 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Geometric Active Learning for Segmentation of Large 3D Volumes
Oct 13, 2022
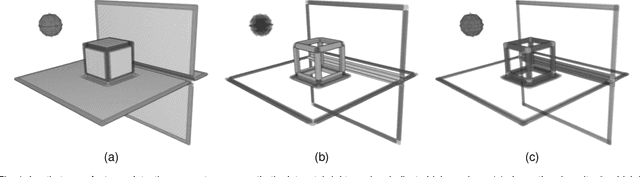
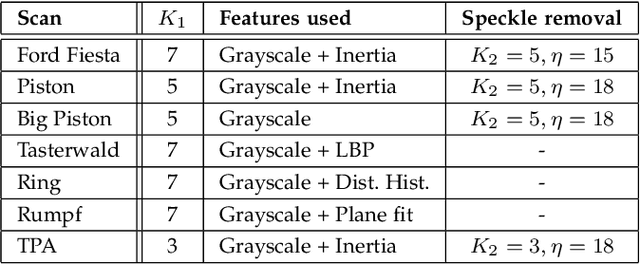
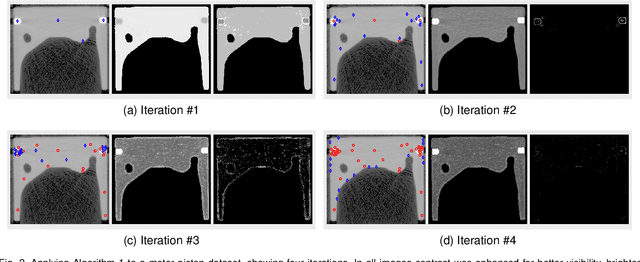
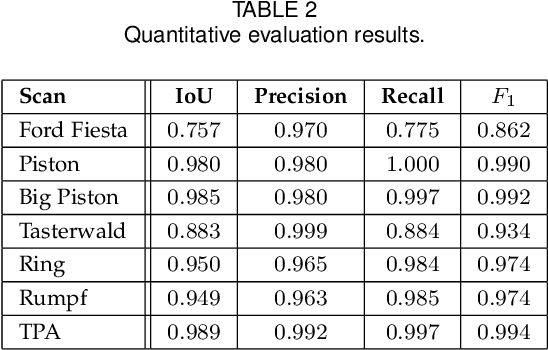
Segmentation, i.e., the partitioning of volumetric data into components, is a crucial task in many image processing applications ever since such data could be generated. Most existing applications nowadays, specifically CNNs, make use of voxelwise classification systems which need to be trained on a large number of annotated training volumes. However, in many practical applications such data sets are seldom available and the generation of annotations is time-consuming and cumbersome. In this paper, we introduce a novel voxelwise segmentation method based on active learning on geometric features. Our method uses interactively provided seed points to train a voxelwise classifier based entirely on local information. The combination of an ad hoc incorporation of domain knowledge and local processing results in a flexible yet efficient segmentation method that is applicable to three-dimensional volumes without size restrictions. We illustrate the potential and flexibility of our approach by applying it to selected computed tomography scans where we perform different segmentation tasks to scans from different domains and of different sizes.
