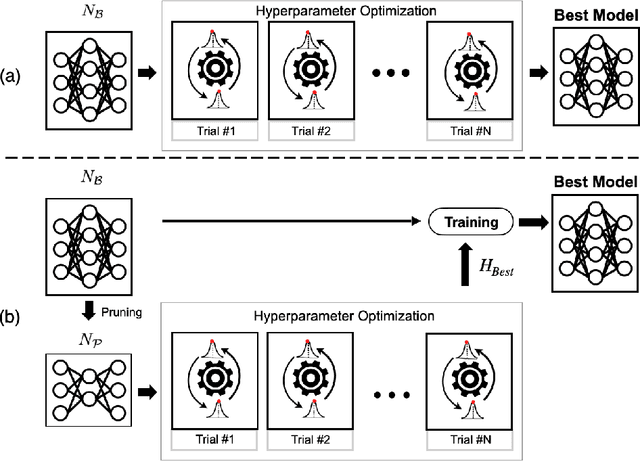
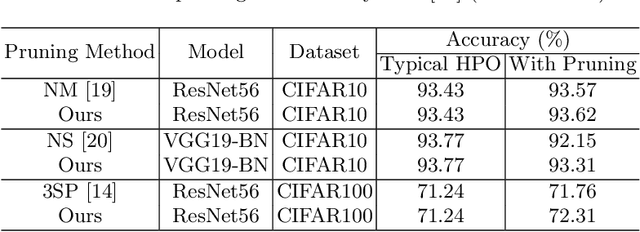

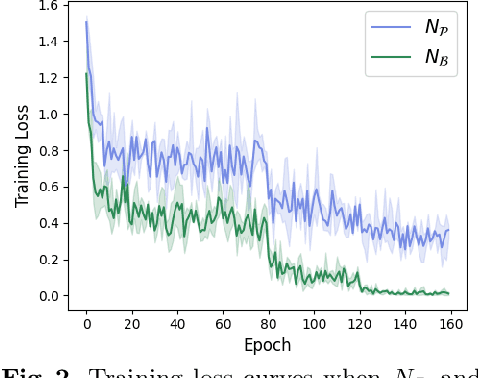
Since the deep learning model is highly dependent on hyperparameters, hyperparameter optimization is essential in developing deep learning model-based applications, even if it takes a long time. As service development using deep learning models has gradually become competitive, many developers highly demand rapid hyperparameter optimization algorithms. In order to keep pace with the needs of faster hyperparameter optimization algorithms, researchers are focusing on improving the speed of hyperparameter optimization algorithm. However, the huge time consumption of hyperparameter optimization due to the high computational cost of the deep learning model itself has not been dealt with in-depth. Like using surrogate model in Bayesian optimization, to solve this problem, it is necessary to consider proxy model for a neural network (N_B) to be used for hyperparameter optimization. Inspired by the main goal of neural network pruning, i.e., high computational cost reduction and performance preservation, we presumed that the neural network (N_P) obtained through neural network pruning would be a good proxy model of N_B. In order to verify our idea, we performed extensive experiments by using CIFAR10, CFIAR100, and TinyImageNet datasets and three generally-used neural networks and three representative hyperparameter optmization methods. Through these experiments, we verified that N_P can be a good proxy model of N_B for rapid hyperparameter optimization. The proposed hyperparameter optimization framework can reduce the amount of time up to 37%.
