 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PhotoFourier: A Photonic Joint Transform Correlator-Based Neural Network Accelerator
Nov 10, 2022

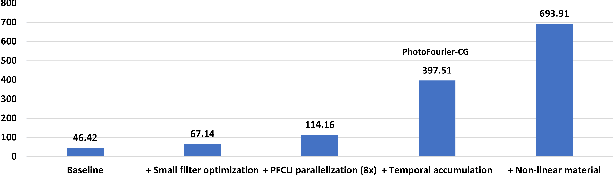
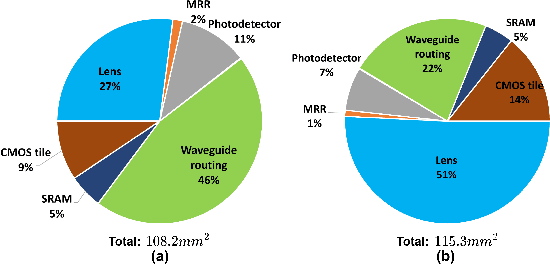
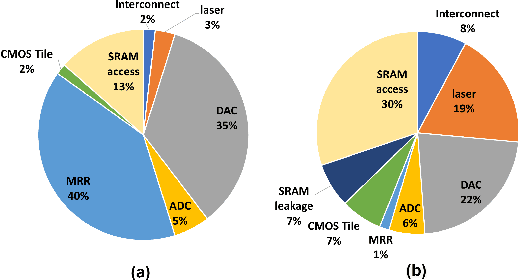
The last few years have seen a lot of work to address the challenge of low-latency and high-throughput convolutional neural network inference. Integrated photonics has the potential to dramatically accelerate neural networks because of its low-latency nature. Combined with the concept of Joint Transform Correlator (JTC), the computationally expensive convolution functions can be computed instantaneously (time of flight of light) with almost no cost. This 'free' convolution computation provides the theoretical basis of the proposed PhotoFourier JTC-based CNN accelerator. PhotoFourier addresses a myriad of challenges posed by on-chip photonic computing in the Fourier domain including 1D lenses and high-cost optoelectronic conversions. The proposed PhotoFourier accelerator achieves more than 28X better energy-delay product compared to state-of-art photonic neural network accelerators.
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Oct 05, 2022
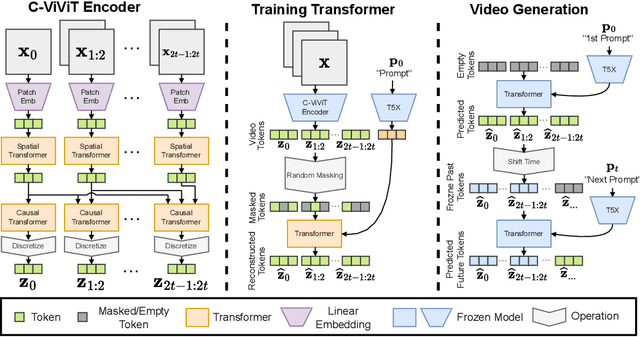


We present Phenaki, a model capable of realistic video synthesis, given a sequence of textual prompts. Generating videos from text is particularly challenging due to the computational cost, limited quantities of high quality text-video data and variable length of videos. To address these issues, we introduce a new model for learning video representation which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text we are using a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, we demonstrate how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to the previous video generation methods, Phenaki can generate arbitrary long videos conditioned on a sequence of prompts (i.e. time variable text or a story) in open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time variable prompts. In addition, compared to the per-frame baselines, the proposed video encoder-decoder computes fewer tokens per video but results in better spatio-temporal consistency.
Demo: LE3D: A Privacy-preserving Lightweight Data Drift Detection Framework
Nov 03, 2022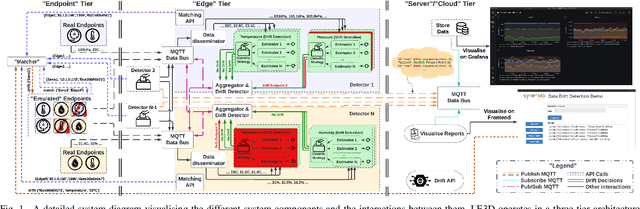
This paper presents LE3D; a novel data drift detection framework for preserving data integrity and confidentiality. LE3D is a generalisable platform for evaluating novel drift detection mechanisms within the Internet of Things (IoT) sensor deployments. Our framework operates in a distributed manner, preserving data privacy while still being adaptable to new sensors with minimal online reconfiguration. Our framework currently supports multiple drift estimators for time-series IoT data and can easily be extended to accommodate new data types and drift detection mechanisms. This demo will illustrate the functionality of LE3D under a real-world-like scenario.
