 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Remote Photoplethysmography for Neonatal Pain Detection from Facial Videos
Apr 28, 2026Unaddressed pain in neonates can lead to adverse effects, including delayed development and slower weight gain, emphasising the need for more objective and reliable pain assessment methods. Hence, automated methods using behavioural and physiological pain indicators have been developed to aid healthcare professionals in the Neonatal ICU. Traditional contact-based methods for physiological parameter estimation are unsuitable for long-term monitoring and increase the risk of spreading diseases like COVID-19. We introduce a novel approach using remote photoplethysmography (rPPG) to estimate pulse signals in a non-contact manner and employ them for neonatal pain detection. The temporal signals acquired from regions-of-interest (ROIs) affected by skin deformations may exhibit lower quality and provide erroneous rPPG signals. Therefore, we incorporated a quality parameter to select the temporal signals obtained from ROIs that are least affected by skin deformations. Further, we employed signal-to-noise ratio as a fitness parameter to extract the rPPG signal corresponding to the clip that is least affected by noise. Experimental findings demonstrate that the rPPG signals provide useful information for neonatal pain detection, and signals extracted from the blue colour channel outperform those extracted from other colour channels. We also show that combining rPPG and audio features provides better results than individual modalities.
Efficient VQ-QAT and Mixed Vector/Linear quantized Neural Networks
Apr 25, 2026In this work, we developed and tested 3 techniques for vector quantization (VQ) based model weight compression. To mitigate codebook collapse and enable end-to-end training, we adopted cosine similarity-based assignment. Building on ideas from attention-based formulations in Differentiable K-Means (DKM), we further improved this approach by using cosine similarity for assignment combined with top-1 sampling and a straight-through estimator, thereby eliminating the need for weighted-average reconstruction. Finally, we investigated the use of differentiable neural architecture search (NAS) to adaptively select layer-wise quantization configurations, further optimizing the compression process. Although our method does not consistently outperform existing approaches across all quantization levels, it provides useful insights into the design trade-offs and behaviors of VQ-based model compression methods.
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Jul 19, 2024



Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($\sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
FRED: Flexible REduction-Distribution Interconnect and Communication Implementation for Wafer-Scale Distributed Training of DNN Models
Jun 28, 2024



Distributed Deep Neural Network (DNN) training is a technique to reduce the training overhead by distributing the training tasks into multiple accelerators, according to a parallelization strategy. However, high-performance compute and interconnects are needed for maximum speed-up and linear scaling of the system. Wafer-scale systems are a promising technology that allows for tightly integrating high-end accelerators with high-speed wafer-scale interconnects, making it an attractive platform for distributed training. However, the wafer-scale interconnect should offer high performance and flexibility for various parallelization strategies to enable maximum optimizations for compute and memory usage. In this paper, we propose FRED, a wafer-scale interconnect that is tailored for the high-BW requirements of wafer-scale networks and can efficiently execute communication patterns of different parallelization strategies. Furthermore, FRED supports in-switch collective communication execution that reduces the network traffic by approximately 2X. Our results show that FRED can improve the average end-to-end training time of ResNet-152, Transformer-17B, GPT-3, and Transformer-1T by 1.76X, 1.87X, 1.34X, and 1.4X, respectively when compared to a baseline waferscale 2D-Mesh fabric.
Cost-Driven Hardware-Software Co-Optimization of Machine Learning Pipelines
Oct 19, 2023



Researchers have long touted a vision of the future enabled by a proliferation of internet-of-things devices, including smart sensors, homes, and cities. Increasingly, embedding intelligence in such devices involves the use of deep neural networks. However, their storage and processing requirements make them prohibitive for cheap, off-the-shelf platforms. Overcoming those requirements is necessary for enabling widely-applicable smart devices. While many ways of making models smaller and more efficient have been developed, there is a lack of understanding of which ones are best suited for particular scenarios. More importantly for edge platforms, those choices cannot be analyzed in isolation from cost and user experience. In this work, we holistically explore how quantization, model scaling, and multi-modality interact with system components such as memory, sensors, and processors. We perform this hardware/software co-design from the cost, latency, and user-experience perspective, and develop a set of guidelines for optimal system design and model deployment for the most cost-constrained platforms. We demonstrate our approach using an end-to-end, on-device, biometric user authentication system using a $20 ESP-EYE board.
Training Neural Networks for Execution on Approximate Hardware
Apr 08, 2023



