 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Personalized QoE Enhancement for Adaptive Video Streaming: A Digital Twin-Assisted Scheme
May 09, 2022
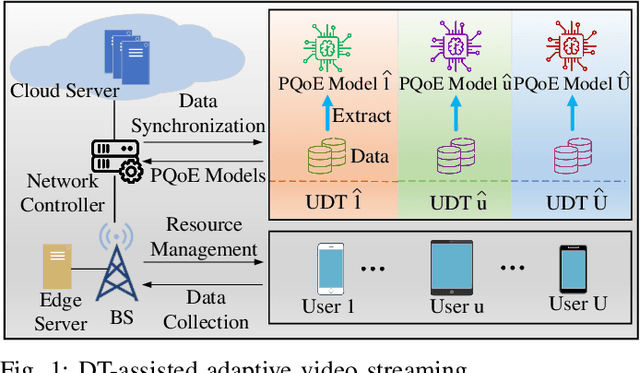
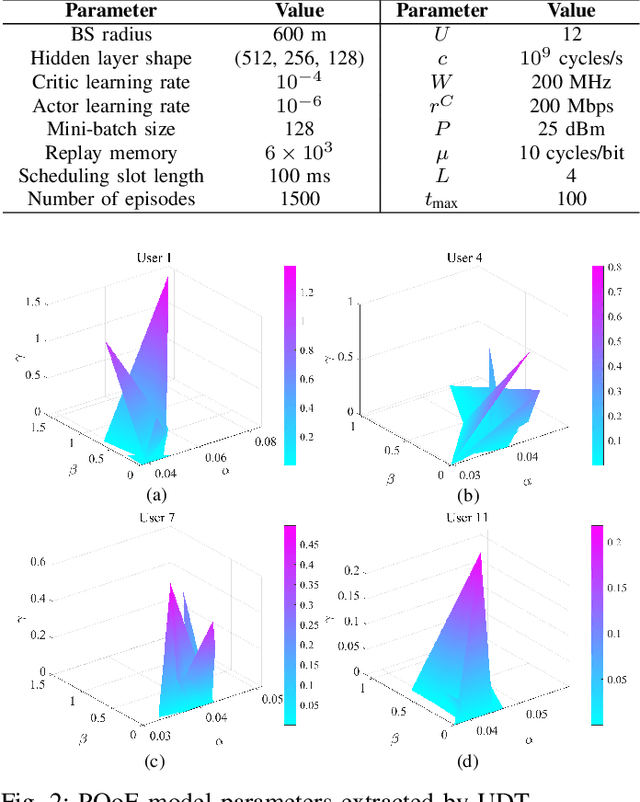
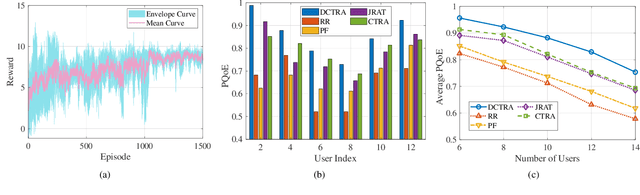
In this paper, we present a digital twin (DT)-assisted adaptive video streaming scheme to enhance personalized quality-of-experience (PQoE). Since PQoE models are user-specific and time-varying, existing schemes based on universal and time-invariant PQoE models may suffer from performance degradation. To address this issue, we first propose a DT-assisted PQoE model construction method to obtain accurate user-specific PQoE models. Specifically, user DTs (UDTs) are respectively constructed for individual users, which can acquire and utilize users' data to accurately tune PQoE model parameters in real time. Next, given the obtained PQoE models, we formulate a resource management problem to maximize the overall long-term PQoE by taking the dynamics of user' locations, video content requests, and buffer statuses into account. To solve this problem, a deep reinforcement learning algorithm is developed to jointly determine segment version selection, and communication and computing resource allocation. Simulation results on the real-world dataset demonstrate that the proposed scheme can effectively enhance PQoE compared with benchmark schemes.