Anytime-valid off-policy inference for contextual bandits
Oct 19, 2022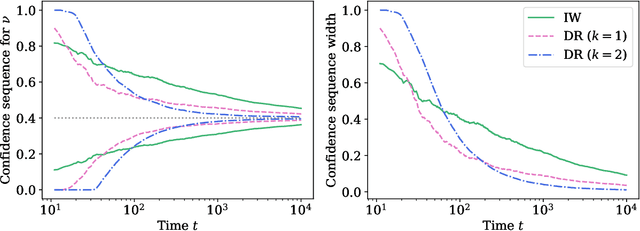

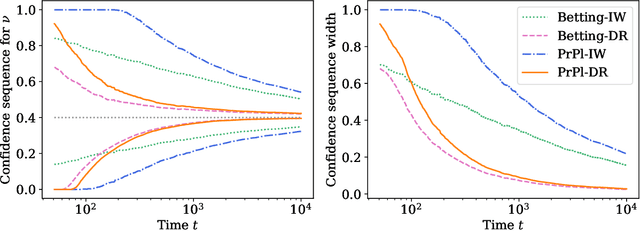

Contextual bandits are a modern staple tool for active sequential experimentation in the tech industry. They involve online learning algorithms that adaptively (over time) learn policies to map observed contexts $X_t$ to actions $A_t$ in an attempt to maximize stochastic rewards $R_t$. This adaptivity raises interesting but hard statistical inference questions, especially counterfactual ones: for example, it is often of interest to estimate the properties of a hypothetical policy that is different from the logging policy that was used to collect the data -- a problem known as "off-policy evaluation" (OPE). Using modern martingale techniques, we present a comprehensive framework for OPE inference that relax many unnecessary assumptions made in past work, significantly improving on them theoretically and empirically. Our methods remain valid in very general settings, and can be employed while the original experiment is still running (that is, not necessarily post-hoc), when the logging policy may be itself changing (due to learning), and even if the context distributions are drifting over time. More concretely, we derive confidence sequences for various functionals of interest in OPE. These include doubly robust ones for time-varying off-policy mean reward values, but also confidence bands for the entire CDF of the off-policy reward distribution. All of our methods (a) are valid at arbitrary stopping times (b) only make nonparametric assumptions, and (c) do not require