 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Frame Interpolation for Dynamic Scenes with Implicit Flow Encoding
Sep 27, 2022

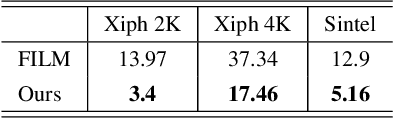
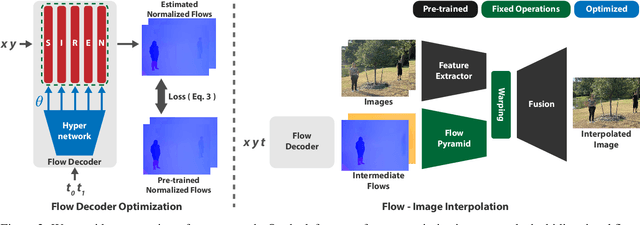
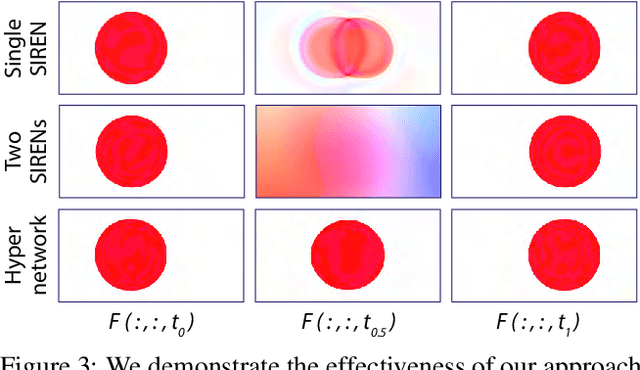
In this paper, we propose an algorithm to interpolate between a pair of images of a dynamic scene. While in the past years significant progress in frame interpolation has been made, current approaches are not able to handle images with brightness and illumination changes, which are common even when the images are captured shortly apart. We propose to address this problem by taking advantage of the existing optical flow methods that are highly robust to the variations in the illumination. Specifically, using the bidirectional flows estimated using an existing pre-trained flow network, we predict the flows from an intermediate frame to the two input images. To do this, we propose to encode the bidirectional flows into a coordinate-based network, powered by a hypernetwork, to obtain a continuous representation of the flow across time. Once we obtain the estimated flows, we use them within an existing blending network to obtain the final intermediate frame. Through extensive experiments, we demonstrate that our approach is able to produce significantly better results than state-of-the-art frame interpolation algorithms.
Clifford Neural Layers for PDE Modeling
Sep 08, 2022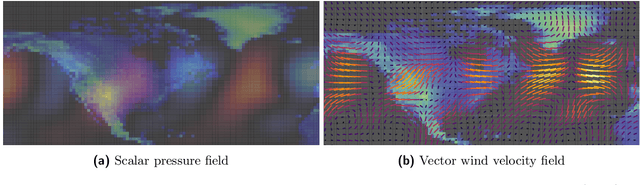
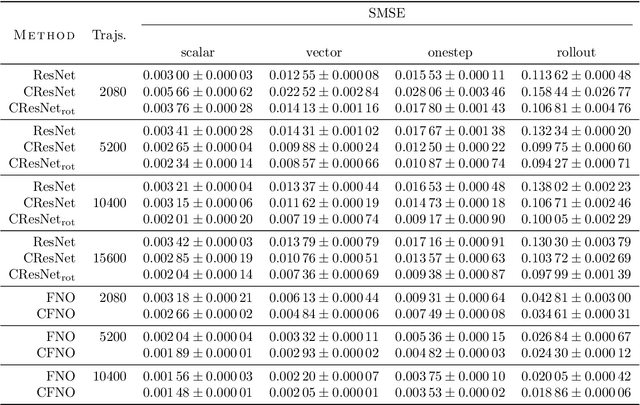
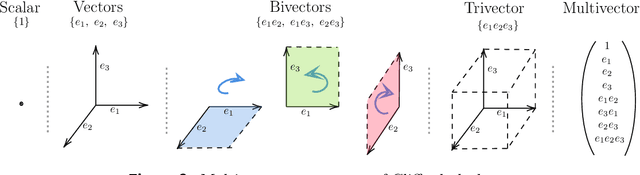
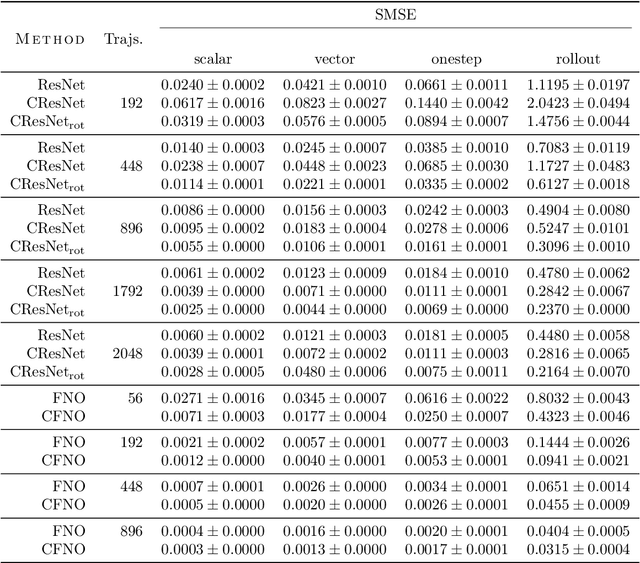
Partial differential equations (PDEs) see widespread use in sciences and engineering to describe simulation of physical processes as scalar and vector fields interacting and coevolving over time. Due to the computationally expensive nature of their standard solution methods, neural PDE surrogates have become an active research topic to accelerate these simulations. However, current methods do not explicitly take into account the relationship between different fields and their internal components, which are often correlated. Viewing the time evolution of such correlated fields through the lens of multivector fields allows us to overcome these limitations. Multivector fields consist of scalar, vector, as well as higher-order components, such as bivectors and trivectors. Their algebraic properties, such as multiplication, addition and other arithmetic operations can be described by Clifford algebras. To our knowledge, this paper presents the first usage of such multivector representations together with Clifford convolutions and Clifford Fourier transforms in the context of deep learning. The resulting Clifford neural layers are universally applicable and will find direct use in the areas of fluid dynamics, weather forecasting, and the modeling of physical systems in general. We empirically evaluate the benefit of Clifford neural layers by replacing convolution and Fourier operations in common neural PDE surrogates by their Clifford counterparts on two-dimensional Navier-Stokes and weather modeling tasks, as well as three-dimensional Maxwell equations. Clifford neural layers consistently improve generalization capabilities of the tested neural PDE surrogates.