Ensemble Creation via Anchored Regularization for Unsupervised Aspect Extraction
Oct 13, 2022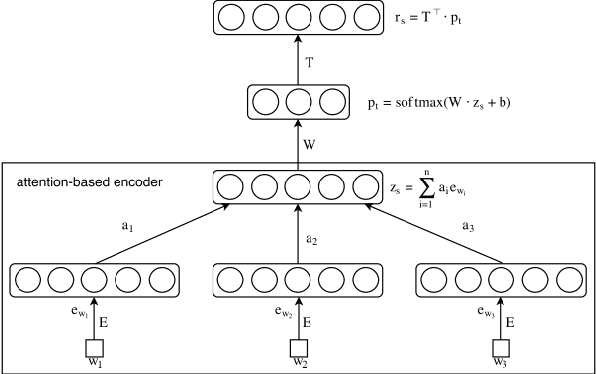
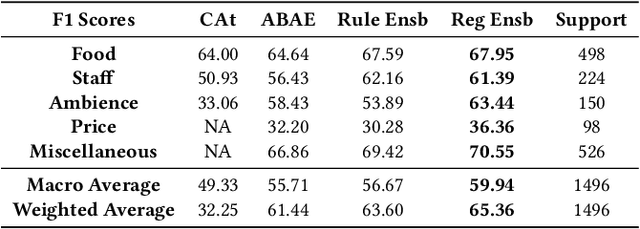
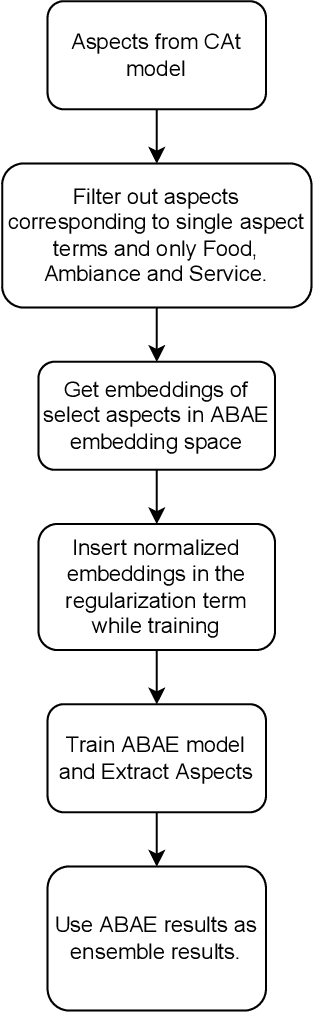
Aspect Based Sentiment Analysis is the most granular form of sentiment analysis that can be performed on the documents / sentences. Besides delivering the most insights at a finer grain, it also poses equally daunting challenges. One of them being the shortage of labelled data. To bring in value right out of the box for the text data being generated at a very fast pace in today's world, unsupervised aspect-based sentiment analysis allows us to generate insights without investing time or money in generating labels. From topic modelling approaches to recent deep learning-based aspect extraction models, this domain has seen a lot of development. One of the models that we improve upon is ABAE that reconstructs the sentences as a linear combination of aspect terms present in it, In this research we explore how we can use information from another unsupervised model to regularize ABAE, leading to better performance. We contrast it with baseline rule based ensemble and show that the ensemble methods work better than the individual models and the regularization based ensemble performs better than the rule-based one.
Fast Hierarchical Learning for Few-Shot Object Detection
Oct 10, 2022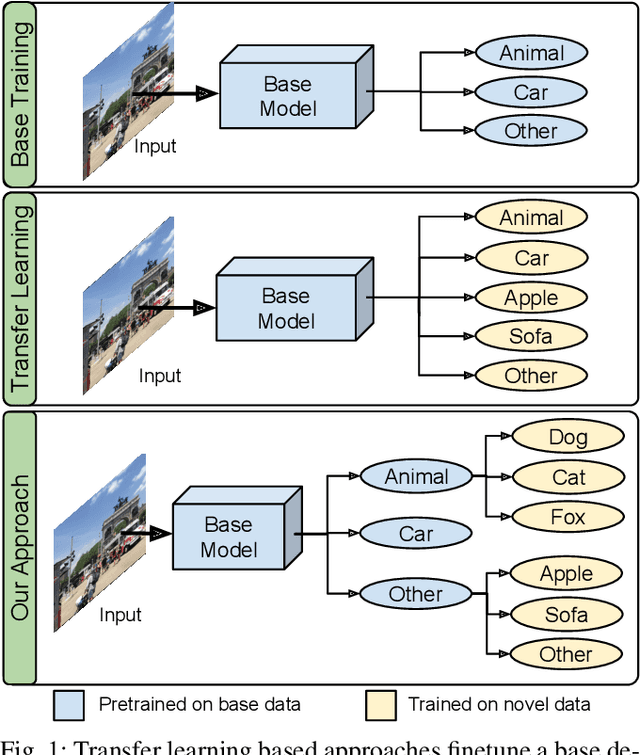
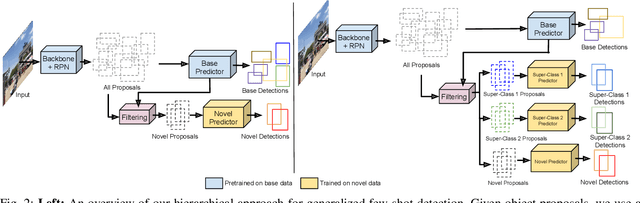
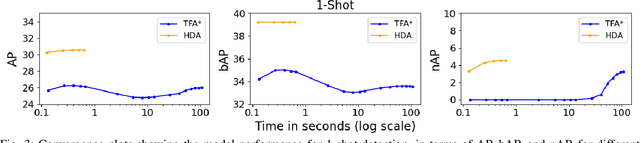

Transfer learning based approaches have recently achieved promising results on the few-shot detection task. These approaches however suffer from ``catastrophic forgetting'' issue due to finetuning of base detector, leading to sub-optimal performance on the base classes. Furthermore, the slow convergence rate of stochastic gradient descent (SGD) results in high latency and consequently restricts real-time applications. We tackle the