 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The WQN algorithm to adaptively correct artifacts in the EEG signal
Jul 24, 2022
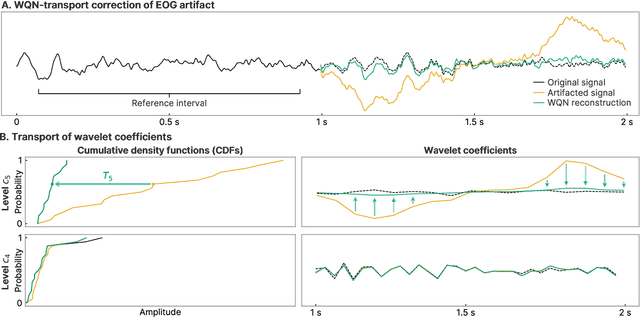
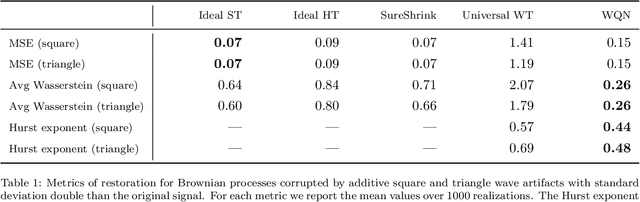
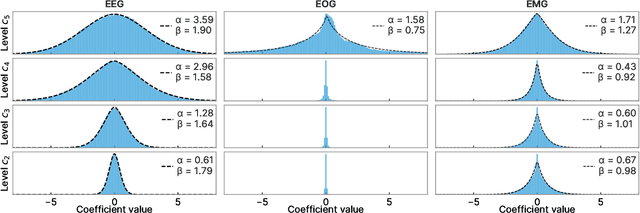
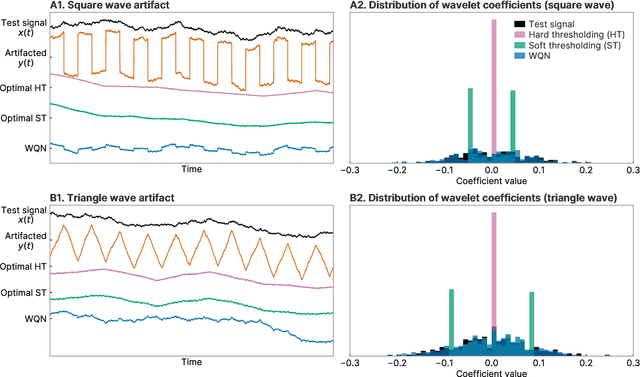
Wavelet quantile normalization (WQN) is a nonparametric algorithm designed to efficiently remove transient artifacts from single-channel EEG in real-time clinical monitoring. Today, EEG monitoring machines suspend their output when artifacts in the signal are detected. Removing unpredictable EEG artifacts would thus allow to improve the continuity of the monitoring. We analyze the WQN algorithm which consists in transporting wavelet coefficient distributions of an artifacted epoch into a reference, uncontaminated signal distribution. We show that the algorithm regularizes the signal. To confirm that the algorithm is well suited, we study the empirical distributions of the EEG and the artifacts wavelet coefficients. We compare the WQN algorithm to the classical wavelet thresholding methods and study their effect on the distribution of the wavelet coefficients. We show that the WQN algorithm preserves the distribution while the thresholding methods can cause alterations. Finally, we show how the spectrogram computed from an EEG signal can be cleaned using the WQN algorithm.