A PAC-Bayes bound for deterministic classifiers
Sep 06, 2022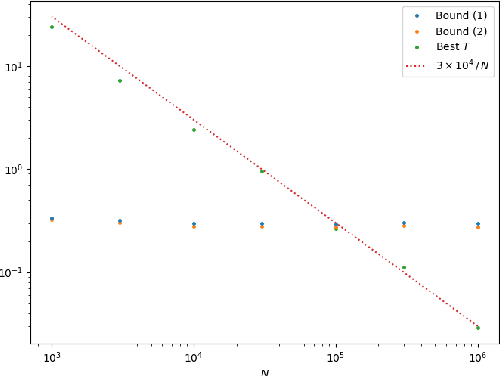
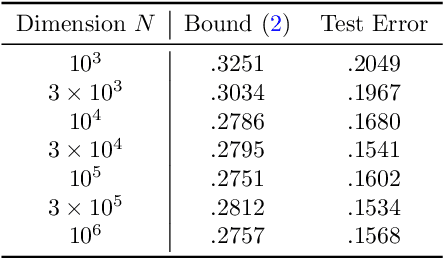
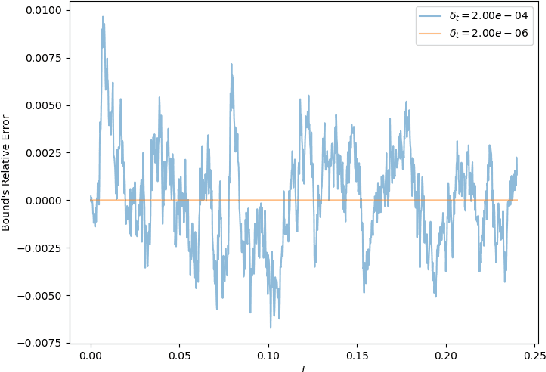
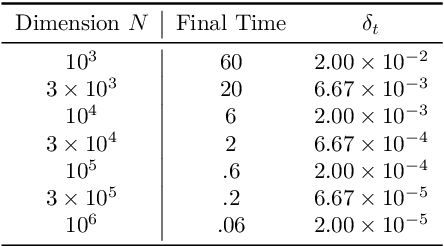
We establish a disintegrated PAC-Bayesian bound, for classifiers that are trained via continuous-time (non-stochastic) gradient descent. Contrarily to what is standard in the PAC-Bayesian setting, our result applies to a training algorithm that is deterministic, conditioned on a random initialisation, without requiring any $\textit{de-randomisation}$ step. We provide a broad discussion of the main features of the bound that we propose, and we study analytically and empirically its behaviour on linear models, finding promising results.
Keypoint-GraspNet: Keypoint-based 6-DoF Grasp Generation from the Monocular RGB-D input
Sep 19, 2022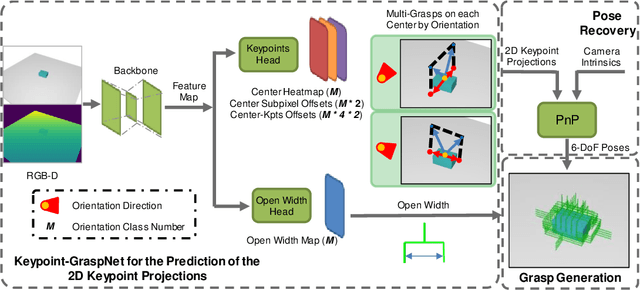
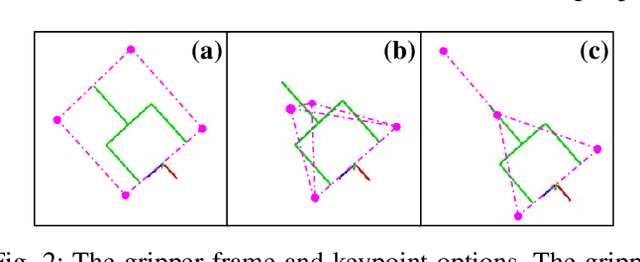
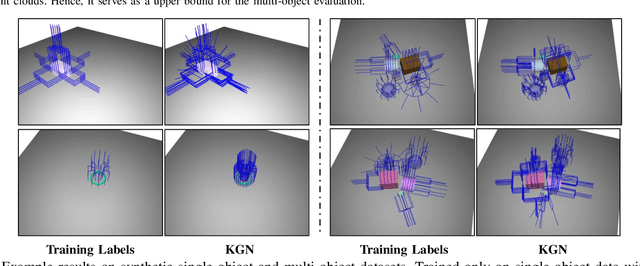
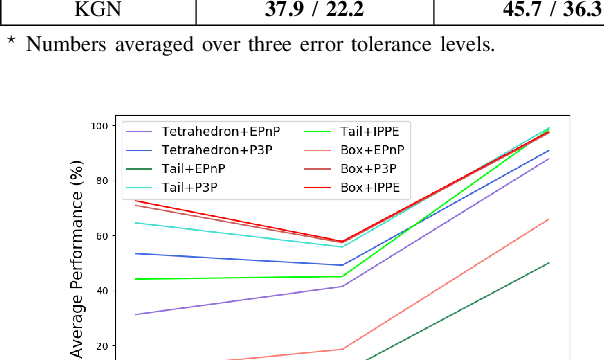
Great success has been achieved in the 6-DoF grasp learning from the point cloud input, yet the computational cost due to the point set orderlessness remains a concern. Alternatively, we explore the grasp generation from the RGB-D input in this paper. The proposed solution, Keypoint-GraspNet, detects the projection of the gripper keypoints in the image space and then recover the SE(3) poses with a PnP algorithm. A synthetic dataset based on the primitive shape and the grasp family is constructed to examine our idea. Metric-based evaluation reveals that our method outperforms the baselines in terms of the grasp proposal accuracy, diversity, and the time cost. Finally, robot experiments show high success rate, demonstrating the potential of the idea in the real-world applications.