Approximate computing methods have shown great potential for deep learning. Due to the reduced hardware costs, these methods are especially suitable for inference tasks on battery-operated devices that are constrained by their power budget. However, approximate computing hasn't reached its full potential due to the lack of work on training methods. In this work, we discuss training methods for approximate hardware. We demonstrate how training needs to be specialized for approximate hardware, and propose methods to speed up the training process by up to 18X.
PhotoFourier: A Photonic Joint Transform Correlator-Based Neural Network Accelerator
Nov 10, 2022The last few years have seen a lot of work to address the challenge of low-latency and high-throughput convolutional neural network inference. Integrated photonics has the potential to dramatically accelerate neural networks because of its low-latency nature. Combined with the concept of Joint Transform Correlator (JTC), the computationally expensive convolution functions can be computed instantaneously (time of flight of light) with almost no cost. This 'free' convolution computation provides the theoretical basis of the proposed PhotoFourier JTC-based CNN accelerator. PhotoFourier addresses a myriad of challenges posed by on-chip photonic computing in the Fourier domain including 1D lenses and high-cost optoelectronic conversions. The proposed PhotoFourier accelerator achieves more than 28X better energy-delay product compared to state-of-art photonic neural network accelerators.
Bit-serial Weight Pools: Compression and Arbitrary Precision Execution of Neural Networks on Resource Constrained Processors
Jan 25, 2022
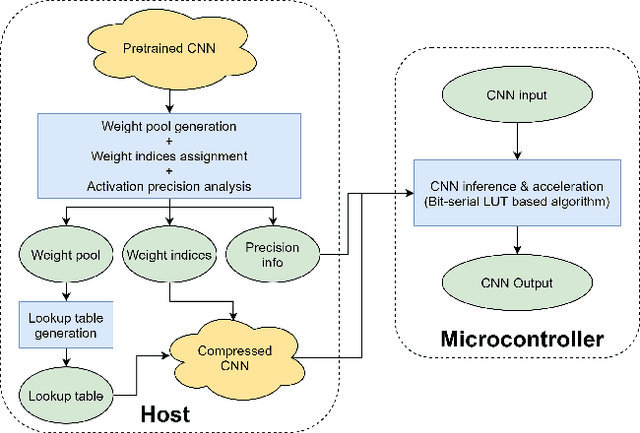
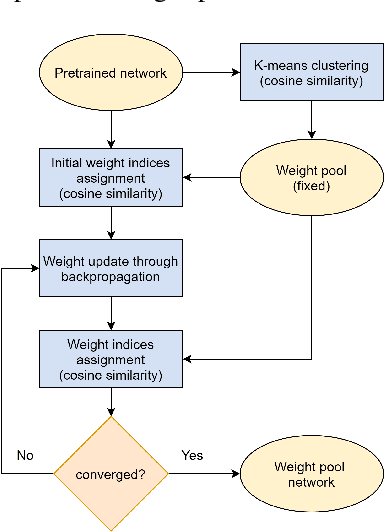

Applications of neural networks on edge systems have proliferated in recent years but the ever-increasing model size makes neural networks not able to deploy on resource-constrained microcontrollers efficiently. We propose bit-serial weight pools, an end-to-end framework that includes network compression and acceleration of arbitrary sub-byte precision. The framework can achieve up to 8x compression compared to 8-bit networks by sharing a pool of weights across the entire network. We further propose a bit-serial lookup based software implementation that allows runtime-bitwidth tradeoff and is able to achieve more than 2.8x speedup and 7.5x storage compression compared to 8-bit weight pool networks, with less than 1% accuracy drop.
Batch Processing and Data Streaming Fourier-based Convolutional Neural Network Accelerator
Dec 23, 2021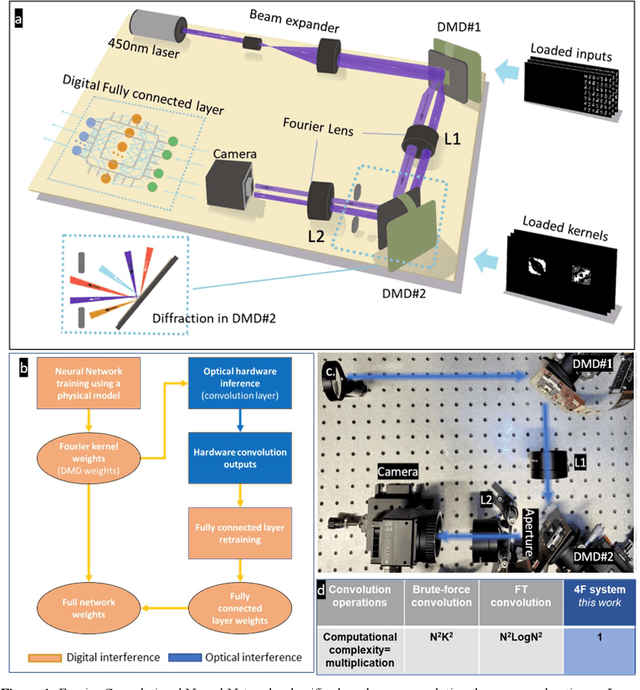