aforementioned issues in this work. We pose few-shot detection as a hierarchical learning problem, where the novel classes are treated as the child classes of existing base classes and the background class. The detection heads for the novel classes are then trained using a specialized optimization strategy, leading to significantly lower training times compared to SGD. Our approach obtains competitive novel class performance on few-shot MS-COCO benchmark, while completely retaining the performance of the initial model on the base classes. We further demonstrate the application of our approach to a new class-refined few-shot detection task.
Leap-frog neural network for learning the symplectic evolution from partitioned data
Aug 30, 2022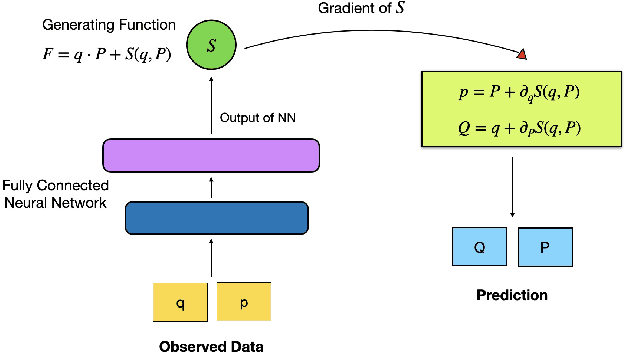

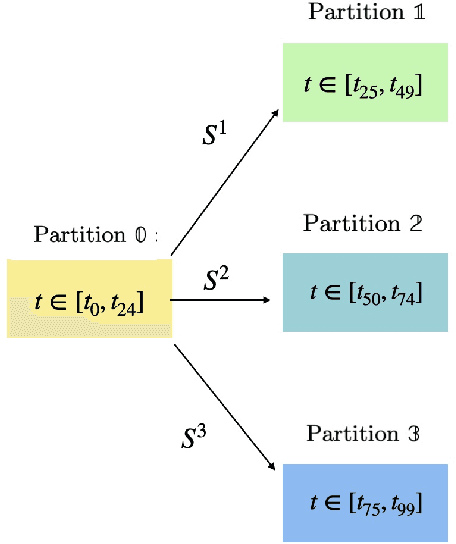
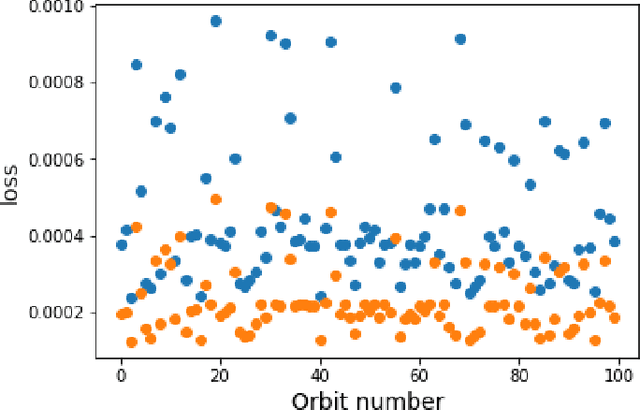
For the Hamiltonian system, this work considers the learning and prediction of the position (q) and momentum (p) variables generated by a symplectic evolution map. Similar to Chen & Tao (2021), the symplectic map is represented by the generating function. In addition, we develop a new learning scheme by splitting the time series (q_i, p_i) into several partitions, and then train a leap-frog neural network (LFNN) to approximate the generating function between the first (i.e. initial condition) and one of the rest partitions. For predicting the system evolution in a short timescale, the LFNN could effectively avoid the issue of accumulative error. Then the LFNN is applied to learn the behavior of the 2:3 resonant Kuiper belt objects, in a much longer time period, and there are two significant improvements on the neural network constructed in our previous work (Li et al. 2022): (1) conservation of the Jacobi integral ; (2) highly accurate prediction of the orbital evolution. We propose that the LFNN may be useful to make the prediction of the long time evolution of the Hamiltonian system.