AccelAT: A Framework for Accelerating the Adversarial Training of Deep Neural Networks through Accuracy Gradient
Oct 13, 2022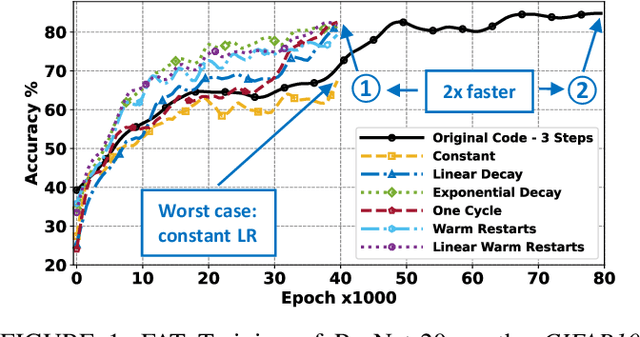

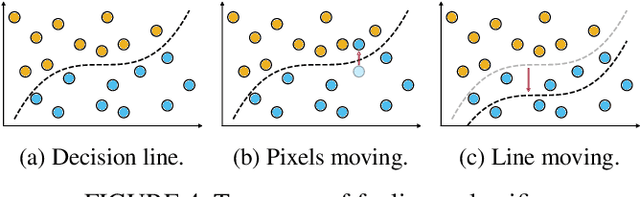
Adversarial training is exploited to develop a robust Deep Neural Network (DNN) model against the malicious altered data. These attacks may have catastrophic effects on DNN models but are indistinguishable for a human being. For example, an external attack can modify an image adding noises invisible for a human eye, but a DNN model misclassified the image. A key objective for developing robust DNN models is to use a learning algorithm that is fast but can also give model that is robust against different types of adversarial attacks. Especially for adversarial training, enormously long training times are needed for obtaining high accuracy under many different types of adversarial samples generated using different adversarial attack techniques. This paper aims at accelerating the adversarial training to enable fast development of robust DNN models against adversarial attacks. The general method for improving the training performance is the hyperparameters fine-tuning, where the learning rate is one of the most crucial hyperparameters. By modifying its shape (the value over time) and value during the training, we can obtain a model robust to adversarial attacks faster than standard training. First, we conduct experiments on two different datasets (CIFAR10, CIFAR100), exploring various techniques. Then, this analysis is leveraged to develop a novel fast training methodology, AccelAT, which automatically adjusts the learning rate for different epochs based on the accuracy gradient. The experiments show comparable results with the related works, and in several experiments, the adversarial training of DNNs using our AccelAT framework is conducted up to 2 times faster than the existing techniques. Thus, our findings boost the speed of adversarial training in an era in which security and performance are fundamental optimization objectives in DNN-based applications.
