 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
System-level Impact of Non-Ideal Program-Time of Charge Trap Flash (CTF) on Deep Neural Network
Feb 15, 2024
Learning of deep neural networks (DNN) using Resistive Processing Unit (RPU) architecture is energy-efficient as it utilizes dedicated neuromorphic hardware and stochastic computation of weight updates for in-memory computing. Charge Trap Flash (CTF) devices can implement RPU-based weight updates in DNNs. However, prior work has shown that the weight updates (V_T) in CTF-based RPU are impacted by the non-ideal program time of CTF. The non-ideal program time is affected by two factors of CTF. Firstly, the effects of the number of input pulses (N) or pulse width (pw), and secondly, the gap between successive update pulses (t_gap) used for the stochastic computation of weight updates. Therefore, the impact of this non-ideal program time must be studied for neural network training simulations. In this study, Firstly, we propose a pulse-train design compensation technique to reduce the total error caused by non-ideal program time of CTF and stochastic variance of a network. Secondly, we simulate RPU-based DNN with non-ideal program time of CTF on MNIST and Fashion-MNIST datasets. We find that for larger N (~1000), learning performance approaches the ideal (software-level) training level and, therefore, is not much impacted by the choice of t_gap used to implement RPU-based weight updates. However, for lower N (<500), learning performance depends on T_gap of the pulses. Finally, we also performed an ablation study to isolate the causal factor of the improved learning performance. We conclude that the lower noise level in the weight updates is the most likely significant factor to improve the learning performance of DNN. Thus, our study attempts to compensate for the error caused by non-ideal program time and standardize the pulse length (N) and pulse gap (t_gap) specifications for CTF-based RPUs for accurate system-level on-chip training.
HyperPredict: Estimating Hyperparameter Effects for Instance-Specific Regularization in Deformable Image Registration
Mar 04, 2024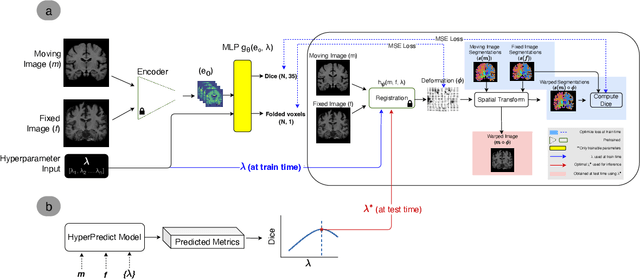

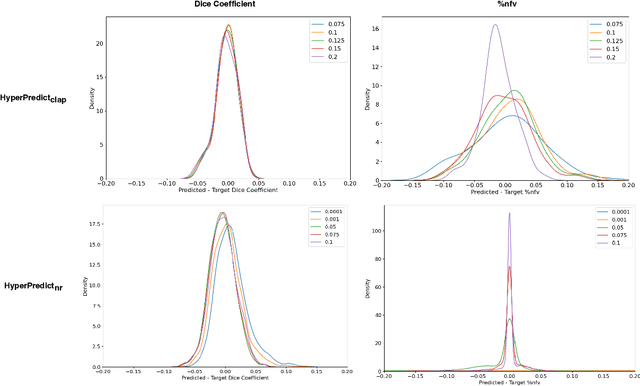
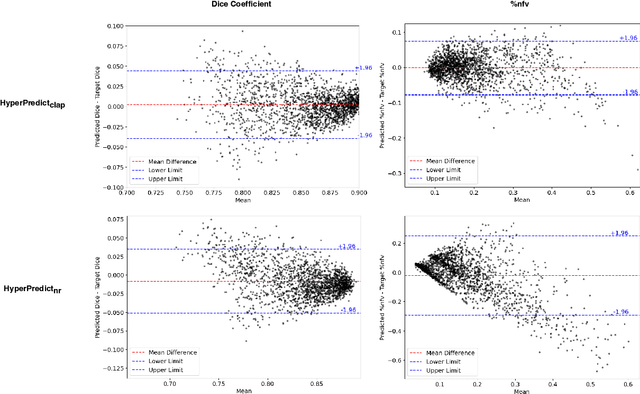