BED: A Real-Time Object Detection System for Edge Devices
Feb 14, 2022


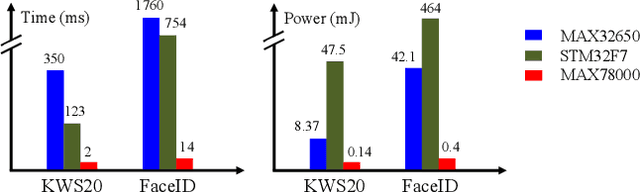
Deploying machine learning models to edge devices has many real-world applications, especially for the scenarios that demand low latency, low power, or data privacy. However, it requires substantial research and engineering efforts due to the limited computational resources and memory of edge devices. In this demo, we present BED, an object detection system for edge devices practiced on the MAX78000 DNN accelerator. BED integrates on-device DNN inference with a camera and a screen for image acquisition and output exhibition, respectively. Experiment results indicate BED can provide accurate detection with an only 300KB tiny DNN model.
Online TSP with Predictions
Jun 30, 2022We initiate the study of online routing problems with predictions, inspired by recent exciting results in the area of learning-augmented algorithms. A learning-augmented online algorithm which incorporates predictions in a black-box manner to outperform existing algorithms if the predictions are accurate while otherwise maintaining theoretical guarantees even when the predictions are extremely erroneous is a popular framework for overcoming pessimistic worst-case competitive analysis. In this study, we particularly begin investigating the classical online traveling salesman problem (OLTSP), where future requests are augmented with predictions. Unlike the prediction models in other previous studies, each actual request in the OLTSP, associated with its arrival time and