GAPX: Generalized Autoregressive Paraphrase-Identification X
Oct 05, 2022
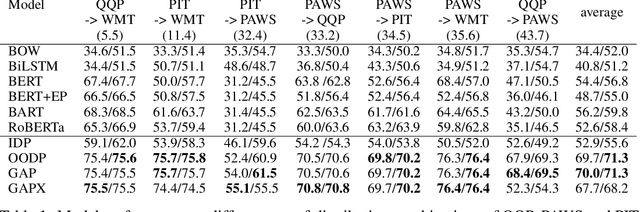
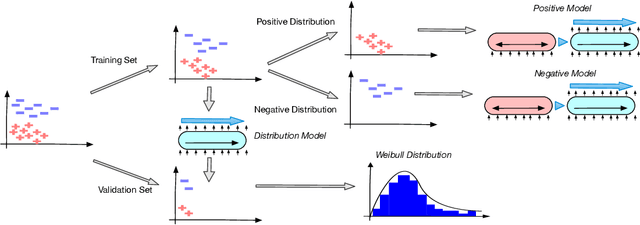
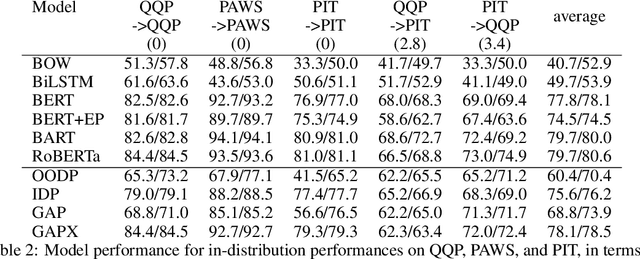
Paraphrase Identification is a fundamental task in Natural Language Processing. While much progress has been made in the field, the performance of many state-of-the-art models often suffer from distribution shift during inference time. We verify that a major source of this performance drop comes from biases introduced by negative examples. To overcome these biases, we propose in this paper to train two separate models, one that only utilizes the positive pairs and the other the negative pairs. This enables us the option of deciding how much to utilize the negative model, for which we introduce a perplexity based out-of-distribution metric that we show can effectively and automatically determine how much weight it should be given during inference. We support our findings with strong empirical results.