Data Augmentation and Squeeze-and-Excitation Network on Multiple Dimension for Sound Event Localization and Detection in Real Scenes
Jun 24, 2022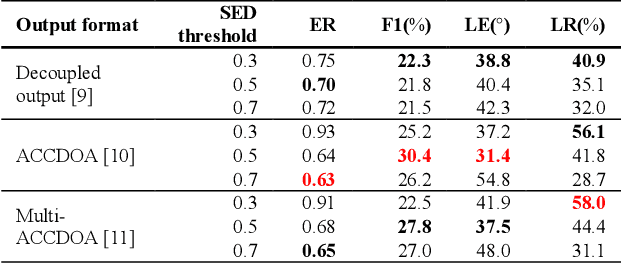
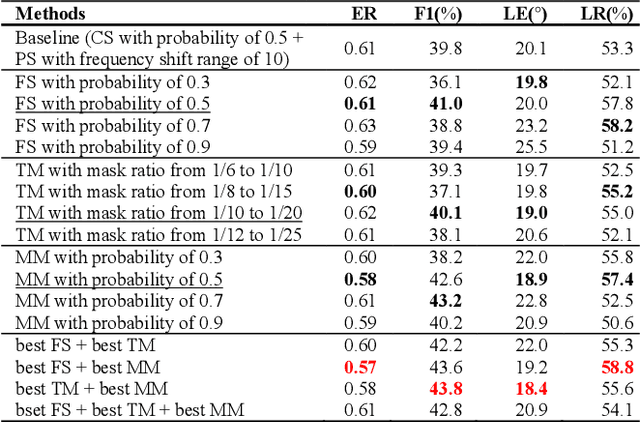
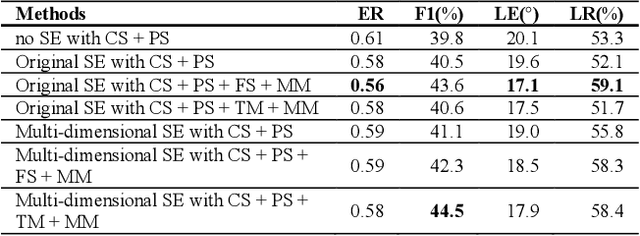
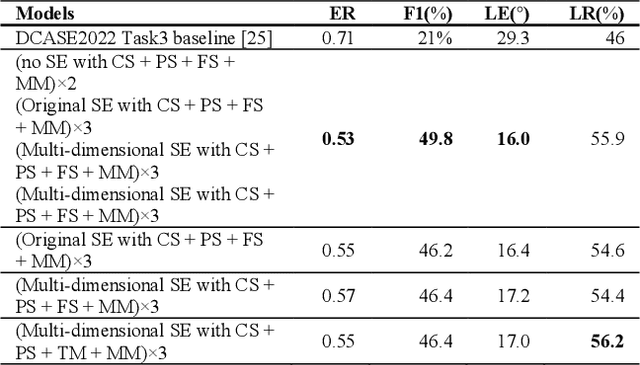
Performance of sound event localization and detection (SELD) in real scenes is limited by small size of SELD dataset, due to difficulty in obtaining sufficient amount of realistic multi-channel audio data recordings with accurate label. We used two main strategies to solve problems arising from the small real SELD dataset. First, we applied various data augmentation methods on all data dimensions: channel, frequency and time. We also propose original data augmentation method named Moderate Mixup in order to simulate situations where noise floor or interfering events exist. Second, we applied Squeeze-and-Excitation block on channel and frequency dimensions to efficiently extract feature characteristics. Result of our trained models on the STARSS22 test dataset achieved the best ER, F1, LE, and LR of 0.53, 49.8%, 16.0deg., and 56.2% respectively.
Multi-Label Retinal Disease Classification using Transformers
Jul 07, 2022
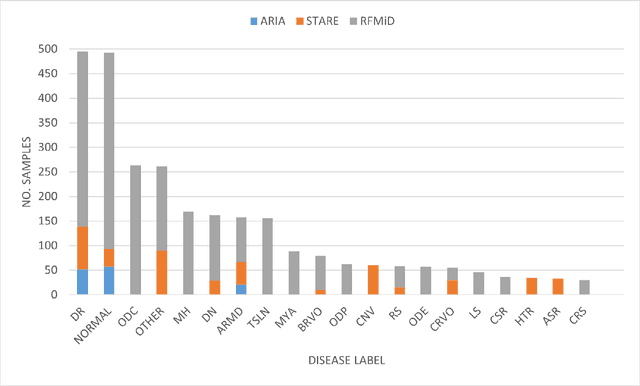
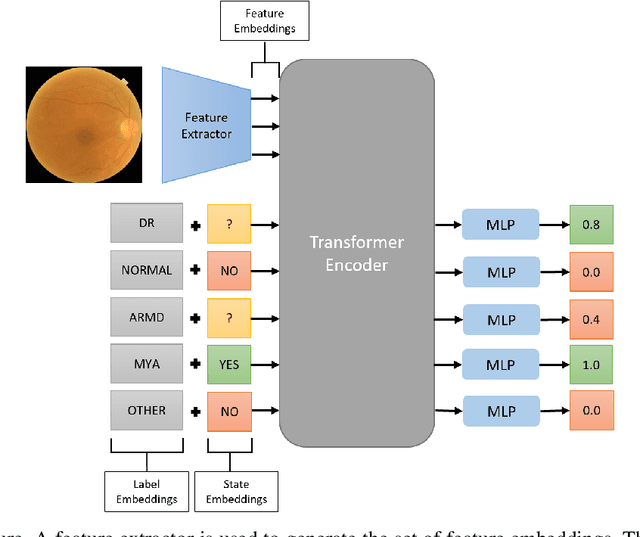
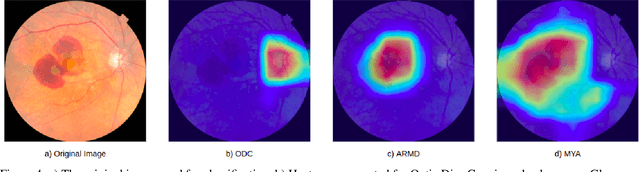
Early detection of retinal diseases is one of the most important means of preventing partial or permanent blindness in patients. In this research, a novel multi-label classification system is proposed for the detection of multiple retinal diseases, using fundus images collected from a variety of sources. First, a new multi-label retinal disease dataset, the MuReD dataset, is constructed, using a number of publicly available datasets for fundus disease classification. Next, a sequence of post-processing steps is applied to ensure the quality of the image data and the range of diseases, present in the dataset. For the first time in fundus multi-label disease classification, a transformer-based model optimized through extensive experimentation is used for image analysis and decision making. Numerous experiments are performed to optimize the configuration of the proposed system. It is shown that the approach performs better than state-of-the-art works on the same task by 7.9% and 8.1% in terms of AUC score for disease detection and disease classification, respectively. The obtained results further support the potential applications of transformer-based architectures in the medical imaging field.