Methods for medical image registration infer geometric transformations that align pairs/groups of images by maximising an image similarity metric. This problem is ill-posed as several solutions may have equivalent likelihoods, also optimising purely for image similarity can yield implausible transformations. For these reasons regularization terms are essential to obtain meaningful registration results. However, this requires the introduction of at least one hyperparameter often termed {\lambda}, that serves as a tradeoff between loss terms. In some situations, the quality of the estimated transformation greatly depends on hyperparameter choice, and different choices may be required depending on the characteristics of the data. Analyzing the effect of these hyperparameters requires labelled data, which is not commonly available at test-time. In this paper, we propose a method for evaluating the influence of hyperparameters and subsequently selecting an optimal value for given image pairs. Our approach which we call HyperPredict, implements a Multi-Layer Perceptron that learns the effect of selecting particular hyperparameters for registering an image pair by predicting the resulting segmentation overlap and measure of deformation smoothness. This approach enables us to select optimal hyperparameters at test time without requiring labelled data, removing the need for a one-size-fits-all cross-validation approach. Furthermore, the criteria used to define optimal hyperparameter is flexible post-training, allowing us to efficiently choose specific properties. We evaluate our proposed method on the OASIS brain MR dataset using a recent deep learning approach(cLapIRN) and an algorithmic method(Niftyreg). Our results demonstrate good performance in predicting the effects of regularization hyperparameters and highlight the benefits of our image-pair specific approach to hyperparameter selection.
Transformer for Times Series: an Application to the S&P500
Mar 04, 2024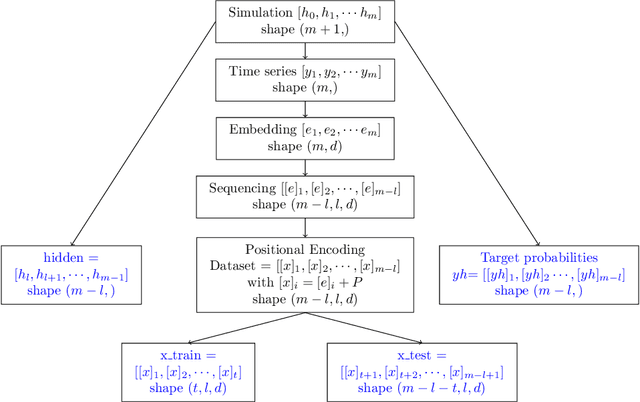

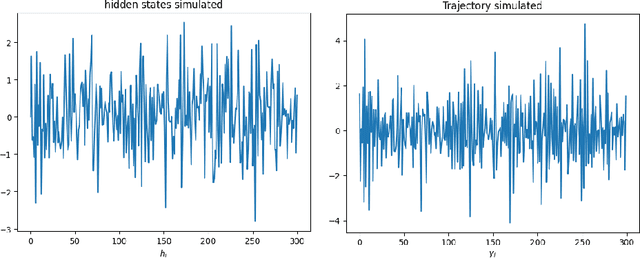
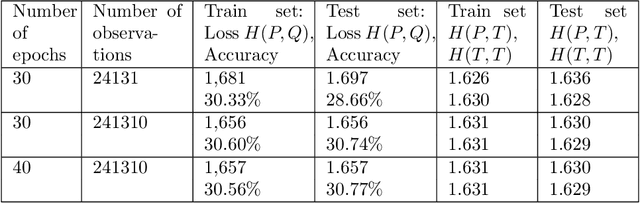
The transformer models have been extensively used with good results in a wide area of machine learning applications including Large Language Models and image generation. Here, we inquire on the applicability of this approach to financial time series. We first describe the dataset construction for two prototypical situations: a mean reverting synthetic Ornstein-Uhlenbeck process on one hand and real S&P500 data on the other hand. Then, we present in detail the proposed Transformer architecture and finally we discuss some encouraging results. For the synthetic data we predict rather accurately the next move, and for the S&P500 we get some interesting results related to quadratic variation and volatility prediction.