Exploration with Global Consistency Using Real-Time Re-integration and Active Loop Closure
Apr 06, 2022
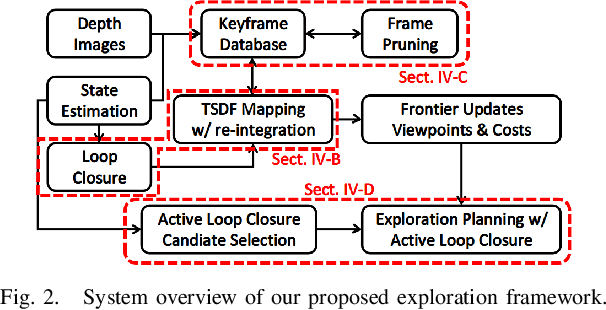
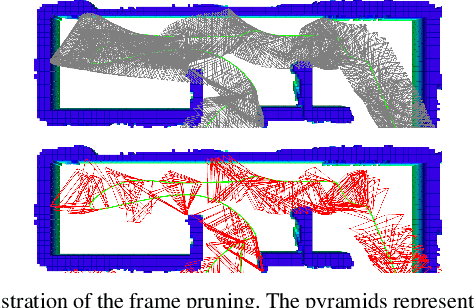

Despite recent progress of robotic exploration, most methods assume that drift-free localization is available, which is problematic in reality and causes severe distortion of the reconstructed map. In this work, we present a systematic exploration mapping and planning framework that deals with drifted localization, allowing efficient and globally consistent reconstruction. A real-time re-integration-based mapping approach along with a frame pruning mechanism is proposed, which rectifies map distortion effectively when drifted localization is corrected upon detecting loop-closure. Besides, an exploration planning method considering historical viewpoints is presented to enable active loop closing, which promotes a higher opportunity to correct localization errors and further improves the mapping quality. We evaluate both the mapping and planning methods as well as the entire system comprehensively in simulation and real-world experiments, showing their effectiveness in practice. The implementation of the proposed method will be made open-source for the benefit of the robotics community.
Efficiently Reconfiguring a Connected Swarm of Labeled Robots
Sep 22, 2022

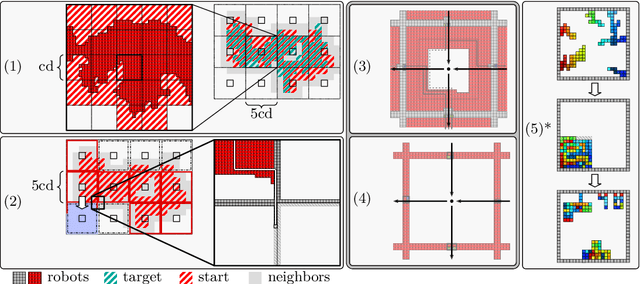
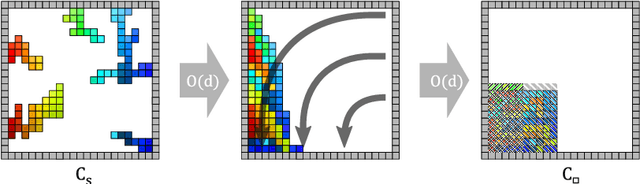
When considering motion planning for a swarm of $n$ labeled robots, we need to rearrange a given start configuration into a desired target configuration via a sequence of parallel, continuous, collision-free robot motions. The objective is to reach the new configuration in a minimum amount of time; an important constraint is to keep the swarm connected at all times. Problems of this type have been considered before, with recent notable results achieving constant stretch for not necessarily connected reconfiguration: If mapping the start configuration to the target configuration requires a maximum Manhattan distance of $d$, the total duration of an overall schedule can be bounded to $\mathcal{O}(d)$, which is optimal up to constant factors. However, constant stretch could only be achieved if disconnected reconfiguration is allowed, or for scaled configurations (which arise by increasing all dimensions of a given object by the same multiplicative factor) of unlabeled robots. We resolve these major open problems by (1) establishing a lower bound of $\Omega(\sqrt{n})$ for connected, labeled reconfiguration and, most importantly, by (2) proving that for scaled arrangements, constant stretch for connected reconfiguration can be achieved. In addition, we show that (3) it is NP-hard to decide whether a makespan of 2 can be achieved, while it is possible to check in polynomial time whether a makespan of 1 can be achieved.