An Edge-Cloud Integrated Framework for Flexible and Dynamic Stream Analytics
May 11, 2022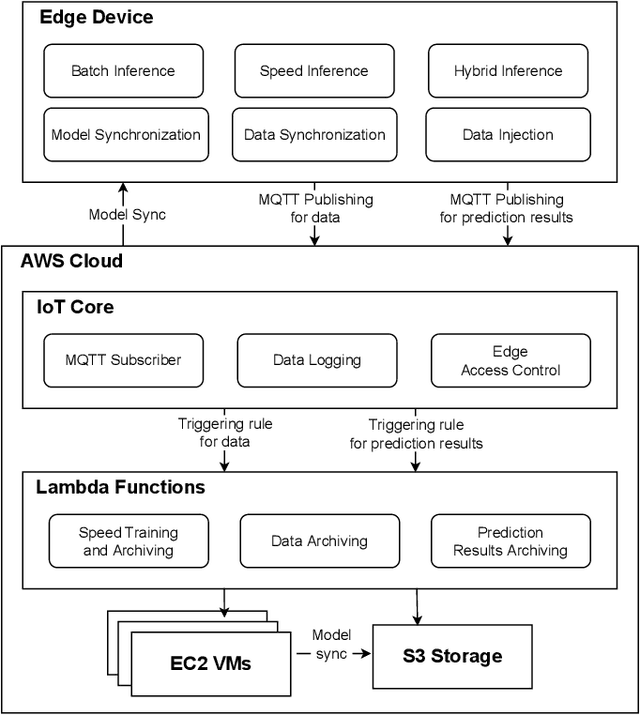
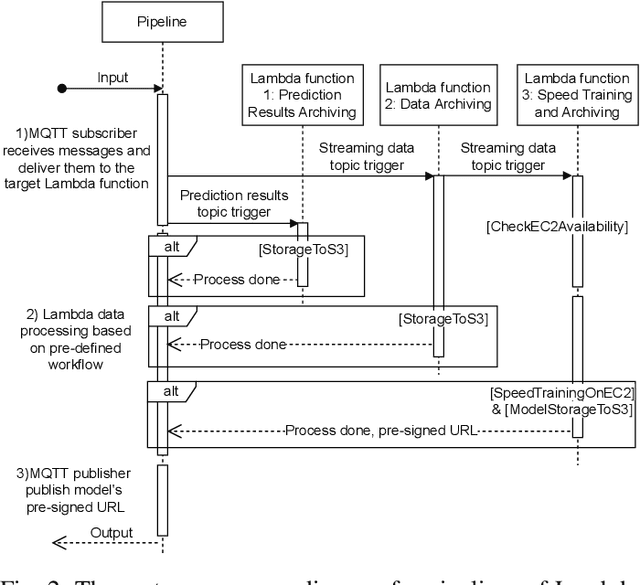
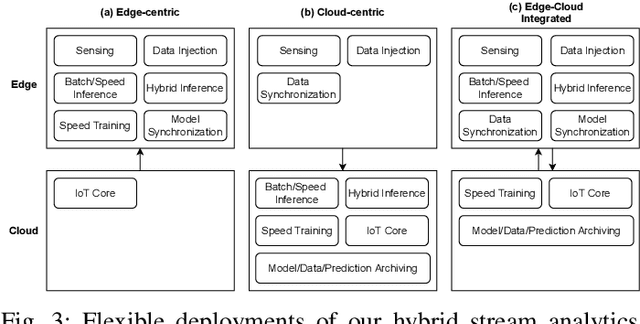
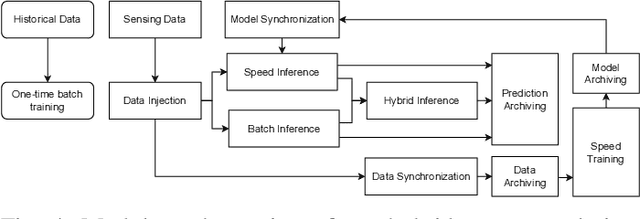
With the popularity of Internet of Things (IoT), edge computing and cloud computing, more and more stream analytics applications are being developed including real-time trend prediction and object detection on top of IoT sensing data. One popular type of stream analytics is the recurrent neural network (RNN) deep learning model based time series or sequence data prediction and forecasting. Different from traditional analytics that assumes data to be processed are available ahead of time and will not change, stream analytics deals with data that are being generated continuously and data trend/distribution could change (aka concept drift), which will cause prediction/forecasting accuracy to drop over time. One other challenge is to find the best resource provisioning for stream analytics to achieve good overall latency. In this paper, we study how to best leverage edge and cloud resources to achieve better accuracy and latency for RNN-based stream analytics. We propose a novel edge-cloud integrated framework for hybrid stream analytics that support low latency inference on the edge and high capacity training on the cloud. We study the flexible deployment of our hybrid learning framework, namely edge-centric, cloud-centric and edge-cloud integrated. Further, our hybrid learning framework can dynamically combine inference results from an RNN model pre-trained based on historical data and another RNN model re-trained periodically based on the most recent data. Using real-world and simulated stream datasets, our experiments show the proposed edge-cloud deployment is the best among all three deployment types in terms of latency. For accuracy, the experiments show our dynamic learning approach performs the best among all learning approaches for all three concept drift scenarios.