position, may not coincide with the predicted ones, which, as imagined, leads to a troublesome situation. Our main result is to study different prediction models and design algorithms to improve the best-known results in the different settings. Moreover, we generalize the proposed results to the online dial-a-ride problem.
Revisiting Competitive Coding Approach for Palmprint Recognition: A Linear Discriminant Analysis Perspective
Jun 30, 2022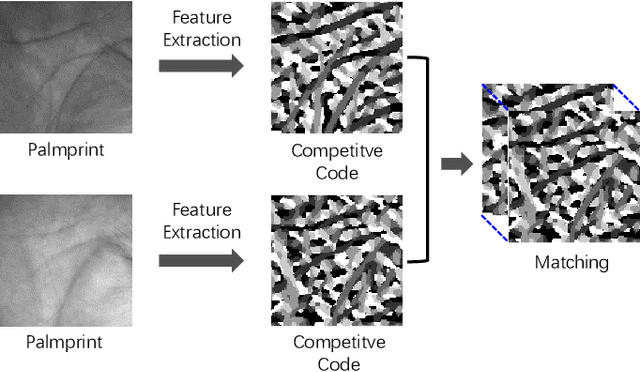

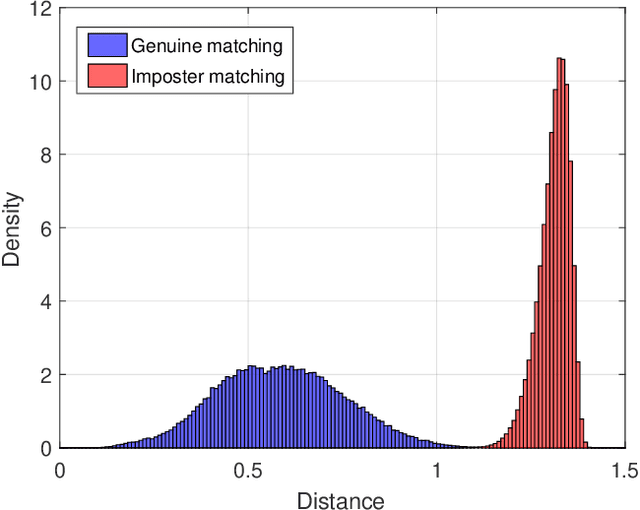
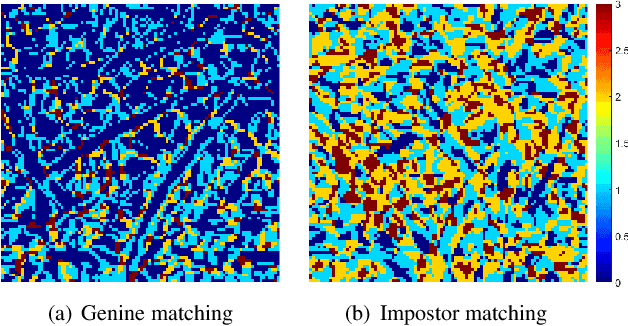
The competitive Coding approach (CompCode) is one of the most promising methods for palmprint recognition. Due to its high performance and simple formulation, it has been continuously studied for many years. However, although numerous variations of CompCode have been proposed, a detailed analysis of the method is still absent. In this paper, we provide a detailed analysis of CompCode from the perspective of linear discriminant analysis (LDA) for the first time. A non-trivial sufficient condition under which the CompCode is optimal in the sense of Fisher's criterion is presented. Based on our analysis, we examined the statistics of palmprints and concluded that CompCode deviates from the optimal condition. To mitigate the deviation, we propose a new method called Class-Specific CompCode that improves CompCode by excluding non-palm-line areas from matching. A nonlinear mapping of the competitive code is also applied in this method to further enhance accuracy. Experiments on two public databases demonstrate the effectiveness of the proposed method.