Leaping Through Time with Gradient-based Adaptation for Recommendation
Dec 11, 2021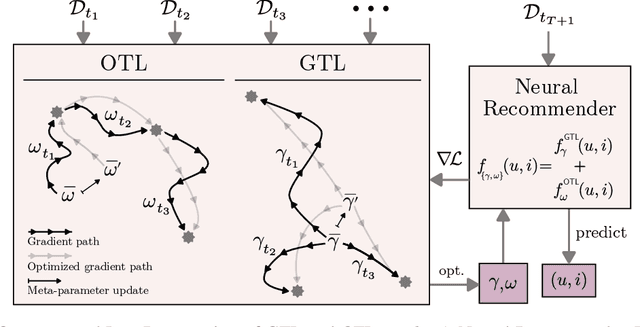
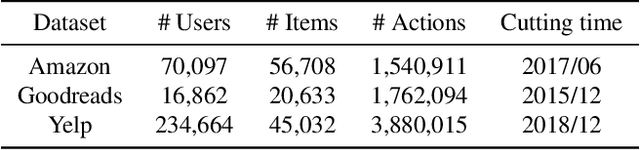
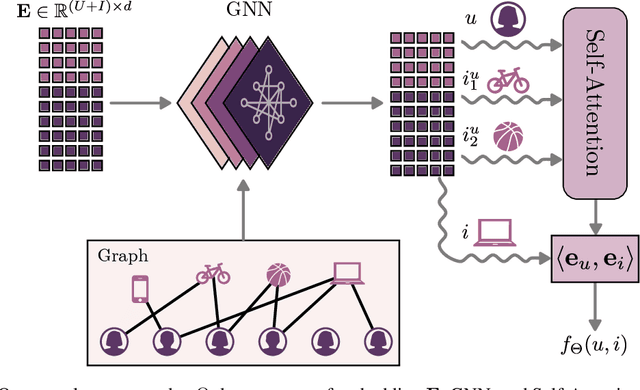
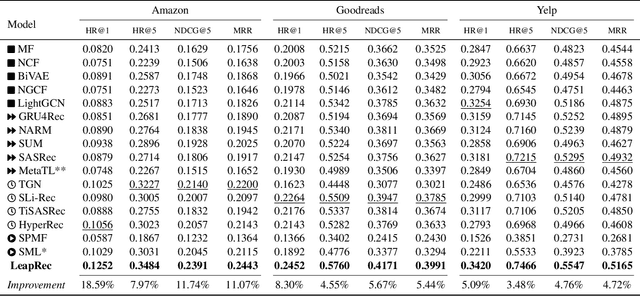
Modern recommender systems are required to adapt to the change in user preferences and item popularity. Such a problem is known as the temporal dynamics problem, and it is one of the main challenges in recommender system modeling. Different from the popular recurrent modeling approach, we propose a new solution named LeapRec to the temporal dynamic problem by using trajectory-based meta-learning to model time dependencies. LeapRec characterizes temporal dynamics by two complement components named global time leap (GTL) and ordered time leap (OTL). By design, GTL learns long-term patterns by finding the shortest learning path across unordered temporal data. Cooperatively, OTL learns short-term patterns by considering the sequential nature of the temporal data. Our experimental results show that LeapRec consistently outperforms the state-of-the-art methods on several datasets and recommendation metrics. Furthermore, we provide an empirical study of the interaction between GTL and OTL, showing the effects of long- and short-term modeling.