known bounds on the maximal importance weights, and (d) adapt to the empirical variance of the reward and weight distributions. In summary, our methods enable anytime-valid off-policy inference using adaptively collected contextual bandit data.
Fully Digital Second-order Level-crossing Sampling ADC for Data Saving in Sensing Sparse Signals
Nov 17, 2022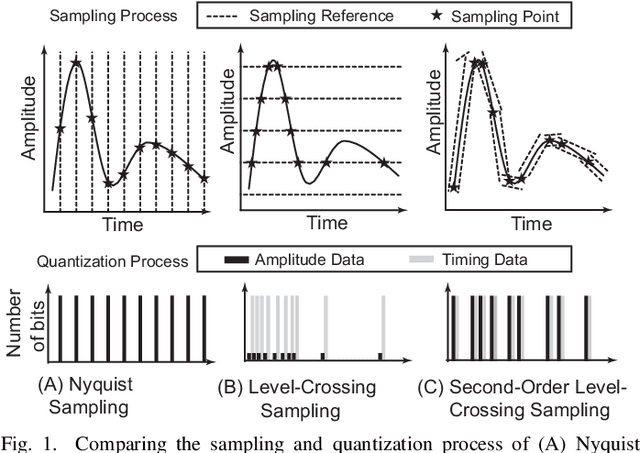
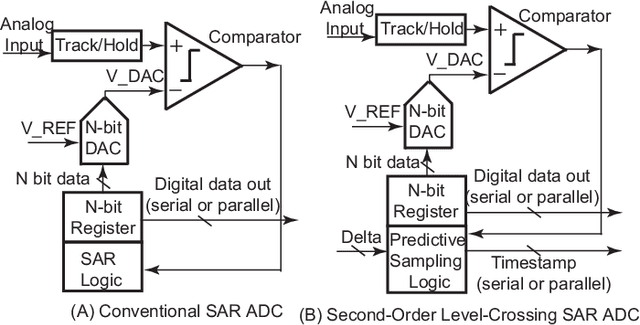
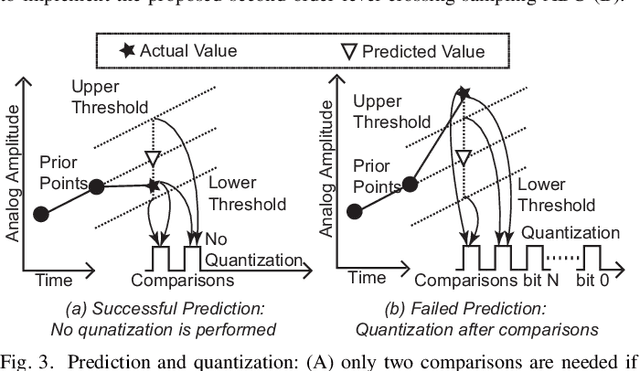
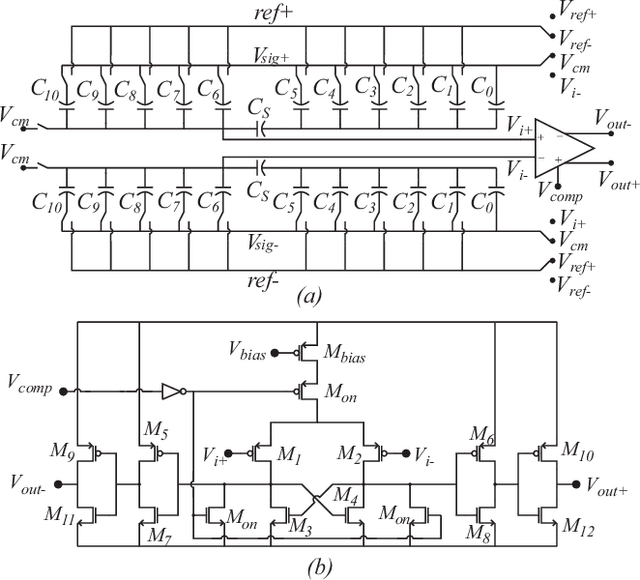
This paper presents a fully integrated second-order level-crossing sampling data converter for real-time data compression and feature extraction. Compared with level-sampling ADCs which sample at fixed voltage levels, the proposed circuits updates tracking thresholds using linear extrapolation, which forms a second-order level-crossing sampling ADC that has sloped sampling levels. The computing is done digitally and is implemented by modifying the digital control logic of a conventional SAR ADC. The system selects only the turning points in the input waveform for quantization. The output of the proposed data converter consists of both the digital value of the selected sampling points and the timestamp between the selected sampling points. The main advantages are data savings and power savings for the data converter and the following digital signal processing or communication circuits, which are ideal for low-power sensors. The test chip was fabricated using a 180nm CMOS process. The proposed ADC saves 30% compared to a conventional SAR ADC and achieves a compression factor of 6.17 for tracking ECG signals.