Fast Real-time Personalized Speech Enhancement: End-to-End Enhancement Network (E3Net) and Knowledge Distillation
Apr 02, 2022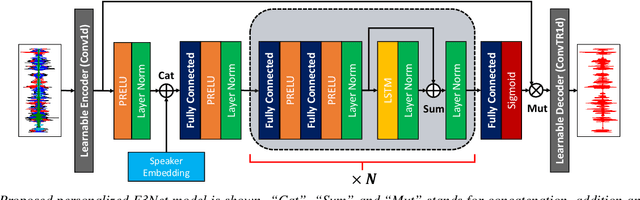
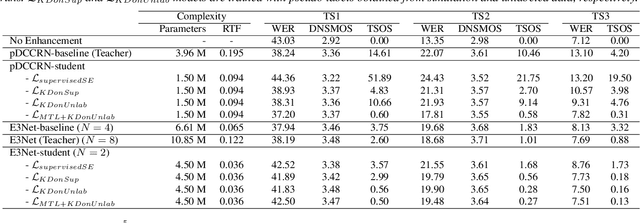
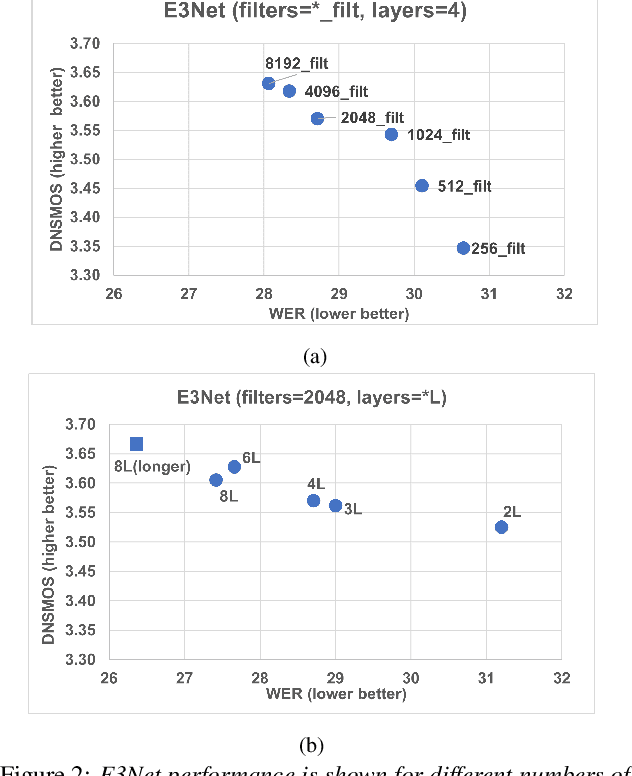
This paper investigates how to improve the runtime speed of personalized speech enhancement (PSE) networks while maintaining the model quality. Our approach includes two aspects: architecture and knowledge distillation (KD). We propose an end-to-end enhancement (E3Net) model architecture, which is $3\times$ faster than a baseline STFT-based model. Besides, we use KD techniques to develop compressed student models without significantly degrading quality. In addition, we investigate using noisy data without reference clean signals for training the student models, where we combine KD with multi-task learning (MTL) using automatic speech recognition (ASR) loss. Our results show that E3Net provides better speech and transcription quality with a lower target speaker over-suppression (TSOS) rate than the baseline model. Furthermore, we show that the KD methods can yield student models that are $2-4\times$ faster than the teacher and provides reasonable quality. Combining KD and MTL improves the ASR and TSOS metrics without degrading the speech quality.