UV Volumes for Real-time Rendering of Editable Free-view Human Performance
Mar 27, 2022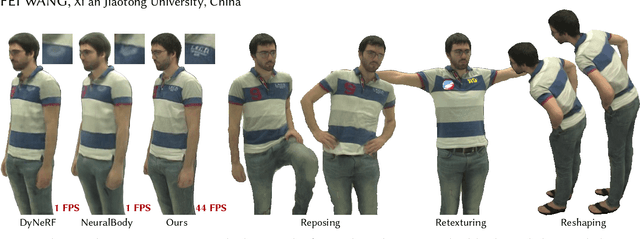
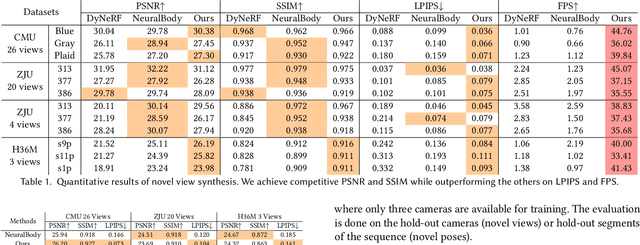
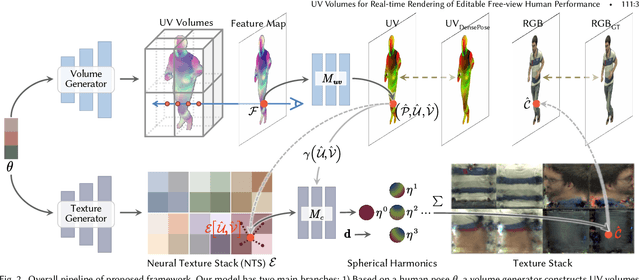

Neural volume rendering has been proven to be a promising method for efficient and photo-realistic rendering of a human performer in free-view, a critical task in many immersive VR/AR applications. However, existing approaches are severely limited by their high computational cost in the rendering process. To solve this problem, we propose the UV Volumes, an approach that can render an editable free-view video of a human performer in real-time. It is achieved by removing the high-frequency (i.e., non-smooth) human textures from the 3D volume and encoding them into a 2D neural texture stack (NTS). The smooth UV volume allows us to employ a much smaller and shallower structure for 3D CNN and MLP, to obtain the density and texture coordinates without losing image details. Meanwhile, the NTS only needs to be queried once for each pixel in the UV image to retrieve its RGB value. For editability, the 3D CNN and MLP decoder can easily fit the function that maps the input structured-and-posed latent codes to the relatively smooth densities and texture coordinates. It gives our model a better generalization ability to handle novel poses and shapes. Furthermore, the use of NST enables new applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 900 * 500 images in 40 fps on average with comparable photorealism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes.
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022
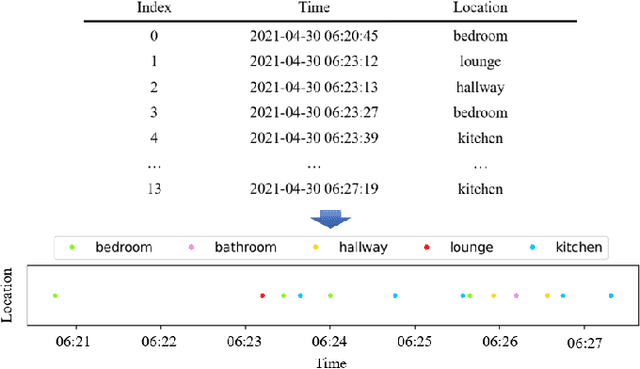