Deep Machine Learning Reconstructing Lattice Topology with Strong Thermal Fluctuations
Aug 08, 2022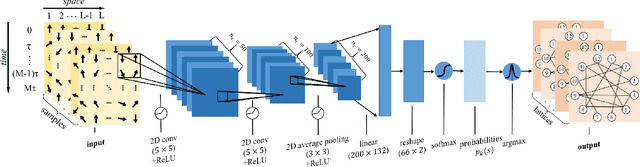
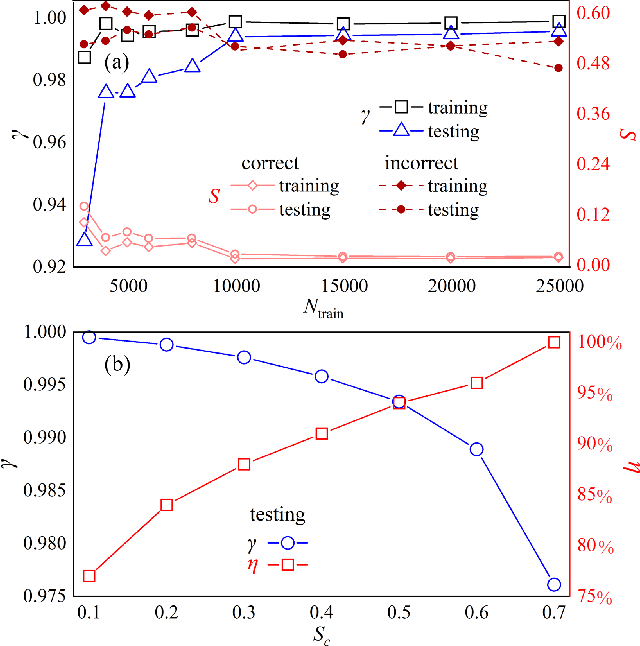
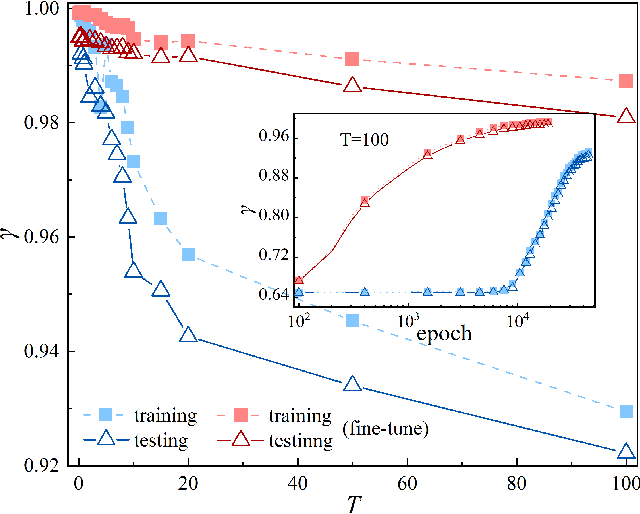
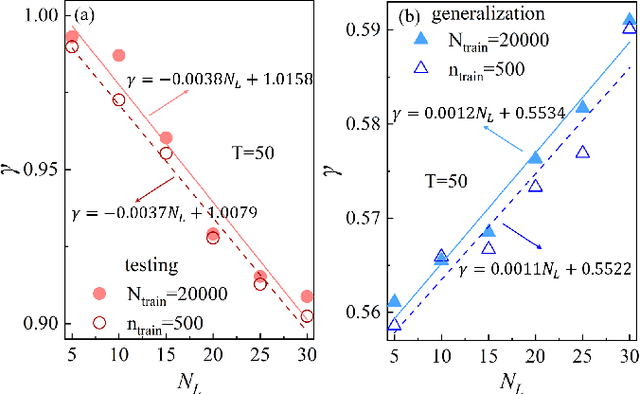
Applying artificial intelligence to scientific problems (namely AI for science) is currently under hot debate. However, the scientific problems differ much from the conventional ones with images, texts, and etc., where new challenges emerges with the unbalanced scientific data and complicated effects from the physical setups. In this work, we demonstrate the validity of the deep convolutional neural network (CNN) on reconstructing the lattice topology (i.e., spin connectivities) in the presence of strong thermal fluctuations and unbalanced data. Taking the kinetic Ising model with Glauber dynamics as an example, the CNN maps the time-dependent local magnetic momenta (a single-node feature) evolved from a specific initial configuration (dubbed as an evolution instance) to the probabilities of the presences of the possible couplings. Our scheme distinguishes from the previous ones that might require the knowledge on the node dynamics, the responses from perturbations, or the evaluations of statistic quantities such as correlations or transfer entropy from many evolution instances. The fine tuning avoids the "barren plateau" caused by the strong thermal fluctuations at high temperatures. Accurate reconstructions can be made where the thermal fluctuations dominate over the correlations and consequently the statistic methods in general fail. Meanwhile, we unveil the generalization of CNN on dealing with the instances evolved from the unlearnt initial spin configurations and those with the unlearnt lattices. We raise an open question on the learning with unbalanced data in the nearly "double-exponentially" large sample space.