Lightweight Object Detection: A Study Based on YOLOv7 Integrated with ShuffleNetv2 and Vision Transformer
Mar 04, 2024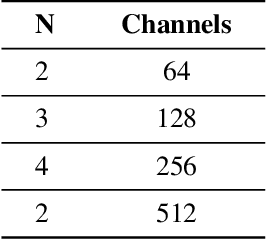
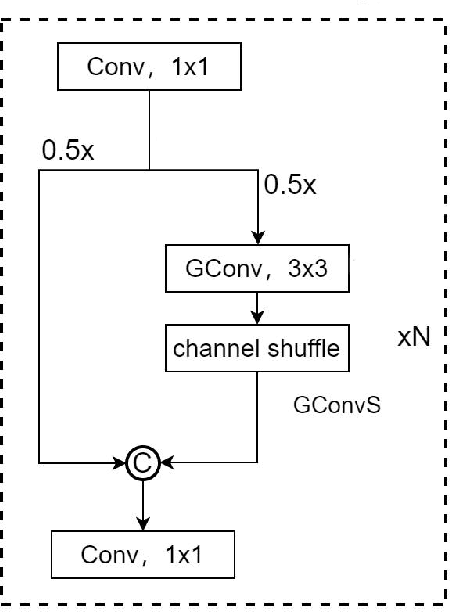
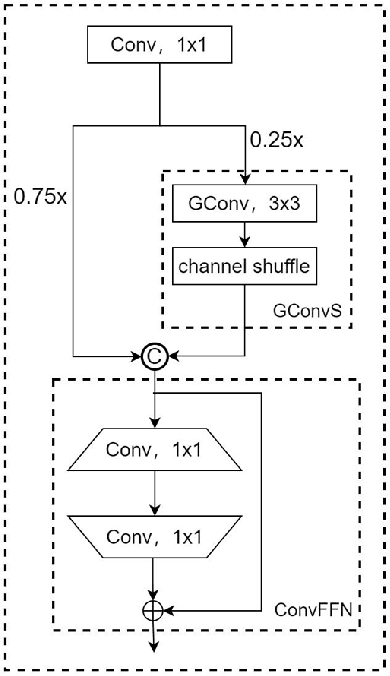

As mobile computing technology rapidly evolves, deploying efficient object detection algorithms on mobile devices emerges as a pivotal research area in computer vision. This study zeroes in on optimizing the YOLOv7 algorithm to boost its operational efficiency and speed on mobile platforms while ensuring high accuracy. Leveraging a synergy of advanced techniques such as Group Convolution, ShuffleNetV2, and Vision Transformer, this research has effectively minimized the model's parameter count and memory usage, streamlined the network architecture, and fortified the real-time object detection proficiency on resource-constrained devices. The experimental outcomes reveal that the refined YOLO model demonstrates exceptional performance, markedly enhancing processing velocity while sustaining superior detection accuracy.
Low Complexity Deep Learning Augmented Wireless Channel Estimation for Pilot-Based OFDM on Zynq System on Chip
Mar 02, 2024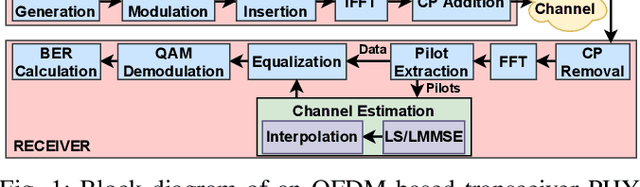
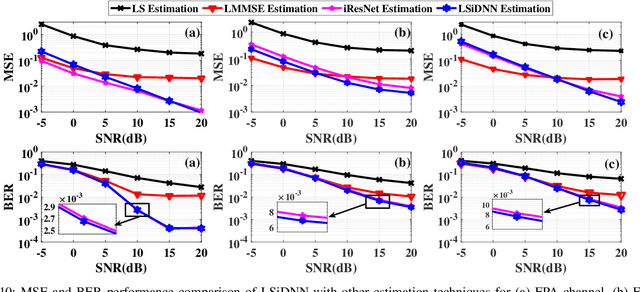
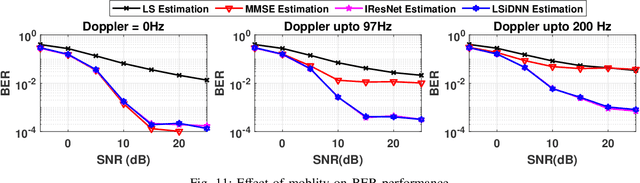
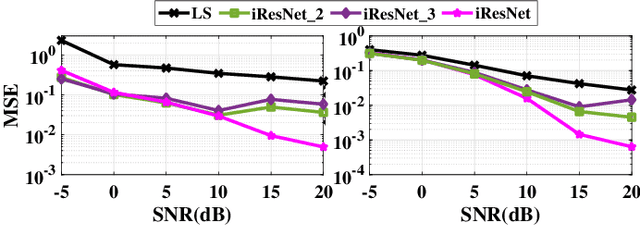
Channel estimation (CE) is one of the critical signal-processing tasks of the wireless physical layer (PHY). Recent deep learning (DL) based CE have outperformed statistical approaches such as least-square-based CE (LS) and linear minimum mean square error-based CE (LMMSE). However, existing CE approaches have not yet been realized on system-on-chip (SoC). The first contribution of this paper is to efficiently implement the existing state-of-the-art CE algorithms on Zynq SoC (ZSoC), comprising of ARM processor and field programmable gate array (FPGA), via hardware-software co-design and fixed point analysis. We validate the superiority of DL-based CE and LMMSE over LS for various signal-to-noise ratios (SNR) and wireless channels in terms of mean square error (MSE) and bit error rate (BER). We also highlight the high complexity, execution time, and power consumption of DL-based CE and LMMSE approaches. To address this, we propose a novel compute-efficient LS-augmented interpolated deep neural network (LSiDNN) based CE algorithm and realize it on ZSoC. The proposed LSiDNN offers 88-90% lower execution time and 38-85% lower resource utilization than state-of-the-art DL-based CE for identical MSE and BER. LSiDNN offers significantly lower MSE and BER than LMMSE, and the gain improves with increased mobility between transceivers. It offers 75% lower execution time and 90-94% lower resource utilization than LMMSE.