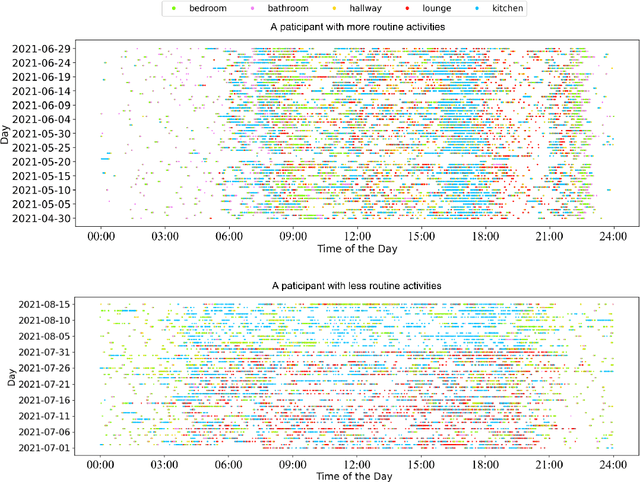
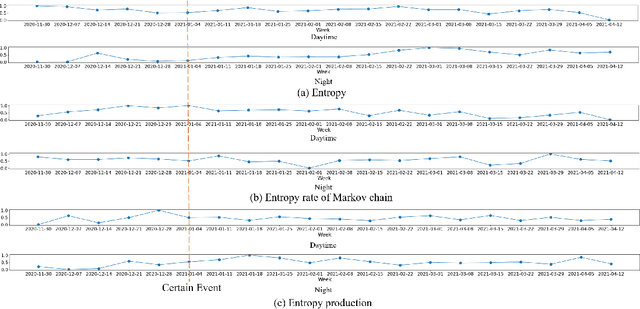
In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.
Digital Twin and Artificial Intelligence Incorporated With Surrogate Modeling for Hybrid and Sustainable Energy Systems
Sep 30, 2022
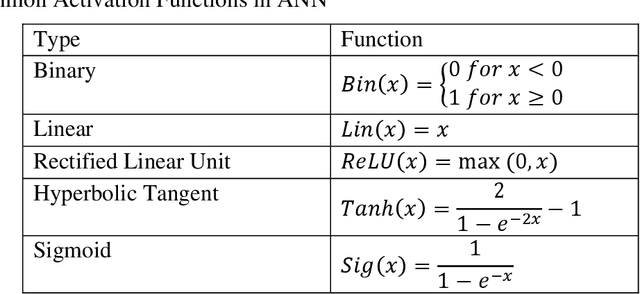
Surrogate modeling has brought about a revolution in computation in the branches of science and engineering. Backed by Artificial Intelligence, a surrogate model can present highly accurate results with a significant reduction in computation time than computer simulation of actual models. Surrogate modeling techniques have found their use in numerous branches of science and engineering, energy system modeling being one of them. Since the idea of hybrid and sustainable energy systems is spreading rapidly in the modern world for the paradigm of the smart energy shift, researchers are exploring the future application of artificial intelligence-based surrogate modeling in analyzing and optimizing hybrid energy systems. One of the promising technologies for assessing applicability for the energy system is the digital twin, which can leverage surrogate modeling. This work presents a comprehensive framework/review on Artificial Intelligence-driven surrogate modeling and its applications with a focus on the digital twin framework and energy systems. The role of machine learning and artificial intelligence in constructing an effective surrogate model is explained. After that, different surrogate models developed for different sustainable energy sources are presented. Finally, digital twin surrogate models and associated uncertainties are described.