Gradient-based Neuromorphic Learning on Dynamical RRAM Arrays
Jun 26, 2022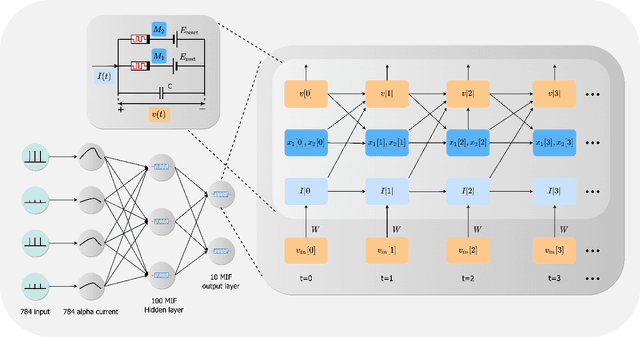
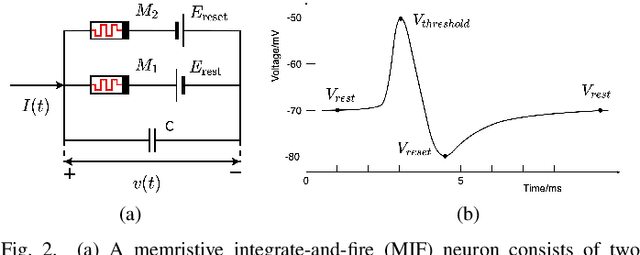
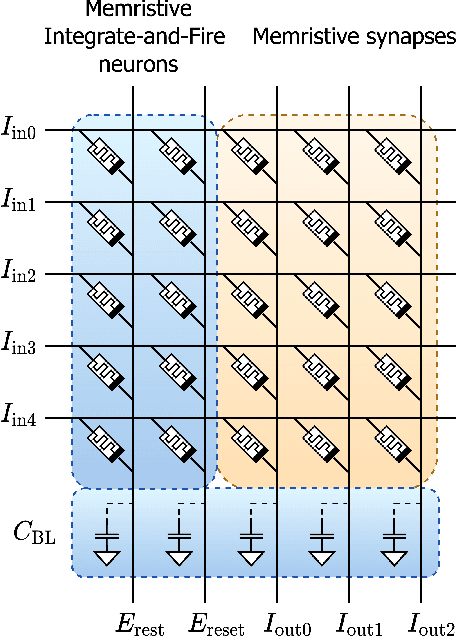
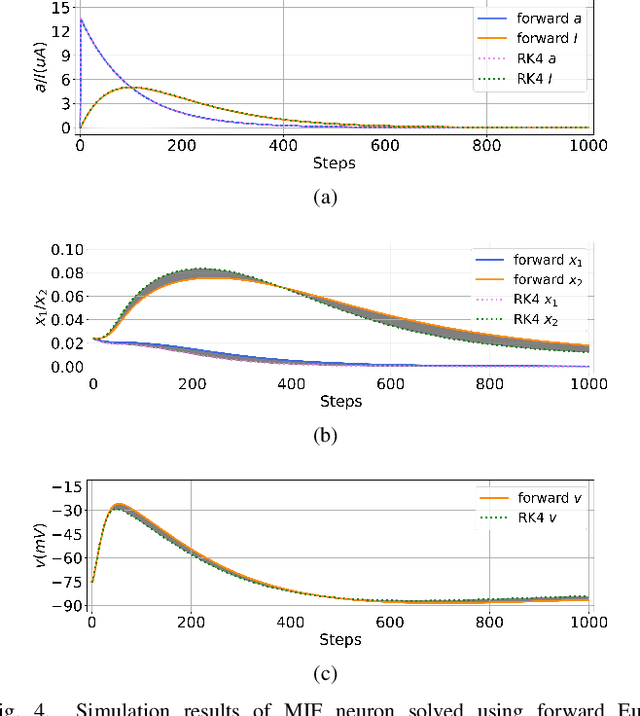
We present MEMprop, the adoption of gradient-based learning to train fully memristive spiking neural networks (MSNNs). Our approach harnesses intrinsic device dynamics to trigger naturally arising voltage spikes. These spikes emitted by memristive dynamics are analog in nature, and thus fully differentiable, which eliminates the need for surrogate gradient methods that are prevalent in the spiking neural network (SNN) literature. Memristive neural networks typically either integrate memristors as synapses that map offline-trained networks, or otherwise rely on associative learning mechanisms to train networks of memristive neurons. We instead apply the backpropagation through time (BPTT) training algorithm directly on analog SPICE models of memristive neurons and synapses. Our implementation is fully memristive, in that synaptic weights and spiking neurons are both integrated on resistive RAM (RRAM) arrays without the need for additional circuits to implement spiking dynamics, e.g., analog-to-digital converters (ADCs) or thresholded comparators. As a result, higher-order electrophysical effects are fully exploited to use the state-driven dynamics of memristive neurons at run time. By moving towards non-approximate gradient-based learning, we obtain highly competitive accuracy amongst previously reported lightweight dense fully MSNNs on several benchmarks.
What Do Deep Neural Networks Find in Disordered Structures of Glasses?