Pitfalls of Climate Network Construction: A Statistical Perspective
Nov 17, 2022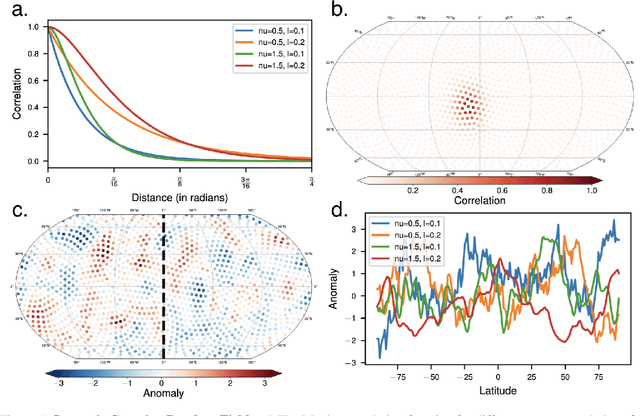
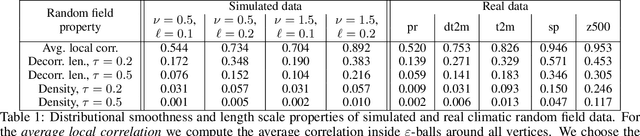
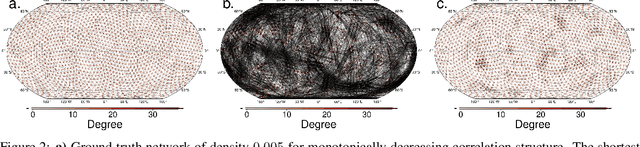
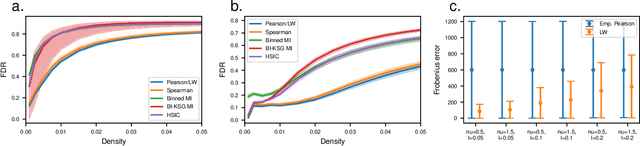
Network-based analyses of dynamical systems have become increasingly popular in climate science. Here we address network construction from a statistical perspective and highlight the often ignored fact that the calculated correlation values are only empirical estimates. To measure spurious behaviour as deviation from a ground truth network, we simulate time-dependent isotropic random fields on the sphere and apply common network construction techniques. We find several ways in which the uncertainty stemming from the estimation procedure has major impact on network characteristics. When the data has locally coherent correlation structure, spurious link bundle teleconnections and spurious high-degree clusters have to be expected. Anisotropic estimation variance can also induce severe biases into empirical networks. We validate our findings with ERA5 reanalysis data. Moreover we explain why commonly applied resampling procedures are inappropriate for significance evaluation and propose a statistically more meaningful ensemble construction framework. By communicating which difficulties arise in estimation from scarce data and by presenting which design decisions increase robustness, we hope to contribute to more reliable climate network construction in the future.
DSLOB: A Synthetic Limit Order Book Dataset for Benchmarking Forecasting Algorithms under Distributional Shift
Nov 17, 2022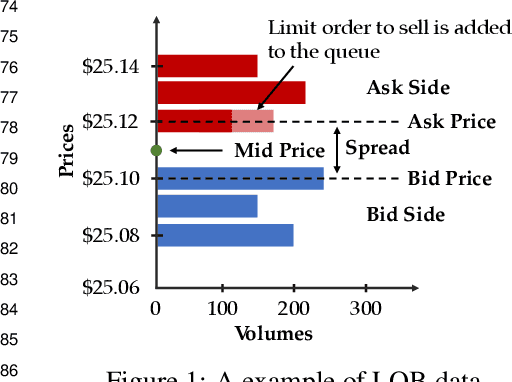

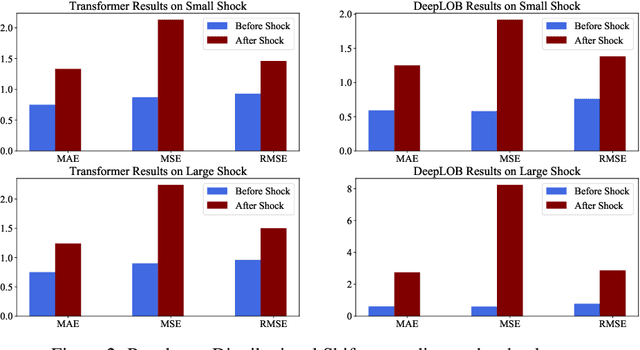
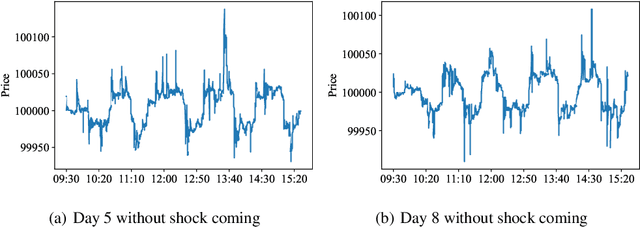
In electronic trading markets, limit order books (LOBs) provide information about pending buy/sell orders at various price levels for a given security. Recently, there has been a growing interest in using LOB data for resolving downstream machine learning tasks (e.g., forecasting). However, dealing with out-of-distribution (OOD) LOB data is challenging since distributional shifts are unlabeled in current publicly available LOB datasets. Therefore, it is critical to build a synthetic LOB dataset with labeled OOD samples serving as a testbed for developing models that generalize well to unseen scenarios. In this work, we utilize a multi-agent market simulator to build a synthetic LOB dataset, named DSLOB, with and without market stress scenarios, which allows for the design of controlled distributional shift benchmarking. Using the proposed synthetic dataset, we provide a holistic analysis on the forecasting performance of three different state-of-the-art forecasting methods. Our results reflect the need for increased researcher efforts to develop algorithms with robustness to distributional shifts in high-frequency time series data.