TAMOLS: Terrain-Aware Motion Optimization for Legged Systems
Jun 28, 2022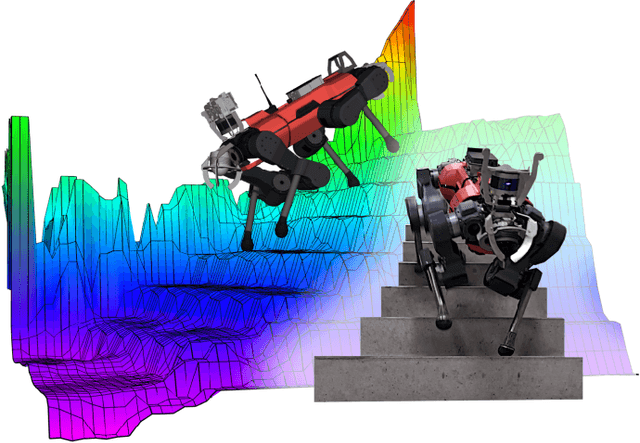
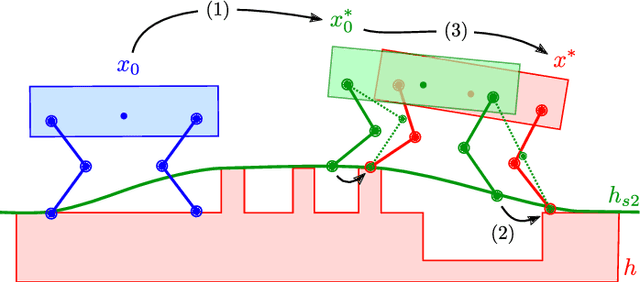
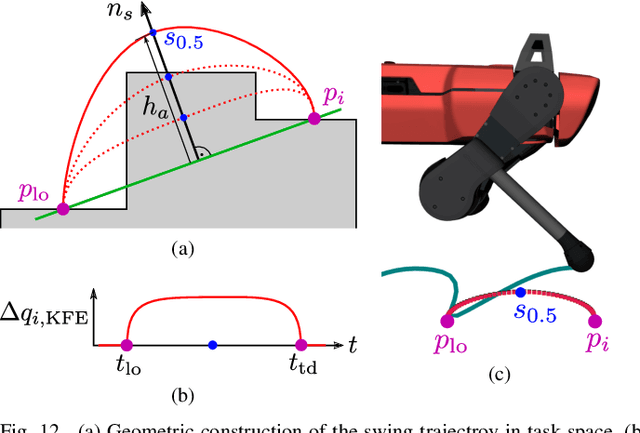
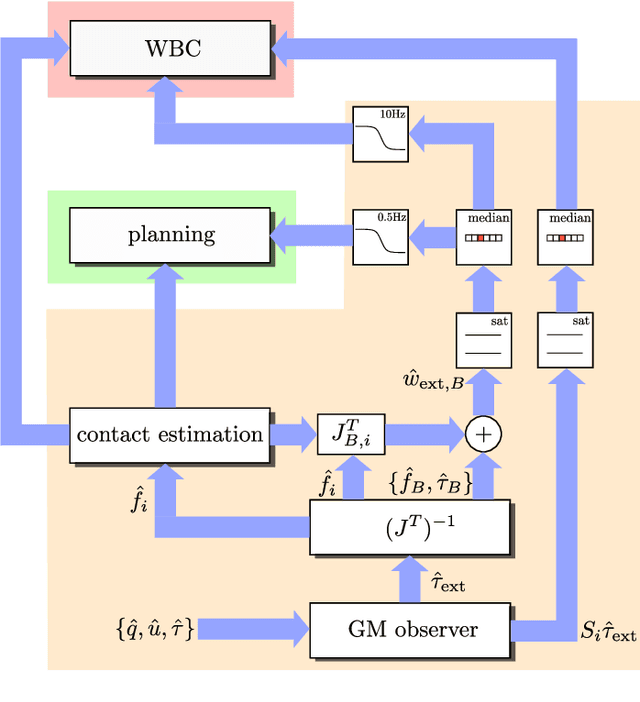
Terrain geometry is, in general, non-smooth, non-linear, non-convex, and, if perceived through a robot-centric visual unit, appears partially occluded and noisy. This work presents the complete control pipeline capable of handling the aforementioned problems in real-time. We formulate a trajectory optimization problem that jointly optimizes over the base pose and footholds, subject to a heightmap. To avoid converging into undesirable local optima, we deploy a graduated optimization technique. We embed a compact, contact-force free stability criterion that is compatible with the non-flat ground formulation. Direct collocation is used as transcription method, resulting in a non-linear optimization problem that can be solved online in less than ten milliseconds. To increase robustness in the presence of external disturbances, we close the tracking loop with a momentum observer. Our experiments demonstrate stair climbing, walking on stepping stones, and over gaps, utilizing various dynamic gaits.
Insights into the origin of halo mass profiles from machine learning
May 09, 2022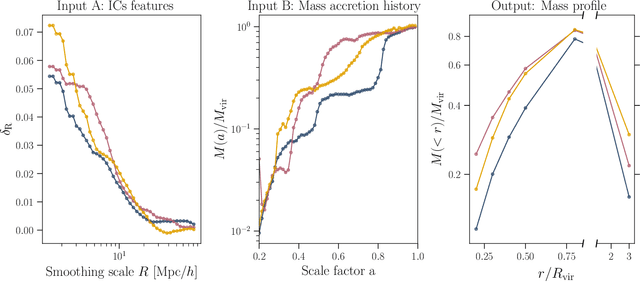
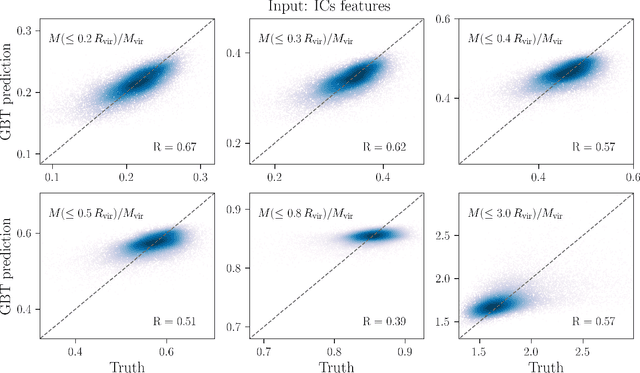
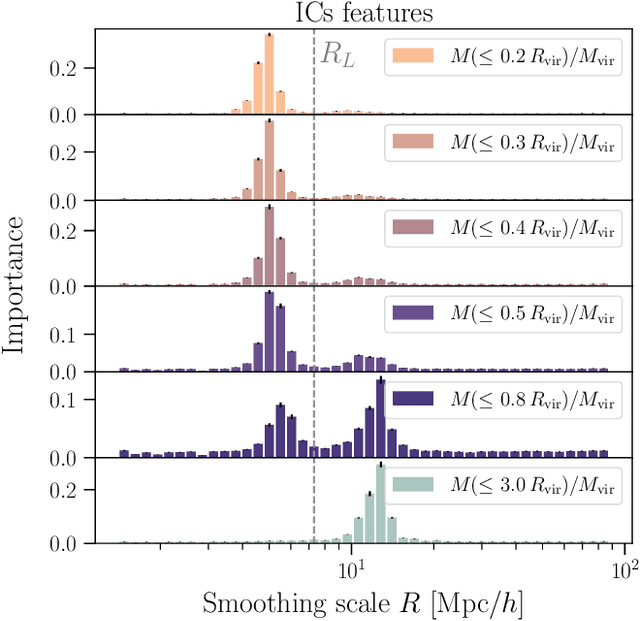
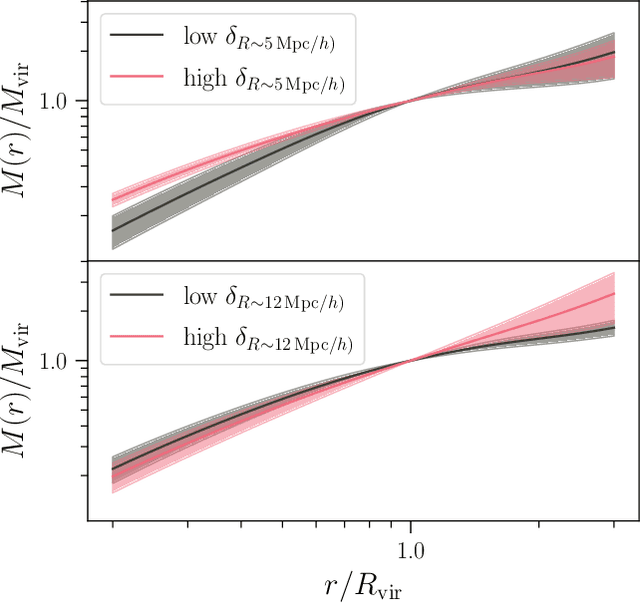