Jul 31, 2022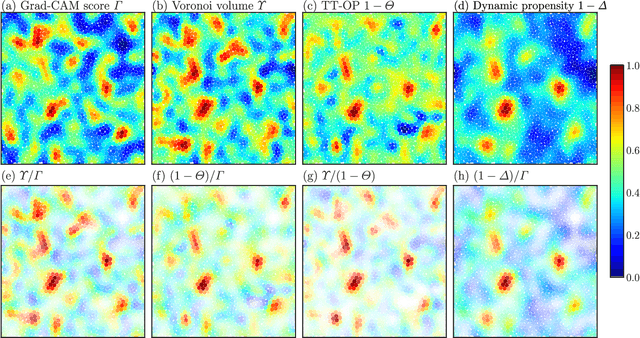
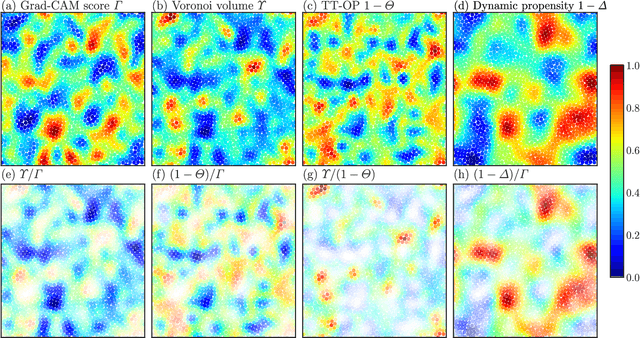
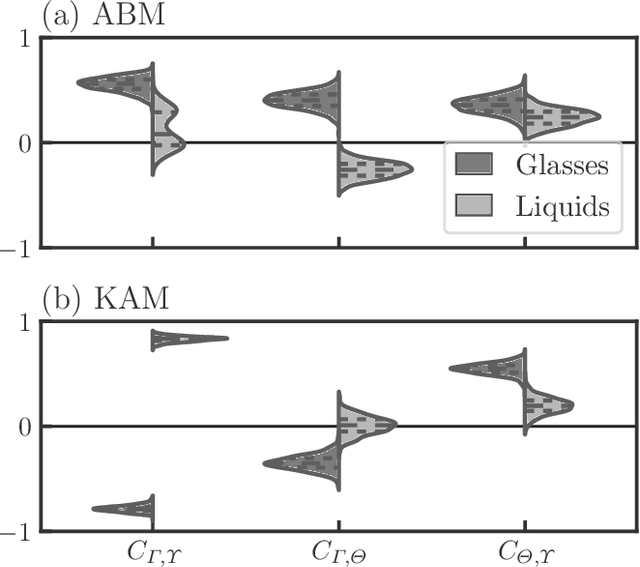
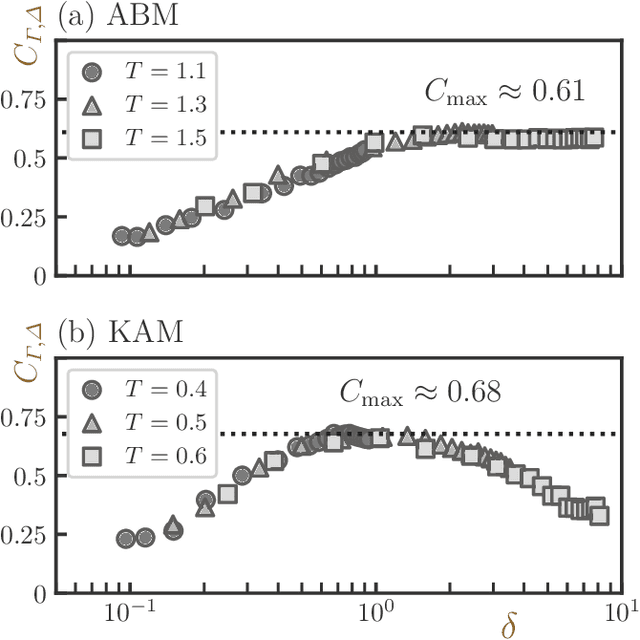
Glass transitions are widely observed in a range of types of soft matter systems. However, the physical mechanism of these transitions remains unknown, despite years of ambitious research. In particular, an important unanswered question is whether the glass transition is accompanied by a divergence of the correlation lengths of the characteristic static structures. Recently, a method that can predict long-time dynamics from purely static information with high accuracy was proposed; however, even this method is not universal and does not work well for the Kob--Andersen system, which is a typical model of glass-forming liquids. In this study, we developed a method to extract the characteristic structures of glasses using machine learning or, specifically, a convolutional neural network. In particular, we extracted the characteristic structures by quantifying the grounds for the decisions made by the network. We considered two qualitatively different glass-forming binary systems and, through comparisons with several established structural indicators, we demonstrate that our system can identify characteristic structures that depend on the details of the systems. Surprisingly, the extracted structures were strongly correlated with the nonequilibrium aging dynamics on thermal fluctuation.