iNavFIter-M: Matrix Formulation of Functional Iteration for Inertial Navigation Computation
Nov 17, 2022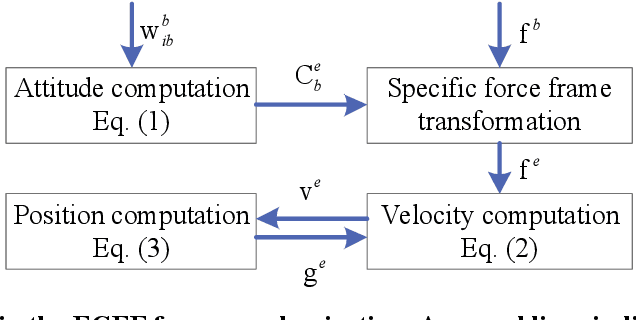

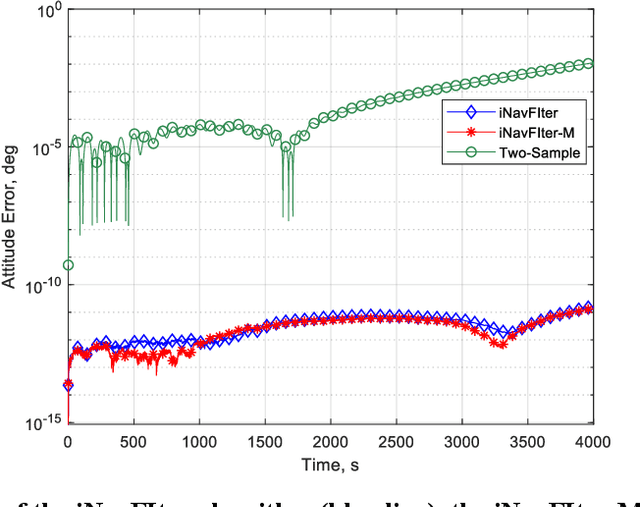
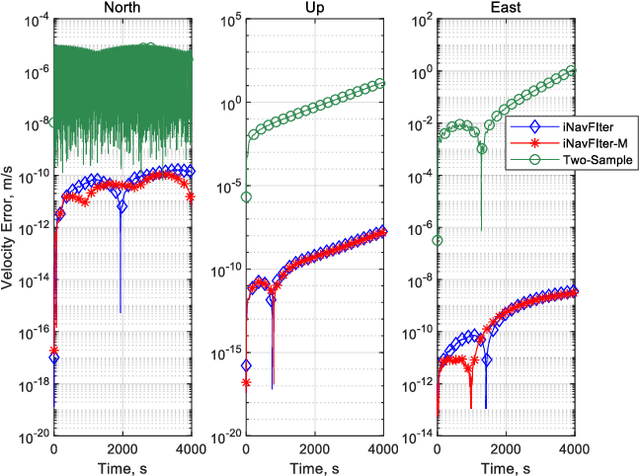
The acquisition of attitude, velocity, and position is an essential task in the field of inertial navigation, achieved by integrating the measurements from inertial sensors. Recently, the ultra-precision inertial navigation computation has been tackled by the functional iteration approach (iNavFIter) that drives the non-commutativity errors almost to the computer truncation error level. This paper proposes a computationally efficient matrix formulation of the functional iteration approach, named the iNavFIter-M. The Chebyshev polynomial coefficients in two consecutive iterations are explicitly connected through the matrix formulation, in contrast to the implicit iterative relationship in the original iNavFIter. By so doing, it allows a straightforward algorithmic implementation and a number of matrix factors can be pre-calculated for more efficient computation. Numerical results demonstrate that the proposed iNavFIter-M algorithm is able to achieve the same high computation accuracy as the original iNavFIter does, at the computational cost comparable to the typical two-sample algorithm. The iNavFIter-M algorithm is also implemented on a FPGA board to demonstrate its potential in real time applications.