The Second Place Solution for The 4th Large-scale Video Object Segmentation Challenge--Track 3: Referring Video Object Segmentation
Jun 24, 2022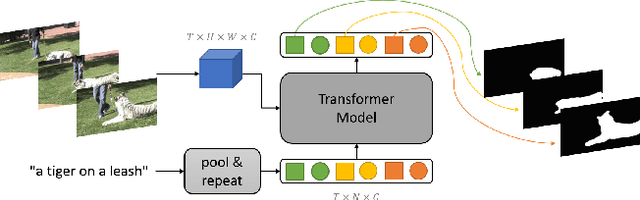
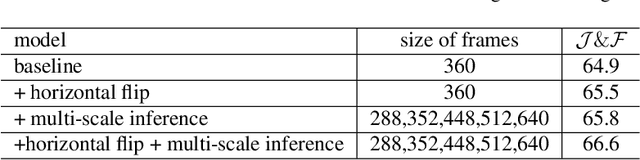
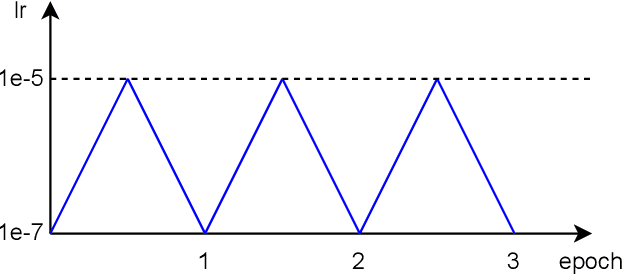
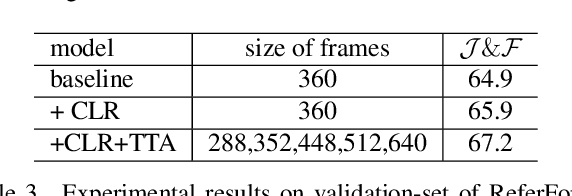
The referring video object segmentation task (RVOS) aims to segment object instances in a given video referred by a language expression in all video frames. Due to the requirement of understanding cross-modal semantics within individual instances, this task is more challenging than the traditional semi-supervised video object segmentation where the ground truth object masks in the first frame are given. With the great achievement of Transformer in object detection and object segmentation, RVOS has been made remarkable progress where ReferFormer achieved the state-of-the-art performance. In this work, based on the strong baseline framework--ReferFormer, we propose several tricks to boost further, including cyclical learning rates, semi-supervised approach, and test-time augmentation inference. The improved ReferFormer ranks 2nd place on CVPR2022 Referring Youtube-VOS Challenge.
Network Traffic Anomaly Detection Method Based on Multi scale Residual Feature
May 08, 2022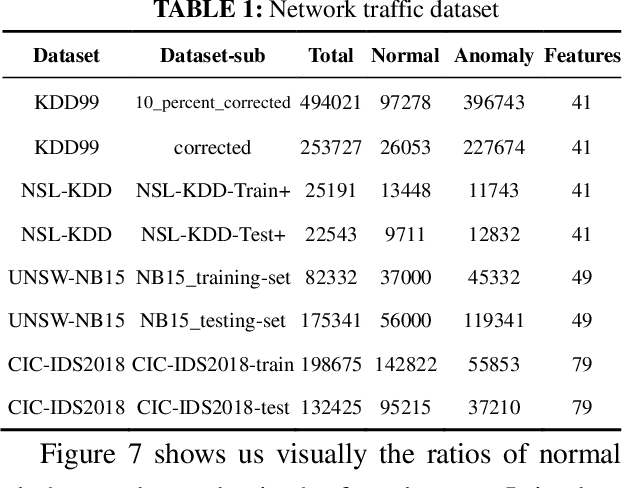
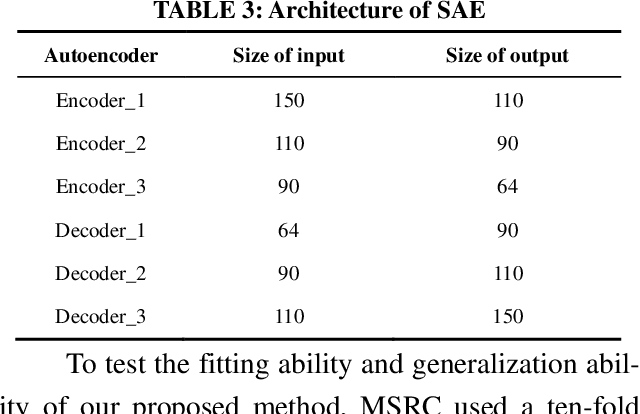
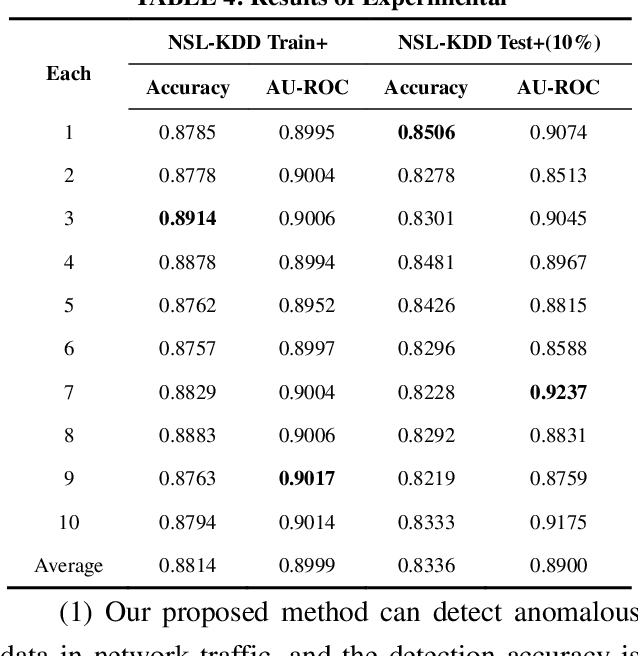
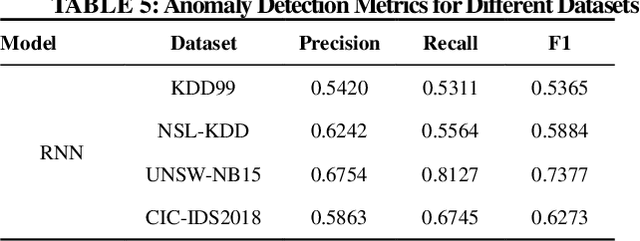
To address the problem that traditional network traffic anomaly detection algorithms do not suffi-ciently mine potential features in long time domain, an anomaly detection method based on mul-ti-scale residual features of network traffic is proposed. The original traffic is divided into subse-quences of different time spans using sliding windows, and each subsequence