Machine Learning Approaches to Predict Breast Cancer: Bangladesh Perspective
Jun 30, 2022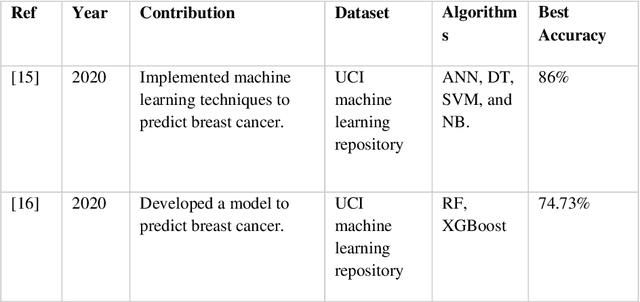
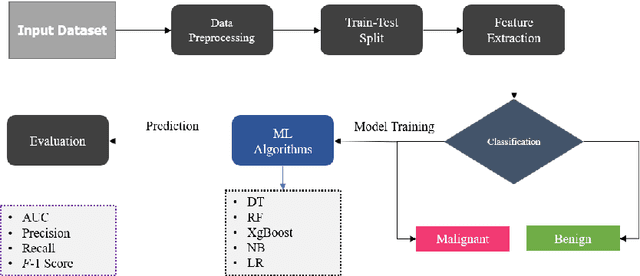
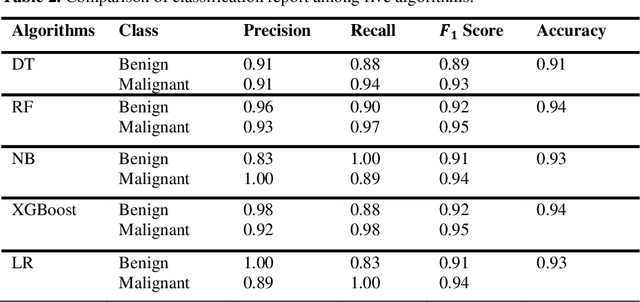
Nowadays, Breast cancer has risen to become one of the most prominent causes of death in recent years. Among all malignancies, this is the most frequent and the major cause of death for women globally. Manually diagnosing this disease requires a good amount of time and expertise. Breast cancer detection is time-consuming, and the spread of the disease can be reduced by developing machine-based breast cancer predictions. In Machine learning, the system can learn from prior instances and find hard-to-detect patterns from noisy or complicated data sets using various statistical, probabilistic, and optimization approaches. This work compares several machine learning algorithm's classification accuracy, precision, sensitivity, and specificity on a newly collected dataset. In this work Decision tree, Random Forest, Logistic Regression, Naive Bayes, and XGBoost, these five machine learning approaches have been implemented to get the best performance on our dataset. This study focuses on finding the best algorithm that can forecast breast cancer with maximum accuracy in terms of its classes. This work evaluated the quality of each algorithm's data classification in terms of efficiency and effectiveness. And also compared with other published work on this domain. After implementing the model, this study achieved the best model accuracy, 94% on Random Forest and XGBoost.
ORB-based SLAM accelerator on SoC FPGA
Jul 18, 2022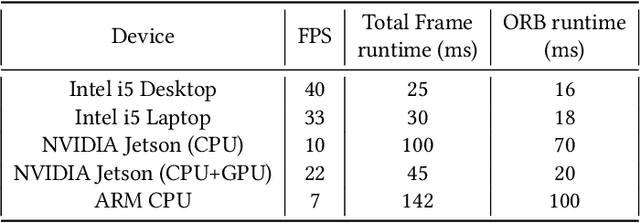
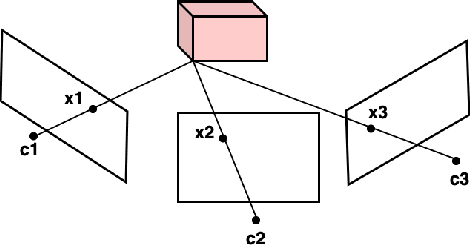
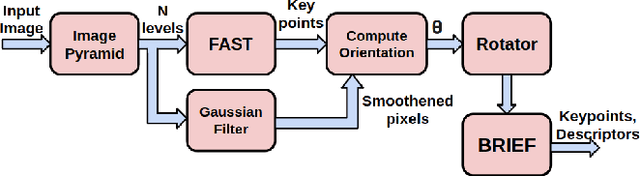
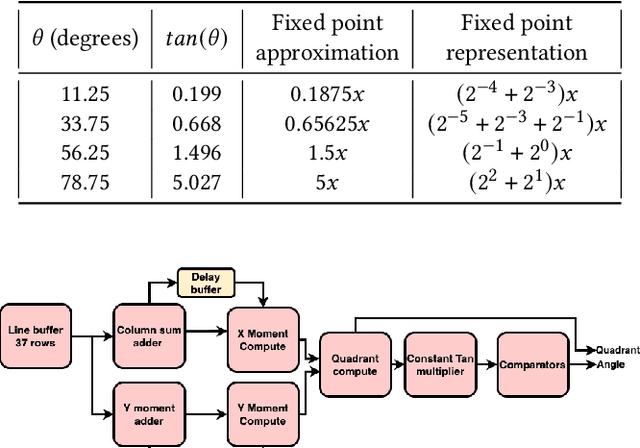