SparseVLR: A Novel Framework for Verified Locally Robust Sparse Neural Networks Search
Nov 17, 2022
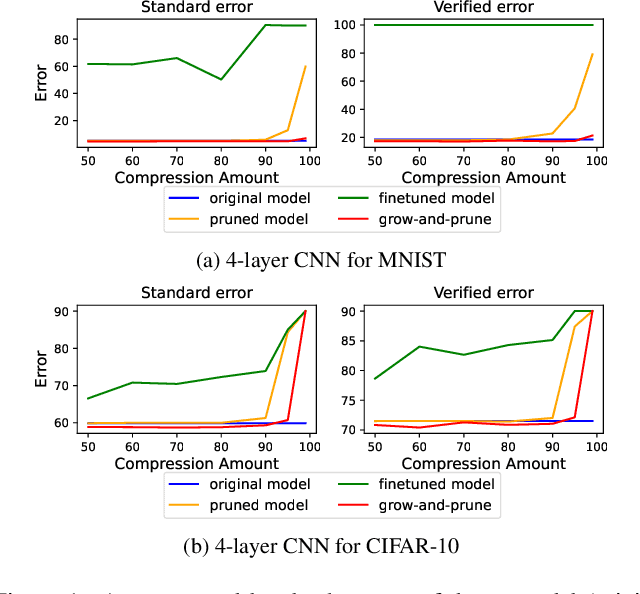
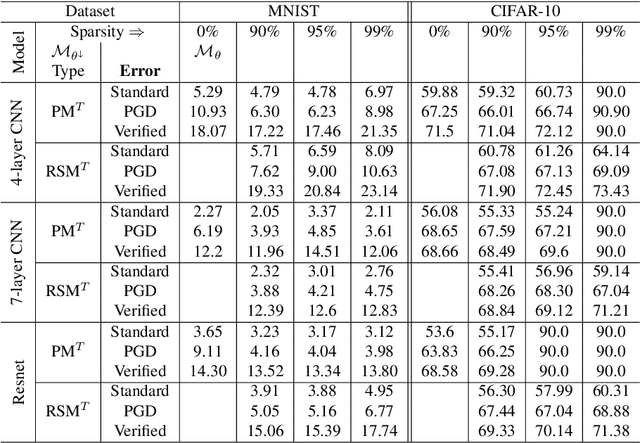
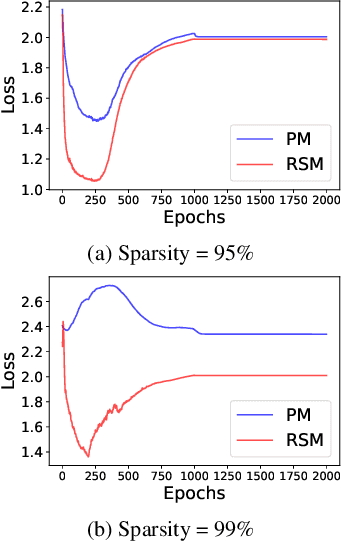
The compute-intensive nature of neural networks (NNs) limits their deployment in resource-constrained environments such as cell phones, drones, autonomous robots, etc. Hence, developing robust sparse models fit for safety-critical applications has been an issue of longstanding interest. Though adversarial training with model sparsification has been combined to attain the goal, conventional adversarial training approaches provide no formal guarantee that the models would be robust against any rogue samples in a restricted space around a benign sample. Recently proposed verified local robustness techniques provide such a guarantee. This is the first paper that combines the ideas from verified local robustness and dynamic sparse training to develop `SparseVLR'-- a novel framework to search verified locally robust sparse networks. Obtained sparse models exhibit accuracy and robustness comparable to their dense counterparts at sparsity as high as 99%. Furthermore, unlike most conventional sparsification techniques, SparseVLR does not require a pre-trained dense model, reducing the training time by 50%. We exhaustively investigated SparseVLR's efficacy and generalizability by evaluating various benchmark and application-specific datasets across several models.