is decomposed and reconstructed into data sequences of different levels using wavelet transform technique; the stacked autoencoder (SAE) constructs similar feature space using normal network traffic, and gen-erates reconstructed error vector using the difference between reconstructed samples and input samples in the similar feature space; the multi-path residual group is used to learn reconstructed error The traffic classification is completed by a lightweight classifier. The experimental results show that the detection performance of the proposed method for anomalous network traffic is sig-nificantly improved compared with traditional methods; it confirms that the longer time span and more S transformation scales have positive effects on discovering potential diversity information in the original network traffic.
Cooperative Reinforcement Learning on Traffic Signal Control
May 23, 2022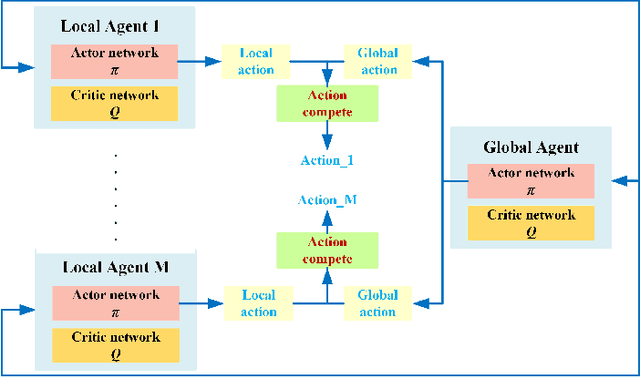
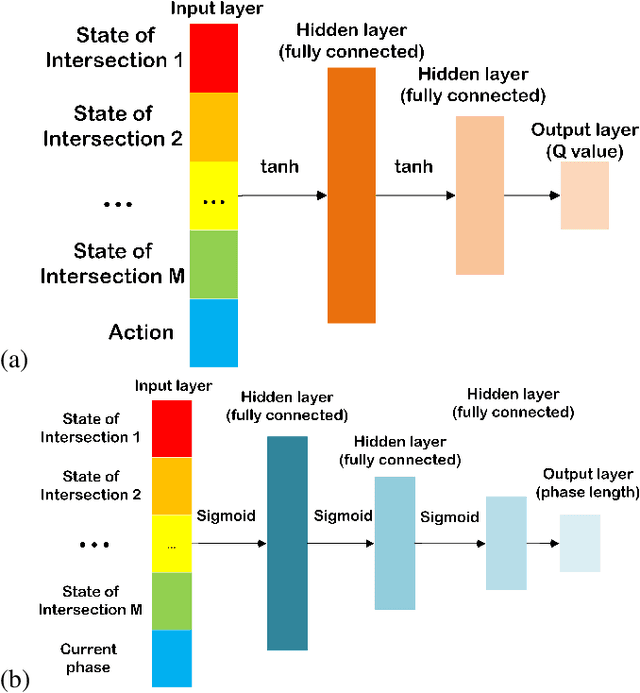
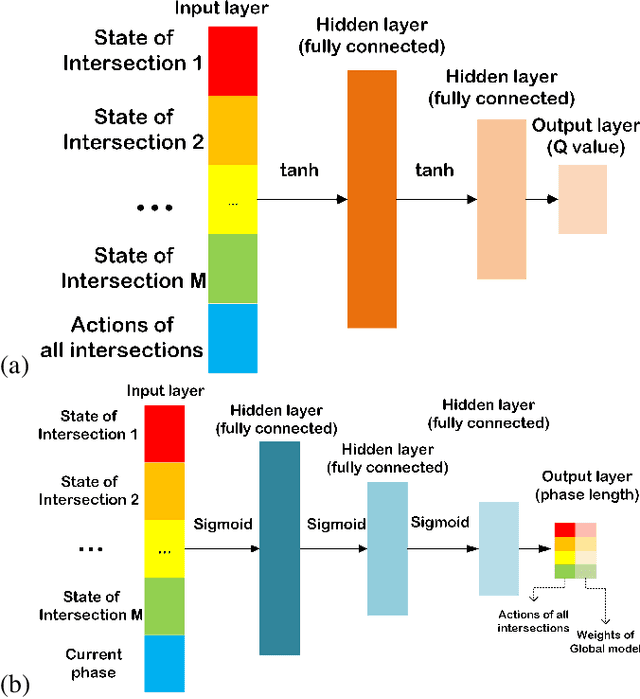

Traffic signal control is a challenging real-world problem aiming to minimize overall travel time by coordinating vehicle movements at road intersections. Existing traffic signal control systems in use still rely heavily on oversimplified information and rule-based methods. Specifically, the periodicity of green/red light alternations can be considered as a prior for better planning of each agent in policy optimization. To better learn such adaptive and predictive priors, traditional RL-based methods can only return a fixed length from predefined action pool with only local agents. If there is no cooperation between these agents, some agents often make conflicts to other agents and thus decrease the whole throughput. This paper proposes a cooperative, multi-objective architecture with