Simultaneous Localization and Mapping (SLAM) is one of the main components of autonomous navigation systems. With the increase in popularity of drones, autonomous navigation on low-power systems is seeing widespread application. Most SLAM algorithms are computationally intensive and struggle to run in real-time on embedded devices with reasonable accuracy. ORB-SLAM is an open-sourced feature-based SLAM that achieves high accuracy with reduced computational complexity. We propose an SoC based ORB-SLAM system that accelerates the computationally intensive visual feature extraction and matching on hardware. Our FPGA system based on a Zynq-family SoC runs 8.5x, 1.55x and 1.35x faster compared to an ARM CPU, Intel Desktop CPU, and a state-of-the-art FPGA system respectively, while averaging a 2x improvement in accuracy compared to prior work on FPGA.
An Efficient Forecasting Approach to Reduce Boundary Effects in Real-Time Time-Frequency Analysis
Feb 22, 2021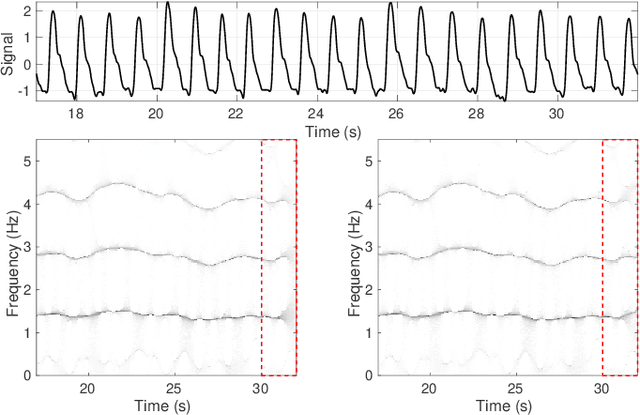
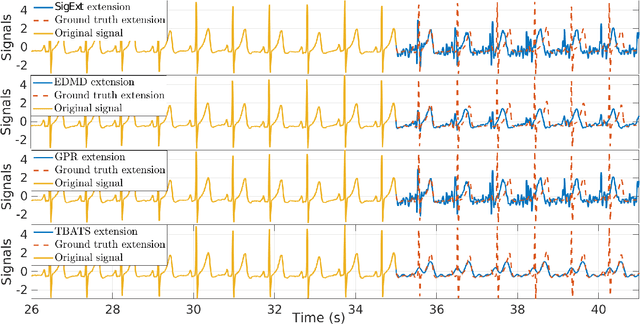
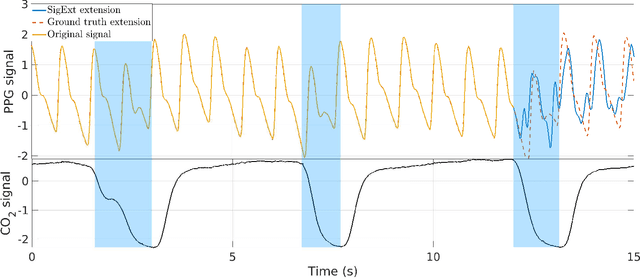
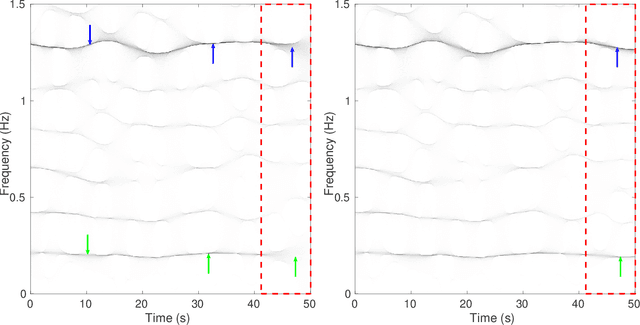
Time-frequency (TF) representations of time series are intrinsically subject to the boundary effects. As a result, the structures of signals that are highlighted by the representations are garbled when approaching the boundaries of the TF domain. In this paper, for the purpose of real-time TF information acquisition of nonstationary oscillatory time series, we propose a numerically efficient approach for the reduction of such boundary effects. The solution relies on an extension of the analyzed signal obtained by a forecasting technique. In the case of the study of a class of locally oscillating signals, we provide a theoretical guarantee of the performance of our approach. Following a numerical verification of the algorithmic performance of our approach, we validate it by implementing it on biomedical signals.