Accelerating hypersonic reentry simulations using deep learning-based hybridization (with guarantees)
Sep 30, 2022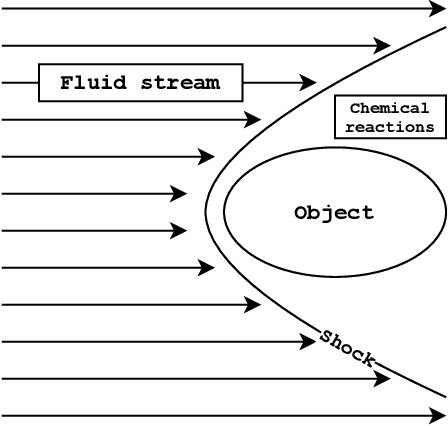

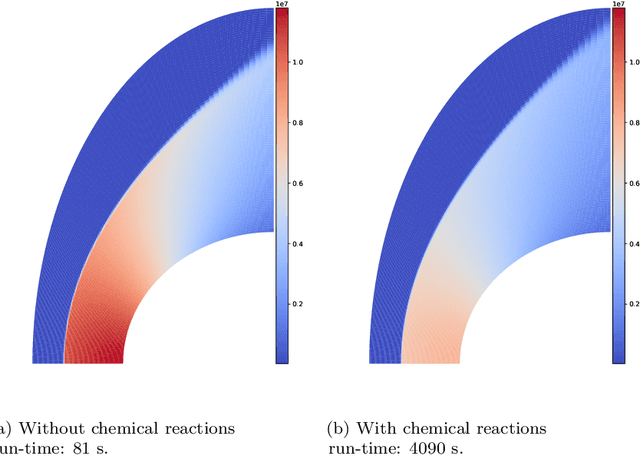
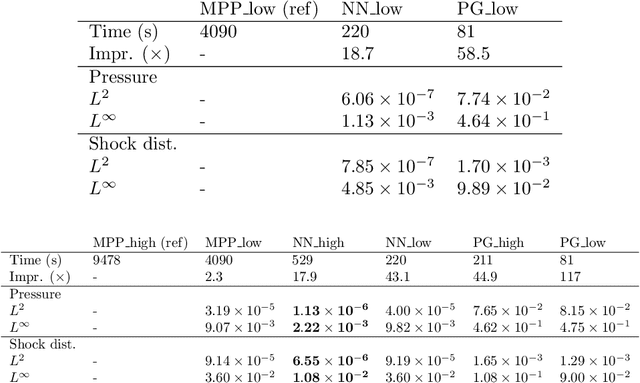
In this paper, we are interested in the acceleration of numerical simulations. We focus on a hypersonic planetary reentry problem whose simulation involves coupling fluid dynamics and chemical reactions. Simulating chemical reactions takes most of the computational time but, on the other hand, cannot be avoided to obtain accurate predictions. We face a trade-off between cost-efficiency and accuracy: the simulation code has to be sufficiently efficient to be used in an operational context but accurate enough to predict the phenomenon faithfully. To tackle this trade-off, we design a hybrid simulation code coupling a traditional fluid dynamic solver with a neural network approximating the chemical reactions. We rely on their power in terms of accuracy and dimension reduction when applied in a big data context and on their efficiency stemming from their matrix-vector structure to achieve important acceleration factors ($\times 10$ to $\times 18.6$). This paper aims to explain how we design such cost-effective hybrid simulation codes in practice. Above all, we describe methodologies to ensure accuracy guarantees, allowing us to go beyond traditional surrogate modeling and to use these codes as references.