SynArtifact: Classifying and Alleviating Artifacts in Synthetic Images via Vision-Language Model
Mar 05, 2024In the rapidly evolving area of image synthesis, a serious challenge is the presence of complex artifacts that compromise perceptual realism of synthetic images. To alleviate artifacts and improve quality of synthetic images, we fine-tune Vision-Language Model (VLM) as artifact classifier to automatically identify and classify a wide range of artifacts and provide supervision for further optimizing generative models. Specifically, we develop a comprehensive artifact taxonomy and construct a dataset of synthetic images with artifact annotations for fine-tuning VLM, named SynArtifact-1K. The fine-tuned VLM exhibits superior ability of identifying artifacts and outperforms the baseline by 25.66%. To our knowledge, this is the first time such end-to-end artifact classification task and solution have been proposed. Finally, we leverage the output of VLM as feedback to refine the generative model for alleviating artifacts. Visualization results and user study demonstrate that the quality of images synthesized by the refined diffusion model has been obviously improved.
Shapley Values-Powered Framework for Fair Reward Split in Content Produced by GenAI
Mar 05, 2024



It is evident that, currently, generative models are surpassed in quality by human professionals. However, with the advancements in Artificial Intelligence, this gap will narrow, leading to scenarios where individuals who have dedicated years of their lives to mastering a skill become obsolete due to their high costs, which are inherently linked to the time they require to complete a task -- a task that AI could accomplish in minutes or seconds. To avoid future social upheavals, we must, even now, contemplate how to fairly assess the contributions of such individuals in training generative models and how to compensate them for the reduction or complete loss of their incomes. In this work, we propose a method to structure collaboration between model developers and data providers. To achieve this, we employ Shapley Values to quantify the contribution of artist(s) in an image generated by the Stable Diffusion-v1.5 model and to equitably allocate the reward among them.