age-decaying weights to better estimate multiple reward terms for traffic signal control optimization, which termed COoperative Multi-Objective Multi-Agent Deep Deterministic Policy Gradient (COMMA-DDPG). Two types of agents running to maximize rewards of different goals - one for local traffic optimization at each intersection and the other for global traffic waiting time optimization. The global agent is used to guide the local agents as a means for aiding faster learning but not used in the inference phase. We also provide an analysis of solution existence together with convergence proof for the proposed RL optimization. Evaluation is performed using real-world traffic data collected using traffic cameras from an Asian country. Our method can effectively reduce the total delayed time by 60\%. Results demonstrate its superiority when compared to SoTA methods.
Using Neural Networks for Novelty-based Test Selection to Accelerate Functional Coverage Closure
Jul 07, 2022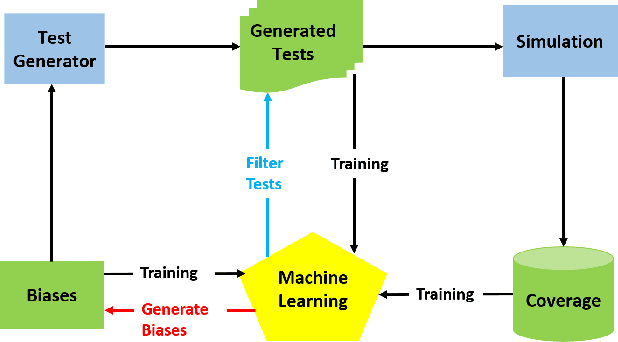
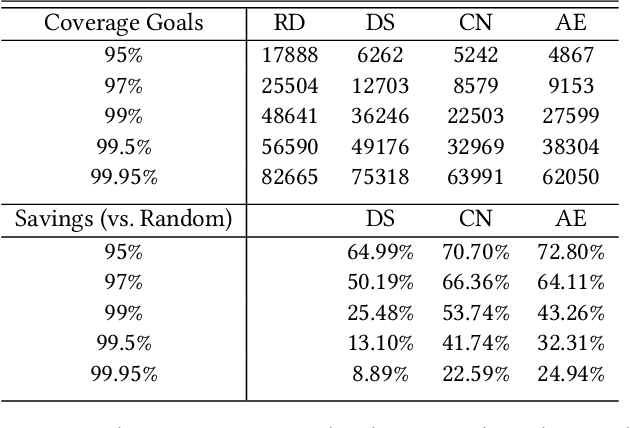
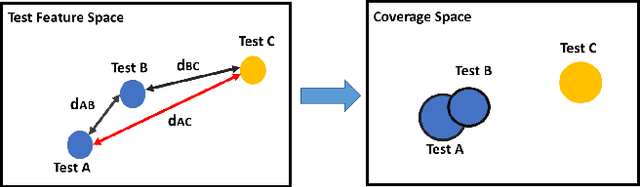
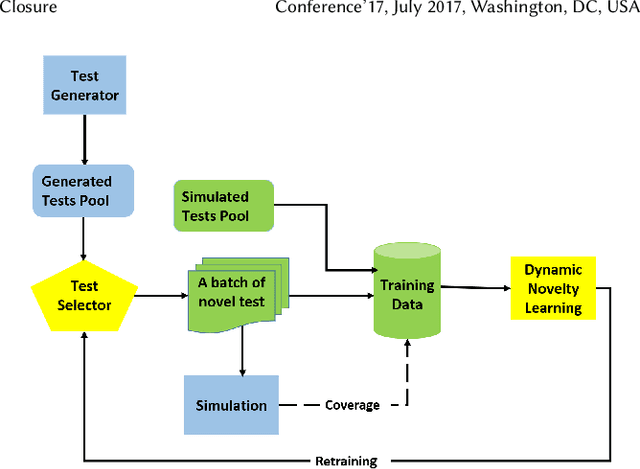
Machine learning (ML) has been used to accelerate the closure of functional coverage in simulation-based verification. A supervised ML algorithm, as a prevalent option in the previous work, is used to bias the test generation or filter the generated tests. However, for missing coverage events, these algorithms lack the positive examples to learn from in the training phase. Therefore, the tests generated or filtered by the algorithms cannot effectively fill the coverage holes. This is more severe when verifying large-scale design because the coverage space is larger and the functionalities are more complex. This paper presents a configurable framework of test selection