MetaGraspNet: A Large-Scale Benchmark Dataset for Scene-Aware Ambidextrous Bin Picking via Physics-based Metaverse Synthesis
Aug 08, 2022
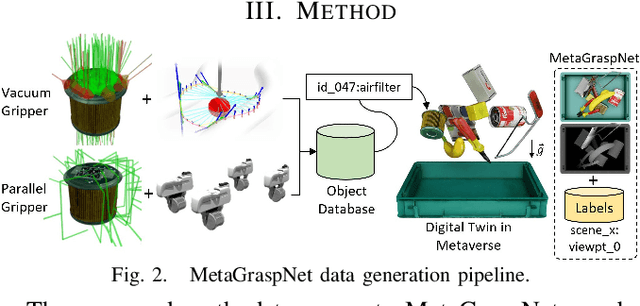
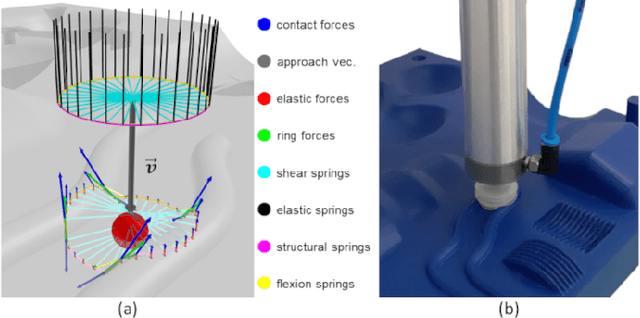
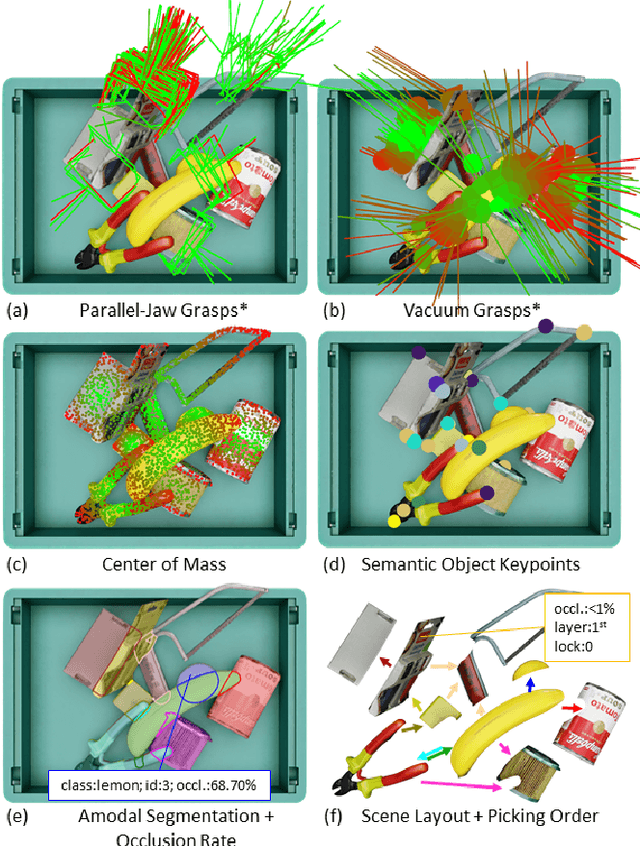
Autonomous bin picking poses significant challenges to vision-driven robotic systems given the complexity of the problem, ranging from various sensor modalities, to highly entangled object layouts, to diverse item properties and gripper types. Existing methods often address the problem from one perspective. Diverse items and complex bin scenes require diverse picking strategies together with advanced reasoning. As such, to build robust and effective machine-learning algorithms for solving this complex task requires significant amounts of comprehensive and high quality data. Collecting such data in real world would be too expensive and time prohibitive and therefore intractable from a scalability perspective. To tackle this big, diverse data problem, we take inspiration from the recent rise in the concept of metaverses, and introduce MetaGraspNet, a large-scale photo-realistic bin picking dataset constructed via physics-based metaverse synthesis. The proposed dataset contains 217k RGBD images across 82 different article types, with full annotations for object detection, amodal perception, keypoint detection, manipulation order and ambidextrous grasp labels for a parallel-jaw and vacuum gripper. We also provide a real dataset consisting of over 2.3k fully annotated high-quality RGBD images, divided into 5 levels of difficulties and an unseen object set to evaluate different object and layout properties. Finally, we conduct extensive experiments showing that our proposed vacuum seal model and synthetic dataset achieves state-of-the-art performance and generalizes to real world use-cases.
