 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoTales: A Multilingual Framework for Open-Ended Stereotype Discovery in LLMs
May 11, 2026Multilingual studies of social bias in open-ended LLM generation remain limited: most existing benchmarks are English-centric, template-based, or restricted to recognizing pre-specified stereotypes. We introduce StereoTales, a multilingual dataset and evaluation pipeline for systematically studying the emergence of social bias in open-ended LLM generation. The dataset covers 10 languages and 79 socio-demographic attributes, and comprises over 650k stories generated by 23 recent LLMs, each annotated with the socio-demographic profile of the protagonist across 19 dimensions. From these, we apply statistical tests to identify more than 1{,}500 over-represented associations, which we then rate for harmfulness through both a panel of humans (N = 247) and the same LLMs. We report three main findings. \textbf{(i)} Every model we evaluate emits consequential harmful stereotypes in open-ended generation, regardless of size or capabilities, and these associations are largely shared across providers rather than isolated misbehaviors. \textbf{(ii)} Prompt language strongly shapes which stereotypes appear: rather than transferring as a shared set of biases, harmful associations adapt culturally to the prompt language and amplify bias against locally salient protected groups. \textbf{(iii)} Human and LLM harmfulness judgments are broadly aligned (Spearman $ρ=0.62$), with disagreements concentrating on specific attribute classes rather than specific providers. To support further analyses, we release the evaluation code and the dataset, including model generations, attribute annotations, and harmfulness ratings.
Phare: A Safety Probe for Large Language Models
May 19, 2025



Ensuring the safety of large language models (LLMs) is critical for responsible deployment, yet existing evaluations often prioritize performance over identifying failure modes. We introduce Phare, a multilingual diagnostic framework to probe and evaluate LLM behavior across three critical dimensions: hallucination and reliability, social biases, and harmful content generation. Our evaluation of 17 state-of-the-art LLMs reveals patterns of systematic vulnerabilities across all safety dimensions, including sycophancy, prompt sensitivity, and stereotype reproduction. By highlighting these specific failure modes rather than simply ranking models, Phare provides researchers and practitioners with actionable insights to build more robust, aligned, and trustworthy language systems.
RealHarm: A Collection of Real-World Language Model Application Failures
Apr 14, 2025Language model deployments in consumer-facing applications introduce numerous risks. While existing research on harms and hazards of such applications follows top-down approaches derived from regulatory frameworks and theoretical analyses, empirical evidence of real-world failure modes remains underexplored. In this work, we introduce RealHarm, a dataset of annotated problematic interactions with AI agents built from a systematic review of publicly reported incidents. Analyzing harms, causes, and hazards specifically from the deployer's perspective, we find that reputational damage constitutes the predominant organizational harm, while misinformation emerges as the most common hazard category. We empirically evaluate state-of-the-art guardrails and content moderation systems to probe whether such systems would have prevented the incidents, revealing a significant gap in the protection of AI applications.
The WQN algorithm for EEG artifact removal in the absence of scale invariance
Jul 09, 2023Electroencephalogram (EEG) signals reflect brain activity across different brain states, characterized by distinct frequency distributions. Through multifractal analysis tools, we investigate the scaling behaviour of different classes of EEG signals and artifacts. We show that brain states associated to sleep and general anaesthesia are not in general characterized by scale invariance. The lack of scale invariance motivates the development of artifact removal algorithms capable of operating independently at each scale. We examine here the properties of the wavelet quantile normalization algorithm, a recently introduced adaptive method for real-time correction of transient artifacts in EEG signals. We establish general results regarding the regularization properties of the WQN algorithm, showing how it can eliminate singularities introduced by artefacts, and we compare it to traditional thresholding algorithms. Furthermore, we show that the algorithm performance is independent of the wavelet basis. We finally examine its continuity and boundedness properties and illustrate its distinctive non-local action on the wavelet coefficients through pathological examples.
The WQN algorithm to adaptively correct artifacts in the EEG signal
Jul 24, 2022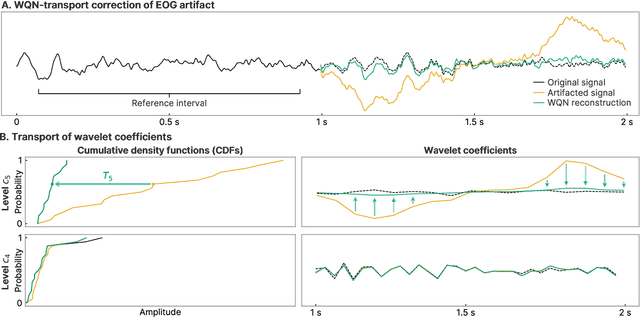
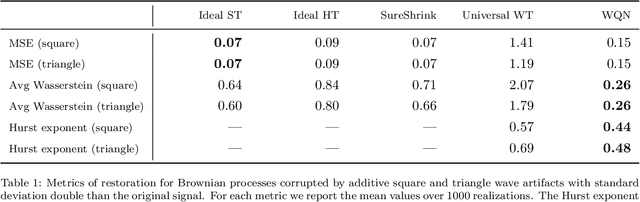
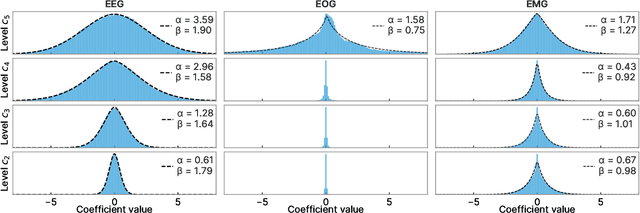
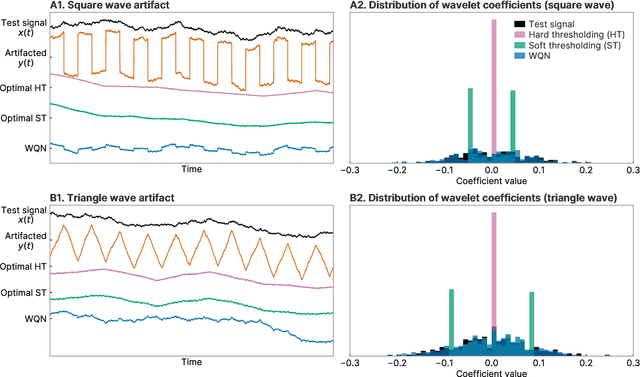
Wavelet quantile normalization (WQN) is a nonparametric algorithm designed to efficiently remove transient artifacts from single-channel EEG in real-time clinical monitoring. Today, EEG monitoring machines suspend their output when artifacts in the signal are detected. Removing unpredictable EEG artifacts would thus allow to improve the continuity of the monitoring. We analyze the WQN algorithm which consists in transporting wavelet coefficient distributions of an artifacted epoch into a reference, uncontaminated signal distribution. We show that the algorithm regularizes the signal. To confirm that the algorithm is well suited, we study the empirical distributions of the EEG and the artifacts wavelet coefficients. We compare the WQN algorithm to the classical wavelet thresholding methods and study their effect on the distribution of the wavelet coefficients. We show that the WQN algorithm preserves the distribution while the thresholding methods can cause alterations. Finally, we show how the spectrogram computed from an EEG signal can be cleaned using the WQN algorithm.