The mass distribution of dark matter haloes is the result of the hierarchical growth of initial density perturbations through mass accretion and mergers. We use an interpretable machine-learning framework to provide physical insights into the origin of the spherically-averaged mass profile of dark matter haloes. We train a gradient-boosted-trees algorithm to predict the final mass profiles of cluster-sized haloes, and measure the importance of the different inputs provided to the algorithm. We find two primary scales in the initial conditions (ICs) that impact the final mass profile: the density at approximately the scale of the haloes' Lagrangian patch $R_L$ ($R\sim 0.7\, R_L$) and that in the large-scale environment ($R\sim 1.7~R_L$). The model also identifies three primary time-scales in the halo assembly history that affect the final profile: (i) the formation time of the virialized, collapsed material inside the halo, (ii) the dynamical time, which captures the dynamically unrelaxed, infalling component of the halo over its first orbit, (iii) a third, most recent time-scale, which captures the impact on the outer profile of recent massive merger events. While the inner profile retains memory of the ICs, this information alone is insufficient to yield accurate predictions for the outer profile. As we add information about the haloes' mass accretion history, we find a significant improvement in the predicted profiles at all radii. Our machine-learning framework provides novel insights into the role of the ICs and the mass assembly history in determining the final mass profile of cluster-sized haloes.