Blockchain-based Monitoring for Poison Attack Detection in Decentralized Federated Learning
Sep 30, 2022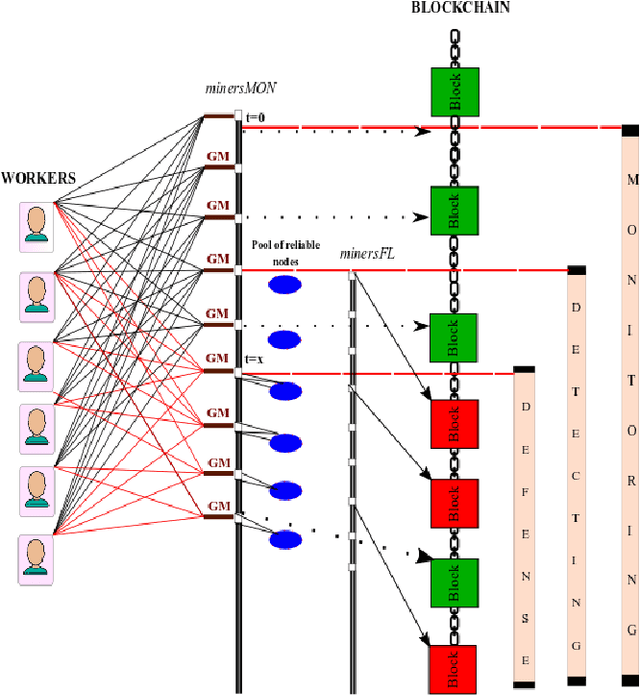
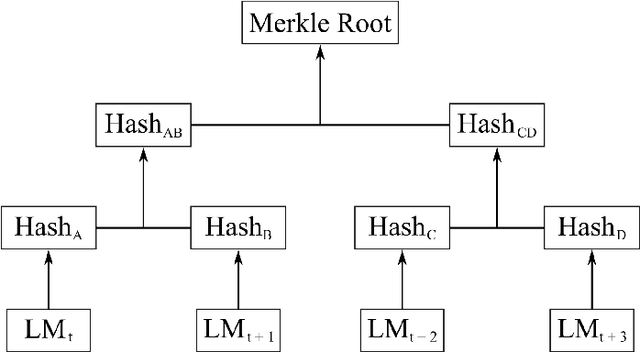
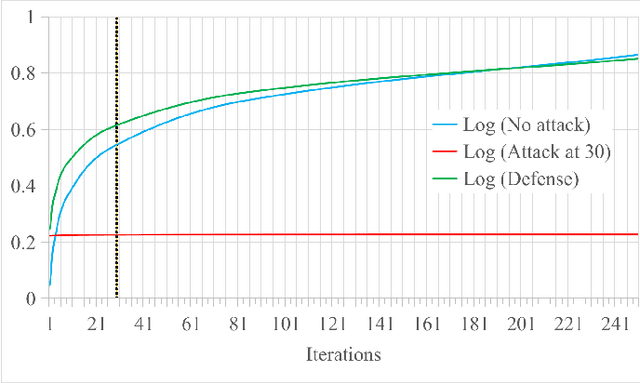
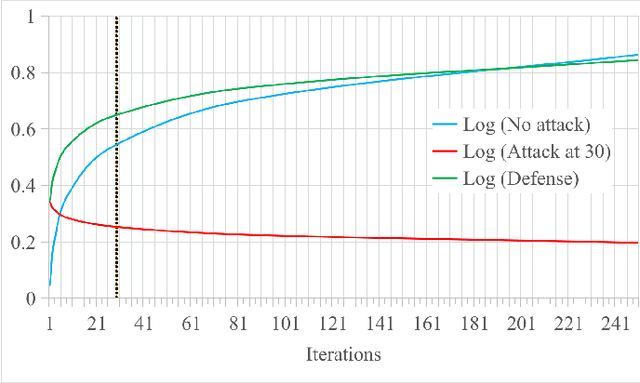
Federated Learning (FL) is a machine learning technique that addresses the privacy challenges in terms of access rights of local datasets by enabling the training of a model across nodes holding their data samples locally. To achieve decentralized federated learning, blockchain-based FL was proposed as a distributed FL architecture. In decentralized FL, the chief is eliminated from the learning process as workers collaborate between each other to train the global model. Decentralized FL applications need to account for the additional delay incurred by blockchain-based FL deployments. Particularly in this setting, to detect targeted/untargeted poisoning attacks, we investigate the end-to-end learning completion latency of a realistic decentralized FL process protected against poisoning attacks. We propose a technique which consists in decoupling the monitoring phase from the detection phase in defenses against poisoning attacks in a decentralized federated learning deployment that aim at monitoring the behavior of the workers. We demonstrate that our proposed blockchain-based monitoring improved network scalability, robustness and time efficiency. The parallelization of operations results in minimized latency over the end-to-end communication, computation, and consensus delays incurred during the FL and blockchain operations.