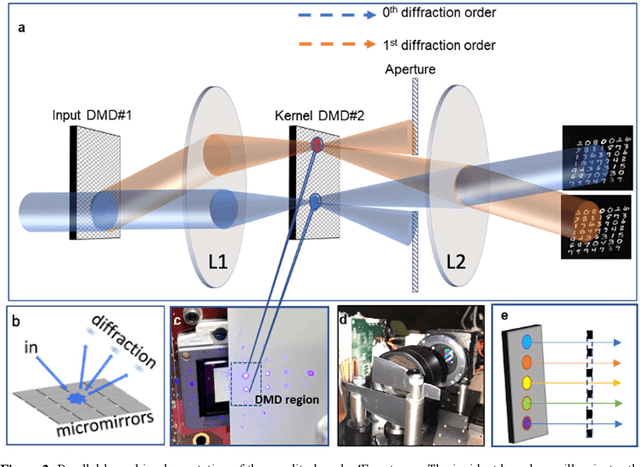
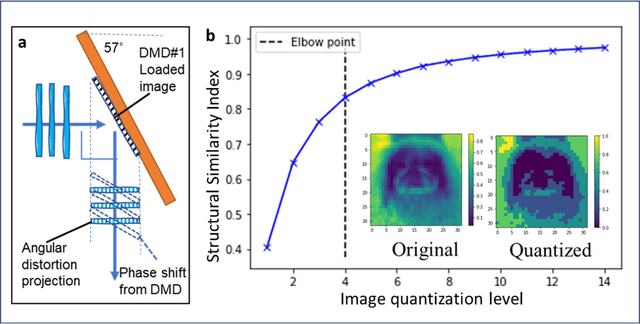
Decision-making by artificial neural networks with minimal latency is paramount for numerous applications such as navigation, tracking, and real-time machine action systems. This requires the machine learning hardware to handle multidimensional data with a high throughput. Processing convolution operations being the major computational tool for data classification tasks, unfortunately, follows a challenging run-time complexity scaling law. However, implementing the convolution theorem homomorphically in a Fourier-optic display-light-processor enables a non-iterative O(1) runtime complexity for data inputs beyond 1,000 x 1,000 large matrices. Following this approach, here we demonstrate data streaming multi-kernel image batch-processing with a Fourier Convolutional Neural Network (FCNN) accelerator. We show image batch processing of large-scale matrices as passive 2-million dot-product multiplications performed by digital light-processing modules in the Fourier domain. In addition, we parallelize this optical FCNN system further by utilizing multiple spatio-parallel diffraction orders, thus achieving a 98-times throughput improvement over state-of-art FCNN accelerators. The comprehensive discussion of the practical challenges related to working on the edge of the system's capabilities highlights issues of crosstalk in the Fourier domain and resolution scaling laws. Accelerating convolutions by utilizing the massive parallelism in display technology brings forth a non-van Neuman-based machine learning acceleration.
SWIS -- Shared Weight bIt Sparsity for Efficient Neural Network Acceleration
Mar 03, 2021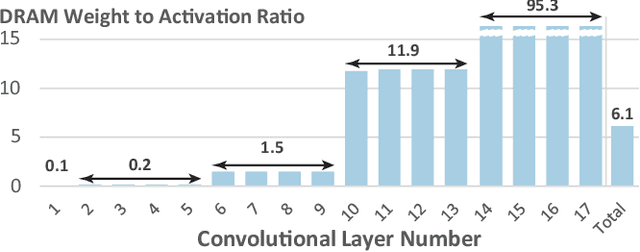
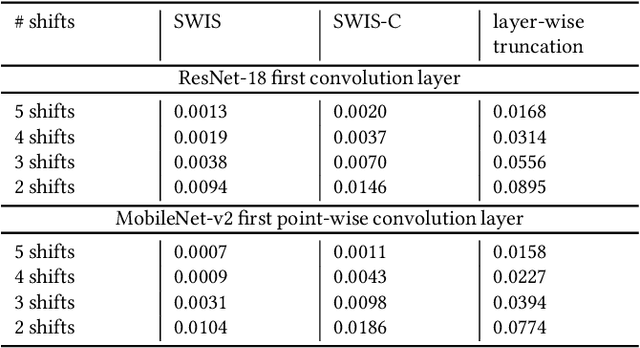
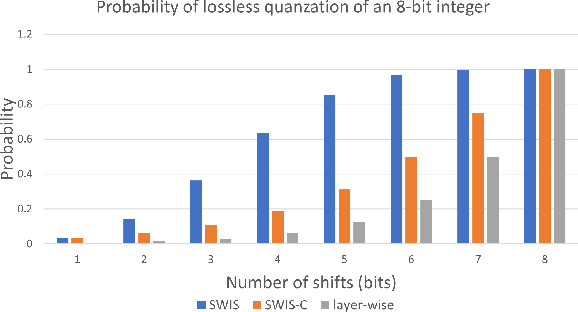

Quantization is spearheading the increase in performance and efficiency of neural network computing systems making headway into commodity hardware. We present SWIS - Shared Weight bIt Sparsity, a quantization framework for efficient neural network inference acceleration delivering improved performance and storage compression through an offline weight decomposition and scheduling algorithm. SWIS can achieve up to 54.3% (19.8%) point accuracy improvement compared to weight truncation when quantizing MobileNet-v2 to 4 (2) bits post-training (with retraining) showing the strength of leveraging shared bit-sparsity in weights. SWIS accelerator gives up to 6x speedup and 1.9x energy improvement overstate of the art bit-serial architectures.