Video Activity Localisation with Uncertainties in Temporal Boundary
Jun 26, 2022

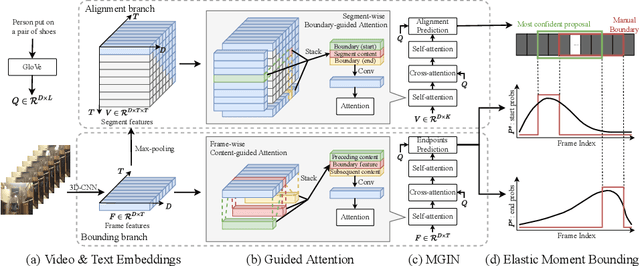
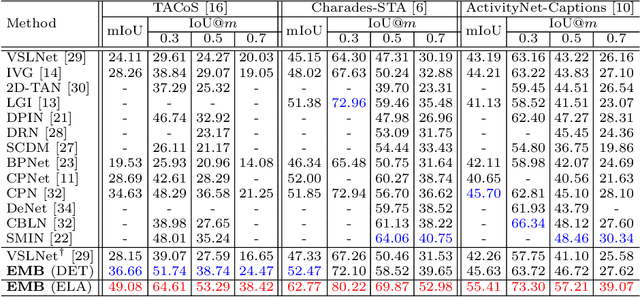
Current methods for video activity localisation over time assume implicitly that activity temporal boundaries labelled for model training are determined and precise. However, in unscripted natural videos, different activities mostly transit smoothly, so that it is intrinsically ambiguous to determine in labelling precisely when an activity starts and ends over time. Such uncertainties in temporal labelling are currently ignored in model training, resulting in learning mis-matched video-text correlation with poor generalisation in test. In this work, we solve this problem by introducing Elastic Moment Bounding (EMB) to accommodate flexible and adaptive activity temporal boundaries towards modelling universally interpretable video-text correlation with tolerance to underlying temporal uncertainties in pre-fixed annotations. Specifically, we construct elastic boundaries adaptively by mining and discovering frame-wise temporal endpoints that can maximise the alignment between video segments and query sentences. To enable both more robust matching (segment content attention) and more accurate localisation (segment elastic boundaries), we optimise the selection of frame-wise endpoints subject to segment-wise contents by a novel Guided Attention mechanism. Extensive experiments on three video activity localisation benchmarks demonstrate compellingly the EMB's advantages over existing methods without modelling uncertainty.
Delving into Effective Gradient Matching for Dataset Condensation
Jul 30, 2022
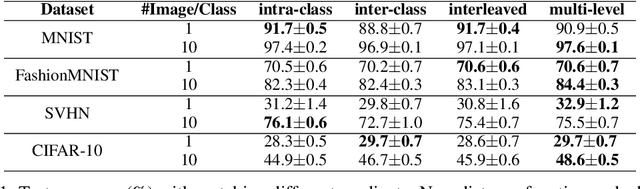
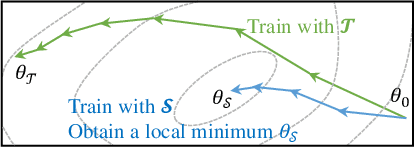

As deep learning models and datasets rapidly scale up, network training is extremely time-consuming and resource-costly. Instead of training on the entire dataset, learning with a small synthetic dataset becomes an efficient solution. Extensive research has been explored in the direction of dataset condensation, among which gradient matching achieves state-of-the-art performance. The gradient matching method directly targets the training dynamics by matching the gradient when training on the original and synthetic datasets. However, there are limited deep investigations into the principle and effectiveness of this method. In this work, we delve into the gradient matching method from a comprehensive perspective and answer the critical questions of what, how, and where to match. We propose to match the multi-level gradients to involve both intra-class and inter-class gradient information. We demonstrate that the distance function should focus on the angle, considering the magnitude simultaneously to delay the overfitting. An overfitting-aware adaptive learning step strategy is also proposed to trim unnecessary optimization steps for algorithmic efficiency improvement. Ablation and comparison experiments demonstrate that our proposed methodology shows superior accuracy, efficiency, and generalization compared to prior work.