Enhancing Weakly Supervised 3D Medical Image Segmentation through Probabilistic-aware Learning
Mar 05, 2024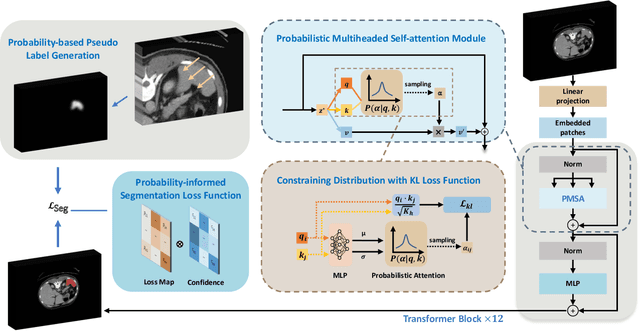
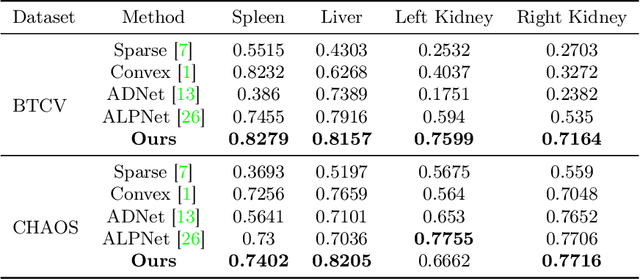
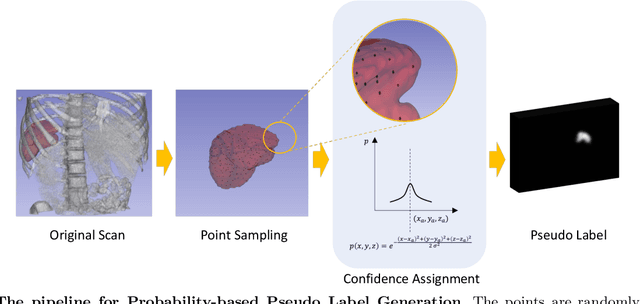
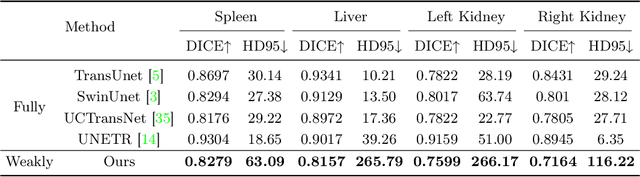
3D medical image segmentation is a challenging task with crucial implications for disease diagnosis and treatment planning. Recent advances in deep learning have significantly enhanced fully supervised medical image segmentation. However, this approach heavily relies on labor-intensive and time-consuming fully annotated ground-truth labels, particularly for 3D volumes. To overcome this limitation, we propose a novel probabilistic-aware weakly supervised learning pipeline, specifically designed for 3D medical imaging. Our pipeline integrates three innovative components: a probability-based pseudo-label generation technique for synthesizing dense segmentation masks from sparse annotations, a Probabilistic Multi-head Self-Attention network for robust feature extraction within our Probabilistic Transformer Network, and a Probability-informed Segmentation Loss Function to enhance training with annotation confidence. Demonstrating significant advances, our approach not only rivals the performance of fully supervised methods but also surpasses existing weakly supervised methods in CT and MRI datasets, achieving up to 18.1% improvement in Dice scores for certain organs. The code is available at https://github.com/runminjiang/PW4MedSeg.