Online Convex Optimization with Unbounded Memory
Oct 18, 2022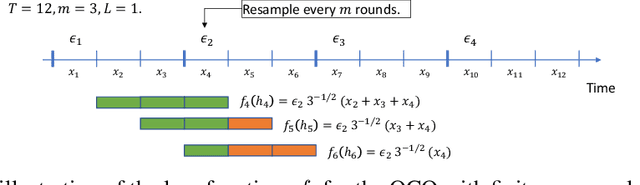
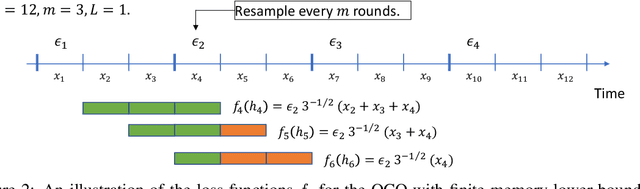
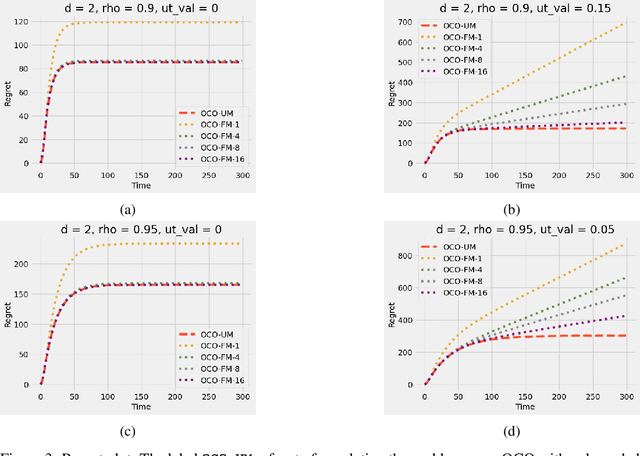
Online convex optimization (OCO) is a widely used framework in online learning. In each round, the learner chooses a decision in some convex set and an adversary chooses a convex loss function, and then the learner suffers the loss associated with their chosen decision. However, in many of the motivating applications the loss of the learner depends not only on the current decision but on the entire history of decisions until that point. The OCO framework and existing generalizations thereof fail to capture this. In this work we introduce a generalization of the OCO framework, ``Online Convex Optimization with Unbounded Memory'', that captures long-term dependence on past decisions. We introduce the notion of $p$-effective memory capacity, $H_p$, that quantifies the maximum influence of past decisions on current losses. We prove a $O(\sqrt{H_1 T})$ policy regret bound and a stronger $O(\sqrt{H_p T})$ policy regret bound under mild additional assumptions. These bounds are optimal in terms of their dependence on the time horizon $T$. We show the broad applicability of our framework by using it to derive regret bounds, and to simplify existing regret bound derivations, for a variety of online learning problems including an online variant of performative prediction and online linear control.
Not All Poisons are Created Equal: Robust Training against Data Poisoning
Oct 18, 2022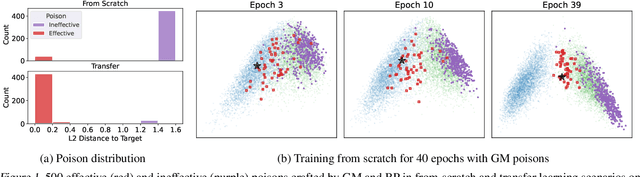
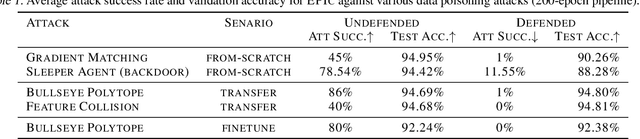
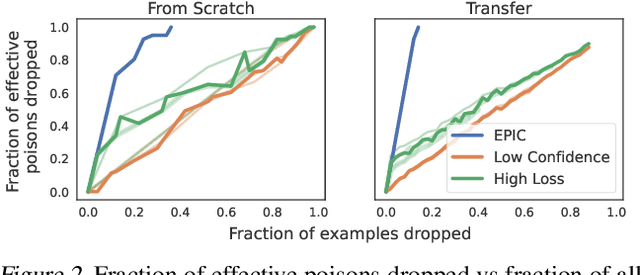

Data poisoning causes misclassification of test time target examples by injecting maliciously crafted samples in the training data. Existing defenses are often effective only against a specific type of targeted attack, significantly degrade the generalization performance, or are prohibitive for standard deep learning pipelines. In this work, we propose an efficient defense mechanism that significantly reduces the success rate of various data poisoning attacks, and provides theoretical guarantees for the performance of the model. Targeted attacks work by adding bounded perturbations to a randomly selected subset of training data to match the targets' gradient or representation. We show that: (i) under bounded perturbations, only a number of poisons can be optimized to have a gradient that is close enough to that of the target and make the attack successful; (ii) such effective poisons move away from their original class and get isolated in the gradient space; (iii) dropping examples in low-density gradient regions during training can successfully eliminate the effective poisons, and guarantees similar training dynamics to that of training on full data. Our extensive experiments show that our method significantly decreases the success rate of state-of-the-art targeted attacks, including Gradient Matching and Bullseye Polytope, and easily scales to large datasets.