A Near-Optimal Best-of-Both-Worlds Algorithm for Online Learning with Feedback Graphs
Jun 01, 2022We consider online learning with feedback graphs, a sequential decision-making framework where the learner's feedback is determined by a directed graph over the action set. We present a computationally efficient algorithm for learning in this framework that simultaneously achieves near-optimal regret bounds in both stochastic and adversarial environments. The bound against oblivious adversaries is $\tilde{O} (\sqrt{\alpha T})$, where $T$ is the time horizon and $\alpha$ is the independence number of the feedback graph. The bound against stochastic environments is $O\big( (\ln T)^2 \max_{S\in \mathcal I(G)} \sum_{i \in S} \Delta_i^{-1}\big)$ where $\mathcal I(G)$ is the family of all independent sets in a suitably defined undirected version of the graph and $\Delta_i$ are the suboptimality gaps. The algorithm combines ideas from the EXP3++ algorithm for stochastic and adversarial bandits and the EXP3.G algorithm for feedback graphs with a novel exploration scheme. The scheme, which exploits the structure of the graph to reduce exploration, is key to obtain best-of-both-worlds guarantees with feedback graphs. We also extend our algorithm and results to a setting where the feedback graphs are allowed to change over time.
Asynchronous Distributed Bayesian Optimization at HPC Scale
Jul 04, 2022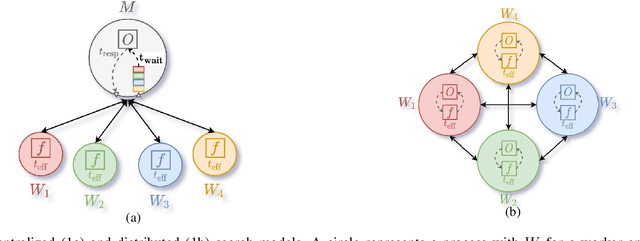
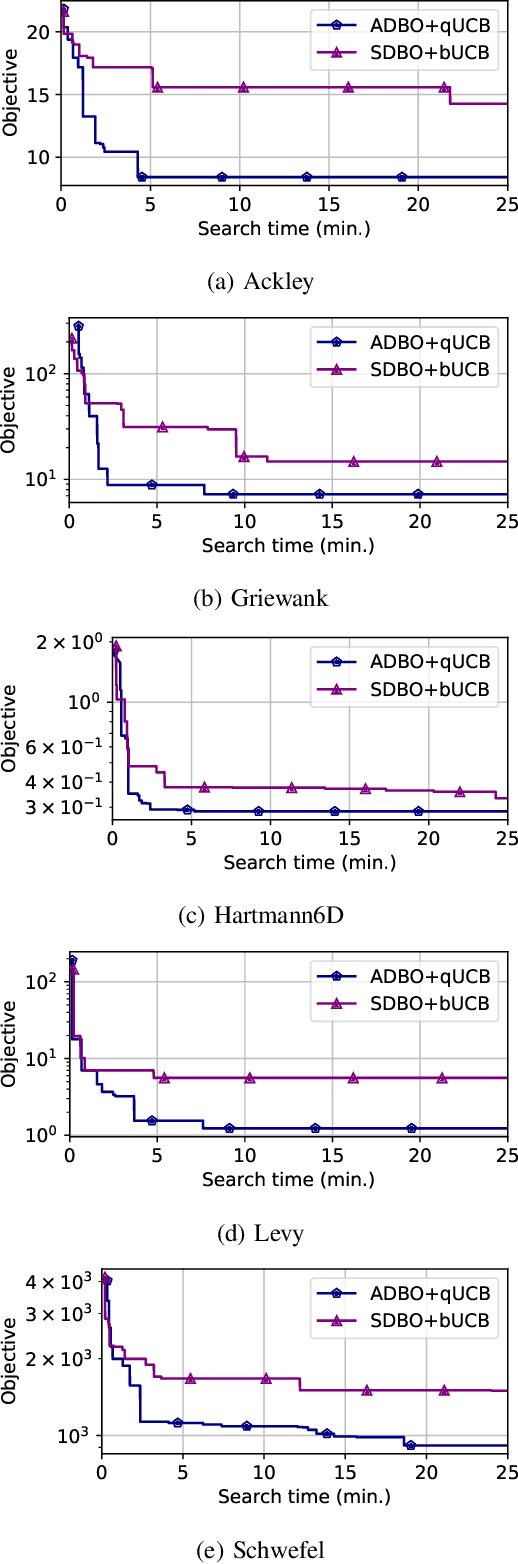
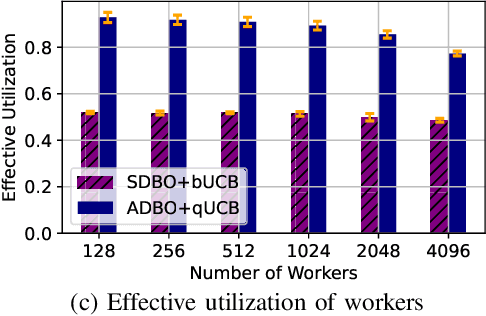

Bayesian optimization (BO) is a widely used approach for computationally expensive black-box optimization such as simulator calibration and hyperparameter optimization of deep learning methods. In BO, a dynamically updated computationally cheap surrogate model is employed to learn the input-output relationship of the black-box function; this surrogate model is used to explore and exploit the promising regions of the input space. Multipoint BO methods adopt a single manager/multiple workers strategy to achieve high-quality solutions in shorter time. However, the