Explainability Via Causal Self-Talk
Nov 17, 2022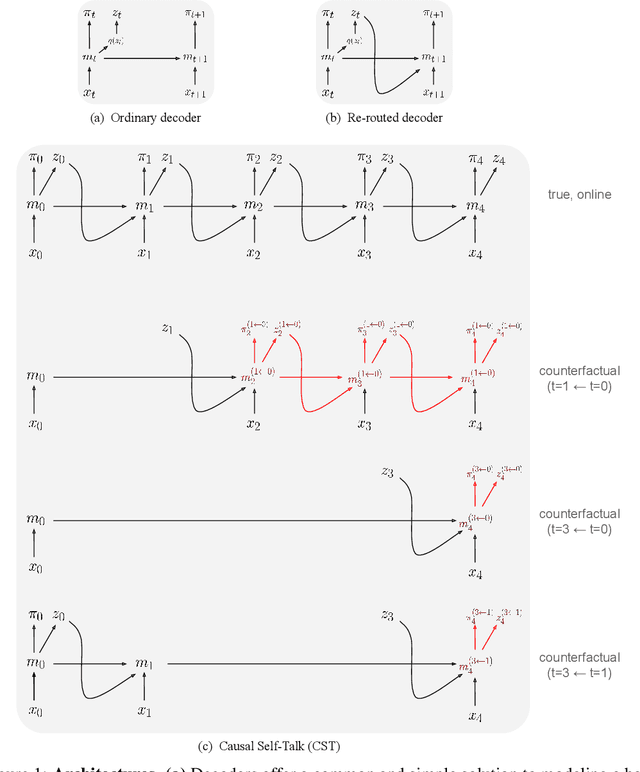
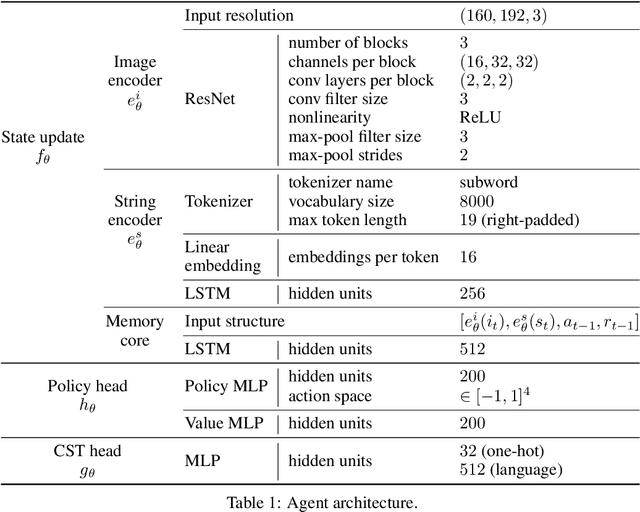
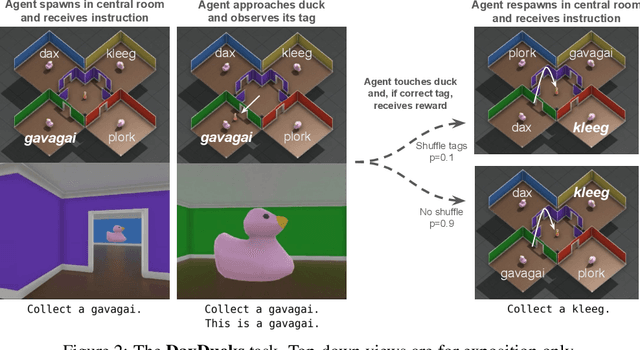
Explaining the behavior of AI systems is an important problem that, in practice, is generally avoided. While the XAI community has been developing an abundance of techniques, most incur a set of costs that the wider deep learning community has been unwilling to pay in most situations. We take a pragmatic view of the issue, and define a set of desiderata that capture both the ambitions of XAI and the practical constraints of deep learning. We describe an effective way to satisfy all the desiderata: train the AI system to build a causal model of itself. We develop an instance of this solution for Deep RL agents: Causal Self-Talk. CST operates by training the agent to communicate with itself across time. We implement this method in a simulated 3D environment, and show how it enables agents to generate faithful and semantically-meaningful explanations of their own behavior. Beyond explanations, we also demonstrate that these learned models provide new ways of building semantic control interfaces to AI systems.