based on neural networks (NN), which can achieve a similar coverage gain as random simulation with far less simulation effort under three configurations of the framework. Moreover, the performance of the framework is not limited by the number of coverage events being hit. A commercial signal processing unit is used in the experiment to demonstrate the effectiveness of the framework. Compared to the random simulation, the framework can reduce up to 53.74% of simulation time to reach 99% coverage level.
Knowledge Distillation of Transformer-based Language Models Revisited
Jun 30, 2022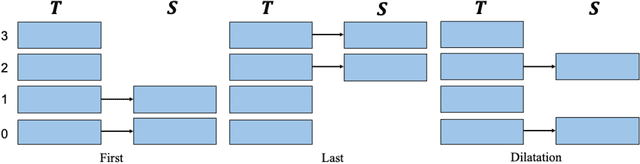
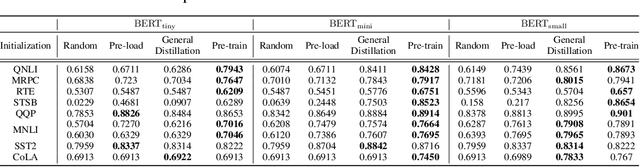
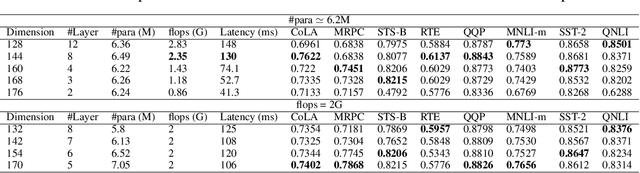
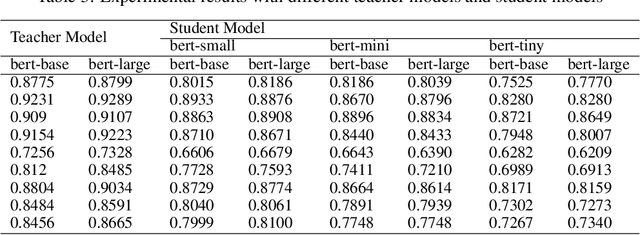
In the past few years, transformer-based pre-trained language models have achieved astounding success in both industry and academia. However, the large model size and high run-time latency are serious impediments to applying them in practice, especially on mobile phones and Internet of Things (IoT) devices. To compress the model, considerable literature has grown up around the theme of knowledge distillation (KD) recently. Nevertheless, how KD works in transformer-based models is still unclear. We tease apart the components of KD and propose a unified KD framework. Through the framework, systematic and extensive experiments that spent over 23,000 GPU hours render a comprehensive analysis from the perspectives of knowledge types, matching strategies, width-depth trade-off, initialization, model size, etc. Our empirical results shed light on the distillation in the pre-train language model and with relative significant improvement over previous state-of-the-arts(SOTA). Finally, we provide a best-practice guideline for the KD in transformer-based models.