computational overhead in multipoint generation schemes is a major bottleneck in designing BO methods that can scale to thousands of workers. We present an asynchronous-distributed BO (ADBO) method wherein each worker runs a search and asynchronously communicates the input-output values of black-box evaluations from all other workers without the manager. We scale our method up to 4,096 workers and demonstrate improvement in the quality of the solution and faster convergence. We demonstrate the effectiveness of our approach for tuning the hyperparameters of neural networks from the Exascale computing project CANDLE benchmarks.
FETA: Fairness Enforced Verifying, Training, and Predicting Algorithms for Neural Networks
Jun 01, 2022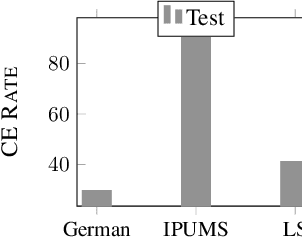
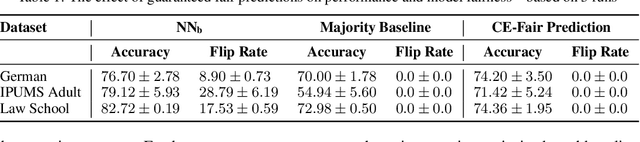

Algorithmic decision making driven by neural networks has become very prominent in applications that directly affect people's quality of life. In this paper, we study the problem of verifying, training, and guaranteeing individual fairness of neural network models. A popular approach for enforcing fairness is to translate a fairness notion into constraints over the parameters of the model. However, such a translation does not always guarantee fair predictions of the trained neural network model. To address this challenge, we develop a counterexample-guided post-processing technique to provably enforce fairness constraints at prediction time. Contrary to prior work that enforces fairness only on points around test or train data, we are able to enforce and guarantee fairness on all points in the input domain. Additionally, we propose an in-processing technique to use fairness as an inductive bias by iteratively incorporating fairness counterexamples in the learning process. We have implemented these techniques in a tool called FETA. Empirical evaluation on real-world datasets indicates that FETA is not only able to guarantee fairness on-the-fly at prediction time but also is able to train accurate models exhibiting a much higher degree of individual fairness.