Learning to Defer to a Population: A Meta-Learning Approach
Mar 05, 2024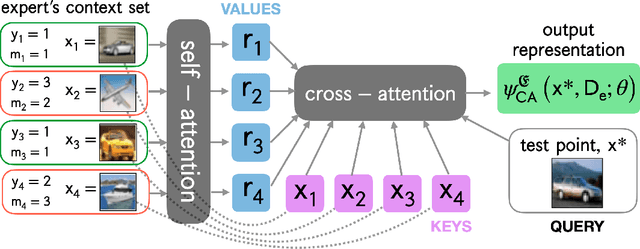



The learning to defer (L2D) framework allows autonomous systems to be safe and robust by allocating difficult decisions to a human expert. All existing work on L2D assumes that each expert is well-identified, and if any expert were to change, the system should be re-trained. In this work, we alleviate this constraint, formulating an L2D system that can cope with never-before-seen experts at test-time. We accomplish this by using meta-learning, considering both optimization- and model-based variants. Given a small context set to characterize the currently available expert, our framework can quickly adapt its deferral policy. For the model-based approach, we employ an attention mechanism that is able to look for points in the context set that are similar to a given test point, leading to an even more precise assessment of the expert's abilities. In the experiments, we validate our methods on image recognition, traffic sign detection, and skin lesion diagnosis benchmarks.
TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
Mar 05, 2024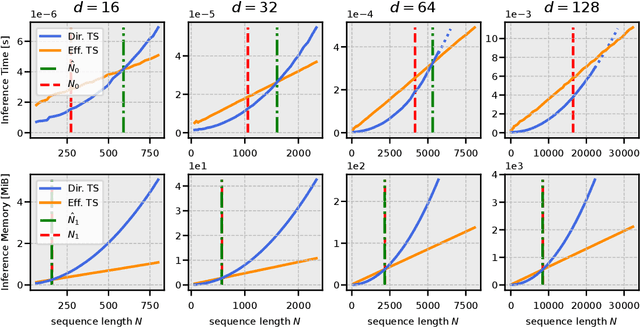
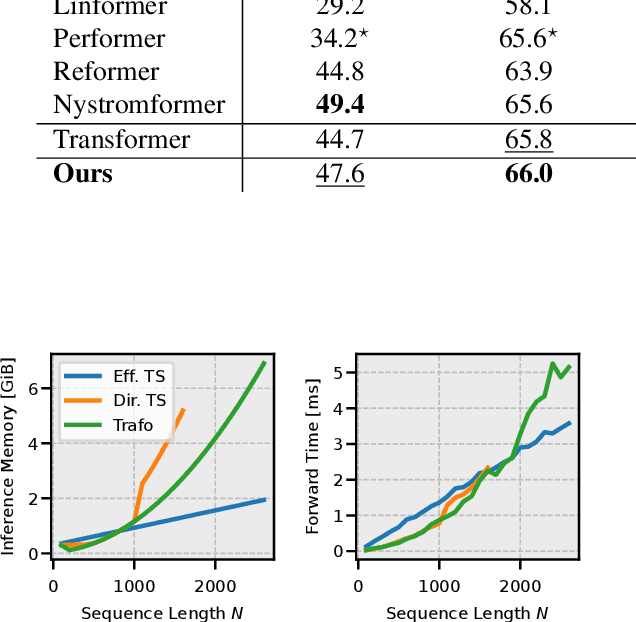
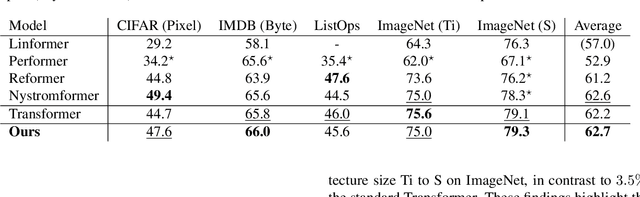
The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or stateful recurrence, sacrifice token-to-token interactions, which ultimately leads to compromises in performance. This paper introduces TaylorShift, a novel reformulation of the Taylor softmax that enables computing full token-to-token interactions in linear time and space. We analytically determine the crossover points where employing TaylorShift becomes more efficient than traditional attention, aligning closely with empirical measurements. Specifically, our findings demonstrate that TaylorShift enhances memory efficiency for sequences as short as 800 tokens and accelerates inference for inputs of approximately 1700 tokens and beyond. For shorter sequences, TaylorShift scales comparably with the vanilla attention. Furthermore, a classification benchmark across five tasks involving long sequences reveals no degradation in accuracy when employing Transformers equipped with TaylorShift. For reproducibility, we provide access to our code under https://github.com/tobna/TaylorShift.