Attention mechanisms for physiological signal deep learning: which attention should we take?
Jul 04, 2022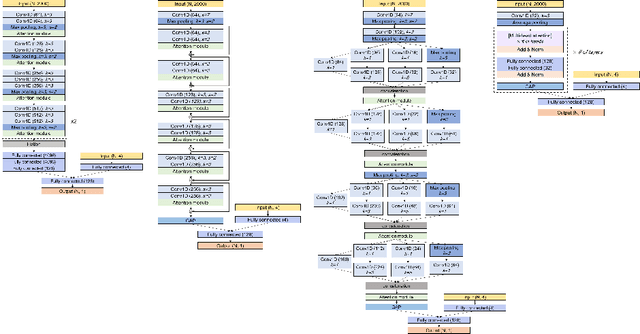
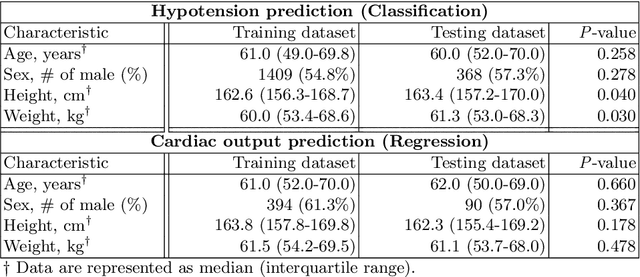
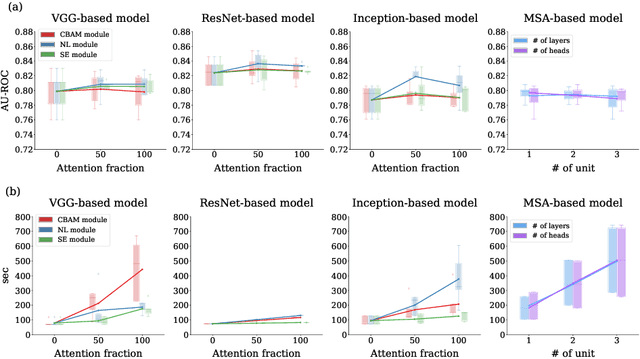
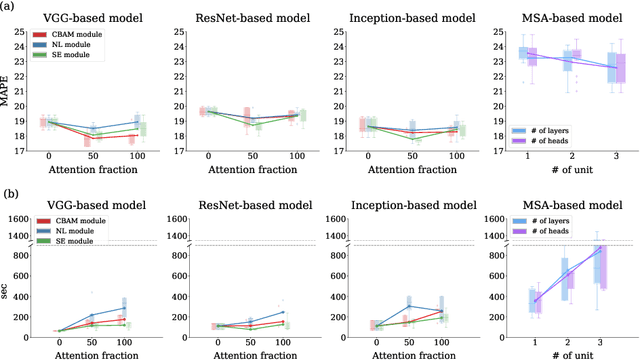
Attention mechanisms are widely used to dramatically improve deep learning model performance in various fields. However, their general ability to improve the performance of physiological signal deep learning model is immature. In this study, we experimentally analyze four attention mechanisms (e.g., squeeze-and-excitation, non-local, convolutional block attention module, and multi-head self-attention) and three convolutional neural network (CNN) architectures (e.g., VGG, ResNet, and Inception) for two representative physiological signal prediction tasks: the classification for predicting hypotension and the regression for predicting cardiac output (CO). We evaluated multiple combinations for performance and convergence of physiological signal deep learning model. Accordingly, the CNN models with the spatial attention mechanism showed the best performance in the classification problem, whereas the channel attention mechanism achieved the lowest error in the regression problem. Moreover, the performance and convergence of the CNN models with attention mechanisms were better than stand-alone self-attention models in both problems. Hence, we verified that convolutional operation and attention mechanisms are complementary and provide faster convergence time, despite the stand-alone self-attention models requiring fewer parameters.